Advent of Code ist eine jährliche, vorweihnachtliche Serie von Programmieraufgaben, die als Adventskalender verpackt sind. Hinter dessen Türen verbergen sich täglich neue – von Tag zu Tag schwierigere – Herausforderungen.
Die Aufgaben können in einer beliebigen Programmiersprache gelöst werden und bestehen jeweils aus zwei Teilaufgaben.
Wie schwer ist Advent of Code?
Die erste Teilaufgabe ist meist relativ schnell gelöst.
Bei der zweiten Aufgabe wird die Größenordnung des Problems drastisch angehoben. Das führt in der Regel dazu, dass die Lösung noch einmal überarbeitet werden muss, da der intuitiv implementierte Algorithmus oft eine zu hohe Komplexitätsklasse aufweist und Stunden, Tage oder gar Monate für die Lösung der Aufgabe brauchen würde.
Kurz nach der Veröffentlichung eines neuen Advent-of-Code-Rätsels findet man bereits die ersten Lösungen im entsprechenden Reddit. Diese bestehen meist aus prozeduralem Spaghetti-Code, der nicht besonders gut lesbar, geschweige denn wartbar, ist.
Meine Advent of Code Antworten 2022
Ich habe mir daher die Mühe gemacht, jede Aufgabe wirklich objektorientiert und testgetrieben in Java zu implementieren, so dass eine Lösung aus kleinen, verständlichen, miteinander interagierenden Objekten entsteht.
Dieser Ansatz führt in der Regel auch dazu, dass sich die Optimierungen, die für Teilaufgabe zwei notwendig sind, auf einen kleinen Ausschnitt des Codes beschränken – oft auf eine einzige Klasse.
Für die Summe der drei größten Blocks müssen wir den Stream absteigend sortieren. Dazu ist leider ein Boxing und ein Unboxing erforderlich, da sich ein IntStream nur aufsteigend sortieren lässt:
An Tag 2 müssen wir einen Simulator für Schere-Stein-Papier schreiben. Teilaufgabe zwei, bei der wir vom Spielergebnis auf den Zug rückschließen müssen, habe ich durch ausprobieren gelöst – es gibt ja nur drei mögliche Züge. Eleganter wäre es natürlich, den eigenen Zug aus dem Zug dem Gegners und dem gewünschten Ergebnis zu berechnen.
An Tag 3 müssen wir einen Algorithmus implementieren, der aus mehreren Listen von Gegenständen (aus zwei Fächern eines Rucksacks bzw. aus drei Rucksäcken) diejenigen herausfiltert, die mehrfach vorkommen.
Wenn wir dabei jedes Element einer Liste mit allen Elementen der zwei anderen Listen vergleichen, kämen wir auf eine Zeitkomplexität von O(n²).
Da die Menge der möglichen Elemente (A-Z und a-z) sehr klein ist, können wir stattdessen ein Array mit Bitsets für jedes mögliche Element anlegen, dann über jede Liste iterieren und für jedes enthaltene Element ein Bit für die entsprechende Liste setzen und zuletzt prüfen, für welche Elemente alle Bits gesetzt sind. Dieser Algorithmus hat die deutlich bessere Zeitkomplexität O(n).
Für Tag 4 habe ich eine Klasse SectionAssignment implementiert. Diese speichert den Start- und Endpunkt einer Sektion und bietet Methoden, um zu prüfen, ob eine Sektion eine andere umschließt bzw. ob zwei Sektionen teilweise überlappen:
record SectionAssignment(int start, int end){
booleanfullyContains(SectionAssignment other){
return start <= other.start && end >= other.end;
}
booleanoverlaps(SectionAssignment other){
return start >= other.start && start <= other.end
|| end >= other.start && end <= other.end
|| other.start >= start && other.start <= end
|| other.end >= start && other.end <= end;
}
}
Code-Sprache:Java(java)
Mit dieser Klasse sind beide Teilaufgaben schnell gelöst.
An Tag 5 habe ich das Strategy Pattern angewendet, um die zwei Arten von Kränen zu implementieren und austauschbar zu machen:
Die move()-Methoden sehen wie folgt aus. Der CrateMover 9000 nimmt – nach und nach – die gewünschte Anzahl von Kisten von einem Stapel und stellt sie auf den anderen:
classCrateMover9000implementsCrateMover{
@Overridepublicvoidmove(CrateStacks crateStacks, Move move){
CrateStack fromStack = CrateMover.getSourceStack(crateStacks, move);
CrateStack toStack = CrateMover.getTargetStack(crateStacks, move);
for (int i = 0; i < move.number(); i++) {
toStack.push(fromStack.pop());
}
}
}Code-Sprache:Java(java)
CrateMover 9001 benutzt einen Hilfs-Stack, um die Reihenfolge der Kisten zwischendurch umzudrehen:
classCrateMover9001implementsCrateMover{
@Overridepublicvoidmove(CrateStacks crateStacks, Move move){
CrateStack fromStack = CrateMover.getSourceStack(crateStacks, move);
CrateStack toStack = CrateMover.getTargetStack(crateStacks, move);
Deque<Crate> helperStack = new LinkedList<>();
for (int i = 0; i < move.number(); i++) {
helperStack.push(fromStack.pop());
}
while (!helperStack.isEmpty()) {
toStack.push(helperStack.pop());
}
}
}Code-Sprache:Java(java)
Die Lösung für Tag 6 habe ich mit einem Set<Character> implementiert. Von jeder Position in der Zeichenkette werden die zurückliegenden Zeichen entsprechend der Marker-Länge in das Set geschrieben. Sobald das Set ein Zeichen bereits enthält, wird das Set zurückgesetzt und der Versuch beim nächsten Zeichen wiederholt – solange, bis der Marker (also die entsprechende Anzahl unterschiedlicher Zeichen) gefunden wurde.
Für Tag 7 habe ich einen Parser geschrieben, der aus den vorgegebenen Kommandos einen Verzeichnis-Baum aus folgenden Klassen (entsprechend dem Composite Pattern) aufbaut:
Für die Lösung von Teil eins müssen wir dann nur noch alle Unterverzeichnisse rekursiv durchgehen und diejenigen herausfiltern, die dem Größenkriterium entsprechen. Das lässt sich sehr elegant mit Javas Stream API lösen:
Um die Aufgabe für Tag 8 zu lösen, brauchen wir keine Tricks, nur etwas Programmierarbeit. Wir können hier viel für die Verständlichkeit des Codes tun, indem wir Richtungen als Enum und Positionen als Record modellieren (die moveTo(...)-Methode ist mit der in Java 14 eingeführten Switch Expression implementiert):
enum Direction {
TOP,
RIGHT,
BOTTOM,
LEFT;
}
record Position(int column, int row){
Position moveTo(Direction direction){
returnswitch (direction) {
case TOP -> new Position(column, row - 1);
case RIGHT -> new Position(column + 1, row);
case BOTTOM -> new Position(column, row + 1);
case LEFT -> new Position(column - 1, row);
};
}
}Code-Sprache:Java(java)
Mittels Position.moveTo(...) können wir dann von jedem Feld aus in die vier Himmelsrichtungen laufen und die Höhe der Bäume mit den Kriterien der jeweiligen Teilaufgabe abgleichen.
Den Position-Record können wir an Tag 9 erneut einsetzen, um die Knoten des Seils zu speichern und einen nach dem anderen entsprechend der vorgegebenen Regeln zu bewegen.
Die Position des jeweils letzten Knotens speichern wir in einem Set<Position>. Dessen Größe ist am Ende die Lösung der Aufgabe.
An Tag 10 müssen wir einen einfachen CPU-Emulator implementieren, der zwei verschiedene Operationen ausführen kann und während der Dauer dieser Operationen entsprechend des X-Registers und der aktuellen X-Position des Bildschirms auf diesem ein Pixel an- oder abschaltet. Die Implementierung erfordert weder Tricks noch Optimierungen.
Das Problem bei Teil zwei von Tag 11 ist, dass der „Worry Level“ durch das Quadrieren schnell gigantische Ausmaße annimmt. Der Trick, um den Worry Level gering zu halten ohne dabei die Spiellogik zu ändern, ist es die Formel für die Erholung
wobei der reliefDivisor das Produkt aller verschiedenen Nenner der „Test“-Operationen ist.
Im Beispiel haben wir die folgenden vier Tests:
Test: divisible by 23
Test: divisible by 19
Test: divisible by 13
Test: divisible by 17Code-Sprache:Klartext(plaintext)
Der reliefDivisor berechnet sich für das Beispiel als 23 × 19 × 13 × 17 = 96.577
Wenn wir nun zur Erholung den Worry Level auf den Rest bei Teilung durch diesen Wert setzen, ist sichergestellt, dass a) der Worry Level klein bleibt und b) sich das Ergebnis der „Test“-Operationen nicht ändern, egal bei welchem Affen sich ein Item befindet.
Für Tag 12 habe ich einen Breadth-First-Algorithmus implementiert, der von der Startposition zu allen erreichbaren Felder geht und dann von jedem erreichbaren Feld weiter zu allen von dort erreichbaren Feldern, usw. Bereits in einem vorherigen Schritt erreichte Felder werden ignoriert, da dorthin bereits ein kürzerer Weg gefunden wurde.
Für Teil zwei habe ich einfach den Algorithmus aus Teil eins auf alle möglichen Startfelder angewendet und den kürzesten aller kürzesten Wege bestimmt.
Die relativ geringe Größe des Problems hat diese triviale Lösung ermöglicht. Bei einer deutlich größeren Karte hätte man auch vom Ziel zurück zum Start gehen können und beim ersten Erreichen eines potentiellen Startfeldes die bis dahin zurückgelegten Felder zurückgeben können.
Für Tag 13 habe ich einen Comparator geschrieben, den ich sowohl in Teil eins verwende, um zu zählen, wie viele Paket-Paare in der richtigen Reihenfolge liegen, als auch in Teil zwei, um die Pakete mittels List.sort() zu sortieren.
Die triviale Lösung für Tag 15 funktioniert ebenfalls mit einem Raster. Bei Teil zwei erweist sich ein Raster allerdings als zu aufwändig.
Der Trick ist es, die durch die Sensoren abgedeckten Bereiche nicht in einem Raster, sondern mit Start- und Endpositionen zu speichern, dabei angrenzende oder überschneidende Bereiche zu kombinieren, und letztlich daraus die nicht abgedeckte Position zu ermitteln.
Die Aufgabe von Tag 16 kann mit einer Tiefensuche gelöst werden. Dabei gibt es nicht die eine Optimierung, sondern mehrere, die den Algorithmus jeweils um einen signifikanten Faktor schneller machen. Ich habe die folgenden vier Optimierungen angewendet:
Der Algorithmus prüft in jeder Situation, ob dieselbe Situation (d. h. die Kombination aus Ventilstellungen, Aktorpositionen und abgelaufene Minuten) bereits zuvor aufgetreten ist. Wenn ja, und wenn diese Situation zu gleich viel oder mehr abgelassenem Druck geführt hat, muss der aktuelle Weg nicht weiter erkundet werden.
In jeder Situation wird berechnet, wie viel Druck in der restlichen Zeit maximal abgelassen werden kann, wenn die Ventile nach absteigender Durchflussmenge geöffnet werden. Ergibt dies ein schlechteres Ergebnis als das aktuell beste, wird der Weg nicht weiter verfolgt.
Bei dem Vergleich der Situation mit allen bisherigen Situationen gelten zwei Situationen auch dann als gleich, wenn die Positionen von dir und dem Elefanten vertauscht sind.
Wenn erkannt wird, dass ein Aktor im Kreis gelaufen ist, ohne auf diesem ein Ventil geöffnet zu haben, wird der aktuelle Weg ebenfalls nicht weiter verfolgt.
Mit Hilfe dieser Optimierungen lässt sich Teilaufgabe zwei in etwa zwei Sekunden lösen.
Die Simulation für Tag 17 ist mit binären Operationen relativ schnell implementiert: „shift left“ und „shift right“, um den Felsen zu verschieben, „bitwise and“ für die Kollisionsprüfung und „bitwise or“ für die Manifestierung eines Felsens.
1.000.000.000.000 Felsen zu simulieren hätte mit meiner initialen Implementierung allerdings knapp 20 Stunden gedauert.
Der Trick für Teilaufgabe zwei besteht darin, Wiederholungen in den Fall- und Verschiebemustern zu finden. Dazu speichert mein Algorithmus eine Kombination aus aktuellem Felsen, aktueller Position in der Eingabe und Höhenprofil der oberen Felsenreihen als Key in einer Map mit aktuell höchstem Felsen und Anzahl der bisher gefallenen Felsen als Value.
Sobald dieselbe Kombination erneut auftritt (was überraschend schnell passiert), können wir mit Hilfe der Anzahl zwischenzeitlich gefallener Felsen und des zwischenzeitlichen Wachstums des Felsenberges in wenigen Millisekunden ein paar Milliarden Schritte überspringen. So lässt sich auch Teilaufgabe zwei in wenigen hundert Millisekunden lösen.
Teilaufgabe eins von Tag 18 ist schnell gelöst. Wir speichern alle Cubes in einem Set und iterieren dann über dieses und zählen – mit Hilfe von Set contains() – diejenigen Seiten, auf denen sich kein Cube befindet.
Teil zwei habe ich mit iterativem Floodfill gelöst. Dabei wird der Bereich außerhalb des Droplets Cube für Cube mit „Dampf“ gefüllt. Jedesmal, wenn ein Cube nicht gefüllt werden kann, weil sich dort Lava befindet, wird ein Counter hochgezählt. Dieser Counter enthält am Ende die gesuchte Außenfläche.
Tag 19 erinnert an die Ventil-Aufgabe von Tag 16. Auch diese Aufgabe löst man mittels einer Tiefensuche und diversen Optimierungen:
Unter der Annahme, dass wir in jeder Runde einen Geode-Roboter produzieren, können wir berechnen, wie viele Geoden von einer bestimmten Situation aus maximal noch produziert werden könnten. Ist diese Zahl kleiner als der aktuelle Bestwert, braucht der aktuelle Pfad nicht weiter erforscht zu werden.
Wenn ein bestimmter Roboter auch in der vorherigen Runde hätte gekauft werden können – in der Runde aber gar kein Roboter gekauft wurde, dann brauchen wir ihn auch jetzt nicht zu kaufen. Sparen macht nur für einen anderen Roboter Sinn.
In der letzten Minute brauchen wir keine Roboter zu produzieren.
In der vorletzten Minute brauchen wir nur Geode-Roboter zu produzieren.
In der vor-vorletzten Minute brauchen wir nur Geode-, Ore- oder Obsidian-Roboter (also keine Clay-Roboter) zu produzieren.
Meine Implementierung löst Teil eins in 4 Sekunden und Teil zwei in 52 Sekunden.
Die Lösung für Tag 20 lässt sich gut mit einer doppelt verketteten, zirkulären Liste implementieren. Teil eins kommt ganz ohne Optimierungen aus.
Bei Teil zwei müssten wir die Knoten mehrere Billionen Mal verschieben. Das können wir mit einer einfachen Formel auf ein paar Tausend reduzieren:
long distance = node.value() % (size - 1);Code-Sprache:Java(java)
Der Trick dabei ist, nicht durch size (die Anzahl der Elemente) zu teilen, sondern durch size - 1. Du kannst das am Beispiel nachvollziehen: In der Liste der Länge 7 müsstest du ein Elemente sechs mal nach rechts schieben, damit es wieder an seinem Ausgangspunkt ankommt.
Für die Lösung von Tag 21 habe ich einen gerichteten azyklischen Graph (Directed acyclic graph) der mathematischen Operationen aufgebaut. Da die Ergebnisse mancher Operationen mehrfach verwendet werden, werden sie gespeichert, sobald sie einmal berechnet wurden.
Für Teil zwei habe ich zunächst versucht, eine Tiefensuche zu implementieren, d. h. verschiedene Werte für den “humn”-Knoten einzusetzen und dann zu prüfen, ob beide Operanden des “root”-Knotens gleich sind. Diese Variante habe ich noch dahingehend optimiert, dass ich zwischen zwei Versuchen nicht alle gespeicherten Ergebnisse gelöscht habe, sondern nur diejenigen auf dem Pfad von “root” zu “humn”. Doch auch so hätte die Berechnung zu lange gedauert, um diese Lösung zu akzeptieren.
Basierend auf der eben genannten Optimierung konnte ich eine deutlich schnellere Lösung implementieren. Und zwar können wir einfach die mathematischen Operationen auf dem Weg von “root” zu “humn” rückwärts ausführen und kommen so in wenigen Millisekunden zum Ergebnis.
Tag 22 fing einmal wieder leicht an. Mit einem zweidimensionalen Raster und ein paar Sonderbehandlungen für die Bereiche außerhalb der Karte ist Teil eins schnell gelöst.
Teil zwei ist deutlich kniffliger. Ich habe dazu Logik geschrieben, die die Koordinaten auf der Karte in Koordinaten auf einer Würfelseite mappt, dann die Würfenseite mittels einer zusätzlichen Liste von Kantenverbindungen (“Wurmlöchern”) verschiebt und dreht, und zuletzt die Koordinaten auf der verschobenen und gedrehten Würfelseite wieder zurück auf die Koordinaten der globalen Karte mappt.
Die Liste von Kantenverbindungen habe ich manuell aus meinem Puzzle Input generiert. Meine Lösung wird daher nicht ohne manuelle Anpassung der Kantenverbindungen bei allen funktionieren (es sei denn die Eingabe hat dasselbe Schnittmuster). Man kann die Kantenverbindungen auch algorithmisch bestimmen, aber dazu hat mir die Zeit gefehlt. Vielleicht hole ich das noch nach.
An Tag 23 können wir uns bereits bei der Lösung der ersten Teilaufgabe darauf einstellen, dass wir in Teilaufgabe zwei vermutlich mehr als zehn Runden simulieren müssen. Da das Feld so immer weiter wachsen wird, sollten wir die Elfen nicht in einem zweidimensionalen Array speichern.
Mein Algorithmus speichert die Elfen als Liste und zusätzlich deren Positionen in einem Set<Position>. So lässt sich die Kollisionsprüfung leicht mittelns Set.contains() lösen. Die Lösung von Teilaufgabe zwei dauert so weniger als eine Sekunde.
An Tag 24 müssen wir erneut einen Pathfinding-Algorithmus implementieren. Für die heutige Aufgabe ist eine Tiefensuche nicht geeignet, da sich die Karte bei jedem Zug ändert. Bei meinem Puzzle Input dauert es 95.400 Schritte, bis das Ziel das erste Mal erreicht wird und etwas über eine Minute, bis Teilaufgabe eins gelöst ist.
Eine Breitensuche löst Teil ein in nur 95 ms und Teil zwei in 130 ms.
Optimiert habe ich die Berechnung der freien Positionen. Statt die komplette Spielkarte für jeden Schritt zu simulieren, berechne ich mittels Modulo-Operation, ob ein Feld zu einer bestimmten Zeit frei ist oder nicht:
Die Lösung für Tag 25 besteht nur aus wenigen Zeilen Code. Der kniffligere Teil ist das Umwandeln einer Dezimalzahl in einen Snafu-String. Hier die entsprechende Methode:
static String toSnafuString(long decimal){
StringBuilder result = new StringBuilder();
do {
long fives = (decimal + 2) / 5;
int digit = (int) (decimal - 5 * fives);
result.insert(0, convertDecimalToSnafuDigit(digit));
decimal = fives;
} while (decimal != 0);
return result.toString();
}Code-Sprache:Java(java)
Wenn dir der Artikel gefallen hat, teile ihn gerne über einen der Share-Buttons am Ende. Möchtest du per E-Mail informiert werden, wenn ich einen neuen Artikel veröffentliche? Dann klicke hier, um dich in den HappyCoders-E-Mail-Verteiler einzutragen
In diesem Artikel lernst du den Sortieralgorithmus „Radix Sort“ kennen. Du erfährst:
Wie funktioniert Radix Sort? (Schritt für Schritt)
Wie implementiert man Radix Sort in Java?
Welche Zeit- und Platzkomplexität hat Radix Sort?
Welche Varianten gibt es von Radix Sort?
… und was bedeutet überhaupt der Begriff „Radix“?
Fangen wir mit der letzten Frage an:
Was ist Radix Sort?
„Radix“ ist zwar das lateinische Wort für „Wurzel“ – dennoch hat Radix Sort nichts mit Wurzelziehen zu tun.
Die „Radix“ eines Zahlensystems (auch „Basis“ genannt) bezeichnet vielmehr die Anzahl der Ziffern, die zur Darstellung von Zahlen in diesem Zahlensystem benötigt werden. Die Radix im Dezimalsystem ist 10, die Radix des Binärsystems ist 2, und die Radix des Hexadezimalsystems ist 16.
Bei Radix Sort sortieren wir die Zahlen Ziffer für Ziffer – und nicht, wie bei den meisten anderen Sortierverfahren, indem wir zwei Zahlen miteinander vergleichen. Wie genau das funktioniert, liest du im folgenden Kapitel.
Radix Sort Algorithmus
Den Algorithmus für Radix Sort erkläre ich am besten Schritt für Schritt an einem Beispiel. Folgende Zahlen sollen sortiert werden:
Wir betrachten zu Beginn ausschließlich die letzte Ziffer (es gibt auch Radix-Sort-Varianten, bei denen man bei der ersten Ziffer beginnt, aber dazu kommen wir später):
Wir sortieren die Zahlen in zwei Phasen: einer Partitionierungsphase und einer Sammelphase.
Partitionierungsphase
Für die Partitionierung legen wir zehn sogenannte „Buckets“ an, bezeichnet mit „0“ bis „9“. Auf diese verteilen wir die Zahlen entsprechend ihrer jeweils letzten Ziffer. Die folgende Grafik demonstriert, wie wir die erste Zahl, die 41, in den Bucket „1“ legen:
Die zweite Zahl, die 573, legen wir, entsprechend ihrer letzten Ziffer, in den Bucket „3“:
Die dritte Zahl, die 3, legen wir ebenfalls in den Bucket „3“:
Auf die gleiche Art verteilen wir auch die restlichen Zahlen auf die Buckets:
Die Partitionierungsphase für die letzte Ziffer ist damit abgeschlossen.
Sammelphase
An die Partitionierungsphase schließt sich die Sammelphase an. Wir sammeln die Zahlen, Bucket für Bucket, in aufsteigender Reihenfolge – und innerhalb der Buckets von links nach rechts (also in der gleichen Reihenfolge wie die Zahlen in den jeweiligen Bucket eingetragen wurden) – in eine neue Liste.
Wir beginnen mit dem Buckets mit der kleinsten Ziffer, also Bucket 1:
Danach sammeln wir die Zahlen des nächsthöheren Buckets, also Bucket 3:
Und schließlich die Zahlen aus Bucket 6 und dann Bucket 8:
Alle Buckets sind nun geleert:
In dieser neuen Liste sind die Zahlen nach ihrer letzten Ziffer aufsteigend sortiert: 1, 1, 3, 3, 3, 6, 8
Nach Zehnerstelle sortieren
Wir wiederholen die Partitionierungs- und Sammelphase für die Zehnerstelle. Die zwei Phasen stelle ich dieses Mal mit nur jeweils einer Grafik dar.
In der Partitionierungsphase verteilen wir die Zahlen nach ihrer Zehnerstelle auf die Buckets:
Die Zehnerstelle von einstelligen Zahlen ist die Null. Dementsprechend habe ich die Drei als „03“ dargestellt.
In der Sammelphase entnehmen wir die Zahlen wieder Bucket für Bucket:
Die Zahlen sind nun nach ihren jeweils zwei letzten Ziffern sortiert: 3, 8, 36, 41, 71, 73, 93
Nach Hunderterstelle sortieren
Die gleiche Prozedur wiederholen wir für die Hunderterstelle. Zunächst die Partitionierungsphase:
Und im Anschluss die Sammelphase:
Nach der dritten und letzten Sammelphase sind die Zahlen nun vollständig sortiert.
Hier noch einmal das Endergebnis ohne führende Nullen:
Im nächsten Kapitel kommen wir zur Implementierung von Radix Sort.
Radix Sort in Java
Radix Sort kann auf verschiedene Weisen implementiert werden. Wir beginnen mit einer einfachen Variante, die sich sehr nah am beschriebenen Algorithmus orientiert. Danach zeige ich dir zwei alternative Implementierungen.
Variante 1: Radix Sort mit dynamischen Listen
Wir fangen mit einer leeren sort()-Methode an und füllen diese Schritt für Schritt.
(Das Endergebnis findest du am Ende dieses Abschnitts und in der Klasse RadixSortWithDynamicLists im GitHub-Repository dieser Sortier-Tutorial-Serie.)
public class RadixSortWithDynamicLists
publicvoidsort(int[] elements){
// We will implement this method step by step...
}
}Code-Sprache:Java(java)
Da wir die zwei Phasen (Partitionierungsphase und Sammelphase) für jede Ziffer wiederholen müssen, müssen wir zunächst einmal feststellen, wie viele Ziffern unsere Zahlen überhaupt haben.
Das tun wir, indem wir die größte Zahl aus dem zu sortierenden Array ermitteln und danach zählen, wie oft sich diese Zahl durch 10 teilen lässt:
public class RadixSortWithDynamicLists
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
// TODO: Implement the partitioning and collection phases
}
privatestaticintgetMaximum(int[] elements){
int max = 0;
for (int element : elements) {
if (element > max) {
max = element;
}
}
return max;
}
privateintgetNumberOfDigits(int number){
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
}Code-Sprache:Java(java)
Danach sortieren wir Ziffer für Ziffer. Dazu schreiben wir eine for-Schleife mit der Schleifenvariable digitIndex, wobei 0 für die Einerstelle steht, 1 für die Zehnerstelle, 2 für die Hunderterstelle, usw.
(In den folgenden Listings drucke ich die Klasse selbst nicht mehr mit ab, nur noch die Methoden innerhalb der Klasse.)
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
// TODO: Sort elements by digit at 'digitIndex'
}
}Code-Sprache:Java(java)
Für den nächsten Schritt benötigen wir die Buckets, auf die wir die Zahlen verteilen können. Wir könnten hierfür zehn ArrayLists verwenden.
Eleganter ist es jedoch diese in eine Bucket-Klasse zu wrappen. Das macht zum einen den Code lesbarer; zum anderen ermöglicht es uns später die Implementierung der Buckets zu ändern, ohne den restlichen Code anpassen zu müssen.
Die Bucket-Klasse können wir als innere Klasse innerhalb der Klasse RadixSortWithDynamicLists anlegen:
privatestaticclassBucket{
privatefinal List<Integer> elements = new ArrayList<>();
privatevoidadd(int element){
elements.add(element);
}
private List<Integer> getElements(){
return elements;
}
}Code-Sprache:Java(java)
Das war die Vorbereitung.
Kommen wir zur Partitionierungsphase. Wir benötigen zehn Buckets, auf die wir die Zahlen verteilen können; diese generieren wir mit einer createBuckets()-Methode:
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}Code-Sprache:Java(java)
Danach verteilen wir unsere Zahlen anhand der aktuell betrachteten Stelle digitIndex auf die Buckets:
privatevoiddistributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets){
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
privateintcalculateDivisor(int digitIndex){
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}Code-Sprache:Java(java)
Der divisor ist dabei diejenige Zahl, durch die wir ein Element teilen müssen, so dass an der hintersten Stelle die aktuell zu betrachtende Ziffer steht – also 1 für die Einerstelle, 10 für die Zehnerstelle, 100 für die Hunderterstelle, usw.
Die Methoden der Partitionierungsphase fassen wir in einer partition()-Methode zusammen:
Und jetzt schließen wir den Kreis, indem wir die sortByDigit()-Methode aus der digitIndex-Schleife der zu Beginn gezeigten sort()-Methode heraus aufrufen:
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}Code-Sprache:Java(java)
Damit ist unserer Radix-Sort-Implementierung abgeschlossen.
Hier siehst du noch einmal den vollständigen Quellcode:
publicclassRadixSortWithDynamicLists{
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}
privatestaticintgetMaximum(int[] elements){
int max = 0;
for (int element : elements) {
if (element > max) {
max = element;
}
}
return max;
}
privateintgetNumberOfDigits(int number){
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
privatevoidsortByDigit(int[] elements, int digitIndex){
Bucket[] buckets = partition(elements, digitIndex);
collect(buckets, elements);
}
private Bucket[] partition(int[] elements, int digitIndex) {
Bucket[] buckets = createBuckets();
distributeToBuckets(elements, digitIndex, buckets);
return buckets;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
privatevoiddistributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets){
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
privateintcalculateDivisor(int digitIndex){
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}
privatevoidcollect(Bucket[] buckets, int[] elements){
int targetIndex = 0;
for (Bucket bucket : buckets) {
for (int element : bucket.getElements()) {
elements[targetIndex] = element;
targetIndex++;
}
}
}
privatestaticclassBucket{
privatefinal List<Integer> elements = new ArrayList<>();
privatevoidadd(int element){
elements.add(element);
}
private List<Integer> getElements(){
return elements;
}
}
}Code-Sprache:Java(java)
Die RadixSortWithDynamicLists-Klasse im GitHub-Repository unterscheidet sich übrigens leicht von dem hier abgedruckten Quellcode:
Sie implementiert das Interface SortAlgorithm, das es ermöglicht verschiedene Radix-Sort-Implementierungen miteinander und mit den anderen Algorithmen der Sortieralgorithmen-Serie zu vergleichen.
Die getMaximum()-Methode ist in die Klasse ArrayUtils ausgelagert.
Die Methoden getNumberOfDigits() und calculateDivisor() liegen in der Klasse RadixSortHelper und können so auch in anderen Radix-Sort-Implementierungen verwendet werden.
Die gezeigte Implementierung hat ein Manko:
Dynamische Listen (also Listen, deren Größe sich zur Laufzeit ändern kann) sind für leistungskritische Einsatzzwecke wie Sortieralgorithmen nicht optimal, da das Hinzufügen von Elementen mit einem gewissen Performance-Overhead verbunden ist (bei einer verketteten Liste beispielsweise müssen neue Knoten angelegt werden; bei einer ArrayList muss das Array in bestimmten Abständen in ein größeres umkopiert werden).
Im nächsten Abschnitt zeige ich dir daher eine alternativen Variante.
Variante 2: Radix Sort mit Arrays
Wir können die Implementierung deutlich beschleunigen (wir werden die Performance der Implementierungen im Anschluss vergleichen), indem wir für die Buckets statt einer ArrayList ein Array verwenden.
Da Arrays eine feste Größe haben, müssen wir vor der Erstellung eines Buckets wissen, wie viele Elemente der Bucket enthalten soll. Wir ändern unsere Bucket-Klasse wie folgt ab und übergeben die Größe an dessen Konstruktor:
Um zu bestimmen, wie viele Elemente ein Bucket enthalten soll, zählen wir vorab die Ziffern an der aktuell betrachteten Stelle digitIndex. Die partition()-Methode sieht dann so aus:
private Bucket[] partition(int[] elements, int digitIndex) {
int[] counts = countDigits(elements, digitIndex);
Bucket[] buckets = createBuckets(counts);
distributeToBuckets(elements, digitIndex, buckets);
return buckets;
}
privateint[] countDigits(int[] elements, int digitIndex) {
int[] counts = newint[10];
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
counts[digit]++;
}
return counts;
}
private Bucket[] createBuckets(int[] counts) {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket(counts[i]);
}
return buckets;
}Code-Sprache:Java(java)
Die distributeToBuckets()-Methode brauchen wir nicht zu ändern, ebensowenig alle anderen in Variante 1 gezeigten Methoden. Gut, dass wir in Variante 1 eine Bucket-Klasse verwendet haben und nicht direkt eine ArrayList :-)
Den vollständigen Code von Variante 2 findest du im GitHub-Repository in der Klasse RadixSortWithArrays.
Kommen wir zu einer dritten Variante.
Variante 3: Radix Sort mit Counting Sort
In Variante 2 haben wir vorab gezählt, wie viele Elemente in jeden Bucket sortiert werden müssen. Mit dieser Information können wir die Buckets auch überspringen und die Elemente direkt an ihre Zielpositionen verschieben. Und zwar indem wir die allgemein Form von Counting Sort anwenden.
Wie Counting Sort funktioniert, werde ich an dieser Stelle nicht noch einmal wiederholen. Ich zeige dir direkt die Implementierung:
publicclassRadixSortWithCountingSort{
@Overridepublicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
// Remember input arrayint[] inputArray = elements;
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
elements = sortByDigit(elements, digitIndex);
}
// Copy sorted elements back to input array
System.arraycopy(elements, 0, inputArray, 0, elements.length);
}
// Same as in the other variants:// getMaximum(), getNumberOfDigits(), calculateDivisor() privateint[] sortByDigit(int[] elements, int digitIndex) {
int[] counts = countDigits(elements, digitIndex);
int[] prefixSums = calculatePrefixSums(counts);
return collectElements(elements, digitIndex, prefixSums);
}
privateint[] countDigits(int[] elements, int digitIndex) {
int[] counts = newint[10];
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
counts[digit]++;
}
return counts;
}
privateint[] calculatePrefixSums(int[] counts) {
int[] prefixSums = newint[10];
prefixSums[0] = counts[0];
for (int i = 1; i < 10; i++) {
prefixSums[i] = prefixSums[i - 1] + counts[i];
}
return prefixSums;
}
privateint[] collectElements(int[] elements, int digitIndex, int[] prefixSums) {
int divisor = calculateDivisor(digitIndex);
int[] target = newint[elements.length];
for (int i = elements.length - 1; i >= 0; i--) {
int element = elements[i];
int digit = element / divisor % 10;
target[--prefixSums[digit]] = element;
}
return target;
}
}Code-Sprache:Java(java)
Es gibt zwei grundlegende Varianten von Radix Sort, die sich durch die Reihenfolge unterscheiden, in der wir die Ziffern der Elemente betrachten.
LSD Radix Sort
Der im ersten Kapitel gezeigte Radix-Sort-Algorithmus nennt sich „LSD Radix Sort“. LSD steht dabei für „least significant digit“, also „niedrigstwertige Stelle“. Wir haben mit dem Sortieren bei der niedrigstwertigen Stelle (den Einern) begonnen und uns Ziffer für Ziffer bis zur höchstwertigen Stelle vorgearbeitet.
MSD Radix Sort
Alternativ können wir auch bei der höchstwertigen Stelle, „most significant digit“ beginnen. Entsprechend heißt die zweite Variante „MSD Radix Sort“.
Dabei müssen wir allerdings anders vorgehen als bei der LSD-Variante. Denn wenn wir in unserem Ausgangsbeispiel die gesamte Eingabeliste zunächst nach Hundertern, dann nach Zehnern und zuletzt nach der Einerstelle sortieren würden, würde folgendes passieren (die Buckets habe ich in der Grafik weggelassen, da es nur um die Ergebnisse nach den drei Collect-Phasen geht):
Die Sortierung nach der Zehner- und Einerstelle hat die jeweiligen vorherigen Sortierungen wieder durcheinander gebracht.
Das Problem ist schnell gelöst:
Nach der Hunderterstelle dürfen wir die Eingabeliste nicht erneut als Ganzes sortieren, sondern die Hunderterstellen-Buckets in sich. Die daraus wiederum resultierenden Zehnerstellen-Buckets sortieren wir dann jeweils nach der Einerstelle. Wir sortieren die Buckets also rekursiv.
MSD Radix Sort – Schritt für Schritt
Die folgenden Grafiken zeigen das rekursive MSD-Radix-Sort-Verfahren Schritt für Schritt am Eingangsbeispiel. Buckets werden durch schwarze Klammern unter den Elementen dargestellt. Leere Buckets werden nicht angezeigt.
Wir beginnen mit der Partitionierung nach Hunderterstellen:
Anstatt nun von der Partitionierungs- in die Sammelphase überzugehen, führen wir auf jedem Bucket eine weitere Partitionierungsphase aus – und zwar auf der nächst niedrigeren Stelle, also den Zehnern.
Leere Buckets und solche, die nur ein Element enthalten (wie die 271 und die 836), brauchen brauchen wir nicht weiter zu partitionieren.
Eigentlich müssten wir die Buckets nun noch nach Einerstellen partitionieren. Da aber keiner der Zehnerstellen-Buckets mehr als ein Element enthält, ist das nicht notwendig.
Wir steigen daher aus der Rekursion wieder aus. Zunächst führen wir eine Sammelphase auf den Zehnerstellen-Buckets aus:
Und zuletzt führen wir die Sammelphase auf den Hunderterstellen-Buckets aus:
Die Sortierung ist damit abgeschlossen.
MSD Radix Sort – Implementierung
Genau wie die LSD-Variante kann auch MSD Radix Sort mit Dynamischen Listen, Arrays und mit Counting Sort implementiert werden.
Ich zeige dir, wie du die oben gezeigte LSD-Array-Implementierung mit wenigen Änderungen in eine MSD-Implementierung ändern kannst.
Hier sind noch einmal die Methoden sort() und sortByDigit() der Klasse RadixSortWithArrays:
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}
privatevoidsortByDigit(int[] elements, int digitIndex){
Bucket[] buckets = partition(elements, digitIndex);
collect(buckets, elements);
}
Code-Sprache:Java(java)
Alles was wir nun tun müssen, ist die sortByDigit()-Methode für die höchstwertige Stelle aufzurufen und zwischen Partitionierungs- und Sammelphase den rekursiven Aufruf für die nächstniedrigere Stelle einzufügen:
publicvoidsort(int[] elements){
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
sortByDigit(elements, numberOfDigits - 1);
}
privatevoidsortByDigit(int[] elements, int digitIndex){
Bucket[] buckets = partition(elements, digitIndex);
// If we haven't reached the last digit, // sort the buckets by the next digit, recursivelyif (digitIndex > 0) {
for (Bucket bucket : buckets) {
if (bucket.needsToBeSorted()) {
sortByDigit(bucket.getElements(), digitIndex - 1);
}
}
}
collect(buckets, elements);
}Code-Sprache:Java(java)
Die Methode Bucket.needsToBeSorted() gibt true zurück, wenn der Bucket wenigstens ein Element enthält.
Ich überlasse es dir als Übungsaufgabe auch für die zwei anderen LSD-Implementierungen (dynamische Listen und Counting Sort) je eine MSD-Variante zu schreiben.
Verwendung anderer Basen
Bisher haben wir die Partitionierung nach dem Dezimalsystem, also mit 10 Buckets, durchgeführt. Wir können aber auch mit jeder anderen Basis arbeiten, also beispielsweise mit dem Binärsystem (2 Buckets), dem Hexadezimalsystem (16 Buckets) oder auch mit hundert, tausend oder mehr Buckets.
Je höher die Basis, desto mehr Buckets, desto aufwändiger die Partitionierungsphase. Andererseits haben die zu sortierenden Zahlen dann weniger Stellen (1.000.000 dezimal = F4240 hexadezimal), so dass insgesamt weniger Partitionierungs- und Sammelphasen stattfinden müssen. Was das für die Performance bedeutet, werden wir im Kapitel „Radix Sort Laufzeit“ ermitteln.
Wie implementiert man Radix Sort mit einer anderen Basis?
Im Grunde genommen müssen wir jedes Vorkommen der Zahl 10 im Quellcode durch die neue Basis ersetzen. In der Klasse RadixSortWithDynamicLists kommt die 10 in den folgenden Methoden vor:
privateintgetNumberOfDigits(int number){
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
privatevoiddistributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets){
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
privateintcalculateDivisor(int digitIndex){
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}Code-Sprache:Java(java)
Wir können die 10 an all diesen Stellen durch eine andere Basis ersetzen. Besser noch: Wir ersetzen sie durch eine Variable, so dass wir den Sortieralgorithmus mit jeder beliebigen Basis aufrufen können.
publicclassRadixSortWithDynamicListsAndCustomBaseimplementsSortAlgorithm{
privatefinalint base;
publicRadixSortWithDynamicListsAndCustomBase(int base){
this.base = base;
}
// All methods not printed here are the same as in RadixSortWithDynamicListsprivateintgetNumberOfDigits(int number){
int numberOfDigits = 1;
while (number >= base) {
number /= base;
numberOfDigits++;
}
return numberOfDigits;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[base];
for (int i = 0; i < base; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
privatevoiddistributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets){
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % base;
buckets[digit].add(element);
}
}
privateintcalculateDivisor(int digitIndex){
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= base;
}
return divisor;
}
}Code-Sprache:Java(java)
Beachte bitte, dass im GitHub-Repository die Methoden getNumberOfDigits() und calculateDivisor() in die Klasse RadixSortHelper ausgelagert sind, da sie auch von anderen Radix-Sort-Implementierungen benötigt werden.
Im GitHub-Repository findest du außerdem die angepassten Algorithmen für Arrays, Counting Sort und rekursives MSD Radix Sort:
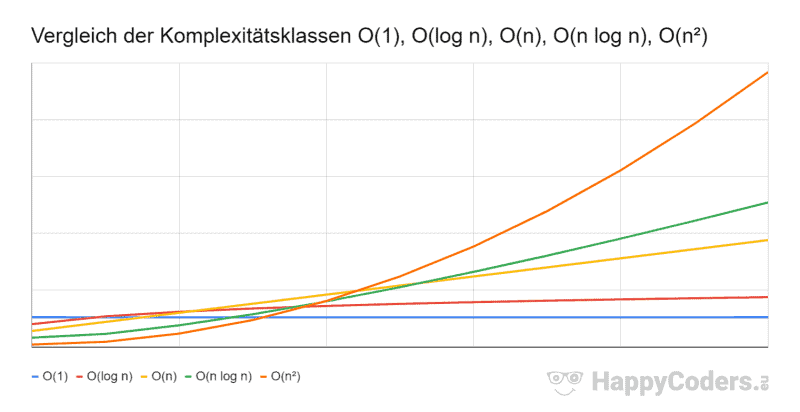
In diesem Kapitel zeige ich dir, wie du die Zeitkomplexität von Radix Sort bestimmst. Eine Einführung in das Thema Zeitkomplexität findest du im Artikel „Zeitkomplexität“ und „O-Notation„.
Wir verwenden im Folgenden die folgenden Variablen:
n = die Anzahl der zu sortierenden Elemente
k = die maximale Schlüssellänge („key length“, Anzahl der Stellen) der zu sortierenden Elemente
b = die Basis (= die Anzahl der Buckets)
Der Algorithmus iteriert über k Stellen; für jede Stelle betreibt er den folgenden Aufwand:
Er legt b Buckets an. Der Aufwand dafür ist jeweils konstant.
Er iteriert über alle n Elemente, um diese in die Buckets einzusortieren. Der Aufwand für die Berechnung der Bucket-Nummer und für das Einfügen in den Bucket ist konstant.
Er iteriert über b Buckets und entnimmt diesen wieder insgesamt n Elemente. Der Aufwand für jeden dieser Schritte ist wiederum konstant.
Konstante Aufwände vernachlässigen wir bei der Bestimmung der Zeitkomplexität. Somit ergibt sich:
Die Zeitkomplexität für Radix Sort ist: O(k · (b + n))
Der Aufwand ist unabhängig davon, wie die Eingabezahlen angeordnet sind. Ob diese zufällig verteilt oder bereits vorsortiert sind, macht keinen Unterschied für den Algorithmus. Best case, average case und worst case sind also identisch.
Die Formel sieht erstmal kompliziert aus. Doch zwei der drei Variablen sind in den meisten Fällen gar nicht variabel. Wenn wir z. B. Longs mit der Basis 10 sortieren, können wir k durch 19 ersetzen (der maximal mögliche Wert für ein Long ist 9.223.372.036.854.775.807) und b durch 10.
Die Formel wird dann zu O(19 · (10 + n)). Konstanten können wir weglassen, somit ergibt sich:
Die Zeitkomplexität für Radix Sort bei bekannter maximaler Länge der zu sortierenden Elemente und mit festgelegter Basis ist: O(n)
Radix Sort hat also für primitive Datentypen wie Integer und Long (bei diesen kennen wir die maximale Länge) eine bessere Zeitkomplexität als Quicksort!
Ob Radix Sort tatsächlich schneller ist, erfährst du im nächsten Kapitel. Dort werden wir die Laufzeit der verschiedenen Radix-Sort-Implementierungen messen und untereinander (und auch mit Quicksort) vergleichen.
Radix Sort Laufzeit
In diesem Kapitel zeige ich dir die Ergebnisse einiger Performance-Tests, die ich mit den Tools UltimateTest und CompareRadixSorts durchgeführt habe, um die Performance der verschiedenen Algorithmen, Implementierungen und Basen zu vergleichen.
Das erste Diagramm zeigt den Vergleich der verschiedenen Implementierungen:
Die Implementierung mit dynamischen Listen schneidet, wie vermutet, am schlechtesten ab. Die restlichen drei Varianten liefern sich ein Kopf-an-Kopf-Rennen, das die Implementierung mit Counting Sort knapp gewinnt, dicht gefolgt von der Implementierung mit Arrays.
Sehr schön zu sehen ist auch die jeweils lineare Laufzeit O(n), die wir im vorangegangenen Kapitel vorhergesagt hatten.
Auswirkung der Basis auf die Laufzeit
Das zweite Diagramm zeigt, wie sich die Wahl der Basis auf die Laufzeit der Array-Implementierung auswirkt:
Wir können sehen, dass die Laufzeit bei einer Basis von 100 und 1.000 deutlich besser ist als bei kleineren als auch größeren Basen.
Untersuchen wir das etwas detaillierter… Das dritte Diagramm zeigt feinere Abstufungen der Basen bei gleicher Anzahl Elemente (n = 5,555,555):
Sowohl eine zu kleine als auch eine zu große Basis sind schlecht für die Performance.
Eine sehr kleine Basis führt dazu, dass viele Iterationen durchgeführt werden müssen. Eine zu große Basis führt zwar zu weniger Iterationen, aber deutlich mehr Buckets innerhalb der Iterationen.
Ein Sweetspot zeigt sich bei einer Basis von 256.
Radix Sort vs. Quicksort
In folgendem Diagramm siehst du die Laufzeiten…
der Radix-Sort-Array-Implementierung mit einer Basis von 256,
von Dual-Pivot Quicksort kombiniert mit Insertion Sort (die schnellste Variante, die wir im Quicksort-Tutorial ermittelt haben)
und der JDK-Sortiermethode Arrays.sort(), welche ebenfalls ein optimiertes Dual-Pivot Quicksort implementiert.
Und tatsächlich ist Radix Sort nicht nur in der Theorie schneller – O(n) vs. O(n log n) – sondern auch in der Praxis – und zwar sowohl im Vergleich mit dem selbst implementierten Quicksort als auch mit der noch schnelleren JDK-Quicksort-Implementierung Arrays.sort().
Wenn du also int-Primitive sortieren musst und die Performance kritisch ist, solltest du erwägen statt des Java-Hausmittels Arrays.sort() besser Radix-Sort einzusetzen. Du kannst gerne die Implementierung aus diesem Artikel verwenden.
Für long-Primitive gilt das nicht, hier ist Arrays.sort() etwa 50% schneller als meine Radix-Sort-Implementierung.
Weitere Eigenschaften von Radix Sort
In diesem abschließenden Kapitel betrachten wir die Platzkomplexität, Stabilität und Parallelisierbarkeit von Radix Sort, sowie die Unterschiede zu Counting Sort und Bucket Sort.
Radix Sort Platzkomplexität
Alle hier gezeigten Varianten benötigen zusätzlichen Speicherplatz:
O(b) für das Zählen der Ziffern (nicht benötigt in der Variante mit dynamischen Listen)
O(b) für die Referenzen auf die Buckets (nicht benötigt bei der Counting-Sort-Variante)
O(n) für die Buckets (nicht benötigt bei der Counting-Sort-Variante)
O(n) für ein zusätzliches Ziel-Array (nur bei der Counting-Sort-Variante)
Jede Variante enthält also mindestens einen O(b)-Anteil und mindestens einen O(n)-Anteil.
Somit gilt:
Die Platzkomplexität von Radix Sort ist: O(b + n)
Es gibt eine Ausnahme: Rekursives MSD Radix Sort mit der Basis 2 kann ohne zusätzlichen Speicher für die Elemente auskommen, indem diese derart partitioniert werden, dass durch jeweiligen Austausch zweier Elemente alle Elemente, deren Bit an der gerade betrachteten Stelle auf 1 steht, an den rechten Rand geschoben werden und alle Elemente, deren Bit auf 0 steht, an den linken Rand (ähnlich wie bei Quicksort).
Ist Radix Sort stabil?
Die Bedeutung von Stabilität bei Sortierverfahren kannst du im verlinkten Einführungsartikel nachlesen. Kurz gesagt: Elemente mit dem gleichen Schlüssel behalten bei der Sortierung ihre ursprüngliche Reihenfolge zueinander bei.
Alle in diesem Artikel gezeigten Implementierungen von Radix Sort sind stabil.
Die im vorherigen Abschnitt angesprochene In-Place-MSD-Radix-Sort-Variante ist hingegen nicht stabil (analog zu Quicksort).
Paralleles Radix Sort
Beide Radix-Sort-Varianten (LSD und MSD) lassen sich parallelisieren.
MSD Radix Sort parallel
Bei MSD Radix Sort können wir nach der ersten Partitionierungsphase alle entstandenen Buckets unabhängig voneinander parallel sortieren. Dank paralleler Streams lässt sich das in Java sehr einfach implementieren:
Um LSD Radix Sort zu parallelisieren, müssen wir etwas mehr Aufwand betreiben:
Wir teilen das Eingabe-Array in parallel zu bearbeitende Segmente auf (z. B. entsprechend der Anzahl der CPU-Kerne).
Wir berechnen parallel pro Segment, wie viele Elemente in welche Buckets sortiert werden müssen.
Wenn Schritt 2 für alle Segmente abgeschlossen ist, berechnen wir a) pro Bucket die Gesamtanzahl der Elemente und b) pro Segment die Start-Schreibpositionen für jeden Bucket.
Wir verteilen die Elemente der Segmente parallel auf die Buckets. Durch die in Schritt 3 berechneten Start-Schreibpositionen wissen wir, an welchen Positionen innerhalb der Buckets wir aus welchen Segmenten schreiben dürfen.
Wenn Schritt 4 für alle Segmente abgeschlossen ist, berechnen wir pro Bucket den Offset im Zielarray (als Präfixsummen über die Anzahl der Elemente der Buckets).
Wir sammeln die Elemente der Buckets parallel ein. Durch die in Schritt 5 berechneten Offsets wissen wir, an welcher Position im Zielarray die Elemente eines Buckets starten müssen.
Den Quellcode findest du in der Klasse ParallelRadixSortWithArrays im GitHub-Repo. Die sechs oben aufgezählten Schritte sind im Code mit entsprechend nummerierten Kommentaren markiert.
Radix Sort parallel vs. sequentiell
Das folgende Diagramm zeigt die Laufzeit der parallelen Varianten verglichen mit den sequentiellen Varianten auf einer 6-Kern-i7-CPU:
Die parallelen Varianten sind bei 67 Millionen Elementen nur etwa 2,3 mal schneller. Dass Faktor 6 nicht einmal annähernd erreicht wird, liegt zum einen daran, dass Teile des Codes nicht parallel ausgeführt werden können und zum anderen daran, dass die CPU-Kerne sehr viele Daten mit dem Arbeitsspeicher austauschen müssen (das Eingabearray belegt 1 GB).
Wenn wir uns einen kleineren Ausschnitt des Diagramms anschauen, sieht die Sache anders aus:
Bei einer halben Million Elemente ist das parallele Radix Sort mit Arrays 5,75 mal schneller als die sequentielle Variante. Die CPU-Kerne werden also nahezu komplett ausgenutzt. Das liegt daran, dass das Eingabearray nur noch 2 MB groß ist, und die Sortierung somit komplett im L3-Cache der CPU stattfinden kann.
Radix Sort vs. Counting Sort
Beide Sortierverfahren verwenden Buckets zum Sortieren. Bei Counting Sort benötigen wir einen Bucket für jeden Wert. Wollten wir beispielsweise Integers sortieren, bräuchten wir etwa vier Milliarden Buckets. Bei Radix Sort hingegen entspricht die Anzahl der Buckets der gewählten Basis.
Bei Radix Sort sortieren wir iterativ Ziffer für Ziffer; bei Counting Sort sortieren wir die Elemente in einer einzigen Iteration.
Counting Sort eignet sich daher in erster Linie für kleine Zahlenräume.
Radix Sort vs. Bucket Sort
Bei Bucket Sort werden die Elemente zunächst so auf eine vorgegebene Anzahl Buckets verteilt, dass alle Elemente eines Buckets größer sind als alle Elemente des vorherigen Buckets (z. B. 0-99, 100-199, 200-299, usw.).
Danach wird jeder Bucket in sich sortiert – entweder rekursiv mit Bucket Sort oder mit einem anderen Sortierverfahren – mit welchem genau ist nicht spezifiziert. Abschließend werden die Elemente aus den sortierten Buckets aneinandergereiht.
Falls dir das bekannt vorkommt – eine Form von Bucket Sort hast du in diesem Artikel kennengelernt: das rekursive MSD Radix Sort.
Zusammenfassung
Radix Sort ist ein stabiler Sortieralgorithmus mit einer allgemeinen Zeitkomplexität von O(k · (b + n)), wobei k für die maximale Schlüssellänge („key length“) der zu sortierenden Elemente steht und b für die Basis.
Ist die maximale Länge der zu sortierenden Elemente bekannt und die Basis festgelegt, dann beträgt die Zeitkomplexität O(n).
Für Integers ist Radix Sort schneller als Quicksort (zumindest auf meiner Testumgebung). Solltest du zeitkritische Sortiervorgänge in Java implementieren müssen, empfehle ich dir Arrays.sort() mit einer Implementierung von Radix Sort zu vergleichen.
Was sind die Unterschiede zwischen den Datenstrukturen Stack und Queue?
Was bedeuten LIFO-Prinzip und FIFO-Prinzip?
Wie unterscheiden sich die Java-Interfaces bzw. Klassen Stack und Queue?
Beginnen wir mit den Datenstrukturen.
Unterschied zwischen Stack und Queue
Ein Stack ist eine lineare Datenstruktur, bei der die Elemente nach dem LIFO-Prinzip („last-in-first-out“) eingefügt und entnommen werden. Das bedeutet, dass dasjenige Elemente, das als letztes auf den Stack gelegt wurde, als erstes wieder entnommen wird – und dass das Element, das zuerst auf den Stack gelegt wurde, als letztes wieder entnommen wird.
Stack-Datenstruktur
Eine Queue ist eine lineare Datenstruktur, bei der die Elemente nach dem FIFO-Prinzip („first-in-first-out“) eingefügt und entnommen werden. Elemente, die als erstes in die Queue eingefügt wurden, werden auch als erstes wieder entnommen. Elemente, die als letztes in die Queue eingefügt wurden, werden zuletzt entnommen.
Die Einfüge- und Entnahmeoperation sowie die Seiten der Datenstrukturen werden bei Stacks und Queues unterschiedlich bezeichnet:
Operation
Stack
Queue
Einfügen
Push (top)
Enqueue (back / tail)
Entnehmen
Pop (top)
Dequeue (front / head)
Die untere Seite des Stacks wird als „bottom“ bezeichnet und ist über die Operationen nicht erreichbar.
Unterschied zwischen Java Stack und Queue
Dieser Abschnitt beschreibt die Unterschiede zwischen der Java-Klasse java.util.Stack und dem Interface java.util.Queue hinsichtlich verschiedener Aspekte.
Alle Stack-Methoden sind synchronized – Stack ist also threadsicher.
Wenn wir jedoch keine Threadsicherheit benötigen, ist die Synchronisation überflüssig.
Und wenn wir Threadsicherheit benötigen, wäre die Verwendung von pessimistischen Locks, wie synchronized sie verwendet, nur bei einer hohen Anzahl an Zugriffskonflikten („high thread contention“) sinnvoll. Bei moderaten Zugriffskonflikten wäre optimistisches Locking besser geeignet.
Für das Queue-Interface bietet das JDK mehrere Implementierungen:
nicht threadsichere Implementierungen (z. B. ArrayDeque¹)
threadsichere Implementierungen mit pessimistischem Locking (z. B. LinkedBlockingQueue)
threadsichere Implementierungen mit optimistischem Locking (z. B. ConcurrentLinkedQueue)
Tatsächlich empfehlen die JDK-Entwickler die Klasse Stack nicht mehr zu verwenden und stattdessen Implementierungen des Deque-Interfaces, welches ebenfalls die Stack-Methoden push() und pop() definiert, einzusetzen.
Auch für das Deque-Interface bietet das JDK zahlreiche Implementierungen:
nicht threadsichere Implementierungen (z. B. ArrayDeque¹)
threadsichere Implementierungen mit pessimistischem Locking (z. B. LinkedBlockingDeque)
threadsichere Implementierungen mit optimistischem Locking (z. B. ConcurrentLinkedDeque)
¹ Das Java-Deque-Interface erbt von Queue, daher kann ArrayDeque sowohl als Deque als auch als Queue eingesetzt werden.
Verletzung des Interface-Segregation-Prinzips
Sowohl die Stack-Klasse als auch das Deque-Interface definieren Methoden, die die jeweilige Datenstruktur eigentlich nicht anbieten sollte. Damit verletzen beide das Interface-Segregation-Prinzip.
Da Stack und Deque letztendlich das Collection-Interface implementieren, haben sie z. B. die Methoden remove(), removeIf(), removeAll() und ratainAll(), mit denen Elemente aus der Mitte der Datenstruktur entnommen werden können.
Stack hat zudem eine insertElementAt()-Methode, mit der Elemente in der Mitte des Stacks eingefügt werden können.
Dieser Artikel hat die Unterschiede zwischen den Datenstrukturen Stack und Queue und den entsprechenden Java-Interfaces bzw. Klassen erläutert.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Was sind die Unterschiede zwischen den Datenstrukturen Deque und Queue?
Wie unterscheiden sich die Java-Interfaces Queue und Deque?
Beginnen wir mit den Datenstrukturen…
Unterschied zwischen Queue und Deque
Eine Queue ist eine Datenstruktur, die nach dem FIFO-Prinzip arbeitet: Elemente, die als erstes in die Queue gelegt werden, werden auch als erstes wieder entnommen. Elemente werden am Ende der Queue eingefügt und am Anfang (auch „Kopf“ genannt) wieder entnommen:
Deque (ausgesprochen „Deck“) steht für „Double-ended Queue“, also eine Queue mit zwei Seiten. Beim Deque können Elemente auf beiden Seiten eingefügt und wieder entnommen werden:
Deque-Datenstruktur
Ein Deque ist eine Erweiterung der Queue und kann auch als solche benutzt werden. Es ist aber nicht auf FIFO-Funktionalität beschränkt. Es kann auch als LIFO-Datenstruktur – also als Stack – verwendet werden, indem man Elemente auf nur einer Seite einfügt und wieder entnimmt.
Deque erweitert Queue um Deque-spezifische Methoden zum Einfügen und Entnehmen von Elementen von spezifischen Seiten des Deques. Eine Übersicht über diese Methoden findest du im oben verlinkten Artikel zum Deque-Interface.
Implementierungen und Performance
Beide Interfaces bieten zahlreiche Implementierungen mit unterschiedlichen Eigenschaften. Welche du einsetzen solltest, erfährst du hier:
Da Deque von Queue erbt, kann jede Deque-Implementierung auch als Queue eingesetzt werden.
Iteration
Queue, und damit auch Deque, erweitern Collection und implementieren damit das Iterable-Interface. Wir können also innerhalb einer for-Schleife über beide Datenstrukturen iterieren:
Queue<String> queue = new ConcurrentLinkedQueue<>();
queue.offer("A");
queue.offer("B");
queue.offer("C");
System.out.println("Queue: ");
for (String s : queue) {
System.out.println(s);
}
Deque<String> deque = new ArrayDeque();
deque.offerLast("A");
deque.offerLast("B");
deque.offerLast("C");
System.out.println("\nDeque: ");
for (String s : deque) {
System.out.println(s);
}Code-Sprache:Java(java)
Beide Datenstrukturen durchläuft der Iterator vom Anfang (Kopf) zum Ende, wie die Ausgabe des kleinen Beispiels zeigt:
Queue:
A
B
C
Deque:
A
B
C
Code-Sprache:Klartext(plaintext)
Deque hat zusätzlich eine descendingIterator()-Methode, mit der die Elemente in entgegengesetzter Richtung – also vom Ende zum Anfang – durchlaufen werden können:
for (Iterator<String> iterator = deque.descendingIterator(); iterator.hasNext(); ) {
String s = iterator.next();
System.out.println(s);
}
Code-Sprache:Java(java)
Zusammenfassung
In diesem Artikel hast du die Unterschiede zwischen den Datenstrukturen Deque und Queue und den entsprechenden Java-Interfaces kennengelernt.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Was sind die Unterschiede zwischen den Datenstrukturen Deque und Stack?
Wie unterscheiden sich die Java-Interfaces bzw. Klassen Deque und Stack?
Warum sollten wir Deque statt Stack verwenden?
Schauen wir uns zunächst einmal die Datenstrukturen an…
Unterschied zwischen Deque und Stack
Ein Stack ist eine Datenstruktur, die nach dem LIFO-Prinzip arbeitet: Elemente, die zuletzt auf den Stack gelegt werden, werden als erstes wieder entnommen – und umgekehrt:
Bei der Klasse Stack sind alle Methoden mit dem synchronized-Keyword versehen. Du kannst Stack also problemlos in einer Multithreading-Anwendung einsetzen.
Für eine single-threaded Anwendung ist diese Synchronisation allerdings überflüssig und würde die Performance negativ beeinflussen. Außerdem ist die Synchronisation durch pessimistische Locks nur in Situationen mit einer hohen Anzahl an Zugriffskonflikten („thread contention“) sinnvoll. Andernfalls ist optimistisches Locking sinnvoller.
Das JDK bietet zum einen nicht-threadsichere Implementierungen, die ohne Locks arbeiten (ArrayDeque und LinkedList) – und zum anderen threadsichere Implementierungen, die ein pessimistisches Lock (LinkedBlockingDeque) oder optimistischen Locking (ConcurrentLinkedDeque) verwenden.
Iteration
Da Stack und Deque Collections sind, implementieren sie letztendlich das Iterable-Interface, so dass wir komfortabel über die enthaltenen Elemente iterieren können.
Allerdings unterscheidet sich die Reihenfolge, in der die Iteratoren von Stack und Deque arbeiten, wie das folgende Beispiel zeigt:
Stack<String> stack = new Stack();
stack.push("A");
stack.push("B");
stack.push("C");
System.out.println("Stack: ");
for (String s : stack) {
System.out.println(s);
}
Deque<String> deque = new ArrayDeque();
deque.push("A");
deque.push("B");
deque.push("C");
System.out.println("\nDeque: ");
for (String s : deque) {
System.out.println(s);
}Code-Sprache:Java(java)
Die Ausgabe dieses Beispiel-Codes lautet:
Stack:
A
B
C
Deque:
C
B
ACode-Sprache:Klartext(plaintext)
Der Iterator von Stack iteriert über die Elemente von unten nach oben, also in der Reihenfolge des Einfügens. Der Iterator von Deque hingegen iteriert von oben nach unten, also in Entnahmereihenfolge.
Um über ein Deque in Einfügereihenfolge zu iterieren, kann über die Methode descendingIterator() ein entsprechender Iterator abgerufen werden:
for (Iterator<String> iterator = deque.descendingIterator(); iterator.hasNext(); ) {
String s = iterator.next();
// ... do something with s ...
}
Code-Sprache:Java(java)
Verletzung des Interface-Segregation-Prinzips
Sowohl Stack als auch Deque bieten weitaus mehr Methoden, als diese Datenstrukturen eigentlich anbieten sollten und verletzen damit das Interface-Segregation-Prinzip.
Beide erben Methoden wie remove(), removeIf(), removeAll() und ratainAll() von Collection. Mit diesen Methoden können Elemente aus der Mitte des Stacks bzw. des Deques entfernt werden.
Stack bietet außerdem eine insertElementAt()-Methode, um ein Element an beliebiger Position des Stacks einzufügen.
Deque bietet die Methoden removeFirstOccurrence() und removeLastOccurrence(), mit denen ebenfalls Elemente entnommen werden können, die nicht am Kopf bzw. Ende des Deques liegen.
Als in Java 6 das Deque-Interface eingeführt wurde, wurde die Stack-Klasse mit folgendem Hinweis versehen:
„A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class.“
Dass das Deque-Interface konsistenter ist als Stack, sehe ich nicht. Beide Interfaces haben zahlreiche Methoden, die eine Stack- bzw. eine Deque-Datenstruktur eigentlich nicht haben sollte (s. Abschnitt „Verletzung des Interface-Segregation-Prinzips“ oben).
Dennoch stimme ich zu, dass wir fortan Deque verwenden sollten. Deque ist ein Interface und bietet mehrere Implementierungen mit verschiedenen Eigenschaften (s. Abschnitt „Thread-Sicherheit“ oben), während wir bei Stack auf eine Implementierung festgelegt sind.
Wenn wir beispielsweise von nur einem Thread auf unseren Stack zugreifen, ist die Synchronisation von Stack überflüssig, und wir sollten lieber ein ArrayDeque einsetzen.
Schöner wäre es allerdings, wenn die Java-Entwickler zusätzlich ein Stack-Interface eingeführt hätten.
Zusammenfassung
In diesem Artikel hast du die Unterschiede zwischen den Datenstrukturen Stack und Deque sowie den entsprechenden Java-Klassen bzw. -Interfaces kennengelernt. Du hast außerdem erfahren, warum du Javas Stack-Klasse nicht mehr verwenden solltest. Die geeignete Deque-Implementierung für deinen Use Case findest du im Artikel „Java Deque-Implementierungen – Welche einsetzen?„
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Teil der Tutorialserie zeige ich dir, wie man eine Deque mit einem Array implementiert – genauer gesagt: mit einem Ringbuffer (englisch: „circular array“).
Wir beginnen mit einem bounded Deque, also einem mit festgelegter Kapazität, und erweitern dieses dann zu einem unbounded Deque, also einem, das unbegrenzt viele Elemente aufnehmen kann.
Falls du den Artikel „Queue mit einem Array implementieren“ gelesen hast, wird dir vieles bekannt vorkommen. Denn die Deque-Implementierung ist im Grunde eine Erweiterung der Queue-Implementierung.
Beginnen wir mit dem bounded Deque…
Implementierung eines bounded Deque mit einem Array
Wir beginnen mit einem leeren Array sowie zwei Variablen:
headIndex – zeigt auf den Kopf des Deques, also das Element, das vom Kopf des Deques als nächstes entnommen werden würde
tailIndex – zeigt auf ein Feld rechts neben dem Ende des Deques, also das Feld, das am Ende des Deques als nächstes gefüllt werden würde
numberOfElements – die Anzahl der Elemente im Deque
Wir lassen die Index-Variablen zunächst auf die Mitte des Arrays zeigen, so dass wir ausreichend Platz haben, um sowohl am Kopf als auch am Ende des Deques Elemente hinzuzufügen:
Deque mit einem Array implementieren: leeres Deque
Funktionsweise der Enqueue-Operationen
Um ein Element am Ende des Deques hinzuzufügen, speichern wir es in demjenigen Arrayfeld, auf das tailIndex zeigt; danach erhöhen wir tailIndex um 1.
Die folgende Grafik zeigt das Deque, nachdem wir die Elemente „banana“ und „cherry“ am Ende des Deques eingefügt haben:
Deque mit einem Array implementieren: zwei Elemente am Ende hinzugefügt
Um ein Element am Kopf des Deques einzufügen, verringern wir headIndex um 1 und speichern das Element dann in demjenigen Arrayfeld, auf das headIndex zeigt.
In der folgenden Grafik siehst du, wie die Elemente „grape“, „lemon“ und „coconut“ (in dieser Reihenfolge) am Kopf des Deques eingefügt wurden:
Deque mit einem Array implementieren: zwei Elemente am Kopf hinzugefügt
Funktionsweise der Dequeue-Operationen
Um Elemente zu entnehmen gehen wir genau andersherum vor.
Um ein Element vom Ende des Deques zu entnehmen, verringern wir tailIndex um 1, lesen das Array an Position tailIndex aus und setzen dieses Feld dann auf null.
Die folgende Grafik zeigt das Deque, nachdem wir drei Elemente am Ende („cherry“, „banana“, „grape“) entnommen haben:
Deque mit einem Array implementieren: drei Elemente am Ende entnommen
Um ein Element am Kopf des Deques zu entnehmen, lesen wir das Array an Position headIndex aus, setzen das Feld auf null und erhöhen headIndex um 1.
Die folgende Grafik zeigt das Deque, nachdem wir ein Element vom Kopf des Deques („coconut“) entnommen haben:
Deque mit einem Array implementieren: ein Element am Kopf entnommen
Damit haben wir die Funktionsweise der vier Grundfunktionen des Deques – Enqueue at front, Enqueue at back, Deque at front und Deque at back – behandelt.
Allerdings könnten wir (ohne zusätzliche Logik) am Kopf des Deques nur noch zwei Elemente hinzufügen, obwohl erst eines von acht Feldern belegt ist. Ebenso könnten wir am Ende des Deques maximal fünf Elemente anhängen.
Um das Deque bis zur Kapazitätsgrenze auffüllen zu können (egal in welcher Richtung), müssen wir aus dem Array einen Ringbuffer (englisch: „circular array“) machen.
Wie das funktioniert, erfährst du im nächsten Abschnitt.
Ringbuffer
Um zu zeigen, wie ein Ringbuffer funktioniert, habe ich das Array aus dem vorherigen Beispiel kreisförmig dargestellt:
Um Elemente am Kopf des Deques einzufügen, schreiben wir diese entgegen dem Uhrzeigersinn in das Array. Das folgende Beispiel zeigt, die die Elemente „mango“, „fig“, „pomelo“ und „apricot“ an die Positionen 1, 0, 7 und 6 eingefügt wurden:
Wenn wir das Array wieder „flach“ darstellen, sieht es wie folgt aus. Der Übersicht halber habe ich am Kopf des Deques einen Pfeil hinzugefügt.
Deque mit „flacher“ Darstellung des Ringpuffers
In beiden Darstellungen ist gut erkennbar, dass vor dem Element „fig“ an Index 0 das Element „pomelo“ an Index 7 steht.
Analog dazu fügen wir Elemente am Ende des Deques ein und entnehmen Elemente. Zusammengefasst gehen wir bei den Operationen wie folgt vor:
Enqueue at back: erhöhe tailIndex um 1; wenn tailIndex 8 erreicht, setze es auf 0.
Enqueue at front: vermindere headIndex um 1; wenn headIndex -1 erreicht, setze es auf 7.
Deque at back: vermindere tailIndex um 1; wenn tailIndex -1 erreicht, setze es auf 7.
Deque at front: erhöhe headIndex um 1; wenn headIndex 8 erreicht, setze es auf 0.
Die Indexe 8 und 7 gelten für das Beispiel oben. Allgemein verwenden wir elements.length statt 8 und element.length - 1 statt 7.
Volles Deque vs. leeres Deque
Sowohl bei einem vollen als auch bei einem leeren Deque zeigen tailIndex und headIndex auf dasselbe Arrayfeld. Um zu erkennen, ob das Deque voll oder leer ist, speichern wir zusätzlich die Anzahl der Elemente in numberOfElements.
Es gibt noch andere Möglichkeiten, um ein volles von einem leeren Deque zu unterscheiden:
Wir speichern die Anzahl der Elemente – und den tailIndexoder den headIndex. Den jeweils anderen Index können wir dann durch Addition oder Subtraktion der Anzahl der Elemente berechnen. Diese Variante führt zu komplexerem und schlechter lesbaren Code.
Wir speichern die Anzahl der Elemente nicht und erkennen ein leeres Deque daran, dass – wenn tailIndex und headIndex identisch sind – das Array an dieser Position leer ist.
Wir füllen das Deque nicht komplett, sondern lassen mindestens ein Feld frei. Wir verschwenden dabei zwar ein Feld des Arrays, sparen uns dafür aber den Speicherplatz für die numberOfElements-Variable.
Quellcode für das bounded Deque mit einem Array
Die Implementierung des oben beschriebenen Algorithmus ist nicht kompliziert, wie du im folgenden Beispiel-Code sehen wirst. Du findest den Code in der Klasse BoundedArrayDeque im GitHub-Repository.
publicclassBoundedArrayDeque<E> implementsDeque<E> {
privatefinal Object[] elements;
privateint headIndex;
privateint tailIndex;
privateint numberOfElements;
publicBoundedArrayDeque(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
@OverridepublicvoidenqueueFront(E element){
if (numberOfElements == elements.length) {
thrownew IllegalStateException("The deque is full");
}
headIndex = decreaseIndex(headIndex);
elements[headIndex] = element;
numberOfElements++;
}
@OverridepublicvoidenqueueBack(E element){
if (numberOfElements == elements.length) {
thrownew IllegalStateException("The deque is full");
}
elements[tailIndex] = element;
tailIndex = increaseIndex(tailIndex);
numberOfElements++;
}
@Overridepublic E dequeueFront(){
E element = elementAtHead();
elements[headIndex] = null;
headIndex = increaseIndex(headIndex);
numberOfElements--;
return element;
}
@Overridepublic E dequeueBack(){
E element = elementAtTail();
tailIndex = decreaseIndex(tailIndex);
elements[tailIndex] = null;
numberOfElements--;
return element;
}
@Overridepublic E peekFront(){
return elementAtHead();
}
@Overridepublic E peekBack(){
return elementAtTail();
}
private E elementAtHead(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
@SuppressWarnings("unchecked")
E element = (E) elements[headIndex];
return element;
}
private E elementAtTail(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
@SuppressWarnings("unchecked")
E element = (E) elements[decreaseIndex(tailIndex)];
return element;
}
privateintdecreaseIndex(int index){
index--;
if (index < 0) {
index = elements.length - 1;
}
return index;
}
privateintincreaseIndex(int index){
index++;
if (index == elements.length) {
index = 0;
}
return index;
}
@OverridepublicbooleanisEmpty(){
return numberOfElements == 0;
}
}
Code-Sprache:Java(java)
Bitte beachte, dass BoundedArrayDequenicht das Deque-Interface des JDK implementiert, sondern ein eigenes, das nur die Methoden enqueueFront(), enqueueBack(), dequeueFront(), dequeueBack(), peekFront(), peekBack() und isEmpty() definiert (s. Deque-Interface im GitHub-Repository):
publicinterfaceDeque<E> {
voidenqueueFront(E element);
voidenqueueBack(E element);
E dequeueFront();
E dequeueBack();
E peekFront();
E peekBack();
booleanisEmpty();
}Code-Sprache:Java(java)
Wie du BoundedArrayDeque benutzen kannst, siehst du im Demo-Programm DequeDemo.
Implementierung eines unbounded Deque mit einem Array
Wenn unser Deque nicht größenbeschränkt, also unbounded sein soll, wird es etwas komplizierter. Denn dazu müssen wir das Array wachsen lassen. Da das nicht direkt möglich ist, müssen wir ein neues, größeres Array erstellen und die bestehenden Elemente dorthin kopieren.
Dabei müssen wir den Ringbuffer-Charakter des Arrays berücksichtigen. D. h. wir können die Elemente nicht einfach an den Anfang des neuen Arrays kopieren.
Die folgende Grafik (ich habe das Deque aus dem vorherigen Beispiel noch um die Elemente „papaya“ am Ende sowie „melon“ und „kiwi“ am Kopf erweitert) zeigt, was dabei passieren würde:
Umkopieren in ein neues Array – so nicht!
Die leeren Felder liegen zwar am Ende des Arrays, aber in der Mitte der Elemente des Deques.
Daher müssen wir beim Kopieren in das neue Array entweder die rechten Elemente (also den linken Teil des Deques) an den rechten Rand des neuen Arrays kopieren. Oder wir kopieren die rechten Elemente an den Anfang des neuen Arrays und die linken Elemente (den rechten Teil des Deques) dahinter.
Die folgende Grafik zeigt die zweite Strategie, die im Code einfacher zu implementieren ist:
Umkopieren in ein neues Array mit Neuanordnung
Somit liegen die leeren Felder vor dem ersten Element („kiwi“) bzw. hinter dem letzten Element („papaya“) des Deques, und wir können auf beiden Seiten das Deques neue Elemente einfügen.
Quellcode für ein unbounded Deque mit einem Array
Im folgenden findest du den Code für ein circular-array-basiertes, unbounded Deque.
Die Klasse hat zwei Konstruktoren: einen, bei dem man die Startkapazität des Deques als Parameter übergeben kann und einen Default-Konstruktor, der die Startkapazität auf zehn Elemente setzt.
Die Methoden enqueueFront() und enqueueBack() prüfen, ob die Kapazität des Deques erreicht ist. Wenn ja, rufen sie die Methode grow() auf. Diese wiederum ruft calculateNewCapacity() auf, um die neue Kapazität zu berechnen, und dann growToNewCapacity(), um die Elemente – wie oben gezeigt – in ein neues, größeres Array zu kopieren.
Du findest den Code in der Klasse ArrayDeque im GitHub-Repository.
publicclassArrayDeque<E> implementsDeque<E> {
privatestaticfinalint DEFAULT_INITIAL_CAPACITY = 10;
private Object[] elements;
privateint headIndex;
privateint tailIndex;
privateint numberOfElements;
publicArrayDeque(){
this(DEFAULT_INITIAL_CAPACITY);
}
publicArrayDeque(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
@OverridepublicvoidenqueueFront(E element){
if (numberOfElements == elements.length) {
grow();
}
headIndex = decreaseIndex(headIndex);
elements[headIndex] = element;
numberOfElements++;
}
@OverridepublicvoidenqueueBack(E element){
if (numberOfElements == elements.length) {
grow();
}
elements[tailIndex] = element;
tailIndex = increaseIndex(tailIndex);
numberOfElements++;
}
privatevoidgrow(){
int newCapacity = calculateNewCapacity(elements.length);
growToNewCapacity(newCapacity);
}
staticintcalculateNewCapacity(int currentCapacity){
return currentCapacity + currentCapacity / 2;
}
privatevoidgrowToNewCapacity(int newCapacity){
Object[] newArray = new Object[newCapacity];
// Copy to the beginning of the new array: from tailIndex to end of old arrayint oldArrayLength = elements.length;
int numberOfElementsAfterTail = oldArrayLength - tailIndex;
System.arraycopy(elements, tailIndex, newArray, 0, numberOfElementsAfterTail);
// Append to the new array: from beginning to tailIndex of old arrayif (tailIndex > 0) {
System.arraycopy(elements, 0, newArray, numberOfElementsAfterTail, tailIndex);
}
// Adjust head and tail
headIndex = 0;
tailIndex = oldArrayLength;
elements = newArray;
}
// The remaining methods are the same as in BoundedArrayDeque:// - dequeFront(), dequeBack(), // - peekFront(), peekBack(), // - elementAtHead(), elementAtTail(), // - decreaseIndex(), increaseIndex(), isEmpty()
}
Code-Sprache:Java(java)
Die in den Kommentaren am Ende des Quellcodes aufgelisteten Methoden gleichen denen des im vorletzten Abschnitt dargestellten BoundedArrayDeque. Daher habe ich hier auf einen erneuten Abdruck verzichtet.
Die calculateNewCapacity()-Methode habe ich hier im Vergleich zum Code auf GitHub stark vereinfacht dargestellt. Die Methode im Repository verdoppelt die Arraygröße solange es kürzer als 64 Elemente ist; danach vergrößert sie es nur noch um Faktor 1,5. Außerdem prüft die Methode, ob eine Maximalgröße für Arrays erreicht ist.
Unser ArrayDeque wächst jetzt, sobald seine Kapazität für ein neues Element nicht mehr ausreicht.
Was es nicht kann, ist wieder zu schrumpfen, wenn sehr viele Elemente wieder entnommen wurden und ein Großteil der Arrayfelder nicht mehr benötigt wird. Gerne überlasse ich dir eine solche Erweiterung als Übungsaufgabe.
Zusammenfassung und Ausblick
Im heutigen Teil der Tutorialserie hast du ein Deque mit einem Array implementiert (genauer gesagt: mit einem Ringbuffer). Schau dir gerne auch einmal den Artikel „Queue mit einem Array implementieren“ an – dort findest du eine ähnliche Implementierung für eine Queue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In den vergangenen Teilen dieser Tutorialserie hast du alle Deque-Implementierungen des JDK kennengelernt. In diesem Artikel gebe ich dir eine Entscheidungshilfe, wann du welche Implementierung einsetzen solltest.
In der Tabelle ist der Name des Deques jeweils mit dem Teil der Serie verlinkt, in dem dieses Deques mit seinen spezifischen Eigenschaften vorgestellt wird.
Erläuterungen zu den Begriffen blocking, non-blocking, fairness policy, bounded und unbounded findest du im Artikel über das BlockingQueue-Interface.
¹ Fail-fast: Der Iterator wirft eine ConcurrentModificationException, wenn während der Iteration Elemente in das Deque eingefügt oder aus diesem entnommen werden.
² Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators im Deque liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Wann solltest du welche Deque-Implementierung verwenden?
Anhand der in den vorherigen Teilen der Serie erklärten und in der Tabelle oben zusammengefassten Eigenschaften kannst du für deinen speziellen Einsatzzweck das richtige Deque auswählen.
Meine Empfehlungen lauten:
ArrayDeque für single-threaded Anwendungen
ConcurrentLinkedDeque als threadsicheres, nicht blockierendes und unbounded Deque
LinkedBlockingDeque als threadsicheres, blockierendes, bounded Deque
Hier meine Empfehlung noch einmal als Entscheidungsbaum:
In diesem Artikel habe ich einen Überblück über alle Deque-Implementierungen gegeben sowie eine Entscheidungshilfe, wann du welche Implementierung einsetzen solltest.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Teil der Tutorialserie erfährst du alles über das LinkedBlockingDeque:
Was sind die Eigenschaften von LinkedBlockingDeque?
Wann sollte man es einsetzen?
Wie setzt man es ein (Java-Beispiel)?
Wir befinden uns hier in der Klassenhierarchie:
LinkedBlockingDeque in der Klassenhierarchie
LinkedBlockingDeque Eigenschaften
Die Klasse java.util.concurrent.LinkedBlockingDeque basiert – genau wie ConcurrentLinkedDeque – auf einer verketteten Liste, ist allerdings bounded (hat eine maximale Kapazität) und blockierend.
LinkedBlockingDeque ist das Deque-Pendant zu LinkedBlockingQueue und hat entsprechend ähnliche Eigenschaften:
Es basiert auf einer doppelt verketteten Liste.
Threadsicherheit wird durch ein einzelnes ReentrantLock garantiert, das von allen Enqueue- und Dequeue-Operationen geteilt wird (LinkedBlockingQueue hingegen verwendet zwei Locks – ein Enqueue-Lock und ein Dequeue-Lock).
Im Gegensatz zu ConcurrentLinkedDeque wird die Größe des Deques in einem Feld gespeichert und nicht bei jedem Aufruf von size() durch Zählen der Listenknoten berechnet. Die Zeitkomplexität der size()-Methode lautet somit: O(1).
LinkedBlockingDeque bietet keine Fairness Policy an, d. h. blockierende Methoden werden in undefinierter Reihenfolge bedient (mit einer Fairness Policy würden sie in der Reihenfolge bedient werden, in der sie blockiert haben).
Die Deque-Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Verkettete Liste
Ja (pessimistisches Locking mit einem Lock)
Blocking
Nicht verfügbar
Bounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators im Deque liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Ich empfehle LinkedBlockingDeque, wenn du ein blockierendes, threadsicheres Deque benötigst.
Das folgende Beispiel, zeigt wie du LinkedBlockingDeque einsetzen kannst. Das Beispiel erweitert das LinkedBlockingQueue-Beispiel dahingehend, dass es Elemente auf einer zufälligen Seite des Deques einfügt bzw. entnimmt.
Folgendes passiert im Beispiel:
Wir erstellen zunächst eine LinkedBlockingDeque mit einer Kapazität für drei Elemente.
Dann planen wir zehn Dequeue-Operationen, die im Abstand von drei Sekunden Elemente aus dem Deque an zufälliger Seite entnehmen.
Außerdem planen wir zehn Enqueue-Operationen, die erst nach 3,5 Sekunden starten, dann aber im Abstand von jeweils nur einer Sekunde Elemente an einer zufälligen Seite des Deques einfügen.
Dadurch, dass wir mit den Enqueue-Operationen später starten, können wir zu Beginn blockierende Dequeue-Operationen sehen.
Da wir dann deutlich schneller einfügen als entnehmen, erreichen wir schnell die Deque-Kapazität, so dass auch Enqueue-Threads blockieren.
Es ist zu Beginn gut zu sehen, wie die takeLast()– und takeFirst()-Aufrufe nach 0 s und 3 s an dem leeren Deque blockieren.
Nach 3,5 s und 4,5 s schreiben wir Elemente in das Deque, die sofort von den vorab blockierten Methoden in Threads 1 und 4 wieder entnommen werden.
Wir schreiben nun schneller als dass wir lesen, so dass nach 10,5 s Thread 1 beim Aufruf von putLast() und nach 11,5 s Thread 4 beim Aufruf von putFirst() am vollen Deque blockieren.
Nach 12 s entnimmt Thread 5 ein Element, so dass Thread 1 fortfahren und das Deque wieder füllen kann.
Nach 12,5 s blockiert Thread 9 mit putFirst(), da das Deque nach wie vor (bzw. wieder) voll ist.
Nach 15 s und 18 s entnehmen die Threads 3 und 7 jeweils ein Element, wodurch die blockierten Threads 4 und 9 wiederum ein Element einfügen können.
Danach werden (bei 21 s, 24 s und 27 s) die verbleibenden drei Elemente entnommen und keine neuen eingefügt.
Zusammenfassung und Ausblick
In diesem Teil der Tutorialserie hast du das auf einer verketteten Liste basierte, threadsichere, bounded und blockierende LinkedBlockingDeque und seine Eigenschaften kennengelernt.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel erfährst du alles über die Klasse java.util.concurrent.ConcurrentLinkedDeque:
Was sind die Eigenschaften des ConcurrentLinkedDeque?
Wann sollte man es einsetzen?
Wie setzt man es ein (Java-Beispiel)?
Hier befinden wir uns in der Klassenhierarchie:
ConcurrentLinkedDeque in der Klassenhierarchie
ConcurrentLinkedDeque Eigenschaften
ConcurrentLinkedDeque ist das Deque-Pendant zur ConcurrentLinkedQueue und teilt deren Eigenschaften:
Es basiert auf einer doppelt verketteten Liste.
Threadsicherheit wird garantiert durch optimistisches Locking in Form von nicht-blockierenden Compare-and-set (CAS)-Operationen auf separate VarHandles für Kopf und Ende des Deques, sowie für die Referenzen der Listenknoten.
Um die Länge eines ConcurrentLinkedDeque zu bestimmen, müssen die Elemente der verketteten Liste gezählt werden. Der Aufwand hierfür wächst proportional mit der Länge der Liste. Die Zeitkomplexität dafür beträgt also: O(n)
Aufgrund der hohen Kosten für die Längenbestimmung ist ConcurrentLinkedDeque unbounded.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Bounded/ Unbounded
Iterator Type
Doppelt verkettete Liste
Ja (optimistisches Locking durch Compare-and-set)
Non-blocking
Unbounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators im Deque liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
ConcurrentLinkedDeque ist eine gute Wahl, wenn ein threadsicheres, nicht blockierendes, unbounded Deque benötigt wird.
Für diesen Einsatzzweck existiert keine Array-basierte Alternative. Das einzige Array-basierte Deque, ArrayDeque, ist nicht threadsicher.
ConcurrentLinkedDeque Beispiel
Das folgende Beispiel (Klasse ConcurrentLinkedDequeExample auf GitHub) demonstriert die Threadsicherheit von ConcurrentLinkedDeque. Vier schreibende und drei lesende Threads fügen nebenläufig Elemente an zufälligen Seiten des Deques ein bzw. entnehmen sie.
publicclassConcurrentLinkedDequeExample{
privatestaticfinalint NUMBER_OF_PRODUCERS = 4;
privatestaticfinalint NUMBER_OF_CONSUMERS = 3;
privatestaticfinalint NUMBER_OF_ELEMENTS_TO_PUT_INTO_DEQUE_PER_THREAD = 5;
privatestaticfinalint MIN_SLEEP_TIME_MILLIS = 500;
privatestaticfinalint MAX_SLEEP_TIME_MILLIS = 2000;
private Deque<Integer> deque;
privatefinal CountDownLatch producerFinishLatch =
new CountDownLatch(NUMBER_OF_PRODUCERS);
privatevolatileboolean consumerShouldBeStoppedWhenDequeIsEmpty;
publicstaticvoidmain(String[] args)throws InterruptedException {
new ConcurrentLinkedDequeExample().runDemo();
// We'll let the program end when all consumers are finished
}
privatevoidrunDemo()throws InterruptedException {
createDeque();
startProducers();
startConsumers();
waitUntilAllProducersAreFinished();
consumerShouldBeStoppedWhenDequeIsEmpty = true;
}
privatevoidcreateDeque(){
deque = new ConcurrentLinkedDeque<>();
}
privatevoidstartProducers(){
for (int i = 0; i < NUMBER_OF_PRODUCERS; i++) {
createProducerThread().start();
}
}
private Thread createProducerThread(){
returnnew Thread(
() -> {
for (int i = 0; i < NUMBER_OF_ELEMENTS_TO_PUT_INTO_DEQUE_PER_THREAD; i++) {
sleepRandomTime();
insertRandomElementAtRandomSide();
}
producerFinishLatch.countDown();
});
}
privatevoidsleepRandomTime(){
ThreadLocalRandom random = ThreadLocalRandom.current();
try {
Thread.sleep(random.nextInt(MIN_SLEEP_TIME_MILLIS, MAX_SLEEP_TIME_MILLIS));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatevoidinsertRandomElementAtRandomSide(){
ThreadLocalRandom random = ThreadLocalRandom.current();
Integer element = random.nextInt(1000);
if (random.nextBoolean()) {
deque.offerFirst(element);
System.out.printf(
"[%s] deque.offerFirst(%3d) --> deque = %s%n",
Thread.currentThread().getName(), element, deque);
} else {
deque.offerLast(element);
System.out.printf(
"[%s] deque.offerLast(%3d) --> deque = %s%n",
Thread.currentThread().getName(), element, deque);
}
}
privatevoidstartConsumers(){
for (int i = 0; i < NUMBER_OF_CONSUMERS; i++) {
createConsumerThread().start();
}
}
private Thread createConsumerThread(){
returnnew Thread(
() -> {
while (shouldConsumerContinue()) {
sleepRandomTime();
removeElementFromRandomSide();
}
});
}
privatebooleanshouldConsumerContinue(){
return !(consumerShouldBeStoppedWhenDequeIsEmpty && deque.isEmpty());
}
privatevoidremoveElementFromRandomSide(){
if (ThreadLocalRandom.current().nextBoolean()) {
Integer element = deque.pollFirst();
System.out.printf(
"[%s] deque.pollFirst() = %4d --> deque = %s%n",
Thread.currentThread().getName(), element, deque);
} else {
Integer element = deque.pollLast();
System.out.printf(
"[%s] deque.pollLast() = %4d --> deque = %s%n",
Thread.currentThread().getName(), element, deque);
}
}
privatevoidwaitUntilAllProducersAreFinished()throws InterruptedException {
producerFinishLatch.await();
}
}Code-Sprache:Java(java)
Im folgenden habe ich die ersten 15 Zeilen eines beispielhaften Programmlaufs abgedruckt:
Es ist schön zu sehen, wie die sieben Threads Elemente an beiden Seiten des Deques einfügen und entnehmen. In der dritten Zeile siehst du, wie Thread 5 beim Aufruf von pollLast() den Rückgabewert null geliefert bekommen hat, da zu diesem Zeitpunkt das Deque leer war.
Zusammenfassung und Ausblick
In diesem Teil der Tutorialserie hast du das auf einer verketteten Liste basierte, threadsichere ConcurrentLinkedDeque und seine Eigenschaften kennengelernt.
Im nächsten Teil stelle ich dir das einzige blockierende Deque, LinkedBlockingDeque, vor.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel erfährst du alles über die Java-Klasse LinkedList in ihrer Rolle als Deque:
Was sind die Eigenschaften von LinkedList?
Wann sollte man sie als Deque einsetzen?
Wie setzt man sie als Deque ein (Java-Beispiel)?
Welche Zeitkomplexitäten haben die LinkedList-Operationen?
Wir befinden uns hier in der Klassenhierarchie:
LinkedList in der Klassenhierarchie
LinkedList Eigenschaften als Deque
Die Klasse java.util.LinkedList implementiert eine klassische doppelt verkettete Liste.
Sie existiert im JDK seit Version 1.2, also deutlich länger als das Deque-Interface, das sie implementiert. Die Deque-spezifischen Methoden wurden mit Einführung von Deque in Java 6 hinzugefügt.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Bounded/ Unbounded
Iterator Type
Verkettete Liste
Nein
Non-blocking
Unbounded
Fail-fast¹
¹ Fail-fast: Der Iterator wirft eine ConcurrentModificationException, wenn während der Iteration Elemente in das Deque eingefügt oder aus diesem entnommen werden.
Ein Array benötigt deutlich weniger Speicher als eine verkettete Liste.
Der Zugriff auf die Elemente eines Arrays ist schneller als auf die einer verketteten Liste.
Verkettete Listen sind für den Garbage Collector „schwer verdaulich“.
Wenn du eine Liste benötigst, ist ArrayList meist die bessere Wahl.
Wenn du eine nicht threadsicheres Deque (oder eine nicht threadsichere Queue) benötigst, dann verwende ein ArrayDeque.
Das sind natürlich nur allgemeine Empfehlungen. Solltest du Gründe haben, die für den Einsatz einer LinkedList sprechen (wenn du z. B. hauptsächlich Elemente in der Mitte entnimmst und einfügst – das allerdings nicht in der Rolle eines Deques), dann würde ich dir raten die Performance der LinkedList für deinen speziellen Anwendungsfall mit alternativen Datenstrukturen zu vergleichen.
LinkedList Deque Beispiel
Im folgenden Beispiel siehst du, wie man eine LinkedList in Java verwenden kann. Der Beispielcode zeigt, wie man eine LinkedList erstellt, wie man sie mit zufälligen Elemente befüllt, wie man das Kopf- und Endelement ausgibt und wie man die Elemente letztlich wieder aus der LinkedList entnimmt.
Falls du das ArrayDeque-Tutorial gelesen hast, dürfte dir das Demo bekannt vorkommen. Da sowohl ArrayDeque als auch LinkedList non-blocking und nicht thread-safe sind, kann ich für beide Implementierungen nur die Deque-Grundfunktionen demonstrieren.
Den Code findest du in der Klasse LinkedListDemo im GitHub-Repo.
Bei einer verketteten Liste spielt es für das Einfügen und Entfernen von Elementen keine Rolle, wie lang die Liste bereits ist. Der Aufwand für beide Operationen ist somit konstant.
Die Zeitkomplexität für die Enqueue- und Dequeue-Operationen beträgt somit: O(1)
Anders sieht es in der Regel für die Bestimmung der Größe aus. Um die Elemente der verketteten Liste zu zählen, muss die Liste einmal komplett von vorne bis hinten durchlaufen werden.
Glücklicherweise ist das bei der Java LinkedList nicht der Fall. Diese speichert ihre Größe in einem zusätzlichen Feld und aktualisiert dieses Feld bei jeder Einfüge- und Löschoperation.
Die Zeitkomplexität für LinkedList.size() beträgt also auch: O(1)
Zusammenfassung und Ausblick
In diesem Artikel hast du alles über die Deque-Implementierung LinkedList erfahren.
Im nächsten Teil dieser Serie kommen wir zur ersten threadsicheren Deque-Implementierung: dem ConcurrentLinkedDeque.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel erfährst du alles über die Klasse java.util.ArrayDeque:
Was sind die Eigenschaften von ArrayDeque?
Wann sollte man es einsetzen?
Wie setzt man es ein (Java-Beispiel)?
Welche Zeitkomplexitäten haben die ArrayDeque-Operationen?
Was unterscheidet ArrayDeque von LinkedList?
Wir befinden uns an diesem Punkt in der Klassenhierarchie:
ArrayDeque in der Klassenhierarchie
ArrayDeque Eigenschaften
ArrayDeque basiert – wie der Name schon sagt – auf einem Array. Auf dessen Basis wird ein Ringpuffer („circular array“) implementiert. Wie der genau funktioniert, erfährst du, wenn wir in einem späteren Teil der Serie selbst ein Deque mit einem Array implementieren.
Das dem ArrayDeque zugrunde liegende Array wächst bei Bedarf, wird jedoch weder automatisch verkleinert, noch kann es manuell verkleinert werden.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Bounded/ Unbounded
Iterator Type
Array
Nein
Non-blocking
Unbounded
Fail-fast¹
¹ Fail-fast: Der Iterator wirft eine ConcurrentModificationException, wenn während der Iteration Elemente in das Deque eingefügt oder aus diesem entnommen werden.
Einsatzempfehlung
ArrayDeque ist für single-threaded Anwendungen (und nur dafür) eine gute Wahl. Die Tatsache, dass das zugrunde liegende Array nicht verkleinert werden kann, sollte im Auge behalten werden.
Für multi-threaded Einsatzzwecke solltest du eines der folgendes Deques verwenden:
Durch die Verwendung eines Ringbuffers („circular array“) müssen weder beim Einfügen in das Deque noch beim Entnehmen aus dem Deque die Elemente innerhalb des Arrays verschoben werden.
Der Aufwand für die Enqueue- und Dequeue-Operationen ist somit unabhängig von der Anzahl der Elemente im Deque, also konstant.
Die Zeitkomplexität sowohl für die Enqueue- also auch die Dequeue-Operationen beträgt somit: O(1)
ArrayDeque vs. LinkedList
Eine alternative Implementierung von Deque ist die LinkedList, die ich im nächsten Teil des Tutorials vorstellen werde.
Der Unterschied zwischen ArrayDeque und LinkedList ist die zugrunde liegende Datenstruktur: Array bzw. verkettete Liste.
In diesem Teil der Tutorialserie hast du die Deque-Implementierung ArrayDeque und ihre Eigenschaften kennengelernt. ArrayDeque ist eine gute Wahl für single-threaded Anwendungen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Das Interface java.util.concurrent.BlockingDeque erweitert das Deque-Interface um zusätzliche blockierende Operationen:
Dequeue-Operationen, die beim Entnehmen eines Elements aus einem leeren Deque so lange warten, bis ein Element verfügbar ist (also darauf, dass ein anderer Thread eines einfügt).
Enqueue-Operationen, die beim Einfügen eines Elements in ein volles¹ Deque so lange blockieren, bis wieder Platz verfügbar ist (also, bis ein anderer Thread ein Element entnommen hat).
BlockingDeque erweitert außerdem BlockingQueue, und indirekt – sowohl über Deque als auch über BlockingQueue – die Queue– und Collection-Interfaces:
BlockingDeque: Interface- und Klassenhierarchie
¹ Ein Deque ist voll, wenn es größenbeschränkt (bounded) ist und die Anzahl der in das Deque eingefügten Elemente die festgelegte Deque-Kapazität erreicht hat.
Java BlockingDeque-Methoden
Die blockierenden Methoden gibt es in jeweils zwei Varianten: eine, die unbegrenzt lange wartet und eine, der man einen Timeout mitgeben kann. Wenn dieser abläuft, bricht die Methode ab und liefert einen Fehlercode zurück.
Die Methoden, die BlockingDeque von BlockingQueue erbt (z. B. Einfügen am Ende, Entnahme am Kopf), wurden der Konsistenz halber mit neuen Namen zusätzlich definiert – beispielsweise BlockingQueue.put() als BlockingDeque.putLast().
In der folgenden Auflistung der Methoden führe ich diese BlockingQueue-Methoden jeweils bei den äquivalenten BlockingDeque-Methoden mit an.
Am Ende des Kapitels findest du zwei Tabellen, in der noch einmal alle Methoden übersichtlich zusammengefasst sind.
Blockierende Methoden zum Einfügen in das Deque
Zunächst eine grafische Darstellung der blockierenden Enqueue-Methoden:
Blockierende Methoden zum Einfügen in ein Deque
BlockingDeque.putFirst() + putLast()
Die Methoden putFirst() und putLast() fügen ein Element am Anfang bzw. Ende des Deques ein, sofern Platz vorhanden ist. Ist das Deque hingegen voll, blockieren diese Methoden so lange, bis ein anderer Thread ein Element entnommen hat und somit wieder Platz für das neue Element vorhanden ist.
Die vom BlockingQueue-Interface geerbte Methode BlockingQueue.put() wird zu BlockingDeque.putLast() weitergeleitet.
BlockingQueue.offerFirst() + offerLast() mit Timeout
Auch offerFirst() und offerLast() fügen ein Element in das Deque ein, sofern Platz vorhanden ist. Andernfalls blockieren diese Methoden für maximal die angegebene Zeit. Konnte nach Ablauf dieser Zeit das Element nicht eingefügt werden, geben diese Methoden false zurück.
Die vom BlockingQueue-Interface geerbte Methode BlockingQueue.offer(E e, long timeout, TimeUnit unit) wird zu BlockingDeque.offerLast(E e, long timeout, TimeUnit unit) weitergeleitet.
Blockierende Methoden zum Entnehmen aus dem Deque
Zunächst wieder eine grafische Darstellung der blockierenden Dequeue-Methoden:
Blockierende Methoden zum Entnehmen aus einem Deque
BlockingQueue.takeFirst() + takeLast()
takeFirst() und takeLast() entnehmen ein Element vom Anfang bzw. Ende des Deques, sofern das Deque nicht leer ist. Bei einem leeren Deque blockieren diese Methoden solange, bis ein anderer Thread ein Element einfügt.
Die vom BlockingQueue-Interface geerbte Methode BlockingQueue.take() wird zu BlockingDeque.takeFirst() weitergeleitet.
BlockingQueue.pollFirst() + pollLast() mit Timeout
Auch pollFirst() und pollLast() entnehmen ein Element vom Deque, sofern eines verfügbar ist. Andernfalls warten die Methoden für die angegebene Zeit. Wenn innerhalb der Wartezeit ein Element eingefügt wird, liefern die Methoden es sofort zurück. Wenn nach Ablauf der Zeit noch immer kein Element vorhanden ist, geben diese Methoden null zurück.
Die vom BlockingQueue-Interface geerbte Methode BlockingQueue.poll(E e, long timeout, TimeUnit unit) wird zu BlockingDeque.pollFirst(E e, long timeout, TimeUnit unit) weitergeleitet.
BlockingDeque-Methoden – Zusammenfassung
Im folgenden findest du zwei Tabellen: die erste enthält die Methoden zum Einfügen und Entnehmen von Elementen am Kopf des Deques; die zweite enthält die Methoden für die Elemente am Ende des Deques.
In den ersten zwei Spalten siehst du jeweils die nicht blockierenden Methoden, die BlockingDeque von Deque (und indirekt von Queue – diese sind mit einer hochgestellten 1 markiert) erbt.
In der dritten und vierten Spalte findest du jeweils die neuen, blockierenden Methoden (einschließlich derer, die in BlockingQueue definiert sind – diese sind mit einer hochgestellten 2 markiert).
Operationen am Anfang (Kopf) des Deques
Nicht blockierend (geerbt von Deque)
Blockierend (neu in BlockingDeque)
Exception
Rückgabewert
Blockiert
Blockiert mit Timeout
Element anhängen (enqueue):
addFirst(E e)
offerFirst(E e)
putFirst(E e)
offerFirst(E e, long timeout, TimeUnit unit)
Element entnehmen (dequeue):
removeFirst()
remove()¹
pollFirst()
poll()¹
takeFirst()
take()²
pollFirst( long timeout, TimeUnit unit) poll( long timeout, TimeUnit unit)²
Element ansehen (examine):
getFirst() element()¹
peekFirst() peek()¹
–
–
Operationen am Ende des Deques
Nicht blockierend (geerbt von Deque)
Blockierend (neu in BlockingDeque)
Exception
Rückgabewert
Blockiert
Blockiert mit Timeout
Element anhängen (enqueue):
addLast(E e)
add(E e)¹
offerLast(E e)
offer(E e)¹
putLast(E e)
put(E e)²
offerLast(E e, long timeout, TimeUnit unit) offer(E e, long timeout, TimeUnit unit)²
Element entnehmen (dequeue):
removeLast()
pollLast()
takeLast()
pollLast( long timeout, TimeUnit unit)
Element ansehen (examine):
getLast()
peekLast()
–
–
¹ Diese Methoden sind im Queue-Interface implementiert und rufen die entsprechenden Deque-Methoden auf.
² Diese Methoden sind im BlockingQueue-Interface implementiert und rufen die entsprechenden BlockingDeque-Methoden auf.
Java BlockingDeque-Beispiel
Ein Beispiel für die Benutzung des BlockingDeque-Interfaces findest du im Tutorial-Teil über die einzige Implementierung dieses Interfaces: LinkedBlockingDeque.
Zusammenfassung und Ausblick
In diesem Artikel hast du das BlockingDeque-Interface und dessen blockierenden Methoden putFirst(), putLast(), offerFirst(), offerLast(), takeFirst(), takeLast(), und pollFirst(), pollLast() kennengelernt.
In den folgenden Teilen dieser Tutorialserie werde ich alle Deque– und BlockingDeque-Implementierungen mit ihren spezifischen Eigenschaften vorstellen. Am Ende findest du eine Empfehlung, wann du welche Implementierung einsetzen solltest. Zum Abschluss des Tutorials zeige ich dir, wie du selbst ein Deque in Java implementieren kannst.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Nachdem Java in Version 5 das Queue-Interface bekommen hat, kamen in Java 6 das Interface java.util.Deque und die ersten Deque-Implementierungen hinzu.¹
Die Implementierungen unterscheiden sich in diversen Eigenschaften (wie bounded/unbounded, blocking/non-blocking, threadsicher/nicht threadsicher). Auf diese Eigenschaften werde ich im Verlauf dieses Tutorials eingehen.
¹ Das stimmt nicht ganz: LinkedList, eine der Deque-Implementierungen, gibt es bereits seit Java 1.2.
Java Deque-Klassenhierarchie
Hier siehst du zunächst einen Überblick über die Deque-Interfaces und -Klassen in Form eines UML-Klassendiagramms:
Java Deque-Klassenhierarchie
Der kompletten linke Teil des Diagramms wird im Queue-Tutorial behandelt.
Du kannst jederzeit über die Navigation am rechten Rand zu den entsprechenden Teilen der Serie springen.
Java Deque-Methoden
Das Deque-Interface erbt von Queue und definiert 15 (!) zusätzliche Methoden zum Einfügen, Entnehmen und Betrachten von Elementen auf beiden Seiten des Deques (12 Deque-Methoden und 3 Stack-Methoden).
Aus Konsistenzgründen wurden die Operationen, die Deque bereits von Queue erbt, mit neuem Namen neu implementiert – beispielsweise Queue.add() als Deque.addLast() und Queue.remove() als Deque.removeFirst().
Das Deque-Interface definiert zusätzlich drei Stack-Methoden als Alternativen zu den Deque-Methoden, z. B. Deque.push() als Alternative zu Deque.addFirst(). Diese Methoden hätten eigentlich in ein Stack-Interface gehört.
All diese Queue- und Stack-Methoden habe ich im Folgenden explizit mit aufgeführt – und zwar jeweils bei den äquivalenten Deque-Methoden.
Am Ende dieses Kapitels findest du eine zusammenfassende Tabelle.
Methoden zum Einfügen in das Deque
Zum Einstieg ein grafischer Überblick aller Enqueue-Methoden:
Methoden zum Einfügen in ein Deque
Deque.addFirst() + addLast()
Diese Methoden fügen ein Element am Kopf bzw. am Ende des Deques ein. Bei Erfolg geben die Methoden true zurück. Wenn ein größenbeschränktes (bounded) Deque voll ist, werfen diese Methoden eine IllegalStateException.
Die vom Queue-Interface geerbte Methode Queue.add() wird zu Deque.addLast() weitergeleitet.
Die Deque.push()-Methode ist das Stack-Äquivalent zu Deque.addFirst().
Deque.offerFirst() + offerLast()
Auch offerFirst() und offerLast() fügen Elemente in das Deque ein und geben im Erfolgsfall true zurück. Wenn ein bounded Deque voll ist, geben diese Methoden false zurück anstatt eine IllegalStateException zu werfen.
Die vom Queue-Interface geerbte Methode Queue.offer() wird zu Deque.offerLast() weitergeleitet.
Methoden zum Entnehmen aus dem Deque
Auch für die Dequeue-Methoden zunächst ein grafischer Überblick:
Methoden zum Entfernen aus einem Deque
Deque.removeFirst() + removeLast()
Die Methoden removeFirst() und removeLast() entnehmen das Element vom Kopf bzw. Ende des Deques. Wenn das Deque leer ist, werfen sie eine NoSuchElementException.
Die vom Queue-Interface geerbte Methode Queue.remove() wird zu Deque.removeFirst() weitergeleitet.
Deque.pop() ist das Stack-Äquivalent zu Deque.removeFirst().
Deque.pollFirst() + pollLast()
pollFirst() und pollLast() entnehmen ebenfalls das Element vom Kopf bzw. Ende des Deques. Im Gegensatz zu removeFirst() und removeLast() werfen diese Methode bei einem leeren Deque keine Exception, sondern geben null zurück.
Die vom Queue-Interface geerbte Methode Queue.poll() wird zu Deque.pollFirst() weitergeleitet.
Methoden zum Betrachten des Head- bzw. Tail-Elements
Und zum Abschluss ein grafischer Überblick der Peek-Methoden:
Methoden zum Betrachten der Elemente am Anfang und Ende des Deques
Deque.getFirst() + getLast()
Die getFirst()– und getLast()-Methoden geben das Element vom Kopf bzw. Ende des Deques zurück, ohne es aus dem Deque zu entfernen. Wenn das Deque leer ist, werfen diese Methoden eine NoSuchElementException.
Die vom Queue-Interface geerbte Methode Queue.element() wird zu Deque.getFirst() weitergeleitet.
Deque.peekFirst() + peekLast()
Auch peekFirst() und peekLast() geben das Kopf- bzw. Tail-Element zurück, ohne es aus dem Deque zu entfernen. Bei einem leeren Deque werfen diese Methoden allerdings keine Exception, sondern geben null zurück.
Die vom Queue-Interface geerbte Methode Queue.peek() wird zu Deque.peekFirst() weitergeleitet. peek() ist ebenfalls das Stack-Äquivalent zu peekFirst().
Deque-Methoden – Zusammenfassung
Die folgende Tabelle zeigt noch einmal alle zwölf Deque-Methoden, die drei Stack-Methoden und die weitergeleiteten Queue-Methoden gruppiert nach Operation, Seite des Deques und Art der Fehlerbehandlung:
Kopf des Deques
Tail des Deques
Exception
Rückgabewert
Exception
Rückgabewert
Element anhängen (enqueue):
addFirst(E e)
push(E e)²
offerFirst(E e)
addLast(E e) add(E e)¹
offerLast(E e) offer(E e)¹
Element entnehmen (dequeue):
removeFirst() remove()¹ pop()²
pollFirst() poll()¹
removeLast()
pollLast()
Element ansehen (examine):
getFirst() element()¹
peekFirst() peek()¹ ²
getLast()
peekLast()
¹ Diese Methoden sind im Queue-Interface implementiert und rufen die entsprechenden Deque-Methoden auf.
² Diese Stack-Methoden sind zusätzlich im Deque-Interface definiert. Das JDK enthält leider kein Stack-Interface.
Wie erzeugt man ein Deque?
Das Interface java.util.Deque kann nicht direkt instatiiert werden. Ein Interface beschreibt lediglich, welche Methoden eine Klasse implementieren muss, die dieses Interface implementiert.
Es muss also eine konkreten Deque-Implementierungen ausgewählt werden, z. B. ein ArrayDeque:
Deque<Integer> deque = new ArrayDeque<>();Code-Sprache:Java(java)
Die konkreten, vom JDK angebotenen Deque-Klassen werden in den folgenden Teilen des Tutorials – mit Erklärung ihrer Eigenschaften – vorgestellt:
Das folgende Java-Code-Beispiel erzeugt genau das Deque, das ich am Anfang des Artikels grafisch dargestellt habe. Danach werden die Elemente wieder entnommen.
Du findest den Code auch in der Klasse JavaDequeDemo im GitHub-Repository des Tutorials.
Das Programm macht das Folgende (die Nummern verweisen auf die Quellcode-Kommentare):
Es erstellt ein Deque. Welches du benutzt, ist für dieses Beispiel unwichtig, da die spezifischen Deque-Eigenschaften für dieses Beispiel irrelevant sind.
Es schreibt mit offerFirst() und offerLast() einige Werte in das Deque.
Wir geben mit isEmpty(), peekFirst() und peekLast() den Zustand des Deques aus.
Wir entnehmen abwechselnd vom Kopf und vom Ende des Deques Elemente und geben diese aus – solange, bis das Deque leer ist.
Abschließend schauen wir uns noch einmal den Zustand des Deques an.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Tutorial lernst du alles über die Datenstruktur „Deque“ (ausgesprochen „Deck“):
Was ist ein Deque?
Welche Operationen bietet ein Deque an?
Was sind die Anwendungsgebiete für Deques?
Welche Deque-Interfaces und -Klassen liefert das JDK?
Welches Deque-Implementierung sollte man für welche Einsatzzwecke verwenden?
Wie implementiert man ein Deque selbst in Java?
Was ist ein Deque?
Ein Deque ist eine Liste von Elementen, bei der die Elemente sowohl auf der einen als auch auf der anderen Seite eingefügt und entnommen werden können. Deque steht für „Double-ended Queue“, also für eine Queue mit zwei Enden:
Deque-Datenstruktur
Ein Deque kann sowohl als Queue als auch als Stack eingesetzt werden:
Als Queue (FIFO, first-in-first-out), indem Elemente auf einer Seite eingefügt und auf der anderen Seite wieder entnommen werden.
Als Stack (LIFO, last-in-first-out), indem Elemente an derselben Seite eingefügt und wieder entnommen werden.
Wir müssen uns beim Deque aber nicht auf FIFO- oder LIFO-Funktionalität beschränken. Wir können die Elemente jederzeit an einer beliebigen Seiten einfügen und wieder entnehmen.
Deque-Operationen
Die Operationen des Deques lauten analog zur Queue auf beiden Seiten „Enqueue“ und „Dequeue“:
„Enqueue at front“: Anhängen von Elementen an den Kopf des Deques
„Enqueue at back“: Anhängen von Elementen an das Ende des Deques
„Dequeue at front“: Entnehmen von Elementen vom Kopf des Deques
„Dequeue at back“: Entnehmen von Elementen vom Ende des Deques
(So wie bei der Queue werden auch beim Deque die entsprechenden Methoden der Java-Implementierungen anders bezeichnet; dazu mehr im nächsten Teil des Tutorials, „Java Deque-Interface„.)
Anwendungsgebiete für Deqeues
Das klassische Anwendungsgebiet für Deques ist eine Undo-Liste. Jeder ausgeführte Bearbeitungsschritt wird auf das Deque gelegt. Beim Aufruf der „Undo“-Funktion wird die zuletzt auf das Deque gelegte Bearbeitung entnommen und wieder rückgängig gemacht.
Bis hierhin ist das ein klassisches LIFO-Prinzip, könnte also auch mit einem Stack realisiert werden.
Aus Speichergründen sollten wir die Undo-Historie allerdings limitieren, z. B. auf 100 Einträge. Bei Verwendung eines Stacks würden die ältesten Elemente am Boden des Stacks liegen und könnten dort nicht entfernt werden. Bei einem Deque stellt das jedoch kein Problem dar, da Elemente an beiden Seiten entnommen werden können.
Deques werden in der Regel mit Arrays oder verketteten Listen implementiert. In beiden Fällen ist der Aufwand für das Einfügen und Entnehmen von Elementen auf beiden Seiten unabhängig von der Länge des Deques, also konstant.
Die Zeitkomplexität dieser Operationen beträgt somit: O(1)
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Arrays und verkettete Listen (Linked Lists) sind Datenstrukturen, die Elemente eines bestimmten Typs sequentiell anordnen.
Allerdings gibt es große Unterschiede, und abhängig von den Anforderungen hat die Auswahl der Datenstruktur einen erheblichen Einfluss auf den Speicherbedarf und die Performance der Anwendung.
Dieser Artikel beantwortet die folgenden Fragen:
Was sind die Unterschiede zwischen Array und Linked List?
Was sie die Vor- und Nachteile der jeweils einen Datenstruktur gegenüber der anderen?
Welche Zeitkomplexität haben die verschiedenen Operationen (wie Zugriff auf ein Element, Einfügen, Entfernen, Bestimmen der Größe)?
Wann solltest du welche Datenstruktur verwenden?
Beginnen wir mit einem Vergleich beider Datenstrukturen…
Unterschied zwischen Array und Linked List
Die folgende Grafik zeigt den grundsätzlichen Aufbau beider Datenstrukturen, wobei ich die verkettete Liste sowohl als einfach als auch als doppelt verkettete Liste dargestellt habe:
Array – Singly Linked List – Doubly Linked List
Ein Array ist ein zusammenhängender Speicherblock, der die Datenelemente¹ direkt enthält.
Eine verkettete Liste besteht aus Listenknoten, die jeweils ein Datenelement¹ enthalten sowie eine Referenz auf den nächsten Knoten (und – bei einer doppelt verketteten Liste – auf den vorherigen Knoten).
Die folgenden Abschnitte vergleichen die Konsequenzen, die sich aus dem Aufbau der beiden Datenstrukturen ergeben, in Bezug auf den Aufwand beim Einfügen und Entfernen von Elementen, den benötigten Speicherplatz und den Lokalitätseffekt (was das bedeutet, erkläre ich im entsprechenden Abschnitt).
¹ Ein Datenelement kann ein primitives Element sein, z. B. ein int, double oder char, oder eine Referenz auf ein Objekt.
Array vs. Linked List: Zeitkomplexität
Beginnen wir mit dem Aufwand für die verschiedenen Operationen.
Zugriff auf ein bestimmtes Element („Random Access“)
Bei einem Array können wir jedes Element direkt adressieren. Es macht vom Aufwand her keinen Unterschied, wie lang das Array ist oder an welcher Position wir ein Element lesen oder schreiben.
Im Array-Beispiel macht es keinen Unterschied, ob wir auf das „a“ oder das „p“ zugreifen:
Zugriff auf ein bestimmtes Element („Random Access“) eines Arrays
Der Aufwand ist also konstant. Die Zeitkomplexität für den (schreibenden oder lesenden) Zugriff auf ein bestimmtes Elements eines Array beträgt somit: O(1)
Bei einer verketteten Liste hingegen können wir nur auf das erste Element direkt zugreifen. Für alle anderen müssen wir der Liste Knoten für Knoten folgen, bis wir das gewünschte Element erreicht haben.
Im Linked-List-Beispiel benötigen wir mehr Schritte, um das „p“ zu erreichen als um das „a“ zu erreichen:
Zugriff auf ein bestimmtes Element („Random Access“) einer verketteten Liste
Bei einem zufällig verteilten Zugriff auf die Elemente ist der mittlere Aufwand proportional zur Länge der Liste. Die Zeitkomplexität beträgt also: O(n)
Hinzufügen oder Entfernen eines Elements
Bei einer Linked List können wir an jeder beliebigen Stelle Knoten einfügen und entfernen. Der Aufwand dafür ist immer gleich, unabhängig davon, wie lang die Liste ist und an welcher Position wir einfügen (vorausgesetzt, wir haben eine Referenz auf den Knoten, an dem wir einfügen/entfernen wollen).
Element in eine Linked List einfügen: O(1)
Die Zeitkomplexität für das Einfügen in und Entfernen aus einer verketteten Liste lautet also: O(1)
Ein Array kann seine Größe nicht ändern. Um ein Element einzufügen oder zu entfernen müssen wir das Array immer in ein neues, größeres oder kleineres Array umkopieren:
Element in ein Array einfügen: O(n)
Der Aufwand dafür ist proportional zur Länge des Arrays. Die Zeitkomplexität lautet somit: O(n)
Datenstrukturen wie z. B. Javas ArrayList haben eine Strategie zur Verringerung der durchschnittlichen Zeitkomplexität beim Einfügen und Entfernen von Elementen: Indem sie im Array Platz für neue Elemente reservieren, sowohl beim Anlegen als auch beim Vergrößern, können sie die Zeitkomplexität – zumindest für das Einfügen und Entfernen am Ende einer Array-basierten Datenstruktur – auf O(1) reduzieren.
Mit einem Ringbuffer (englisch: „circular array“) können wir auch die Zeitkomplexität für das Einfügen und Entfernen am Anfang einer array-basierten Datenstruktur auf O(1) reduzieren. So wird z. B. das Java ArrayDeque realisiert.
Größenbestimmung
Die Größe eines Arrays ist bekannt und kann z. B. in Java über array.length abgefragt werden. Der Aufwand dafür ist unabhängig von der Länge des Arrays, also konstant.
Die Zeitkomplexität für die Bestimmung der Länge eines Arrays lautet somit: O(1)
Bei einer verketteten Liste hingegeben müssen wir die gesamte Liste ablaufen und die Listenknoten zählen. Je länger die Liste, desto länger dauert das Zählen.
Die Zeitkomplexität für die Bestimmung der Länge einer Linked List lautet somit: O(n)
Einige auf verketteten Listen basierende Datenstrukturen (z. B. die Java LinkedList) speichern die Größe zusätzlich in einem Feld ab, das sie beim Einfügen und Entfernen aktualisieren – so kann auch die Größe solcher Datenstrukturen mit konstantem Aufwand, also O(1), abgefragt werden.
Übersicht Zeitkomplexität
Die folgende Tabelle fasst die Zeitkomplexitäten der verschiedenen Operationen zusammen:
Operation
Array
Linked List
Zugriff auf das n-te Element:
O(1)
O(n)
Einfügen eines Elements:
O(n)
O(1)
Entfernen eines Elements:
O(n)
O(1)
Bestimmung der Länge:
O(1)
O(n)
Der Zugriff auf ein Element (lesend oder schreibend) und die Längenbestimmung sind also bei einem Array günstiger – Einfügen und Entfernen hingegen bei einer Linked List.
Array vs. Linked List: Speicherverbrauch
Bei einem Array benötigt jedes Feld so viel Speicherplatz wie der darin enthaltene Datentyp. Ein Array mit int-Primitiven beispielsweise benötigt 4 Byte pro Eintrag:
Speicherverbrauch eines int-Arrays: 4 Byte pro Eintrag
Bei einer verketteten Liste hingegen müssen für jeden Knoten sowohl das Datenelement als auch Referenzen auf Nachfolger- und ggf. Vorgängerknoten gespeichert werden.
Bleiben wir bei den int-Primitiven und gehen wir von 4 Byte¹ pro Referenz aus, dann kommen wir bei einer einfach verketteten Liste auf 8 Byte pro Element.
Bei JVM-Sprachen kommen allerdings pro Knoten noch 12 Byte für den Header des Knotenobjekts hinzu – sowie 4 Füllbytes, da Objekte ein Vielfaches von 8 Bytes an Speicher belegen müssen.¹ Insgesamt benötigen wir also 24 Byte pro Listenknoten.
Speicherverbrauch einer einfach verketteten Liste in Java: 24 Byte pro Knoten
Bei einer doppelt verketteten Liste benötigen wir eine weitere Referenz, wir kommen also auf 12 Byte pro Eintrag.
Bei JVM-basierten Sprachen kommen die 12 Byte für den Objekt-Header hinzu. Insgesamt bleibt es aber bei 24 Byte, da die zusätzlichen vier Bytes den Platz einnehmen, den vorher die Füllbytes belegt haben.
Speicherverbrauch einer doppelt verketteten Liste in Java: 24 Byte pro Knoten
Die folgende Tabelle zeigt den Speicherbedarf pro Feld für ein Array und eine Linked List – jeweils für C/C++ und JVM-basierte Sprachen:
Sprache
Array
Einfach verkettete Liste
Doppelt verkettete Liste
C/C++:
4 Bytes
8 Bytes
12 Bytes
JVM-Sprache:
4 Bytes
24 Bytes¹
24 Bytes¹
Bis hierhin spricht der Speicherverbrauch für das Array – ganz besonders in Java.
So eindeutig fällt der Vergleich allerdings nur aus, wenn wir die Größe der Datenstruktur vorab kennen und sie sich nicht ändert.
Bei einer Array-basierten Datenstruktur, deren Größe sich ändern kann, z. B. der Java ArrayList, wird – wie oben erwähnt – meist eine Reserve für neue Elemente freigehalten. Bei einer verketteten Liste hingegen wird erst dann, wenn ein Element eingefügt wird, der Speicher für dieses Element – und nur für dieses Element – allokiert.
Array vs. Linked List: Speichereffizienz
Analoges gilt für das Entfernen von Elementen. Bei einer Array-basierten Datenstruktur wird das Feld in der Regel für zukünftige Einfügeoperationen freigelassen. Bei einer Linked List wird es sofort gelöscht (bzw. für das Löschen durch den Garbage Collector freigegeben).
Linked Lists sind also speichereffizienter als Arrays.
Zusammengefasst: bei gleicher Länge benötigt eine Linked List mindestens doppelt so viel Speicherplatz wie ein Array – in Java sogar das Sechsfache! Bei variierender Länge kann eine Array-basierte Datenstruktur jedoch ungenutzten Speicherplatz blockieren, so dass diese beiden Faktoren gegeneinander abgewägt werden müssen.
Array vs. Linked List: Lokalitätseffekt
Um die Frage „Was ist schneller – ein Array oder eine Linked List?“ zu beantworten, müssen wir noch einen weiteren Faktor berücksichtigen: den Lokalitätseffekt.
Da der Speicher für ein Array am Stück allokiert wird, liegen dessen Elemente an aufeinanderfolgenden Speicheradressen. Beim Zugriff auf den Hauptspeicher werden alle Array-Elemente, die auf derselben Memory Page liegen, gleichzeitig in den CPU-Cache geladen. Sobald wir auf ein Array-Element zugegriffen haben, können wir also sehr schnell auf die benachbarten Elemente zugreifen.
Die Knoten einer verketteten Listen hingegen werden an beliebigen Stellen im Speicher allokiert, können also über den gesamten Speicher verteilt sein. Beim Traversieren einer verketteten Liste müsste also im worst case für jedes Element eine neue Memory Page geladen werden.
Vorteile der Linked List gegenüber dem Array
In diesem und dem nächsten Abschnitt fasse ich die Vor- und Nachteile von Array und Linked List noch einmal zusammen.
Warum ist eine Linked List besser als ein Array?
Elemente können mit konstantem Aufwand eingefügt und entfernt werden.
Die Linked List belegt keinen ungenutzten Speicher.
Vorteile des Arrays gegenüber der Linked List
Und wann ist ein Array besser als eine Linked List?
Wir können auf jedes beliebige Element des Arrays („random access“) in konstanter Zeit zugreifen.
Wir können ein Array von hinten nach vorne traversieren – das ist bei einer einfach verketteten Liste nicht möglich, nur bei einer doppelt verketteten.
Ein Array belegt – bei gleicher Anzahl Elemente – deutlich weniger Speicher als eine verkettete Liste (C/C++: Faktor 2–3; Java: Faktor 6).
Durch den Lokalitätseffekt können wir bei einem Array auf nah nebeneinander liegende Elemente deutlich schneller zugreifen.
Der Garbage Collector kann bei einem Array eine Reachability-Analyse deutlich schneller durchführen als bei einer Linked List.
Beim Löschen eines Arrays wird ein zusammenhängender Speicherbereich freigegeben, während das Löschen einer verketteten Liste einen fragmentierten Speicher zurücklässt.
Fazit: Wann ein Array benutzen und wann eine Linked List?
Die Frage „Welche Datenstruktur ist besser – Array oder Linked List?“ lässt sich, wie so vieles, nur mit einem „Es kommt darauf an“ beantworten.
Wenn oft Elemente in der Mitte der Datenstruktur eingefügt oder entfernt werden, dann sollte eine verkettete Liste die bessere Wahl sein.
Für alle anderen Anwendungsfälle liefern in der Regel Array-basierte Datenstrukturen eine bessere Performance und einen besseren Memory Footprint und sollten daher bevorzugt eingesetzt werden.
Wenn du vermutest, dass für deinen Einsatzzweck eine Linked List besser geeignet ist, dann probier es einfach aus. Führe Messungen durch, und entscheide dich basierend auf den Messergebnissen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im vorherigen Teil der Tutorialserie haben wir eine Queue mit einem Array implementiert. In diesem letzten Teil der Serie zeige ich dir, wie du eine Priority Queue implementierst – und zwar mit Hilfe eines Heaps.
Zur Erinnerung: Bei einer Priority Queue werden die Elemente nicht in FIFO-Reihenfolge entnommen, sondern entsprechend ihrer Priorität. Das Element mit der höchsten Priorität steht immer am Kopf der Queue und wird zuerst entnommen – unabhängig davon, wann es in die Queue eingefügt wurde.
Was ist ein Heap?
Ein „Heap“ ist einen Binärbaum, in dem jeder Knoten entweder größer/gleich seiner Kinder ist („Max Heap“) – oder kleiner/gleich seiner Kinder („Min-Heap“).
Für die Priority Queue in diesem Artikel verwenden wir einen Min-Heap, da die höchste Priorität diejenige mit der niedrigsten Zahl ist (Prio 1 ist in der Regel höher als Prio 2).
Hier ist ein Beispiel, wie so ein Min-Heap aussehen könnte:
Min-Heap-Beispiel
Das Element an jedem Knoten dieses Baums ist kleiner als die Elemente seiner beiden Kindknoten:
1 ist kleiner als 2 und 4;
2 ist kleiner als 3 und 7;
4 ist kleiner als 9 und 6;
3 ist kleiner als 8 und 5.
Array-Darstellung eines Heaps
Ein Heap können wir in einem Array speichern, indem wir dessen Elemente zeilenweise – von links oben nach rechts unten – auf das Array abbilden:
Abbildung eines Min-Heaps auf ein Array
Unser Beispiel-Heap sieht als Array wie folgt aus:
Array-Repräsentation des Min-Heaps
Bei einem Min-Heap ist das kleinste Element immer oben, im Array also immer an erster Position. Genau deshalb siehst du, wenn du eine Java-PriorityQueue als String ausgibst, immer das kleinste Element links. Was du siehst, ist die Array-Darstellung des der PriorityQueue zugrunde liegenden Min-Heaps.
Mit den folgenden Codezeilen lässt sich das gut demonstrieren:
Das kleinste Element ist ganz links. Und wenn du genau hinschaust, erkennst du, dass die Zahlen exakt die gleiche Reihenfolge haben wie in der grafischen Array-Darstellung oben. Der Min-Heap der im Beispiel erstellten PriorityQueue ist genau der, den ich zu Beginn des Artikels abgebildet habe.
Priority Queue mit einem Min-Heap – Der Algorithmus
OK, das kleinste Element steht immer ganz links. Damit ist schon mal klar, wie die peek()-Operation zu funktionieren hat: sie muss einfach das erste Element des Arrays zurückgeben.
Doch wie wird so ein Heap aufgebaut? Wie funktionieren enqueue() und dequeue()?
Einfügen in den Min-Heap: Sift Up
Um ein Element in einen Heap einzufügen, gehen wir wie folgt vor:
Wir fügen das neue Element als letztes Element in den Baums ein, d. h.:
Ist der Baum leer, fügen wir das neue Element als Wurzel ein.
Wenn die unterste Ebene des Baums nicht voll ist, fügen wir das neue Element neben dem letzen Knoten der untersten Ebene ein.
Ist die unterste Ebene voll, dann hängen wir den Knoten unter den ersten Knoten der untersten Ebene.
Solange der Elternknoten des neuen Elements kleiner ist als das Element selbst (was die Min-Heap Regel verletzten würde), vertauschen wir den neuen Knoten mit seinem Elternknoten.
Schritt 1 hört sich kompliziert an, bedeutet in der Array-Darstellung aber lediglich, dass das neue Element an die erste freie Stelle des Arrays gesetzt wird. Schritt 2 sorgt dafür, dass am Ende der Operation wieder jedes Element kleiner ist als seine Kinder.
Das Beispiel im folgenden Abschnitt demonstriert die beiden Schritte.
Einfügen in den Min-Heap: Beispiel
An den folgenden Beispielen zeige ich dir Schritt für Schritt, wie eine auf einem Min-Heap basierende Priority Queue mit den oben gezeigten Beispielwerten (4, 7, 3, 8, 2, 9, 6, 5, 1) gefüllt wird. In jedem Schritt zeige ich den Min-Heap jeweils in Baum- und in Array-Darstellung.
1. Element – Einfügen der 4 in eine leere Priority Queue
Das erste einzufügende Element wird zum Wurzelknoten des Baumes; im Array wird es an die erste Position gesetzt:
2. Element – Einfügen der 7
Die 7 wird unter den ersten Knoten der untersten Ebene eingehängt – also links unter die Wurzel. Im Array wird sie einfach angehängt:
Die 7 ist größer als ihr Elternknoten 4 – damit ist die Einfügeoperation abgeschlossen. Das kleinste Element steht nach wie vor am Anfang der Priority Queue.
3. Element – Einfügen der 3
Die 3 wird neben dem letzten Knoten der untersten Ebene, also rechts unter der 4, angehängt. Im Array kommt sie ans Ende:
Die 3 ist kleiner als ihr Elternknoten. Die Regeln des Min-Heaps sind also verletzt. Wir stellen den Min-Heap wieder her, in dem wir die 3 mit der 4 tauschen:
Damit haben wir wieder einen validen Min-Heap.
Wir überspringen die 8, 2, 9, 6 und 5 (diese werden analog eingefügt) und kommen zum…
9. Element – Einfügen der 1
Zuletzt fügen wir die 1 am Ende der Queue (und des Arrays) ein:
Die 1 ist größer als ihr Elternknoten 5; unser Baum ist also kein gültiger Min-Heap mehr. Um ihn zu reparieren, tauschen wir zunächst die 1 mit der 5:
Die 1 ist ebenfalls größer als ihr neuer Elternknoten 3; somit tauschen wir erneut:
Die 1 ist auch größer als die Wurzel 2, also tauschen wir ein drittes Mal:
Da die 1 nun an der Wurzel angelangt ist, ist die Operation beendet. Der Baum ist wieder ein Min-Heap. Das kleinste Element steht an der Wurzel des Baumes (und am Anfang des Arrays).
Dieses Hochreichen des eingefügten Elements auf die eben gezeigte Weise bezeichnet man als „Sift Up“.
Vereinfachter Sift-Up-Algorithmus
Tatsächlich brauchen wir uns gar nicht die Mühe zu machen das neue Element am Ende einzufügen, um es dann schrittweise mit seinem Elternknoten zu tauschen. Stattdessen können wir uns das neue Element merken, die größeren Elternelemente nach unten schieben und zum Schluss das neue Element direkt an seine Zielposition setzen.
Die folgenden Grafiken zeigen das Einfügen der 1 nach dem vereinfachten Algorithmus.
Die 1 ist kleiner als der Elternknoten des freien Knotens. Wir schieben daher die 5 in den freien Knoten:
Die einzufügende 1 ist ebenso kleiner als die 3; wir schieben die 3 nach unten:
Die 1 ist kleiner als die 2; wir schieben auch die 2 nach unten:
Wir können keine weiteren Elemente nach unten schieben und setzen das einzufügende Element, die 1, auf den freigewordenen Wurzelknoten (oder das erste Feld des Arrays):
Damit ist die Sift-Up-Operation abgeschlossen.
Das Einfügen eines Elements in die Priority Queue (bzw. in den Min-Heap) mag beim ersten Durchlesen sehr komplex erscheinen. Falls du es nicht verstanden hast, mach eine kurze Pause und wiederhole das Kapitel noch einmal, bevor du zur Dequeue-Operation fortschreitest.
Entnahme aus dem Min-Heap: Sift Down
Wir wissen, dass das kleinste Element immer an der Wurzel des Baumes steht (oder am Anfang des Arrays).
Um es zu entnehmen, gehen wir wie folgt vor:
Wir entfernen das Wurzelelement aus dem Baum.
Wir verschieben den letzten Knoten der letzten Ebene des Baumes (das entspricht dem letzten Element des Arrays) an die freigewordene Wurzelposition.
Solange dieser Knoten größer ist als eines seiner Kinder (was die Min-Heap Regel verletzten würde), vertauschen wir den Knoten mit seinem kleinsten Kindknoten.
Entnahme aus dem Min-Heap: Beispiel
Das folgende Beispiel zeigt, wie wir das Wurzelelement des im letzten Kapitel gefüllten Min-Heaps entnehmen und danach die Min-Heap-Bedingung wiederherstellen.
Als erstes entnehmen wir das Wurzelelement:
Als zweites verschieben wir das letzte Element des Baumes, die 5, an die frei gewordene Wurzel:
Da das neue Wurzelelement, die 5, jetzt größer ist als das kleinste seiner Kinder, die 2, vertauschen wir diese beiden Elemente:
Die 5 ist weiterhin größer als das kleinste ihrer Kinder, die 3. Wir tauschen ein zweites Mal:
Die 5 ist jetzt größer als ihr einziges Kind; die Min-Heap-Bedingung ist damit wiederhergestellt.
An der Wurzel des Min-Heaps (bzw. am Anfang des Arrays) befindet sich jetzt die 2, das neue kleinste Element nach Entnahme der 1.
Das Herunterwandern des an die Wurzel verschobenen Elements bezeichnet man als „Sift Down“.
Vereinfachter Sift-Down-Algorithmus
Auch den Sift-Down-Algorithmus können wir vereinfachen. Wir müssen das letzte Element (im Beispiel die 5) nicht erst an die Wurzel schieben, um es dann schrittweise mit seinen Kindern zu tauschen. Wir können auch zuerst die größeren Elemente nach oben schieben und am Ende das letzte Element direkt an seine endgültige Position verschieben.
Die folgenden Grafiken zeigen das Herunterreichen der 5 (oder besser gesagt: des freien Feldes, auf das am Ende die 5 gesetzt wird) nach dem vereinfachten Algorithmus.
Die 5 ist größer als der kleinste Kindknoten der leeren Wurzel, die 2. Wir schieben die 2 nach oben:
Die 5 ist ebenso größer als das kleinste Kind des jetzt freien Platzes, die 3. Wir schieben auch die 3 nach oben:
Die 5 ist nicht größer als das einzige Kind des jetzt freien Platzes, die 8. Wir haben also das Zielfeld für die 5 gefunden und schieben die 5 dorthin:
Wir haben die Min-Heap-Bedingung wiederhergestellt.
Die Sift-Up- und Sift-Down-Operationen mögen komplex erscheinen, sie können allerdings beide mit maximal 10 Zeilen Java-Code implementiert werden. Wie, erfährst du im nächsten Kapitel.
Quellcode für Priority Queue mit Min-Heap
Der folgende Quellcode zeigt, wie man eine Priority Queue mit einem Min-Heap implementiert (Klasse HeapPriorityQueue im GitHub-Repository). Aufgrund der Länge der Klasse zeige ich sie im Folgenden abschnittsweise.
Konstruktoren
Es gibt zwei Konstrukturen: einen, bei dem man die initiale Größe des Arrays angeben kann und einen Default-Konstruktor, der die initiale Kapazität auf zehn setzt:
publicclassHeapPriorityQueue<EextendsComparable<? superE>> implementsQueue<E> {
privatestaticfinalint DEFAULT_INITIAL_CAPACITY = 10;
privatestaticfinalint ROOT_INDEX = 0;
private Object[] elements;
privateint numberOfElements;
publicHeapPriorityQueue(){
this(DEFAULT_INITIAL_CAPACITY);
}
publicHeapPriorityQueue(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
Code-Sprache:Java(java)
enqueue()
Die enqueue()-Methode prüft zunächst, ob das Array voll ist. Ist das der Fall, ruft sie die grow()-Methode auf, welche das Array in ein neues, größeres Array kopiert:
@Overridepublicvoidenqueue(E newElement){
if (numberOfElements == elements.length) {
grow();
}
siftUp(newElement);
numberOfElements++;
}
privatevoidgrow(){
int newCapacity = elements.length + elements.length / 2;
elements = Arrays.copyOf(elements, newCapacity);
}Code-Sprache:Java(java)
Die grow()-Methode habe ich hier stark vereinfacht dargestellt, da der Fokus auf den siftUp()– und siftDown()-Methoden liegen soll.
In der HeapPriorityQueue-Klasse im GitHub-Repository vergrößert die grow()-Methode das Array bis zu einer bestimmten Größe (64 Elemente) um Faktor 2 und erst danach um Faktor 1,5. Außerdem wird dort sichergestellt, dass eine bestimmte Maximalgröße nicht überschritten wird.
Wenn wir sichergestellt haben, dass das Array groß genug ist, rufen wir die siftUp()-Methode auf:
siftUp()
privatevoidsiftUp(E newElement){
int insertIndex = numberOfElements;
while (isNotRoot(insertIndex) && isParentGreater(insertIndex, newElement)) {
copyParentDownTo(insertIndex);
insertIndex = parentOf(insertIndex);
}
elements[insertIndex] = newElement;
}
privatebooleanisNotRoot(int index){
return index != ROOT_INDEX;
}
privatebooleanisParentGreater(int insertIndex, E element){
int parentIndex = parentOf(insertIndex);
E parent = elementAt(parentIndex);
return parent.compareTo(element) > 0;
}
privatevoidcopyParentDownTo(int insertIndex){
int parentIndex = parentOf(insertIndex);
elements[insertIndex] = elements[parentIndex];
}
privateintparentOf(int index){
return (index - 1) / 2;
}
Code-Sprache:Java(java)
Beachte, dass ich versucht habe den Algorithmus so verständlich wie möglich (und nicht so performant wie möglich) zu implementieren. Die parentOf()-Methode wird in jeder Iteration drei Mal aufgerufen: einmal von isParentGreater(), einmal von copyParentDownTo() und einmal direkt.
Eine verbesserten Variante (Klasse OptimizedHeapPriorityQueue im GitHub-Repo, ab Zeile 74) zeigt einen optimierten Algorithmus, der den Elternindex nur ein Mal berechnet.
dequeue()
Die dequeue()-Methode entnimmt das Kopf-Element, entfernt das letzte Element und ruft dann siftDown() auf, das letztendlich dieses letzte Element an seine neue Position verschiebt.
@Overridepublic E dequeue(){
E result = elementAtHead();
E lastElement = removeLastElement();
siftDown(lastElement);
return result;
}
private E removeLastElement(){
numberOfElements--;
E lastElement = elementAt(numberOfElements);
elements[numberOfElements] = null;
return lastElement;
}
Code-Sprache:Java(java)
siftDown()
siftDown() ist die komplizierteste Methode, da sie einen Knoten immer mit ggf. zwei Kindknoten vergleichen muss.
privatevoidsiftDown(E lastElement){
int lastElementInsertIndex = ROOT_INDEX;
while (isGreaterThanAnyChild(lastElement, lastElementInsertIndex)) {
moveSmallestChildUpTo(lastElementInsertIndex);
lastElementInsertIndex = smallestChildOf(lastElementInsertIndex);
}
elements[lastElementInsertIndex] = lastElement;
}
privatebooleanisGreaterThanAnyChild(E element, int parentIndex){
E leftChild = leftChildOf(parentIndex);
E rightChild = rightChildOf(parentIndex);
return leftChild != null && element.compareTo(leftChild) > 0
|| rightChild != null && element.compareTo(rightChild) > 0;
}
private E leftChildOf(int parentIndex){
int leftChildIndex = leftChildIndexOf(parentIndex);
return exists(leftChildIndex) ? elementAt(leftChildIndex) : null;
}
privateintleftChildIndexOf(int parentIndex){
return2 * parentIndex + 1;
}
private E rightChildOf(int parentIndex){
int rightChildIndex = rightChildIndexOf(parentIndex);
return exists(rightChildIndex) ? elementAt(rightChildIndex) : null;
}
privateintrightChildIndexOf(int parentIndex){
return2 * parentIndex + 2;
}
privatebooleanexists(int index){
return index < numberOfElements;
}
privatevoidmoveSmallestChildUpTo(int parentIndex){
int smallestChildIndex = smallestChildOf(parentIndex);
elements[parentIndex] = elements[smallestChildIndex];
}
privateintsmallestChildOf(int parentIndex){
int leftChildIndex = leftChildIndexOf(parentIndex);
int rightChildIndex = rightChildIndexOf(parentIndex);
if (!exists(rightChildIndex)) {
return leftChildIndex;
}
return smallerOf(leftChildIndex, rightChildIndex);
}
privateintsmallerOf(int leftChildIndex, int rightChildIndex){
E leftChild = elementAt(leftChildIndex);
E rightChild = elementAt(rightChildIndex);
return leftChild.compareTo(rightChild) < 0 ? leftChildIndex : rightChildIndex;
}
Code-Sprache:Java(java)
Genau wie siftUp() habe ich auch siftDown() mit Fokus auf Lesbarkeit geschrieben, nicht auf Performance. So werden hier pro Iteration drei Mal die Positionen der Kindelemente berechnet: in isGreaterThanAnyChild(), in moveSmallestChildUpTo() und noch einmal in smallestChildOf().
In der optimierten Klasse OptimizedHeapPriorityQueue werden diese Positionen nur einmal berechnet. Dadurch ist der Code aber auch nicht mehr ganz so leicht zu lesen.
peek(), isEmpty() und zwei Hilfsmethoden
Und zum Schluss noch die peek()– und isEmpty()-Methoden sowie zwei Hilfsmethoden, die verwendet werden, um das Element vom Kopf der Queue oder von einer spezifischen Position zu lesen.
Da wir die Elemente in einem Object-Array speichern, müssen die Array-Elemente nach E gecastet werden. Damit die Casts nicht über den gesamten Quellcode verteilt sind, habe ich das Casten in eine zentrale Stelle, die Methode elementAt(), ausgelagert und dort die „unchecked“-Warnung einmalig unterdrückt.
@Overridepublic E peek(){
return elementAtHead();
}
private E elementAtHead(){
E element = elementAt(0);
if (element == null) {
thrownew NoSuchElementException();
}
return element;
}
private E elementAt(int child){
@SuppressWarnings("unchecked")
E element = (E) elements[child];
return element;
}
@OverridepublicbooleanisEmpty(){
return numberOfElements == 0;
}
}Code-Sprache:Java(java)
Wenn dir der Kopf noch nicht raucht, schau dir auch gerne einmal den Quellcode der PriorityQueue-Klasse des JDK an. Diese kann Elemente nicht nur nach ihrer natürlichen Ordnung sortieren, sondern auch anhand eines dem Konstruktor übergebenen Comparators.
Fazit
Damit endet diese Tutorial-Serie über Queues. In dieser Serie hast du gelernt, wie eine Queue funktioniert, was bounded und unbounded, blocking und non-blocking Queues sind, welche Queue-Implementierungen es im JDK gibt und wie man Queues auf verschiedene Arten selbst implementieren kann.
Wenn dir die Serie gefallen hat, hinterlasse mir gerne einen Kommantar oder teile die Artikel über die Share-Buttons am Ende. Wenn du noch Fragen hast, kannst du sie gerne über die Kommentar-Funktion stellen.
Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im letzten Teil der Tutorialserie ging es darum, wie man eine Queue mit einer verketteten Liste implementiert. In diesem Teil implementieren wir eine Queue mit einem Array – zunächst eine bounded Queue (also eine mit fester Kapazität) – und dann eine unbounded Queue (also eine, deren Kapazität sich ändern kann).
Beginnen wir mit der einfachen Variante, der bounded Queue.
Implementierung einer bounded Queue mit einem Array
Wir legen ein leeres Array an und füllen dieses von links nach rechts (also von Index 0 an aufsteigend) mit den in die Queue eingefügten Elementen.
Die folgende Grafik zeigt eine Queue mit einem Array namens elements, das acht Elemente fassen kann. Bisher wurden sechs Elemente in die Queue eingefügt. Der tailIndex zeigt immer die nächste Einfügeposition:
Queue mit einem Array implementieren
Beim Entnehmen der Elemente lesen wir diese ebenfalls von links nach rechts aus und entfernen sie aus dem Array. Der headIndex zeigt dabei immer die nächste Leseposition.
Die folgende Darstellung zeigt die Queue, nachdem wir vier der sechs Elemente wieder entnommen haben:
Queue mit einem Array implementiert: Array in der Mitte gefüllt
Da wir nun kurz vor dem Ende des Arrays angekommen sind, könnten wir (ohne zusätzliche Logik) nur noch zwei Elemente in die Queue schreiben. Um die Queue wieder auf acht Elemente aufzufüllen, gibt es zwei Lösungsmöglichkeiten:
Wir schieben die verbleibenden Elemente nach links, an den Anfang des Arrays. Diese Operation ist, insbesondere bei großen Arrays, sehr teuer.
Die bessere Lösung ist ein Ringbuffer (englisch: „circular array“). Das bedeutet, dass wir, wenn wir am Ende des Arrays angekommen sind, am Anfang des Arrays fortfahren. Das gilt sowohl für die Schreib- als auch die Leseoperation.
Ringbuffer
Um die Funktionsweise des Ringbuffers zu verdeutlichen, habe ich das Array aus dem Beispiel kreisförmig dargestellt:
Weitere Elemente fügen wir im Uhrzeigersinn ein, im folgenden Beispiel „mango“, „fig“, „pomelo“ und „apricot“ an die Positionen 6, 7 – und dann 0 und 1:
Zurück in der „flachen“ Darstellung sieht das Array nunmehr wie folgt aus:
Queue mit „flacher“ Darstellung des Ringpuffers
Sowohl in der Kreisdarstellung als auch in dieser ist gut zu sehen, dass nach dem Element „fig“ an Index 7 das Element „pomelo“ an Index 0 folgt.
Das Entnehmen der Elemente erfolgt analog. Mit jeder Dequeue-Operation wandert der headIndex um eine Position nach rechts, wobei auf die 7 nicht die 8, sondern die 0 folgt.
Volle Queue vs. leere Queue
tailIndex und headIndex liegen sowohl bei einer leeren als auch bei einer vollen Queue auf derselben Position. Damit wir erkennen können, wann die Queue voll ist, speichern wir zusätzlich die Anzahl der Elemente.
So könnte eine volle Queue aussehen:
Queue-Implementierung: voller Ringpuffer
Und so eine leere (z. B. nachdem aus der eben dargestellten Queue alle acht Elemente entnommen wurden):
Queue-Implementierung: leerer Ringpuffer
Das Speichern der Anzahl der Elemente ist nicht die einzige Möglichkeit, aber eine sehr simple, um eine volle von einer leeren Queue zu unterscheiden. Alternativen sind z. B.:
Man speichert (neben der Anzahl der Elemente) nur den tailIndexoder den headIndex und berechnet den jeweils anderen aus der Anzahl der Elemente (das macht den Code aber deutlich komplexer).
Man speichert die Anzahl der Elemente nicht und erkennt eine volle Queue daran, dass tailIndex und headIndex gleich sind und dass das Array an der Position tailIndex kein Element enthält.
Man füllt die Queue nicht komplett, sondern lässt immer mindestens ein Feld frei.
Quellcode für die bounded Queue mit einem Array
Die Implementierung einer bounded Queue mit einem Array ist recht einfach. Du findest den folgenden Code auch in der Klasse BoundedArrayQueue im GitHub-Repository.
publicclassBoundedArrayQueue<E> implementsQueue<E> {
privatefinal Object[] elements;
privateint headIndex;
privateint tailIndex;
privateint numberOfElements;
publicBoundedArrayQueue(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
@Overridepublicvoidenqueue(E element){
if (numberOfElements == elements.length) {
thrownew IllegalStateException("The queue is full");
}
elements[tailIndex] = element;
tailIndex++;
if (tailIndex == elements.length) {
tailIndex = 0;
}
numberOfElements++;
}
@Overridepublic E dequeue(){
final E element = elementAtHead();
elements[headIndex] = null;
headIndex++;
if (headIndex == elements.length) {
headIndex = 0;
}
numberOfElements--;
return element;
}
@Overridepublic E peek(){
return elementAtHead();
}
private E elementAtHead(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
@SuppressWarnings("unchecked")
E element = (E) elements[headIndex];
return element;
}
@OverridepublicbooleanisEmpty(){
return numberOfElements == 0;
}
}
Code-Sprache:Java(java)
Beachte, dass BoundedArrayQueuenicht das Interface java.util.Queue implementiert, sondern ein eigenes, das nur die vier Methoden enqueue(), dequeue(), peek() und isEmpty() definiert (s. Queue im GitHub-Repository):
publicinterfaceQueue<E> {
voidenqueue(E element);
E dequeue();
E peek();
booleanisEmpty();
}Code-Sprache:Java(java)
Wie du die BoundedArrayQueue (und alle anderen Implementierungen des Queue-Interfaces) benutzt, kannst du dir im Programm QueueDemo ansehen.
Implementierung einer unbounded Queue mit einem Array
Etwas komplexer wird die Implementierung für eine unbounded Queue, also eine Queue ohne Größenbeschränkung. Ein Array kann ja nicht wachsen. Und selbst wenn – es dürfte nicht am Ende wachsen, sondern müsste an genau der Stelle freien Platz erzeugen, an der sich tailIndex und headIndex befinden.
Schauen wir uns noch einmal die volle Queue vom Ende des vorherigen Beispiels an:
Um ein weiteres Element einzufügen, müssen wir die Kapazität der Queue erhöhen, indem wir das Array vergrößern.
(Aus Platzgründen in der grafischen Darstellung erhöhen wir die Kapazität nur um zwei Elemente. In der Realität findet man Erweiterungen um Faktor 1,5 oder 2,0.)
Wir müssten diesen freien Platz allerdings zwischen Ende und Anfang der Queue, also innerhalb des Arrays schaffen:
Erweiterung des Arrays in der Mitte
Das ist nicht ohne weiteres möglich. Ein Array kann nicht wachsen – schon gar nicht in der Mitte. Stattdessen müssen wir ein neues Array erzeugen und die bestehenden Elemente dorthinein kopieren.
Wenn wir die Elemente aber ohnehin umkopieren müssen, können wir sie dabei auch in der richtigen Reihenfolge an den Anfang des neuen Arrays kopieren, z. B. so:
Umkopieren in ein neues Array mit Neuanordnung
Der Code dafür ist gar nicht so kompliziert, wie du im nächsten Abschnitt sehen wirst.
Quellcode für die unbounded Queue mit einem Array
Der folgende Code zeigt die Klasse ArrayQueue aus dem Tutorial-GitHub-Repository.
Es gibt zwei Konstrukturen: einen, bei dem man die initiale Größe des Arrays angeben kann und einen Default-Konstruktor, der die initiale Kapazität auf zehn setzt.
Bei jedem Aufruf der enqueue()-Methode wird geprüft, ob das Array voll ist. Wenn das der Fall ist, wird die grow()-Methode aufgerufen.
Diese ruft zunächst calculateNewCapacity() auf, um die neue Größe des Arrays zu berechnen. Ich habe diese Methode hier in vereinfachter Form wiedergegeben: Sie multipliziert die aktuelle Größe mit 1,5.
Die calculateNewCapacity()-Methode im GitHub-Repository hat einen ausgefeilteren Algorithmus und stellt sicher, dass eine bestimmte Maximalgröße nicht überschritten wird. Der Fokus dieses Artikels soll jedoch nicht auf der Bestimmung der neuen Größe liegen, sondern auf der eigentlichen Erweiterung des Arrays.
Dazu wird in der Methode growToNewCapacity() das neue Array angelegt, die Elemente an die entsprechenden Positionen im neuen Array kopiert und headIndex sowie tailIndex neu gesetzt.
publicclassArrayQueue<E> implementsQueue<E> {
privatestaticfinalint DEFAULT_INITIAL_CAPACITY = 10;
private Object[] elements;
privateint headIndex;
privateint tailIndex;
privateint numberOfElements;
publicArrayQueue(){
this(DEFAULT_INITIAL_CAPACITY);
}
publicArrayQueue(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
@Overridepublicvoidenqueue(E element){
if (numberOfElements == elements.length) {
grow();
}
elements[tailIndex] = element;
tailIndex++;
if (tailIndex == elements.length) {
tailIndex = 0;
}
numberOfElements++;
}
privatevoidgrow(){
int newCapacity = calculateNewCapacity(elements.length);
growToNewCapacity(newCapacity);
}
staticintcalculateNewCapacity(int currentCapacity){
return currentCapacity + currentCapacity / 2;
}
privatevoidgrowToNewCapacity(int newCapacity){
Object[] newArray = new Object[newCapacity];
// Copy to the beginning of the new array: tailIndex to end of the old arrayint oldArrayLength = elements.length;
int numberOfElementsAfterTail = oldArrayLength - tailIndex;
System.arraycopy(elements, tailIndex, newArray, 0, numberOfElementsAfterTail);
// Append to the new array: beginning to tailIndex of the old arrayif (tailIndex > 0) {
System.arraycopy(elements, 0, newArray, numberOfElementsAfterTail, tailIndex);
}
// Adjust head and tail
headIndex = 0;
tailIndex = oldArrayLength;
elements = newArray;
}
// dequeue(), peek(), elementAtHead(), isEmpty() are the same as in BoundedArrayQueue
}
Code-Sprache:Java(java)
Die Methoden dequeue(), peek(), elementAtHead() und isEmpty() gleichen denen in der BoundedArrayQueue aus dem vorletzten Abschnitt. Ich habe sie daher nicht noch einmal mit abgedruckt.
Vielleicht ist dir aufgefallen, dass die Queue zwar wachsen, aber nicht wieder schrumpfen kann. Evtl. muss unsere Queue nur bei Lastspitzen eine hohen Zahl von Elementen speichern und würde danach den Speicher mit einem größtenteils leeren Array belegen. Wir könnten die Queue dahingehend erweitern, dass sie nach einer gewissen Karenzzeit ihren Inhalt wieder in ein kleineres Array umkopiert.
Diese Erweiterung überlasse ich dir als Übungsaufgabe.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im letzten Teil dieser Tutorialserie habe ich dir gezeigt, wie man eine Queue mit Stacks implementiert. In diesem Teil werden wir eine Queue mit einer verketteten Liste implementieren.
Der Algorithmus – Schritt für Schritt
Unsere Queue besteht aus zwei Referenzen auf Listenknoten: einer head– und einer tail-Referenz.
Die head-Referenz zeigt auf einen Listenknoten, der das vorderste Element der Queue enthält sowie einen next-Zeiger auf einen zweiten Listenknoten. Dieser wiederum enthält das zweite Element und einen Zeiger auf den dritten Listenknoten, usw.
Der letzte Knoten wird sowohl vom next-Zeiger des vorletzten Elements als auch vom tail-Zeiger referenziert. Er enthält das letzte Queue-Element, und dessen next-Referenz zeigt auf null.
Die folgende Grafik zeigt eine Beispiel-Queue, in die die Elemente „banana“, „cherry“ und „grape“ (in dieser Reihenfolge) eingefügt wurden:
Queue mit einer verketteten Liste implementieren
Wie gelangen wir diesen Zustand?
Enqueue-Algorithmus
Wir beginnen mit einer leeren Queue. Sowohl head– aus auch tail-Referenz sind null.
Queue mit verketteter Liste: leere Queue
Das erste Element fügen wir in die Queue ein, indem wir es in einen Listenknoten wrappen und sowohl head als auch tail auf diesen Knoten zeigen lassen:
Queue mit verketteter Liste: ein Element
Weitere Elemente fügen wir wie folgt ein:
Wir wrappen das einzufügende Element in einem neuen Listenknoten.
Wir lassen den next-Zeiger des letzten Knotens, also tail.next, auf den neuen Knoten zeigen.
Wir lassen ebenso tail auf den neuen Knoten zeigen.
In der folgenden Grafik siehst du, wie ein zweites Element, „cherry“, in die Beispiel-Queue eingefügt wird:
Queue mit verketteter Liste: zweites Element einfügen
Dequeue-Algorithmus
Die Entnahme des Kopf-Elements mit dequeue() funktioniert dann wie folgt:
Wir merken uns das Element des Knotens, auf den head zeigt (im Beispiel wäre das „banana“).
Wir lassen head auf head.next zeigen (im Beispiel auf den Knoten, der „cherry“ wrappt). Falls head danach null sein sollte (die Queue also leer ist), setzen wir auch tail auf null.
Wir geben das in Schritt 1 gemerkte Element zurück (im Beispiel „banana“).
In einer Programmiersprache mit Garbage Collector (z. B. Java) löscht dieser den nicht mehr referenzierten Knoten; in anderen Sprachen (wie C++) müssten wir ihn manuell löschen.
Die folgende Grafik soll die vier Schritte verdeutlichen:
Queue mit verketteter Liste: Element entnehmen
Der gestrichelte Rahmen um den „banana“-Knoten in Schritt 2 und 3 soll darstellen, dass dieser Knoten zu diesem Zeitpunkt nicht mehr referenziert wird.
Quellcode für die Queue mit einer Linked List
Der folgende Code zeigt die Implementierung einer Queue mit einer verketteten Liste (LinkedListQueue im GitHub-Repo). Die Klasse für die Knoten, Node, findest du ganz am Ende als statische innere Klasse.
publicclassLinkedListQueue<E> implementsQueue<E> {
private Node<E> head;
private Node<E> tail;
@Overridepublicvoidenqueue(E element){
Node<E> newNode = new Node<>(element);
if (isEmpty()) {
head = tail = newNode;
} else {
tail.next = newNode;
tail = newNode;
}
}
@Overridepublic E dequeue(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
E element = head.element;
head = head.next;
if (head == null) {
tail = null;
}
return element;
}
@Overridepublic E peek(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
return head.element;
}
@OverridepublicbooleanisEmpty(){
return head == null;
}
privatestaticclassNode<E> {
final E element;
Node<E> next;
Node(E element) {
this.element = element;
}
}
}
Code-Sprache:Java(java)
Wie du die LinkedListQueue-Klasse einsetzen kannst, kannst du dir Demo-Programm QueueDemo anschauen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Teil der Tutorialserie zeige ich dir, wie man eine Queue mit einem Stack (genauer gesagt: mit zwei Stacks) implementiert.
Diese Variante hat keinen praktischen Nutzen, sondern ist in erster Linie eine Übungsaufgabe. Als solche ist sie das Gegenstück zur Implementierung eines Stacks mit einer Queue.
Zur Erinnerung: ein Stack ist eine Datenstruktur, bei der die Elemente in der umgekehrten Reihenfolge des Einfügens abgerufen werden, also eine Last-in-first-out-Datenstruktur (LIFO).
Wie können wir damit eine Queue, also eine First-in-first-out-Datenstruktur (FIFO) implementieren?
Die Lösung – Schritt für Schritt
Das erste Element, dass wir in die Queue einfügen, legen wir auf einen Stack (im Beispiel: „banana“). Um es aus der Queue zu entnehmen, holen wir es wieder vom Stack:
Mit dem zweiten Element funktioniert das so schon nicht mehr, denn der Stack arbeitet ja nach dem LIFO-Prinzip. Wenn z. B. „banana“ und „cherry“ auf dem Stack liegen, müssten wir „cherry“ als erstes wieder entnehmen:
Bei einer Queue wollen wir jedoch das zuerst eingefügte Element (also „banana“) auch als erstes wieder entnehmen.
Das ist mit einem Stack allein nicht möglich.
Stattdessen gehen wir beim Einfügen eines Elements in die Queue wie folgt vor:
Wir erzeugen einen temporären Stack (in der Grafik unten orange dargestellt) und verschieben alle Elemente des ursprünglichen Stacks auf den temporären Stack.
Wir legen das neue Element auf den ursprünglichen Stack.
Wir schieben alle Elemente zurück vom temporären Stack auf den ursprünglichen Stack. Der temporäre Stack wird dann nicht mehr benötigt.
Die folgende Grafik zeigt die drei Schritte:
Zweites Element „cherry“ in die Queue einfügen
Danach liegen die Elemente so auf dem Stack, dass wir als erstes das zuerst eingefügte Element „banana“ entnehmen können und dann das als zweites eingefügte Element „cherry“.
Das funktioniert so nicht nur mit zwei Elementen, sondern mit beliebig vielen. Die folgende Grafik zeigt, wie wir ein drittes Element „grape“ in die Queue einfügen:
Drittes Element „grape“ in die Queue einfügen
Danach können wir die Elemente in First-in-First-out-Reihenfolge aus der Queue entnehmen, also erst die zuerst eingefügte „banana“, dann die „cherry“, und dann die zuletzt eingefügte „grape“.
Quellcode für die Queue mit Stacks
Der Quellcode für diesen Algorithmus benötigt nur wenige Zeilen Java-Code.
Du findest den Code in der Klasse StackQueue im GitHub-Repository.
publicclassStackQueue<E> implementsQueue<E> {
privatefinal Stack<E> stack = new ArrayStack<>();
@Overridepublicvoidenqueue(E element){
// 1. Move elements from main stack to a temporary stack
Stack<E> temporaryStack = new ArrayStack<>();
while (!stack.isEmpty()) {
temporaryStack.push(stack.pop());
}
// 2. Push new element on the main stack
stack.push(element);
// 3. Move elements back from temporary stack to main stackwhile (!temporaryStack.isEmpty()) {
stack.push(temporaryStack.pop());
}
}
@Overridepublic E dequeue(){
return stack.pop();
}
@Overridepublic E peek(){
return stack.peek();
}
@OverridepublicbooleanisEmpty(){
return stack.isEmpty();
}
}Code-Sprache:Java(java)
Beachte, dass hier nicht das java.util.Queue-Interface implementiert wird. Dieses erbt von java.util.Collection, sodass wir wesentlich mehr Methoden implementieren müssten.
Stattdessen habe ich für dieses Tutorial ein eigenes Queue-Interface geschrieben, das nur die Methoden enqueue(), dequeue(), peek() und isEmpty() definiert:
publicinterfaceQueue<E> {
voidenqueue(E element);
E dequeue();
E peek();
booleanisEmpty();
}Code-Sprache:Java(java)
Zum Einsatz der Queue kannst du dir das Demo-Programm QueueDemo ansehen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Dieser Artikel gibt einen Überblick über alle im JDK verfügbaren Queue-Implementierungen mitsamt ihrer Eigenschaften sowie eine Entscheidungshilfe, für welche Einsatzzwecke welche Implementierung am besten geeignet ist.
Der Klassenname in der folgenden Tabelle ist jeweils mit demjenigen Artikel der Tutorial-Serie verlinkt, in dem die jeweilige Queue-Implementierung mit all ihren Eigenschaften im Detail erklärt wird.
Eine Erklärung der Begriffe blocking, non-blocking, fairness policy, bounded und unbounded findest du im Artikel über das BlockingQueue-Interface.
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
² Fail-fast: Der Iterator wirft eine ConcurrentModificationException, wenn während der Iteration Elemente in die Queue eingefügt oder aus dieser entnommen werden.
Wann solltest du welche Queue-Implementierung einsetzen?
Anhand der Eigenschaften der Queue-Implementierungen, die in den jeweiligen Artikeln beschrieben und in der Tabelle oben zusammengefasst sind, kannst du die richtige Queue für jeden Einsatzzweck finden.
Für den tagtäglichen Gebrauch der allgemeinen Queue-Implementierungen mache ich folgende Empfehlungen:
ConcurrentLinkedQueue als threadsichere, nicht blockierende und unbounded Queue.
ArrayBlockingQueue als threadsichere, blockierende, bounded Queue, sofern du niedrige bis mittlere Contention zwischen Producer- und Consumer-Threads erwartest.
LinkedBlockingQueue als threadsichere, blockierende, bounded Queue, wenn du hohe Contention zwischen Producer- und Consumer-Threads erwartest (am besten testen, welche Implementierung für deinen Use Case performanter ist).
Hier das ganze noch einmal als Entscheidungsbaum:
Entscheidungsbaum Java Queue-Implementierungen
Optimierte MPMC-, MPSC-, SPMC- und SPSC-Queues
Alle vom JDK angebotenen threadsicheren Queue-Implementierungen können bedenkenlos in multi-producer-multi-consumer-Umgebungen eingesetzt werden. Das bedeutet, dass ein oder mehrere schreibende Threads sowie ein oder mehrere lesende Threads nebenläufig auf die JDK-Queues zugreifen können.
Mit speziellen Mechanismen ist es möglich Queues so zu optimieren, dass der Overhead für das Gewährleisten der Threadsicherheit minimiert wird, wenn es eine Beschränkung auf einen lesenden und/oder einen schreibenden Thread gibt.
Dementsprechend unterscheidet man folgende vier Fälle:
Multi-producer-multi-consumer (MPMC)
Multi-producer-single-consumer (MPSC)
Single-producer-multi-consumer (SPMC)
Single-producer-single-consumer (SPSC)
Die Open-Source-Bibliothek JCTools bietet für alle vier Fälle hoch-optimierte Queue-Implementierungen.
Zusammenfassung und Ausblick
Dieser Artikel hat einen Überblick über alle in Java verfügbaren Queue-Implementierungen gegeben sowie eine Entscheidungshilfe, in welchen Fällen welche Queue einzusetzen ist.
In den nächsten Teilen dieser Serie zeige ich dir, wie du Queues selbst implementieren kannst, beginnend mit der Implementierung mit einem Stack.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel lernst du eine sehr spezielle Queue kennen: die LinkedTransferQueue. Dieser Artikel beschreibt deren Eigenschaften und zeigt dir anhand eines Beispiels, wie du diese Queue einsetzt.
Wir befinden uns nunmehr am untersten Punkt der Queue-Klassenhierarchie:
LinkedTransferQueue in der Klassenhierarchie
TransferQueue Interface
Wie im Klassendiagram gut zu erkennen ist, ist java.util.concurrent.LinkedTransferQueue die einzige Klasse, die das Interface TransferQueue implementiert.
TransferQueue definiert zusätzliche Enqueue-Methoden, die nur dann erfolgreich ausgeführt werden können, wenn ein anderer Thread mit take() oder poll() das übergebe Element entgegennimmt:
transfer(E e) – übermittelt das Element an einen Thread, der mit take() oder poll() auf ein Element wartet. Wenn solch ein Thread nicht existiert, blockiert die Methode solange, bis ein anderer Thread take() oder poll() aufruft.
tryTransfer(E e) – übermittelt das Element an einen Thread, der mit take() oder poll() auf ein Element wartet. Wenn solch ein Thread nicht existiert, gibt die Methode umgehend false zurück.
tryTransfer(E e, long timeout, TimeUnit unit) – übermittelt das Element an einen Thread, der mit take() oder poll() auf ein Element wartet. Wenn solch ein Thread nicht existiert und auch nicht innerhalb der Wartezeit erscheint, gibt die Methode false zurück.
LinkedTransferQueue Eigenschaften
Bei der LinkedTransferQueue handelt es sich um eine unbounded blocking Queue, d. h. die regulären Enqueue-Operationen put() und offer() können nicht blockieren (da die Queue beliebig groß werden kann). Blockieren können hingegen:
die Dequeue-Operationen (wenn die Queue leer ist)
und die transfer()– bzw. tryTransfer()-Methoden des TransferQueue-Interfaces, bis die jeweiligen Elemente entnommen werden.
LinkedTransferQueue basiert auf einer einfach verketteten Liste. Das hat zur Folge, dass die Zeitkomplexität der size()-Methode O(n) beträgt¹ (und nicht O(1) wie bei den Array-basierten Queues), da zum Bestimmen der Länge die komplette Liste abgelaufen werden muss.
Threadsicherheit wird durch nicht-blockierende Compare-and-set (CAS)-Operationen erreicht, was eine hohe Performance bei niedriger bis moderater Contention (Zugriffskonflikten durch mehrere Threads) sicherstellt.
² Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Die LinkedTransferQueue wird im JDK nicht verwendet. Ursprünglich wurde sie für das im JDK 7 eingeführte Fork/Join-Framework implementiert, dann aber noch nicht dafür genutzt. Die Wahrscheinlichkeit von Bugs ist daher recht hoch, so dass du auf den Einsatz dieser Klasse verzichten solltest.
LinkedTransferQueue Beispiel
Im folgenden Beispiel (→ Code auf GitHub) werden zwei Threads gestartet, die LinkedTransferQueue.transfer() aufrufen. Danach wird ein Element direkt in die Queue geschrieben. Dann werden zwei weitere Threads gestartet, die transfer() aufrufen. Abschließend werden solange Elemente aus der Queue entnommen, bis diese wieder leer ist.
publicclassLinkedTransferQueueExample{
publicstaticvoidmain(String[] args)throws InterruptedException {
TransferQueue<Integer> queue = new LinkedTransferQueue<>();
// Start 2 threads calling queue.transfer(),
startTransferThread(queue, 1);
startTransferThread(queue, 2);
// ... then put one element directly,
enqueueViaPut(queue, 3);
// ... then start 2 more threads calling queue.transfer().
startTransferThread(queue, 4);
startTransferThread(queue, 5);
// Now take all elements until the queue is emptywhile (!queue.isEmpty()) {
dequeueViaTake(queue);
}
}
privatestaticvoidstartTransferThread(TransferQueue<Integer> queue, int element)throws InterruptedException {
new Thread(() -> enqueueViaTransfer(queue, element)).start();
// Wait a bit to let the thread enqueue the element
Thread.sleep(100);
log(" --> queue = " + queue);
}
privatestaticvoidenqueueViaTransfer(TransferQueue<Integer> queue, int element){
log("Calling queue.transfer(%d)...", element);
try {
queue.transfer(element);
log("queue.transfer(%d) returned --> queue = %s", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidenqueueViaPut(TransferQueue<Integer> queue, int element)throws InterruptedException {
log("Calling queue.put(%d)...", element);
queue.put(element);
log("queue.put(%d) returned --> queue = %s", element, queue);
}
privatestaticvoiddequeueViaTake(TransferQueue<Integer> queue)throws InterruptedException {
log(" Calling queue.take() (queue = %s)...", queue);
Integer e = queue.take();
log(" queue.take() returned %d --> queue = %s", e, queue);
// Wait a bit to get the log output in a readable order
Thread.sleep(10);
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US, "[%-8s] %s%n",
Thread.currentThread().getName(),
String.format(format, args));
}
}Code-Sprache:Java(java)
Man sieht sehr schön, wie zu Beginn zwei mal transfer() aufgerufen wird (aber nicht zurückkehrt), wie dann einmal put() aufgerufen wird (und zurückkehrt) und wie noch zwei mal transfer() aufgerufen wird (und nicht zurückkehrt).
Danach sehen wir, wie das erste Element entnommen wird und daraufhin auch transfer(1) zurückkehrt.
Dann wird das zweite Element entnommen und transfer(2) kehrt zurück.
Die Entnahme der 3 führt zu keiner weiteren Aktion, da diese mit put() in die Queue geschrieben wurde.
Nach der Entnahme der 4 und der 5 sieht man wieder schön, wie der jeweils zugehörige transfer()-Aufruf zurückkehrt.
Zusammenfassung und Ausblick
In diesem Artikel hast du das TransferQueue-Interface und die LinkedTransferQueue-Implementierung kennengelernt und an einem Beispiel gesehen, wie man diese einsetzen kann.
Im nächsten Teil dieser Tutorialserie findest du eine Zusammenfassung aller Queue-Implementierungen des JDK und eine Übersicht, in welchen Fällen du welche Implementierung verwenden solltest.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel geht es um eine sehr spezielle Queue – die SynchronousQueue, deren Eigenschaften und Einsatzgebiete. Anhand eines Beispiels siehst du, wie man die SynchronousQueue einsetzt.
Hier befinden wir uns in der Klassenhierarchie:
SynchronousQueue in der Klassenhierarchie
SynchronousQueue Eigenschaften
Das “Synchronous” in der Klasse java.util.concurrent.SynchronousQueue ist nicht mit „synchronized“ zu verwechseln. Es bedeutet vielmehr, dass jede Enqueue-Operation auf eine korrespondierende Dequeue-Operation warten muss und jede Dequeue-Operation auf eine Enqueue-Operation.
Eine SynchronousQueue enthält niemals Elemente, auch dann nicht, wenn Enqueue-Operationen gerade auf Dequeue-Operationen warten. Analog dazu ist die Größe einer SynchronousQueue immer 0, und peek() liefert immer null zurück.
Die SynchronousQueue und die ArrayBlockingQueue sind die einzigen Queue-Implementierungen, die eine Fairness Policy anbieten. Hierbei gibt es eine Besonderheit: Wenn die Fairness Policy nicht aktiviert ist, werden blockierende Aufrufe laut Dokumentation in unspezifizierter Reihenfolge bedient. Tatsächlich ist es jedoch so, dass diese exakt in umgekehrter Reihenfolge bedient werden (also in LIFO-Reihenfolge), da intern ein Stack verwendet wird.
Die Eigenschaften der SynchronousQueue im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Stack (implementiert mit verketteter Liste)
Ja (optimistisches Locking durch Compare-and-set)
Blocking
Optional
Unbounded
Der Iterator ist immer leer.
Einsatzempfehlung
Genau wie die DelayQueue und die LinkedTransferQueue habe ich auch die SynchronousQueue in eigenen Projekten noch nie direkt eingesetzt.
Sollten ihre Eigenschaften zu deinen Anforderungen passen, kannst du sie bedenkenlos verwenden. Im JDK wird die SynchronousQueue von Executors.newCachedThreadPool() als „work queue“ für den Executor eingesetzt; die Wahrscheinlichkeit von Bugs ist also äußerst gering.
SynchronousQueue Beispiel
Im folgende Beispiel (→ Code auf GitHub) werden zunächst drei Threads gestartet, die SynchronousQueue.put() aufrufen, danach sechs Threads, die SynchronousQueue.take() aufrufen und anschließend noch einmal drei Threads, die SynchronousQueue.put() ausführen:
publicclassSynchronousQueueExample{
privatestaticfinalboolean FAIR = false;
publicstaticvoidmain(String[] args)throws InterruptedException {
BlockingQueue<Integer> queue = new SynchronousQueue<>(FAIR);
// Start 3 producing threadsfor (int i = 0; i < 3; i++) {
int element = i; // Assign to an effectively final variablenew Thread(() -> enqueue(queue, element)).start();
Thread.sleep(250);
}
// Start 6 consuming threadsfor (int i = 0; i < 6; i++) {
new Thread(() -> dequeue(queue)).start();
Thread.sleep(250);
}
// Start 3 more producing threadsfor (int i = 3; i < 6; i++) {
int element = i; // Assign to an effectively final variablenew Thread(() -> enqueue(queue, element)).start();
Thread.sleep(250);
}
}
privatestaticvoidenqueue(BlockingQueue<Integer> queue, int element){
log("Calling queue.put(%d) (queue = %s)...", element, queue);
try {
queue.put(element);
log("queue.put(%d) returned (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoiddequeue(BlockingQueue<Integer> queue){
log(" Calling queue.take() (queue = %s)...", queue);
try {
Integer element = queue.take();
log(" queue.take() returned %d (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US,
"[%-9s] %s%n",
Thread.currentThread().getName(),
String.format(format, args));
}
}
Code-Sprache:Java(java)
In der Ausgabe kannst du sehen, wie die ersten drei Aufrufe von put() durch die Threads 0, 1 und 2 solange blockieren, bis die eingefügten Elemente mit take() durch die Threads 3, 4 und 5 in umgekehrter Reihenfolge entnommen werden.
Danach blockieren die drei folgenden Aufrufe von take() (Threads 6, 7, 8) solange bis mit put() drei weitere Elemente in die Queue geschrieben wurden (Threads 9, 10, 11).
Wenn du die Konstante FAIR auf true setzt, wirst du sehen, wie die Elemente nicht in LIFO-, sondern in FIFO-Reihenfolge entnommen werden.
Zusammenfassung und Ausblick
In diesem Artikel hast du die SynchronousQueue kennengelernt – eine Queue, die niemals Elemente enthält, sondern diese direkt von den enqueuenden Threads an die dequeuenden Threads übergibt.
Im nächsten Teil geht es um die letzte Queue-Impementierung dieser Tutorial-Serie: die LinkedTransferQueue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem und den nächsten Teilen dieser Tutorialserie geht es um Queues für spezielle Einsatzzwecke. Wir beginnen mit der DelayQueue, einer Queue, die die Elemente nach Ablaufzeit sortiert herausgibt.
Hier befinden wir uns in der Klassenhierarchie:
DelayQueue in der Klassenhierarchie
DelayQueue Eigenschaften
Die Klasse java.util.concurrent.DelayQueue ist – genau wie die PriorityQueue, die sie intern verwendet – keine FIFO-Queue. Es wird nicht das Element entnommen, das sich am längsten in der Queue befindet. Stattdessen wird ein Element dann entnommen, wenn eine diesem Element zugeordnete Wartezeit („delay“) abgelaufen ist.
Dazu müssen die Elemente das Interface java.util.concurrent.Delayed und dessen getDelay()-Methode implementieren. Diese Methode liefert bei jeden Aufruf die restliche Wartezeit zurück, die noch ablaufen muss, bis das Element aus der Queue entnommen werden darf.
DelayQueue ist blockierend, aber unbounded, kann also beliebig viele Elemente aufnehmen und blockiert nur bei der Entnahme (bis die Wartezeit abgelaufen ist), nicht beim Einfügen.
Threadsicherheit wird durch pessimistisches Locking über ein einzelnes ReentrantLock sichergestellt.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Priority Queue
Ja (pessimistisches Locking mit einem Lock)
Blocking (nur dequeue)
Nicht verfügbar
Unbounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Ich habe die DelayQueue noch nie benötigt und kann sie für keinen mir bekannten, sinnvollen Einsatzzweck empfehlen. Sie wird im JDK nur ein einziges Mal genutzt (in einer alten Swing-Klasse, die mit einem ScheduledExecutorService wahrscheinlich eleganter hätte implementiert werden können). Von daher ist nicht ausgeschlossen, dass sie unentdeckte Fehler enthält.
DelayQueue Beispiel
In folgendem Beispiel (→ Code auf GitHub) wird eine DelayQueue mit Instanzen der Klasse DelayedElement gefüllt, welche eine Zufallszahl enthalten sowie ein zufälliges initiales Delay zwischen 100 und 1.000 ms. Danach wird so oft poll() aufgerufen, bis die Queue wieder leer ist.
publicclassDelayQueueExample{
publicstaticvoidmain(String[] args){
BlockingQueue<DelayedElement<Integer>> queue = new DelayQueue<>();
ThreadLocalRandom random = ThreadLocalRandom.current();
long startTime = System.currentTimeMillis();
// Enqueue random numbers with random initial delaysfor (int i = 0; i < 7; i++) {
int randomNumber = random.nextInt(10, 100);
int initialDelayMillis = random.nextInt(100, 1000);
DelayedElement<Integer> element =
new DelayedElement<>(randomNumber, initialDelayMillis);
queue.offer(element);
System.out.printf(
"[%3dms] queue.offer(%s) --> queue = %s%n",
System.currentTimeMillis() - startTime, element, queue);
}
// Dequeue all elementswhile (!queue.isEmpty()) {
try {
DelayedElement<Integer> element = queue.take();
System.out.printf(
"[%3dms] queue.poll() = %s --> queue = %s%n",
System.currentTimeMillis() - startTime, element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}Code-Sprache:Java(java)
Und hier die zugehörige Klasse DelayedElement (→ Code auf GitHub). Die Sortierung ist – um den Code nicht noch länger zu machen – nicht stabil. D. h. wenn zwei Elemente mit derselben Wartezeit in die Queue gestellt werden, werden sie in zufälliger Reihenfolge wieder entnommen.
Hier eine beispielhafte Ausgabe des Programms. Es ist gut zu sehen, wie die Queue zwar nicht sortiert ist¹, das Element mit der kürzesten Wartezeit sich jedoch immer vorne (links) befindet und dass die Elemente (ungefähr) nach Ablauf ihrer jeweiligen Wartezeit entnommen werden:
¹ Tatsächlich sieht man die Reihenfolge der Elemente in der Array-Repräsentation des Min-Heaps.
Zusammenfassung und Ausblick
In diesem Artikel hast du alles über die DelayQueue, ihre Eigenschaften und ihre Verwendung erfahren.
Im nächsten Teil dieser Serie stelle ich dir weitere Spezialqueue vor – eine die niemals Elemente enthält: die SynchronousQueue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel erfährst du wie die PriorityBlockingQueue funktioniert und welche Eigenschaften sie hat. Anhand eines Beispiels siehst du, wie man sie einsetzt.
Hier befinden wir uns in der Klassenhierarchie:
PriorityBlockingQueue in der Klassenhierarchie
PriorityBlockingQueue Eigenschaften
Bei der java.util.concurrent.PriorityBlockingQueue handelt es sich um eine threadsichere und blockierende Variante der PriorityQueue. In dem verlinkten Artikel erfährst du auch, was eine Priotity Queue ist.
Wie bei der PriorityQueue werden die Elemente in einem Array gespeichert, das einen Min-Heap repräsentiert; der Iterator durchläuft die Elemente in entsprechender Reihenfolge.
Threadsicherheit wird durch ein einzelnes ReentrantLock sichergestellt.
Die PriorityBlockingQueue ist nicht bounded, sie hat also keine Kapazitätsgrenze. Das bedeutet, dass put(e) und offer(e, time, unit) niemals blockieren. Nur die Dequeue-Operationen take() und poll(time, unit) blockieren, wenn die Queue leer ist.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Min-Heap (gespeichert in einem Array)
Ja (pessimistisches Locking mit einem Lock)
Blocking (nur dequeue)
Nicht verfügbar
Unbounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Die PriorityBlockingQueue wird im JDK nicht genutzt. Es ist daher nicht auszuschließen, dass sie Bugs enthält. Wenn du eine Queue mit entsprechenden Eigenschaften benötigst und die PriorityBlockingQueue verwendest, solltest du deine Anwendung intensiv testen.
PriorityBlockingQueue Beispiel
Das folgenden Beispiel zeigt, wie eine PriorityBlockingQueue angelegt wird und wie mehrere Threads lesend und schreibend darauf zugreifen (→ Code auf GitHub).
Lesende Threads starten alle 3 Sekunden, beginnend sofort nach dem Erstellen der Queue.
Schreibende Threads starten nach 3,5 Sekunden (so dass bereits zwei lesende Threads warten) und schreiben sekündlich einen Zufallswert in die Queue.
publicclassPriorityBlockingQueueExample{
privatestaticfinallong startTime = System.currentTimeMillis();
publicstaticvoidmain(String[] args)throws InterruptedException {
BlockingQueue<Integer> queue = new PriorityBlockingQueue<>();
ScheduledExecutorService pool = Executors.newScheduledThreadPool(10);
// Start reading from the queue immediately, every 3 secondsfor (int i = 0; i < 8; i++) {
int delaySeconds = i * 3;
pool.schedule(() -> dequeue(queue), delaySeconds, TimeUnit.SECONDS);
}
// Start writing to the queue after 3.5 seconds (so there are already 2 threads// waiting), every 1 seconds (so that the queue fills faster than it's emptied,// so that we see some more elements and their order in the queue)for (int i = 0; i < 8; i++) {
int delayMillis = 3500 + i * 1000;
pool.schedule(() -> enqueue(queue), delayMillis, TimeUnit.MILLISECONDS);
}
pool.shutdown();
pool.awaitTermination(1, TimeUnit.MINUTES);
}
privatestaticvoidenqueue(BlockingQueue<Integer> queue){
int element = ThreadLocalRandom.current().nextInt(10, 100);
log("Calling queue.put(%d) (queue = %s)...", element, queue);
try {
queue.put(element);
log("queue.put(%d) returned (queue = %s)", element, queue);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
privatestaticvoiddequeue(BlockingQueue<Integer> queue){
log(" Calling queue.take() (queue = %s)...", queue);
try {
Integer element = queue.take();
log(" queue.take() returned %d (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US,
"[%4.1fs] [%-16s] %s%n",
(System.currentTimeMillis() - startTime) / 1000.0,
Thread.currentThread().getName(),
String.format(format, args));
}
}Code-Sprache:Java(java)
Im folgenden siehst du eine beispielhafte Ausgabe des Programms:
Zunächst einmal siehst du, wie nach 0,0 s und 3,0 s die Threads 1 und 2 beim Aufruf von take() blockieren, da die Queue leer ist.
Nach 3,5 s schreibt Thread 6 die 87 in die Queue. Sofort im Anschluss wacht der zuvor blockierte Thread 1 auf und entnimmt die 87 wieder.
Nach 4,5 s schreibt Thread 9 die 89 in die Queue, die sofort von Thread 2 wieder entnommen wird.
Nach 5,5 s wird die 31 in die Queue geschrieben, die nach 6,0 s wieder entnommen wird.
Nach 6,5 s, 7,5 s und 8,5 s werden die 71, die 15 und die 33 in die Queue geschrieben. Du siehst, wie jeweils das kleinste Element vorne (links) in der Queue steht.
Nach 9,0 s wird das kleinste Elemente, die 15, entnommen. Daraufhin steht das nächstkleinere Element, die 33 am Kopf der Queue.
Nach 9,5 s und 10,5 s werden zwei weitere Elemente, 58 und 19, in die Queue geschrieben. Du siehst wieder gut, wie jeweils das kleinste Element am Kopf der Queue steht.
Die Queue enthält nun vier Elemente. Es werden keine weiteren Elemente in die Queue geschrieben und die existierenden Elemente entsprechend ihrer Priorität entnommen.
Zusammenfassung und Ausblick
In diesem Artikel hast du erfahren, welche Eigenschaften die PriorityBlockingQueue hat und wie diese eingesetzt wird.
Ab dem nächsten Teil der Tutorial-Serie stelle ich dir einige Queue-Implementierungen für Sonderfälle vor, beginnend mit der DelayQueue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im diesem Artikel geht es um die ArrayBlockingQueue und deren Eigenschaften. Du siehst anhand eines Beispiels, wie die ArrayBlockingQueue eingesetzt wird. Außerdem gebe ich dir eine Empfehlung, in welchen Fällen du diese Queue einsetzen solltest.
Hier befinden wir uns in der Klassenhierarchie:
ArrayBlockingQueue in der Klassenhierarchie
ArrayBlockingQueue Eigenschaften
Die Klasse java.util.concurrent.ArrayBlockingQueue basiert auf einem Array und ist – wie die meisten Queue-Implementierungen – threadsicher (s. u.). Sie ist bounded (hat eine maximale Kapazität), entsprechend blockierend und bietet eine Fairness Policy (d. h. blockierende Methoden werden in der Reihenfolge bedient, in der sie aufgerufen wurden).
Die Eigenschaften in der Übersicht:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Array
Ja (pessimistisches Locking mit einem Lock)
Blocking
Optional
Bounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Aufgrund der möglicherweise hohen Contention bei gleichzeitigem Schreib- und Lesezugriff solltest du – wenn du eine blockierende, threadsichere Queue benötigst – für deinen speziellen Einsatzweck testen, ob evtl. eine LinkedBlockingQueue performanter ist. Diese basiert zwar auf einer verketteten Liste, verwendet allerdings zum Schreiben und Lesen zwei separate ReentrantLocks, was die Zugangskonflikte reduziert.
ArrayBlockingQueue Beispiel
Im folgenden Beispiel erzeugen wir eine ArrayBlockingQueue mit der Kapazität 3. Dann lassen wir über einen ScheduledExecutorService in bestimmten Abständen Elemente in die Queue schreiben und aus ihr lesen (→ Code auf GitHub):
publicclassArrayBlockingQueueExample{
privatestaticfinallong startTime = System.currentTimeMillis();
publicstaticvoidmain(String[] args)throws InterruptedException {
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(3);
ScheduledExecutorService pool = Executors.newScheduledThreadPool(10);
// Start reading from the queue immediately, every 3 secondsfor (int i = 0; i < 10; i++) {
int delaySeconds = i * 3;
pool.schedule(() -> dequeue(queue), delaySeconds, TimeUnit.SECONDS);
}
// Start writing to the queue after 3.5 seconds (so there are already 2 threads // waiting), every 1 seconds (so that the queue fills faster than it's emptied, // so that we see a full queue soon)for (int i = 0; i < 10; i++) {
int element = i; // Assign to an effectively final variableint delayMillis = 3500 + i * 1000;
pool.schedule(() -> enqueue(queue, element), delayMillis, TimeUnit.MILLISECONDS);
}
pool.shutdown();
pool.awaitTermination(1, TimeUnit.MINUTES);
}
privatestaticvoidenqueue(BlockingQueue<Integer> queue, int element){
log("Calling queue.put(%d) (queue = %s)...", element, queue);
try {
queue.put(element);
log("queue.put(%d) returned (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoiddequeue(BlockingQueue<Integer> queue){
log(" Calling queue.take() (queue = %s)...", queue);
try {
Integer element = queue.take();
log(" queue.take() returned %d (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US,
"[%4.1fs] [%-16s] %s%n",
(System.currentTimeMillis() - startTime) / 1000.0,
Thread.currentThread().getName(),
String.format(format, args));
}
}Code-Sprache:Java(java)
Wir versuchen alle drei Sekunden, beginnend sofort, ein Element aus der Queue zu lesen. Wir schreiben die Elemente sekündlich, fangen allerdings erst nach 3,5 s damit an. Zu diesem Zeitpunkt sollten also bereits zwei lesende Threads blockiert haben und darauf warten, dass Elemente in die Queue geschrieben werden.
Da wir schneller schreiben als lesen, sollte die Queue bald ihre Kapazitätsgrenze erreicht haben. Ab dem Moment sollten die schreibenden Threads so lange blockieren, bis die lesenden Threads aufgeholt haben.
Wie vorausgesehen blockieren die ersten zwei Leseversuche bei 0,0 s und 3,0 s, da noch keine Elemente in die Queue geschrieben wurden.
Nach 3,5 s wird das erste Element geschrieben. Dadurch wird der erste Thread aufgeweckt und entnimmt dieses Element wieder. Nach 4,5 s wird das zweite Element geschrieben und der zweite Thread aufgeweckt, um das Element zu entnehmen.
Da das Programm schneller schreibt als liest, blockieren nach 10,5 s Thread 1, nach 11,5 s Thread 9 und nach 12,5 s Thread 7 beim Versuch weitere Elemente in die zu dem Zeitpunkt volle Queue zu schreiben.
Nach 12,0 s wird ein Element entnommen und Thread 1 kann mit dem Schreiben fortfahren. Nach 15,0 s wird ein weiteres Element entnommen und Thread 9 kann fortfahren. Nach 18,0 s kann Thread 7 fortfahren.
Da keine weiteren Elemente in die Queue geschrieben werden, leert sie sich gegen Ende wieder.
Ist ArrayBlockingQueue threadsicher?
Ja, ArrayBlockingQueue ist threadsicher.
Die Threadsicherheit von ArrayBlockingQueue wird durch ein einzelnes ReentrantLock gewährleistet. Dieses wird sowohl für den Kopf als auch für das Ende der Queue verwendet, so dass es bei gleichzeitigen Schreib- und Lesezugriffen zu Zugriffskonflikten („thread contention“) zwischen Producer- und Consumer-Threads kommen kann.
Explizite Locks wie ReentrantLock sind hauptsächlich für Einsatzgebiete geeignet, in denen es zu hoher Thread Contention kommt. Bei niedriger bis moderater Contention ist optimistisches Locking performanter.
Unterschiede zu anderen Queues:
Bei LinkedBlockingQueue wird die Threadsicherheit nicht nur durch eines, sondern durch zwei Locks gewährleistet. So können Producer- und Consumer-Threads sich nicht gegenseitig blockieren.
Bei ConcurrentLinkedQueue wird die Threadsicherheit durch optimistisches Locking via Compare-and-Set gewährleistet, was zu besserer Performance bei niedriger bis moderater Contention führt.
Zusammenfassung und Ausblick
Dieser Artikel hat dir die ArrayBlockingQueue vorgestellt. Diese Queue ist threadsicher, blockierend und bounded. Anhand eines Beispiels hast du gesehen, wie du ArrayBlockingQueue einsetzen kannst.
Wie der Name schon sagt, basiert diese Queue auf einem Array. Das auf einer verketteten Liste basierende Pendant – LinkedBlockingQueue – wurde im vorherigen Teil der Serie behandelt.
Im nächsten Teil der Serie geht es um die PriorityBlockingQueue – eine threadsichere und blockierende Variante der in einem vorherigen Teil vorgestellten PriorityQueue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Teil der Tutorialserie geht es um die LinkedBlockingQueue. Du wirst deren speziellen Eigenschaften kennenlernen und anhand eines Beispiels sehen, wie man diese Queue einsetzt. Außerdem wirst du erfahren, wann du genau diese Queue einsetzen solltest.
Hier befinden wir uns in der Klassenhierarchie:
LinkedBlockingQueue in der Klassenhierarchie
LinkedBlockingQueue Eigenschaften
Die Klasse java.util.concurrent.LinkedBlockingQueue basiert – genau wie ConcurrentLinkedQueue – auf einer verketteten Liste, ist allerdings – ebenso wie die im nächsten Teil vorgestellte ArrayBlockingQueue – threadsicher (s. u.), bounded und blockierend.
Anders als die ArrayBlockingQueue bietet LinkedBlockingQueue keine Fairness Policy an. (Fairness Policy bedeutet, dass blockierende Methoden in der Reihenfolge bedient werden, in der sie aufgerufen werden.)
Die Queue-Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Fairness Policy
Bounded/ Unbounded
Iterator Type
Verkettete Liste
Ja (pessimistisches Locking mit zwei Locks)
Blocking
Nicht verfügbar
Bounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
Ich empfehle LinkedBlockingQueue, wenn du eine blockierende, threadsichere Queue benötigst.
Die Klasse LinkedBlockingQueue wird übrigens von Executors.newFixedThreadPool() und Executors.newSingleThreadedExecutor() als „work queue“ für den Executor verwendet. Sie wird somit intensiv genutzt, was die Wahrscheinlichkeit für Bugs äußerst gering hält.
LinkedBlockingQueue Beispiel
Das folgende Beispiel zeigt, wie die LinkedBlockingQueue verwendet wird. Wir erzeugen eine Queue mit der Kapazität 3. Direkt im Anschluss beginnen wir im Abstand von jeweils drei Sekunden Elemente aus der Queue zu lesen. Erst nach 3,5 Sekunden beginnen wir im Abstand von jeweils einer Sekunde Elemente in die Queue zu schreiben (→ Code auf GitHub).
publicclassLinkedBlockingQueueExample{
privatestaticfinallong startTime = System.currentTimeMillis();
publicstaticvoidmain(String[] args)throws InterruptedException {
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(3);
ScheduledExecutorService pool = Executors.newScheduledThreadPool(10);
// Start reading from the queue immediately, every 3 secondsfor (int i = 0; i < 10; i++) {
int delaySeconds = i * 3;
pool.schedule(() -> dequeue(queue), delaySeconds, TimeUnit.SECONDS);
}
// Start writing to the queue after 3.5 seconds (so there are already 2 threads // waiting), every 1 seconds (so that the queue fills faster than it's emptied, // so that we see a full queue soon)for (int i = 0; i < 10; i++) {
int element = i; // Assign to an effectively final variableint delayMillis = 3500 + i * 1000;
pool.schedule(() -> enqueue(queue, element), delayMillis, TimeUnit.MILLISECONDS);
}
pool.shutdown();
pool.awaitTermination(1, TimeUnit.MINUTES);
}
privatestaticvoidenqueue(BlockingQueue<Integer> queue, int element){
log("Calling queue.put(%d) (queue = %s)...", element, queue);
try {
queue.put(element);
log("queue.put(%d) returned (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoiddequeue(BlockingQueue<Integer> queue){
log(" Calling queue.take() (queue = %s)...", queue);
try {
Integer element = queue.take();
log(" queue.take() returned %d (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US,
"[%4.1fs] [%-16s] %s%n",
(System.currentTimeMillis() - startTime) / 1000.0,
Thread.currentThread().getName(),
String.format(format, args));
}
}Code-Sprache:Java(java)
Im folgenden siehst du die Ausgabe des Beispiel-Programms:
Da wir erst mit dem Schreiben beginnen, nachdem bereits zwei Threads take() aufrufen, blockieren diese ersten zwei Leseversuche bei 0,0 und 3,0 s (Thread 1 und 4).
Nach 3,5 s wird das erste Element geschrieben (Thread 8). Dadurch wird Thread 1 aufgeweckt und die take() Methode entnimmt dieses Element sofort wieder aus der Queue.
Nach 4,5 s wird das zweite Element geschrieben (Thread 5). Thread 4 wird aufgeweckt und entnimmt dieses Element wieder aus der Queue.
Das Programm schreibt schneller als es liest. Nach 10,5 s blockiert daher zum ersten Mal ein schreibender Thread (Thread 8) beim Versuch die 7 in die – zu dem Zeitpunkt volle – Queue zu schreiben. Nach 11,5 s blockiert ebenfalls Thread 4 beim Versuch die 8 in die Queue zu schreiben.
Nach 12,0 s entnimmt Thread 5 ein Element aus der Queue. Dadurch wird in der Queue ein Platz frei. Thread 8 wird aufgeweckt und schreibt die 7 in die Queue.
Versuch einmal selbst die restlichen Ausgaben zu lesen und zu verstehen.
Ist LinkedBlockingQueue threadsicher?
Ja, LinkedBlockingQueue ist threadsicher.
Die Threadsicherheit der LinkedBlockingQueue wird durch pessimistisches Locking mittels zweier separater ReentrantLock für Schreib- und Leseoperationen gewährleistet. So kann es zu keiner Contention (Zugriffskonflikten) zwischen Producer- und Consumer-Threads kommen.
Unterschiede zu anderen Queues:
Bei ConcurrentLinkedQueue wird die Threadsicherheit durch optimistisches Locking via Compare-and-Set gewährleistet, was zu besserer Performance bei niedriger bis moderater Contention führt.
ArrayBlockingQueue wird mit nur einemReentrantLock geschützt, so dass dort Zugriffskonflikte zwischen Producer- und Consumer-Threads möglich sind.
LinkedBlockingQueue Zeitkomplexität
Wie bei allen Queues ist der Aufwand für die Enqueue- und Dequeue-Operationen unabhängig von der Länge der Queue. Die Zeitkomplexität beträgt also O(1).
Dies gilt auch für die size()-Methode. Im Gegensatz zur ebenfalls auf einer verketteten Liste basierenden ConcurrentLinkedQueue, die bei jedem Aufruf von size() die komplette Liste durchläuft, um die Elemente zu zählen, verwendet LinkedBlockingQueue intern ein AtomicInteger, das beim Einfügen und Entnehmen aktualisiert wird, und somit die Größe mit konstantem Aufwand verfügbar hält.
Zusammenfassung und Ausblick
In diesem Artikel hast du die LinkedBlockingQueue kennengelernt – eine threadsichere, blockierende, bounded Queue. An einem Beispiel hast du gesehen, wie du LinkedBlockingQueue einsetzen kannst. Du hast außerdem erfahren, in welchen Fällen du LinkedBlockingQueue einsetzen solltest.
LinkedBlockingQueue basiert auf einer verketteten Liste. Im nächsten Teil des Tutorials geht es um das auf einem Array basierende Pendant – die ArrayBlockingQueue.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Teil der Tutorialserie stelle ich dir eine Queue vor, die streng genommen gar keine Queue ist: die PriorityQueue.
Wir befinden uns hier in der Klassenhierarchie:
PriorityQueue in der Klassenhierarchie
Was ist eine Priority Queue?
Eine Priority Queue (deutsch: Vorrangwarteschlange) ist keine Queue im klassischen Sinne. Denn die Elemente werden nicht in FIFO-Reihenfolge entnommen, sondern entsprechend ihrer Priorität. Es wird immer das Element mit der höchsten Priorität zuerst entnommen – unabhängig davon, wann es in die Queue eingefügt wurde.
Das folgende Beispiel zeigt eine Priority Queue mit Elementen der Priorität 10 (höchste Priorität), 20, usw. bis 80 (niedrigste Priorität). Ein weiteres Element mit Priorität 45 wird in die Queue eingefügt. Die Queue sorgt dann automatisch dafür, dass dieses Element nach dem Element mit der Priorität 40 und vor dem Element mit der Priorität 50 entnommen wird.
Einfügen eines Elements in eine PriorityQueue
Mit welcher Datenstruktur wird eine Priority Queue implementiert?
Priority Queues werden in der Regel mit einem Heap implementiert.
Im letzten Teil dieser Tutorialserie werde ich dir zeigen, wie du selbst eine Priority Queue mit einem Heap implementieren kannst.
Eigenschaften der Java-PriorityQueue
Bei der Klasse java.util.PriorityQueue ergibt sich die Dequeue-Reihenfolge entweder aus der natürlichen Ordnung¹ der Elemente oder entsprechend eines dem Constructor übergebenen Comparators¹. Die zugrundeliegende Datenstruktur ist ein Min-Heap, d. h. am Kopf der Queue befindet sich immer das kleinste Element.
Die Sortierung ist dabei nicht stabil, d. h. zwei Elemente, die entsprechend der Sortierreihenfolge an gleicher Position stehen, werden nicht zwangsläufig in derselben Reihenfolge entnommen, wie sie in die Queue eingefügt wurden.
PriorityQueue ist weder threadsicher noch blockierend. Als threadsicheres, blockierendes Pendant gibt es die PriorityBlockingQueue.
Die Queue-Eigenschaften sind:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Bounded/ Unbounded
Iterator Type
Min-Heap (gespeichert in einem Array)
Nein
Non-blocking
Unbounded
Fail-fast²
Die PriorityQueue verstößt übrigens nicht gegen das Liskovsche Substitutionsprinzip (Liskov substitution principle, LSP). Denn die Dokumentation des Queue-Interfaces besagt: „Queues typically, but do not necessarily, order elements in a FIFO (first-in-first-out) manner.“
¹ Alles über die „natürliche Ordnung“ von Objekten und die Sortierung per Comparator liest du im Artikel „Vergleichen von Objekten in Java„.
² Fail-fast: Der Iterator wirft eine ConcurrentModificationException, wenn während der Iteration Elemente in die Queue eingefügt oder aus dieser entnommen werden.
Einsatzempfehlung
Die PriorityQueue kann genau dann eingesetzt werden, wenn eine nicht threadsichere Queue mit oben beschriebener Dequeue-Reihenfolge benötigt wird.
Allerdings ist zu beachten, dass die PriorityQueue im JDK nur an sehr wenigen Stellen eingesetzt wird und somit eine gewisse Wahrscheinlichkeit für das Vorhandensein von Bugs existiert (was wenig genutzt wird, wird auch wenig getestet).
PriorityQueue Beispiel
Das folgende Beispiel zeigt, wie in Java eine Priority Queue erstellt wird und wie mehrere Zufallszahlen in die Queue geschrieben und dann wieder entnommen werden (→ Code auf GitHub).
Wir geben keinen Comparator an, d. h. die Integer-Elemente werden entsprechend ihrer natürlichen Ordnung sortiert.
publicclassPriorityQueueExample{
publicstaticvoidmain(String[] args){
Queue<Integer> queue = new PriorityQueue<>();
// Enqueue random numbersfor (int i = 0; i < 8; i++) {
int element = ThreadLocalRandom.current().nextInt(100);
queue.offer(element);
System.out.printf("queue.offer(%2d) --> queue = %s%n", element, queue);
}
// Dequeue all elementswhile (!queue.isEmpty()) {
Integer element = queue.poll();
System.out.printf("queue.poll() = %2d --> queue = %s%n", element, queue);
}
}
}Code-Sprache:Java(java)
Es folgt eine beispielhafte Ausgabe des Programms.
wie acht Elemente in die Priority Queue eingefügt werden,
wie die Elemente in der Priority Queue in vermeintlich zufälliger Reihenfolge dargestellt werden (tatsächlich handelt es sich um die Array-Repräsentation des Min-Heaps),
dass das kleinste Element immer am Kopf der Queue (links) ist,
wie die Elemente in aufsteigender Reihenfolge entnommen werden.
PriorityQueue mit einem Comparator
Im vorherigen Beispiel haben wir eine PriorityQueue über den Default-Konstruktor erstellt. Dies führt dazu, dass die Elemente entsprechend ihrer natürlichen Ordnung sortiert werden.
Wir können aber auch einen benutzerdefinierten Comparator für die Priority Queue angeben. Im folgenden Beispiel erstellen wir dazu Tasks mit je einem Namen und einer Priorität. Diese Tasks sollen nach Priorität sortiert wieder entnommen werden.
Den Comparator dafür definieren wir ganz einfach als:
Falls du mit dieser Schreibweise nicht vertraut bist – sie erstellt einen Comparator, der Tasks nach Priorität sortiert. Das ist doch viel besser lesbar als der folgende, mit einem Lambda, definierte Comparator:
Der Aufwand für die Enqueue- und Dequeue-Operationen bei der Java-PriorityQueue gleicht dem Aufwand für das Einfügen in und Entnehmen aus einem Heap.
Die Zeitkomplexität für beide Operationen lautet somit: O(n log n)
Durch die Verwendung eines Heaps befindet sich das Element mit der höchsten Priority immer automatisch am Kopf der Queue und kann mit konstantem Aufwand entnommen werden.
Die Zeitkomplexität für die Peek-Operation beträgt somit: O(1)
Dieser Artikel hat erklärt, was eine Priority Queue im allgemeinen ist, welche Eigenschaften die Java-PriorityQueue hat, wann man sie einsetzt, wie man die Dequeue-Reihenfolge mit einem benutzerdefinierten Comparator festlegt und welche Zeitkomplexitäten die Operationen der Priority Queue aufweisen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel erfährst du alles über die ConcurrentLinkedQueue, deren Eigenschaften und Einsatzszenarien. Anhand eines Beispiels siehst du, wie man ConcurrentLinkedQueue einsetzt.
Hier befinden wir uns in der Klassenhierarchie:
ConcurrentLinkedQueue in der Klassenhierarchie
ConcurrentLinkedQueue Eigenschaften
Die Klasse java.util.concurrent.ConcurrentLinkedQueue basiert auf einer einfach verketteten Liste und ist – wie die meisten Queue-Implementierungen – threadsicher (s. u.).
(Die einzige nicht threadsichere Queue ist PriorityQueue – sowie die Deques ArrayDeque und LinkedList, welche auch das Queue-Interface implementieren. Dazu mehr in der nächsten Tutorial-Serie „Deques“.)
Da die Länge einer verketteten Liste nur aufwändig zu bestimmen ist, ist ConcurrentLinkedQueue unbounded. ConcurrentLinkedQueue bietet außerdem keine blockierenden Operationen.
Die Eigenschaften im Detail:
Unterliegende Datenstruktur
Thread-safe?
Blocking/ Non-blocking
Bounded/ Unbounded
Iterator Type
Verkettete Liste
Ja (optimistisches Locking durch Compare-and-set)
Non-blocking
Unbounded
Weakly consistent¹
¹ Weakly consistent: Alle Elemente, die zum Zeitpunkt der Erzeugung des Interators in der Queue liegen, werden vom Iterator genau einmal durchlaufen. Änderungen, die danach erfolgen, können – müssen aber nicht – durch den Iterator berücksichtigt werden.
Einsatzempfehlung
ConcurrentLinkedQueue ist eine gute Wahl, wenn eine threadsichere, nicht blockierende und unbounded Queue benötigt wird.
Das im Folgetutorial über Deques beschriebene ArrayDeque – dieses ist allerdings nicht thread-safe.
Die später in diesem Tutorial beschriebe ArrayBlockingQueue – diese ist zum einen bounded, und zum anderen wird die Threadsicherheit über ein einzelnes ReentrantLock implementiert. Dies ist für die meisten Einsatzszenarien (mit niedriger bis mittlerer Contention) unperformanter ist als optimistisches Locking.
ConcurrentLinkedQueue Beispiel
Das folgende Beispiel demonstriert die Threadsicherheit von ConcurrentLinkedDeque. Vier schreibende und drei lesende Threads fügen nebenläufig Elemente in die Queue ein und entnehmen sie wieder (→ Code auf GitHub):
publicclassConcurrentLinkedQueueExample{
privatestaticfinalint NUMBER_OF_PRODUCERS = 4;
privatestaticfinalint NUMBER_OF_CONSUMERS = 3;
privatestaticfinalint NUMBER_OF_ELEMENTS_TO_PUT_INTO_QUEUE_PER_THREAD = 5;
privatestaticfinalint MIN_SLEEP_TIME_MILLIS = 500;
privatestaticfinalint MAX_SLEEP_TIME_MILLIS = 2000;
privatestaticfinalint POISON_PILL = -1;
publicstaticvoidmain(String[] args)throws InterruptedException {
Queue<Integer> queue = new ConcurrentLinkedQueue<>();
// Start producers
CountDownLatch producerFinishLatch = new CountDownLatch(NUMBER_OF_PRODUCERS);
for (int i = 0; i < NUMBER_OF_PRODUCERS; i++) {
createProducerThread(queue, producerFinishLatch).start();
}
// Start consumersfor (int i = 0; i < NUMBER_OF_CONSUMERS; i++) {
createConsumerThread(queue).start();
}
// Wait until all producers are finished
producerFinishLatch.await();
// Put poison pills on the queue (one for each consumer)for (int i = 0; i < NUMBER_OF_CONSUMERS; i++) {
queue.offer(POISON_PILL);
}
// We'll let the program end when all consumers are finished
}
privatestatic Thread createProducerThread(
Queue<Integer> queue, CountDownLatch finishLatch){
returnnew Thread(
() -> {
ThreadLocalRandom random = ThreadLocalRandom.current();
for (int i = 0; i < NUMBER_OF_ELEMENTS_TO_PUT_INTO_QUEUE_PER_THREAD; i++) {
sleepRandomTime();
Integer element = random.nextInt(1000);
queue.offer(element);
System.out.printf(
"[%s] queue.offer(%3d) --> queue = %s%n",
Thread.currentThread().getName(), element, queue);
}
finishLatch.countDown();
});
}
privatestatic Thread createConsumerThread(Queue<Integer> queue){
returnnew Thread(
() -> {
while (true) {
sleepRandomTime();
Integer element = queue.poll();
System.out.printf(
"[%s] queue.poll() = %4d --> queue = %s%n",
Thread.currentThread().getName(), element, queue);
// End the thread when a poison pill is detectedif (element != null && element == POISON_PILL) {
break;
}
}
});
}
privatestaticvoidsleepRandomTime(){
ThreadLocalRandom random = ThreadLocalRandom.current();
try {
Thread.sleep(random.nextInt(MIN_SLEEP_TIME_MILLIS, MAX_SLEEP_TIME_MILLIS));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
Code-Sprache:Java(java)
Hier die ersten 10 Zeilen einer beispielhaften Ausgabe:
Wir sehen sehr schön, wie die sieben Threads Elemente einfügen und entnehmen. In der dritten Zeile sehen wir auch, dass Thread 5 beim Aufruf von queue.poll() den Wert null geliefert bekommen hat, da die Queue zu diesem Zeitpunkt leer war.
ConcurrentLinkedQueue Performance
Dieser Abschnitt behandelt die Threadsicherheit und Zeitkomplexität von ConcurrentLinkedQueue.
Ist ConcurrentLinkedQueue threadsicher?
Die Threadsicherheit der ConcurrentLinkedQueue wird durch optimistisches Locking erzielt. Genauer gesagt: durch nicht-blockierende Compare-and-set (CAS)-Operationen auf separate VarHandles für den Kopf und das Ende der Queue.
Beim Zugriff auf Queues ist normalerweise niedrige bis moderate Contention (Zugriffskonflikte durch mehrere Threads) zu erwarten, da ein Thread in der Regel nicht ununterbrochen auf die Queue zugreift, sondern das einzustellende Element erstmal erzeugen bzw. das entnommende Element verarbeiten muss.
Bei niedriger bis moderater Contention erzielt optimistisches Locking einen deutlichen Performance-Gewinn gegenüber pessimistischem Locking durch implizite oder explizite Locks.
Unterschiede zu anderen Queues:
Bei LinkedBlockingQueue wird die Threadsicherheit durch pessimistisches Locking via zweier ReentrantLocks gewährleistet, was zu besserer Performance bei hoher Contention führen kann.
Bei ArrayBlockingQueue wird die Threadsicherheit durch ein einzelnes ReentrantLock gewährleistet.
ConcurrentLinkedQueue Zeitkomplexität
Wie bei allen Queues ist der Aufwand für die Enqueue- und Dequeue-Operationen unabhängig von der Länge der Queue. Die Zeitkomplexität beträgt also O(1).
Dies gilt hingegen nicht für die size()-Methode. Um die Länge der Queue zu bestimmen, muss über alle Elemente der verketteten Liste iteriert werden. Je länger die Queue, desto länger dauert es die Länge zu berechnen. Die Zeitkomplexität für size() beträgt somit O(n).
In diesem Teil der Tutorialserie habe ich dir die konkrete Queue-Implementierung ConcurrentLinkedQueue und deren Eigenschaften vorgestellt.
Im folgenden Teil wird es um die PriorityQueue gehen, die einige Überraschungen bereithält.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Artikel lernst du das Interface java.util.concurrent.BlockingQueue kennen. BlockingQueue erweitert das im vorherigen Teil dieser Tutorial-Serie besprochene Queue-Interface um Methoden zum blockierenden Zugriff auf Queues.
Bevor wir klären, was „blockierender Zugriff“ bedeutet, müssen wir zunächst über den Begriff „bounded Queue“ sprechen.
Was ist eine bounded Queue?
Wenn eine Queue nur eine begrenzte Anzahl von Elementen aufnehmen kann, spricht man von einer „bounded Queue“. Die maximale Anzahl von Elementen wird mit „Kapazität“ (englisch „capacity“) bezeichnet und beim Erzeugen der Queue einmalig festgelegt.
Die folgende Code-Zeile bspw. erzeugt eine auf 100 Elemente begrenzte ArrayBlockingQueue:
Queue<Integer> queue = new ArrayBlockingQueue<>(100);Code-Sprache:Java(java)
Ist die Anzahl der Elemente in der Queue hingegen nicht begrenzt (bzw. nur durch den zur Verfügung stehenden Speicher), spricht man von einer „unbounded Queue“.
(Dieselbe Definition gilt übrigens für alle Datenstrukturen, z. B. auch für Stacks und Deques.)
Was ist eine blockierende Queue?
Bei den Queue-Operationen „Enqueue“ und „Dequeue“ können zwei Sonderfälle auftreten:
Wir könnten versuchen ein Element in eine bounded Queue einzufügen, die ihre Kapazitätsgrenze erreicht hat – oder anders gesagt: die voll ist.
Wir könnten versuchen ein Element aus einer leeren Queue zu entnehmen.
Eine blockierende Queue hingegen bietet zusätzliche Methoden, die darauf warten, dass die gewünschte Operation ausgeführt werden kann:
Enqueue-Methoden, die beim Einfügen in eine volle bounded Queue warten, bis diese wieder freie Kapazitäten hat (dazu muss ein ander Thread ein Element entnehmen).
Dequeue-Methoden, die beim Entnehmen eines Element aus einer leeren Queue darauf warten, dass diese nicht mehr leer ist (dazu muss ein anderer Thread ein Element einfügen).
Diese zusätzlichen Methoden sind im BlockingQueue-Interface definiert und werden im folgenden Kapitel erläutert.
Fairness Policy
Blockierende Methoden werden dabei nicht automatisch in der Reihenfolge bedient, in der sie aufgerufen wurden. Die Abarbeitung in Aufrufreihenfolge kann bei einigen Queue-Implementierungen durch eine optionale „Fairness Policy“ aktiviert werden. Diese erhöht allerdings den Overhead und verringert damit den Durchsatz der Queue massiv. In der Regel ist die Aktivierung der „Fairness Policy“ nicht nötig.
BlockingQueue Interface
Die blockierenden Enqueue- und Dequeue-Operationen gibt es in jeweils zwei Varianten. Die erste Variante wartet unbegrenzt lange. Die zweite Variante gibt nach Ablauf einer vorgegebenen Wartezeit auf und liefert false bzw. null zurück.
Die folgende Tabelle zeigt in den ersten zwei Spalten die nicht blockierenden Methoden, die BlockingQueue von Queue erbt (und die wir im vorherigen Teil des Tutorials besprochen haben). In der dritten und vierten Spalte findest du die hinzugekommenden, blockierenden Methoden:
Nicht blockierend (geerbt von Queue)
Blockierend (neu in BlockingQueue)
Exception
Rückgabewert
Blockiert
Blockiert mit Timeout
Element anhängen (enqueue):
add(E e)
offer(E e)
put(E e)
offer(E e, long timeout, TimeUnit unit)
Element entnehmen (dequeue):
remove()
poll()
take()
poll( long timeout, TimeUnit unit)
Element ansehen (examine):
element()
peek()
–
–
Der folgende Abschnitt beschreibt die BlockingQueue-Methoden im Einzelnen
BlockingQueue Methoden
BlockingQueue.put()
Die put()-Methode fügt, sofern Platz vorhanden ist, ein Element in die Queue ein. Ist die Kapazitätsgrenze der Queue hingegen erreicht, blockiert die Methode solange, bis Platz freigeworden ist.
BlockingQueue.offer() mit Timeout
Auch die offer()-Methode fügt ein Element ein, wenn in der Queue noch Platz ist. Andernfalls wartet die Methode die angegebene Zeit. Wird in dieser Zeit ein Platz frei, wird das Element eingefügt und die Methode gibt true zurück. Läuft die Wartezeit hingegen ab, ohne dass ein Platz freigeworden ist, gibt die Methode false zurück.
BlockingQueue.take()
Diese Methode entnimmt ein Element vom Kopf der Queue, sofern die Queue nicht leer ist. Bei einer leeren Queue blockiert take() solange, bis ein Element verfügbar geworden ist und gibt dieses dann zurück.
BlockingQueue.poll() mit Timeout
Auch poll() entnimmt ein Element vom Kopf der Queue, wenn diese nicht leer ist. Ist die Queue hingegen leer, wartet die Methode die angegebene Zeit. Sofern in der Wartezeit ein Element verfügbar wird, wird dieses entnommen und zurückgegeben. Läuft die Wartezeit ergebnislos ab, gibt die Methode null zurück.
InterruptedException bei blockierenden Methoden
Alle blockierenden Methoden werfen eine InterruptedException, wenn auf dem wartenden Thread die interrupt()-Methode aufgerufen wird. Mit interrupt() sollten wartende Threads abgebrochen werden, wenn das Warten nicht mehr nötig ist.
Dies ist z. B. beim Herunterfahren der Applikation der Fall. Dabei wird eventuell das Ereignis, auf das die blockierende Methode wartet, nicht mehr eintreten. Die Methode würde aber dennoch auf den Eintritt des Ereignisses warten und damit ein reguläres Herunterfahren der Applikation verhindern. Das Abbrechen der wartenden Threads mit interrupt() ermöglicht ein sauberes Herunterfahren.
Java BlockingQueue Beispiel
Der folgende Quellcode zeigt ein Beispiel, welches aufgrund der Nebenläufigkeit deutlich komplexer ausfällt als das Beispiel mit einer nicht-blockierenden Queue (→ Code in GitHub):
publicclassBlockingQueueExample{
privatestaticfinallong startTime = System.currentTimeMillis();
publicstaticvoidmain(String[] args)throws InterruptedException {
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(3);
ScheduledExecutorService pool = Executors.newScheduledThreadPool(10);
// Start reading from the queue immediately, every 3 secondsfor (int i = 0; i < 10; i++) {
int delaySeconds = i * 3;
pool.schedule(() -> dequeue(queue), delaySeconds, TimeUnit.SECONDS);
}
// Start writing to the queue after 3.5 seconds (so there are already 2// threads waiting), every 1 seconds (so that the queue fills faster than// it's emptied, so that we see a full queue soon)for (int i = 0; i < 10; i++) {
int element = i; // Assign to an effectively final variableint delayMillis = 3500 + i * 1000;
pool.schedule(() -> enqueue(queue, element), delayMillis, TimeUnit.MILLISECONDS);
}
pool.shutdown();
pool.awaitTermination(1, TimeUnit.MINUTES);
}
privatestaticvoidenqueue(BlockingQueue<Integer> queue, int element){
log("Calling queue.put(%d) (queue = %s)...", element, queue);
try {
queue.put(element);
log("queue.put(%d) returned (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoiddequeue(BlockingQueue<Integer> queue){
log(" Calling queue.take() (queue = %s)...", queue);
try {
Integer element = queue.take();
log(" queue.take() returned %d (queue = %s)", element, queue);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
privatestaticvoidlog(String format, Object... args){
System.out.printf(
Locale.US,
"[%4.1fs] [%-16s] %s%n",
(System.currentTimeMillis() - startTime) / 1000.0,
Thread.currentThread().getName(),
String.format(format, args));
}
}Code-Sprache:Java(java)
In diesem Beispiel erstellen wir eine blocking, bounded Queue mit der Kapazität 3 und schedulen jeweils zehn Enqueue- und zehn Dequeue-Operationen.
Die Enqueue-Operationen beginnen später, so dass wir am Anfang blockierende Dequeue-Operationen sehen können. Außerdem erfolgen die Enqueue-Operationen in kürzen Abständen, so dass die Kapazitätsgrenze der Queue nach einer Weile erreicht ist und wir blockierende Enqueue-Operationen sehen können.
Zu Beginn ist die Queue leer, so dass die ersten zwei Leseversuche (nach 0 und 3 s) blockieren.
Nach 3,5 s (nachdem also zwei lesende Threads an der Queue warten) beginnt das Programm sekündlich in die Queue zu schreiben. Man sieht in der Ausgabe schön, wie dabei jeweils ein lesender Thread fortgesetzt wird und das angehängte Element sofort wieder entnimmt (bei 3,5 und 4,5 s).
Da das Programm dreimal so schnell in die Queue schreibt wie es daraus liest, blockiert nach 10,5 s der Versuch eine 7 in die Queue zu schreiben, da diese mit den Elementen [4, 5, 6] ihre Kapazitätsgrenze von 3 erreicht hat.
Erst nachdem nach 12 s die 4 aus der Queue entnommen wurde, kann die 7 eingefügt werden. Für die 8 und die 9 sehen wir ein entsprechendes Verhalten.
BlockingQueue Implementierungen
Im JDK gibt es fünf Implementierungen des BlockingQueue-Interfaces mit jeweils spezifischen Eigenschaften. In dem folgenden UML-Klassendiagramm sind diese mitsamt ihrem Interface farbig hinterlegt:
BlockingQueue Interface in der Klassenhierarchie
Die Implementierungen werden jeweils in separaten Teilen des Tutorials behandelt. Dort werden deren Eigenschaften vorgestellt und anhand dieser erläutert, unter welchen Voraussetzungen die jeweilige Implementierung eingesetzt werden sollte. Folgende Links führen zu den entsprechenden Artikeln:
Du gelangst zu diesen Artikeln auch jederzeit über die Tutorial-Navigation am rechten Rand.
Zusammenfassung und Ausblick
Dieser Artikel hat zunächst die Unterschiede zwischen bounded/unbounded und blocking/non-blocking Queues erläutert. Im Anschluss hast du das BlockingQueue-Interface und dessen Methoden put(), offer(), take() und poll() kennengelernt.
In den folgenden Teilen dieser Serie werden wir alle Queue– und BlockingQueue-Implementierung und deren Eigenschaften genauer unter die Lupe nehmen.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Das JDK enthält seit Java 5.0 das Interface java.util.Queue und mehrere Queue-Implementierungen, die sich in diversen Eigenschaften (wie bounded/unbounded, blocking/non-blocking, threadsicher/nicht threadsicher) unterscheiden.
Auf all diese Eigenschaften werde ich im weiteren Verlauf dieses Tutorials eingehen.
Java Queue Klassenhierarchie
Bevor ich die Java-Queue im Detail vorstelle, möchte ich einen Überblick in Form eines UML-Klassendiagramms geben:
Du kannst zu den entsprechenden Teilen jederzeit über die Tutorial-Navigation am rechten Rand springen.
Die grau eingezeichneten Interfaces Deque und BlockingDeque mitsamt ihren Implementierungen werden in der Tutorial-Serie „Deques“ behandelt.
Java Queue Methoden
Das Queue-Interface definiert sechs Methoden zum Einfügen, Entnehmen und Betrachten von Elementen. Für jede der drei Queue-Operationen „Enqueue“, „Dequeue“ und „Peek“ definiert das Interface jeweils zwei Methoden: eine die im Fehlerfall eine Exception wirft und eine die einen speziellen Wert (false oder null) zurückliefert.
Methoden zum Einfügen in die Queue
Zunächst ein grafischer Überblick über die Enqueue-Methoden:
Methoden zum Einfügen in eine Queue
Queue.add()
Diese Methode ist bereits im Collection-Interface definiert und fügt ein Element in die Queue ein. Bei Erfolg gibt die Methode true zurück. Wenn eine größenbeschränkte Queue voll ist, wirft diese Methode eine IllegalStateException.
Queue.offer()
offer() fügt wie add() ein Element in die Queue ein und gibt bei Erfolg true zurück. Wenn eine größenbeschränkte Queue voll ist, gibt diese Methode false zurück anstatt eine IllegalStateException zu werfen.
Methoden zum Entnehmen aus der Queue
Auch für die Dequeue-Methoden zunächst ein grafischer Überblick:
Methoden zum Entfernen aus einer Queue
Queue.remove()
remove() entnimmt das Element vom Kopf der Queue. Ist die Queue leer, wirft die Methode eine NoSuchElementException.
Queue.poll()
Auch poll() entnimmt das Element am Kopf der Queue. Anders als remove() wirft die Methode bei einer leeren Queue keine Exception, sondern gibt null zurück.
Methoden zum Betrachten des Kopf-Elements
Und wieder zunächst ein Überblick über Methoden:
Methoden zum Betrachten des Kopf-Elements einer Queue
Queue.element()
Die element()-Methode gibt das Element vom Kopf der Queue zurück, ohne es aus der Queue zu entnehmen. Ist die Queue leer, wird eine NoSuchElementException geworfen.
Queue.peek()
Genau wie element() gibt auch peek() das Kopf-Element zurück, ohne es aus der Queue zu entfernen. Bei einer leeren Queue gibt diese Methode allerdings – genau wie poll() – null zurück.
Queue-Methoden – Zusammenfassung
Die folgende Tabelle zeigt noch einmal die sechs Methoden gruppiert nach Operation und Art der Fehlerbehandlung:
im Fehlerfall: Exception
im Fehlerfall: Rückgabewert
Element anhängen (enqueue):
add(E e)
offer(E e)
Element entnehmen (dequeue):
remove()
poll()
Element ansehen (peek):
element()
peek()
Wie erzeugt man eine Queue?
java.util.Queue ist ein Interface. Ein Interface kann nicht instatiiert werden, da es lediglich beschreibt, welche Methoden eine Klasse anbietet, jedoch keine Implementierungen dieser Methoden beinhaltet.
Was passiert, wenn man es dennoch versucht?
publicclassQueueTest{
publicstaticvoidmain(String[] args){
Queue<Integer> queue = new Queue<>(); // <-- Don't do this!
}
}Code-Sprache:Java(java)
Beim Versuch diesen Code zu compilieren würdest du folgende Fehlermeldung sehen:
QueueTest.java:5: error: Queue is abstract; cannot be instantiated
Queue<Integer> queue = new Queue<>(); // <-- Don't do this!
^
1 errorCode-Sprache:Klartext(plaintext)
Daher muss eine der konkreten Queue-Implementierungen ausgewählt werden, z. B. die ConcurrentLinkedQueue:
Queue<Integer> queue = new ConcurrentLinkedQueue<>();Code-Sprache:Java(java)
(Die verschiedenen Queue-Klassen werden in weiteren Teilen des Tutorials erläutert. Im letzten Teil findest du eine Entscheidungshilfe, wann du welche Implementierung verwenden solltest.)
Beispiel: Wie benutzt man eine Queue?
Das folgende Beispiel zeigt, wie man eine Queue erstellt, wie man diese mit einigen Werten befüllt, und wie man die Werte wieder entnimmt. Du findest den Beispiel-Code auch auf GitHub.
Das Programm tut folgendes (die Numerierung verweist auf die Kommentare im Quellcode):
Es erstellt eine Queue. Welche du benutzt, ist für dieses Beispiel irrelevant, da es keine speziellen Queue-Eigenschaften erfordert. Wir verwenden die ConcurrentLinkedQueue.
Die Werte 1 bis 5 werden mit Queue.offer() in die Queue geschrieben. Der Inhalt der Queue wird nach jedem Einfügen angezeigt.
Wir betrachten mit Queue.peek() das Kopf-Element der Queue.
Solange die Queue Elemente enthält (dies prüfen wir mit der isEmpty()-Methode, die das Queue-Interface von Collection erbt), werden diese mit Queue.poll() entnommen und angezeigt. Danach wird jeweils wieder der gesamte Inhalt der Queue angezeigt.
Nachdem die Queue geleert wurde, werden noch einmal die Rückgabewerte von poll() und peek() angezeigt.
Es ist sehr gut zu sehen, wie die Elemente in derselben Reihenfolge entnommen werden, wie sie eingefügt wurden (First-in-First-out – FIFO).
Zusammenfassung und Ausblick
In diesem Teil des Tutorials hast du das Queue-Interface von Java kennengelernt. Anhand eines Beispiels hast du gesehen, wie man die Java-Queue benutzt.
Im nächsten Teil schauen wir uns das Interface „BlockingQueue“ genauer an. Dort werde ich auch den Unterschied zwischen bounded und unbounded bzw. blocking und non-blocking Queues erklären.
Danach werden wir alle Queue-Implementierungen des JDK einzeln betrachten. Anhand deren besonderer Eigenschaften werde ich dir erklären, wann man welche Implementierung einsetzen sollte.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Tutorial lernst du alles über den abstrakten Datentyp „Queue“ (im deutschen auch als „Warteschlange“ bezeichnet):
Wie funktioniert eine Queue?
Was sind die Anwendungsgebiete für Queues?
Welche Queue-Interfaces und -Klassen gibt es im JDK?
Was sind blocking, non-blocking, bounded und unbounded Queues?
Wie implementiert man eine Queue in Java?
Was ist eine Queue?
Eine Queue ist eine Liste von Elementen, bei der die Elemente auf einer Seite eingefügt und in derselben Reihenfolge auf der anderen Seite wieder entnommen werden.
Man kann sich das wie eine Warteschlange an einer Kasse oder bei einer Behörde vorstellen:
Warteschlange
Ankommende Personen stellen sich am Ende der Schlange (rechts im Bild) an. Sobald ein Kunde abgefertigt wurde, kommt der nächste Kunde vom Kopf der Schlange (links) an die Reihe.
Die Person, die sich zuerst angestellt hat, kommt somit auch zuerst an die Reihe. Daher sprechen wir vom First-in-First-out-Prinzip (FIFO).
FIFO-Prinzip bei Queues
Beim abstrakten Datentyp „Queue“ kann das wie im folgenden Beispiel aussehen:
Queue-Datenstruktur
Die Grafik zeigt eine Queue, die die Elemente 6, 7, 8, usw. bis 13 enhält. Die 5 wurde gerade vom Kopf der Queue (englisch „Front“ oder „Head“, links im Bild) entnommen und die 14 wird gerade an das Ende der Queue („Back“, „Tail“ oder „Rear“ im englischen, rechts im Bild) eingefügt.
Queue Operationen: Enqueue und Dequeue
Die Operationen der Queue bezeichnen wir wie folgt:
„Enqueue“: Einfügen neuer Elemente am Ende der Queue
„Dequeue“: Entnehmen von Elementen vom Kopf der Queue
„Peek“ oder „Front“: Betrachten des Elements am Kopf, ohne es zu entnehmen (optional)
(Die entsprechenden Methoden der Java-Queue-Implementierungen heißen übrigens anders; mehr dazu im nächsten Teil des Tutorials, „Java Queue-Interface„.)
Anwendungsgebiete für Queues
Ein Anwendungsbereich von Queues, den wir alle kennen, ist die Druckerwarteschlange. Verschiedene Programme stellen dort Druckaufträge ein. In der Regel gibt es nur einen Drucker, der diese dann der Reihe nach abarbeitet.
Ein technisches Anwendungsbeispiel ist die Verarbeitung von HTTP-Requests in einem Webserver. Ein Webserver arbeitet in der Regel mit einem Threadpool für gleichzeitig abzuarbeitende Requests. Wenn mehr Anfragen hereinkommen als gleichzeitig abgearbeitet werden können, ist der Threadpool ausgelastet. Zusätzliche Requests werden dann in eine Warteschlange gestellt und in First-in-First-out-Reihenfolge abgearbeitet, sobald wieder Threads zur Verfügung stehen.
Queues werden in der Regel mit Arrays oder verketteten Listen implementiert. Bei beiden Varianten ist der Aufwand für die Enqueue- und Dequeue-Operationen jeweils konstant, d. h. der Aufwand ändert sich nicht mit der Länge der Queue.
Die Zeitkomplexität dieser Operationen lautet also: O(1).
Zu Übungszwecken kann man eine Queue auch mit Stacks implementieren (dazu mehr in einem späteren Teil des Tutorials). Die Zeitkomplexität ist dann allerdings höher.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem letzten Teil des Stack-Tutorials zeige ich dir, wie man die Reihenfolge der Elemente eines Stacks ausschließlich per Rekursion (also ohne Iteration) umkehren kann.
Genau wie die Implementierung eines Stacks mit Queues hat auch der in diesem Artikel gezeigte Algorithmus in erster Linie Schulungs-Character. Von daher: Versuch gerne zuerst einmal selbst auf die Lösung zu kommen.
Die Lösung – Schritt für Schritt
Wir lösen die Aufgabe mit zwei Methoden, die ich in den folgenden zwei Abschnitten erklären werde.
1. Die reverse()-Methode
Wir implementieren zunächst eine reverse()-Methode, die wie folgt vorgeht:
Schritt 1:
Solange Elemente auf dem Eingabe-Stack sind, nehmen wir sie vom Stack und rufen die reverse()-Methode rekursiv auf. Dadurch werden alle Elemente vom obersten bis zum untersten Element in den Call Stack verschoben:
Schritt 2:
Beim Ausstieg aus der Rekursion schieben wir die Elemente vom Call Stack zurück auf den Ziel-Stack – aber in umgekehrter Reihenfolge!
Dazu erstellen wir eine Methode insertAtBottom(), welche ein Element am Boden eines Stacks einfügt. (Wie diese Methode funktioniert, siehst du im nächsten Abschnitt.)
Fertig! Der Ziel-Stack enthält die Elemente des Eingabe-Stacks in umgekehrter Reihenfolge.
2. Die insertAtBottom()-Methode
Doch wie fügen wir Elemente am Boden des Stacks ein?
Dazu implementieren wir eine zweite Methode – insertAtBottom(). Auch für diese setzen wir ausschließlich auf Rekursion.
Die folgenden Grafiken zeigen den letzten insertAtBottom()-Aufruf des vorherigen Diagramms. Also den Aufruf, bei dem das Element „peach“ am Boden des Ziel-Stacks eingefügt wird. Dieser enthält zu dem Zeitpunkt bereits die Elemente „apple“, „orange“ und „pear“.
Der Einfüge-Vorgang besteht aus drei Schritten:
Schritt 1:
Solange Elemente auf dem Ziel-Stack sind, entnehmen wir diese und rufen insertAtBottom() rekursiv auf. Dadurch werden die Elemente des Ziel-Stacks auf den Call Stack verschoben:
Schritt 2:
Sobald der Ziel-Stack leer ist, wird das Element, das am Boden des Stacks eingefügt werden soll, auf den Ziel-Stack gelegt:
Schritt 3:
Beim Ausstieg aus der Rekursion schieben wir die Elemente vom Call Stack zurück in den Ziel-Stack:
Damit hat die insertAtBottom()-Methode ihre Aufgabe erledigt: Das Element „peach“ wurde am Boden des Ziel-Stacks eingefügt.
Quellcode für die Umkehrung eines Stacks per Rekursion
Der Java-Quellcode für die Umkehrung des Stacks besteht aus nur wenigen Zeilen für die zwei Methoden. Du findest den Code in der Klasse Stacks im GitHub-Repo:
publicclassStacks{
publicstatic <E> voidreverse(Stack<E> stack){
if (stack.isEmpty()) {
return;
}
E element = stack.pop();
reverse(stack);
insertAtBottom(stack, element);
}
privatestatic <E> voidinsertAtBottom(Stack<E> stack, E element){
if (stack.isEmpty()) {
stack.push(element);
} else {
E top = stack.pop();
insertAtBottom(stack, element);
stack.push(top);
}
}
}Code-Sprache:Java(java)
Den Klassennamen Stacks habe ich übrigens analog zu Java-Utility-Klassen wie Collections und Arrays gewählt.
Umsetzung mit Default-Methode im Interface
Moderner ist es die Methoden direkt im Stack-Interface zu implementieren:
publicinterfaceStack<E> {
// ...defaultvoidreverse(){
if (isEmpty()) {
return;
}
E element = pop();
reverse();
insertAtBottom(element);
}
privatevoidinsertAtBottom(E element){
if (isEmpty()) {
push(element);
} else {
E top = pop();
insertAtBottom(element);
push(top);
}
}
}
Code-Sprache:Java(java)
Diese Variante findest du nicht im GitHub-Repository, da ich bei der Vorstellung des Stack-Interfaces zu Beginn des Tutorials nicht mit der reverse()-Methode verwirren wollte.
Fazit
Damit endet die Tutorial-Serie zum Thema Stack. Wenn du alle Teile gelesen hast, hast du gelernt, wie ein Stack funktioniert, welche Stack-Implementierungen es im JDK gibt, wie man Stacks auf verschiedene Arten selbst implementiert und – in diesem Artikel – wie man einen Stack per Rekursion umkehren kann.
Wenn dir die Serie gefallen hat, hinterlasse mir gerne einen Kommantar oder teile die Artikel über die Share-Buttons am Ende. Wenn du noch Fragen hast, kannst du sie gerne über die Kommentar-Funktion stellen.
Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im vorherigen Teil dieser Tutorial-Serie ging es darum, wie man einen Stack mit einer verketteten Liste implementiert. In diesem Teil zeige ich dir, wie du einen Stack mit einer Queue (besser gesagt: mit zwei Queues) implementieren kannst.
Diese Variante hat kaum praktischen Nutzen und wird in erster Linie als Übungsaufgabe verwendet (als Gegenstück gibt es übrigens auch eine Übung zur Implementierung einer Queue mit Stacks). Von daher: Versuch doch einmal selbst auf die Lösung zu kommen!
Zur Erinnerung: Eine Queue ist eine Datenstruktur, bei der du Elemente auf einer Seite einfügst und auf der anderen Seite wieder entnimmst – also eine First-in-First-out-Datenstruktur (FIFO).
Wie können wir damit einen Stack, also eine Last-in-First-out-Datenstruktur (LIFO) implementieren?
Die Lösung – Schritt für Schritt
Das erste Element, das wir auf den Stack schieben (im Beispiel: „apple“), fügen wir in eine Queue ein. Um es vom Stack zu entnehmen, holen wir es wieder aus der Queue:
Das zweite Element können wir nicht einfach auch in diese Queue schreiben. Denn die funktioniert ja nach dem FIFO-Prinzip. Wenn wir „apple“ und dann „orange“ in die Queue schieben, müssen wir auch „apple“ zuerst wieder entnehmen:
Bei einem Stack müssen wir jedoch das zuletzt auf den Stack geschobene Elemente „orange“ zuerst wieder entnehmen – und nicht den zuerst eingefügten „apple“.
Das ist mit einer einzigen Queue nicht möglich.
Stattdessen gehen wir beim Einfügen eines Elements wie folgt vor:
Wir erzeugen eine neue Queue (in der Grafik unten orange dargestellt) und schieben auf diese das einzufügende Element.
Wir verschieben das Element aus der ersten Queue in die neu erstellte Queue.
Wir ersetzen die bestehende Queue durch die neue Queue.
Die folgende Grafik zeigt die drei Schritte:
Zweites Element auf den Stack schieben
Danach liegen die Elemente so in der Queue, dass wir als erstes das zuletzt eingefügte Element „orange“ entnehmen können und danach das zuerst eingefügte Element „apple“.
Das funktioniert so nicht nur mit zwei Elementen, sondern mit beliebig vielen. Die folgende Grafik zeigt, wie wir ein drittes Element „pear“ auf den Stack schieben. Der zweite Schritt aus der vorherigen Grafik ist hier in die Schritte 2a und 2b aufgeteilt: Zuerst wird „orange“ aus der alten Queue in die neue verschoben, danach „apple“.
Drittes Element auf den Stack schieben
Danach können wir die Elemente in Last-in-First-out-Reihenfolge aus dem Stack entnehmen, also erst die zuletzt eingefügte „pear“, dann die „orange“, dann den zuerst eingefügten „apple“.
Quellcode für den Stack mit Queues
Im folgenden siehst du, dass der Quellcode für die Lösung ziemlich einfach ist.
Als Queue verwende ich die einfachste Queue-Implementierung, ArrayDeque. Dass es sich auch um ein Deque handelt, stört uns nicht, denn wir weisen es ja einer Variablen zu, deren Typ das Queue-Interface ist.
Du findest den Quellcode in der Klasse QueueStack im GitHub-Repository.
publicclassQueueStack<E> implementsStack<E> {
private Queue<E> queue = new ArrayDeque<>();
@Overridepublicvoidpush(E element){
Queue<E> newQueue = new ArrayDeque<>();
newQueue.add(element);
while (!queue.isEmpty()) {
newQueue.add(queue.remove());
}
queue = newQueue;
}
@Overridepublic E pop(){
return queue.remove();
}
@Overridepublic E peek(){
return queue.element();
}
@OverridepublicbooleanisEmpty(){
return queue.isEmpty();
}
}Code-Sprache:Java(java)
Das Demo-Programm StackDemo zeigt dir, wie du den QueueStack einsetzen kannst.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im vorangeganenen Teil haben wir einen Stack mit einem Array implementiert. In diesem Teil zeige ich dir, wie du einen Stack mit einer einfach verketteten Liste programmierst.
Der Algorithmus – Schritt für Schritt
Dies ist im Grunde ganz einfach: Eine top-Referenz zeigt auf einen Knoten, der das oberste Element des Stacks enthält sowie einen next-Zeiger auf den zweiten Knoten. Dieser wiederum enthält das zweite Element und einen Zeiger auf den dritten Knoten, usw. Der letzte Knoten enthält das unterste Element des Stacks; die next-Referenz des letzten Knotens ist null.
Die folgende Grafik zeigt einen Beispiel-Stack, auf den die Elemente „apple“, „orange“ und „pear“ (in dieser Reihenfolge) gepusht wurden:
Stack mit einer verketteten Liste implementieren
Doch wie kommen wir dorthin?
Enqueue-Algorithmus
Beginnen wir mit einem leeren Stack. Die top-Referenz ist zunächst null:
Stack mit verketteter Liste: leerer Stack
Um das erste Element auf den Stack zu pushen, wrappen wir dieses in einen neuen Knoten und lassen top auf diesen Knoten zeigen:
Stack mit verketteter Liste: ein Element
Jedes weitere Element fügen wir zwischen top und den ersten Knoten ein. Dazu brauchen wir drei Schritte:
Wir legen einen neuen Knoten an und wrappen damit das einzufügende Element.
Wir lassen die next-Referenz des neuen Knotens auf denselben Knoten zeigen wie top.
Wir lassen top auf den neuen Knoten zeigen.
Die folgende Grafik zeigt die drei Einfüge-Schritte:
Stack mit verketteter Liste: Element einfügen
Dequeue-Algorithmus
Um ein Element mit pop() wieder zu entnehmen, gehen wir wie folgt vor:
Wir merken uns das Element des Knotens, auf das top zeigt (im Beispiel „orange“).
Wir ändern die top-Referenz auf denjenigen Knoten auf den top.next zeigt.
Wir geben das in Schritt 1 gemerkte Element zurück.
In einer Sprache mit Garbage Collector (z. B. Java) sorgt dieser dann für das Löschen des nicht mehr referenzierten Knotens. In Sprachen ohne Garbage Collector (z. B. C++) müssen wir das selbst tun.
Die folgende Grafik zeigt die vier Schritte:
Stack mit verketteter Liste: Element entnehmen
Der gestrichelte Rahmen um den „orange“-Knoten im zweiten und dritten Schritt soll andeuten, dass dieser Listenknoten nicht mehr referenziert wird.
Quellcode für den Stack mit einer Linked List
Der folgende Quellcode zeigt die Implementierung des Stacks mit einer verketteten Liste (Klasse LinkedListStack im GitHub-Repo). Die Klasse für die Knoten, Node, findest du am Ende des Quellcodes als statische innere Klasse.
publicclassLinkedListStack<E> implementsStack<E> {
private Node<E> top = null;
@Overridepublicvoidpush(E element){
top = new Node<>(element, top);
}
@Overridepublic E pop(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
E element = top.element;
top = top.next;
return element;
}
@Overridepublic E peek(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
return top.element;
}
@OverridepublicbooleanisEmpty(){
return top == null;
}
privatestaticclassNode<E> {
final E element;
final Node<E> next;
Node(E element, Node<E> next) {
this.element = element;
this.next = next;
}
}
}Code-Sprache:Java(java)
Wie die LinkedListStack-Klasse eingesetzt wird, kannst du dir beispielhaft im Demo-Programm StackDemo ansehen.
Vor- und Nachteile der Implementierung des Stacks mit einer Linked List
Die Implementierung mit einer verketteten Liste hat gegenüber der Array-Variante den Vorteil, dass sie keinen Speicherplatz durch unbelegte Array-Felder verschwendet und dass sie keine Größenänderung des Arrays durch Kopieren des gesamten Arrays erfordert.
Die Knoten-Objekte wiederum belegen mehr Speicherplatz als ein einzelnes Feld in einem Array. Das Anlegen von Knoten-Objekten kostet mehr Zeit als das Setzen eines Array-Feldes. Eine verkettete Liste verursacht außerdem mehr Arbeit für den Garbage Collector, da dieser bei jedem Durchgang der kompletten Kette folgen muss.
In der Regel überwiegen die Vorteile der Array-Implementierung, so dass diese häufiger anzutreffen ist.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im letzten Teil haben wir einen Stack als Adapter um ein ArrayDeque geschrieben. In diesem Teil des Tutorials zeige ich dir, wie man einen Stack – ganz ohne Java-Collection-Klassen – mit einem Array implementiert.
Im Grunde ist das ganz einfach: Wir legen ein leeres Array an und füllen dieses von links nach rechts (also von Index 0 an aufsteigend) mit den auf den Stack gelegten Elementen. Beim Entnehmen der Elemente lesen wir diese von rechts nach links aus dem Array aus (und entfernen sie aus dem Array).
Die folgende Grafik zeigt einen Stack mit einem Array namens elements, das acht Elemente fassen kann. Bisher wurden vier Elemente auf den Stack gelegt.
Stack mit einem Array implementieren
Die Anzahl der Elemente (nicht die Größe des Arrays) wird in der Variablen numberOfElements gespeichert. Der Wert dieser Variablen zeigt uns, an welcher Position im Array wir ein Element einfügen bzw. auslesen müssen:
Einfügen: an Position numberOfElements
Auslesen: an Position numberOfElements - 1
Quellcode für den Stack mit einem Array fester Größe
Solange wir die Größe das Arrays nicht ändern müssen, ist die Implementierung relativ einfach, wie der folgende Java-Code zeigt (Klasse BoundedArrayStack in GitHub):
publicclassBoundedArrayStack<E> implementsStack<E> {
privatefinal Object[] elements;
privateint numberOfElements;
publicBoundedArrayStack(int capacity){
if (capacity < 1) {
thrownew IllegalArgumentException("Capacity must be 1 or higher");
}
elements = new Object[capacity];
}
@Overridepublicvoidpush(E item){
if (numberOfElements == elements.length) {
thrownew IllegalStateException("The stack is full");
}
elements[numberOfElements] = item;
numberOfElements++;
}
@Overridepublic E pop(){
E element = elementAtTop();
elements[numberOfElements - 1] = null;
numberOfElements--;
return element;
}
@Overridepublic E peek(){
return elementAtTop();
}
private E elementAtTop(){
if (isEmpty()) {
thrownew NoSuchElementException();
}
@SuppressWarnings("unchecked")
E element = (E) elements[numberOfElements - 1];
return element;
}
@OverridepublicbooleanisEmpty(){
return numberOfElements == 0;
}
}Code-Sprache:Java(java)
Etwas komplizierter wird es, wenn mehr Elemente auf den Stack geschoben werden sollen als das Array groß ist. Ein Array kann ja nicht wachsen. Wie das funktioniert, zeige ich dir im nächsten Kapitel.
Implementierung eines Stacks mit einem Array variabler Größe
Stattdessen müssen wir (wenn das Array voll ist):
ein neues, größeres Array anlegen,
die Elemente des ursprünglichen Arrays in das neue Array kopieren und
das alte Array verwerfen.
Das folgende Diagramm stellt diese drei Schritte grafisch dar:
Stack mit Array: Vergrößern des Arrays
All das können wir in Java mit dem Aufruf der Methode Arrays.copyOf() in einem Schritt erledigen. Dazu müssen wir der Methode bloß die gewünschte Größe des neuen Arrays übergeben.
Quellcode für den Stack mit einem Array variabler Größe
Der folgende Code zeigt einen Stack, der initial mit einem Array für zehn Elemente angelegt wird. Bei jedem Aufruf der push()-Methode wird geprüft, ob das Array voll ist. Ist das der Fall, wird die grow()-Methode aufgerufen.
Diese wiederum ruft calculateNewCapacity() auf, um die neue Größe des Arrays zu berechnen. Im Beispiel wird das Array immer um den Faktor 1,5 vergrößert. Im Code ist außerdem eine Maximalgröße für das Array festgelegt. Wenn diese erreicht ist und ein weiteres Element gepusht wird, wird eine Exception geworfen (sofern es nicht schon vorher zu einem OutOfMemoryError kam).
publicclassArrayStack<E> implementsStack<E> {
publicstaticfinalint MAX_SIZE = Integer.MAX_VALUE - 8;
privatestaticfinalint DEFAULT_INITIAL_CAPACITY = 10;
private Object[] elements;
privateint numberOfElements;
publicArrayStack(){
this(DEFAULT_INITIAL_CAPACITY);
}
publicArrayStack(int initialCapacity){
elements = new Object[initialCapacity];
}
@Overridepublicvoidpush(E item){
if (elements.length == numberOfElements) {
grow();
}
elements[numberOfElements] = item;
numberOfElements++;
}
privatevoidgrow(){
int newCapacity = calculateNewCapacity(elements.length);
elements = Arrays.copyOf(elements, newCapacity);
}
staticintcalculateNewCapacity(int currentCapacity){
if (currentCapacity == MAX_SIZE) {
thrownew IllegalStateException("Can't grow further");
}
int newCapacity = currentCapacity + calculateIncrement(currentCapacity);
if (newCapacity > MAX_SIZE || newCapacity < 0/* overflow */) {
newCapacity = MAX_SIZE;
}
return newCapacity;
}
privatestaticintcalculateIncrement(int currentCapacity){
return currentCapacity / 2;
}
// pop(), peek(), elementAtTop(), isEmpty() are the same as in BoundedArrayStack
}Code-Sprache:Java(java)
Die Methoden pop(), peek(), elementAtTop() und isEmpty() gleichen denen im oben vorgestellten BoundedArrayStack. Ich habe sie daher nicht noch einmal mit abgedruckt.
Was der ArrayStack in der abgedruckten Form noch nicht kann, ist das Array auch wieder verkleinern (wir wollen ja nicht übermäßig viel Speicherplatz verschwenden). Versuch doch selbst einmal die Implementierung dahingehend zu erweitern.
Wie BoundedArrayStack und ArrayStack eingesetzt werden können, kannst du dir im Programm StackDemo ansehen.
Ausblick
Im nächsten Teil der Serie lernst du eine Variante kennen, die nicht auf einem Array, sondern auf einer verketteten Liste basiert und damit vollautomatisch bei jedem push() wächst und sich mit jedem pop() wieder verkleinert.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Im vorherigen Teil des Tutorials, „Stack-Klasse in Java„, hast du erfahren, warum man Javas Stack-Klasse nicht verwenden sollte (unnötige Operationen wie insertElementAt() und setElementAt(), fehlendes Interface, over-synchronized).
Die von den JDK-Entwicklern empfohlene Alternative, Deque, bietet ebenfalls Methoden an, die eigentlich nicht in einen Stack gehören, z. B. addLast() und removeLast().
Die unnötigen Operationen stehen im Widerspruch zum Interface-Segregation-Prinzip (ISP), demzufolge eine Schnittstelle nur diejenigen Methoden enthalten sollte, die der Nutzer dieser Schnittstelle benötigt.
Daher zeige ich in diesem und den folgenden Teilen dieses Tutorials, wie man in Java einen Stack selbst implementiert – und zwar auf vier verschiedene Arten:
Als erstes legen wir ein Stack-Interface an. Dieses enthält nur diejenigen Methoden, die ein Stack anbieten sollte, nämlich:
push() – zum Hinzufügen von Elementen auf den Stack
pop() – zum Entnehmen von Elementen von der Oberseite des Stacks
peek() – zum Betrachten des obersten Stack-Elements, ohne es zu entnehmen
isEmpty() – um zu prüfen, ob der Stack leer ist (diese Methode ist optional)
Der folgende Code zeigt das Interface (Klasse Stack im im GitHub-Repo):
publicinterfaceStack<E> {
voidpush(E item);
E pop();
E peek();
booleanisEmpty();
}Code-Sprache:Java(java)
Ich habe mich an dieser Stelle entschieden, dass pop() und peek() bei einem leeren Stack eine NoSuchElementException werfen, so wie es die add/remove/get-Methoden von Deque tun.
Alternativ könnte man auch Optional<E> zurückliefern. Die Entscheidung hängt davon ab, inwieweit der Aufruf von pop() und peek() auf einem leeren Stack eine Ausnahme darstellt (dann sollte man Exceptions werfen) oder einen regulären Control Flow (dann sollte man ein Optional zurückgeben).
Was man nicht tun sollte, ist bei einem leeren Stack null zurückzugeben.
Stack implementieren mit ArrayDeque
Unsere erste Implementierung besteht aus einem Adapter um die (nicht threadsichere) Deque-Implementierung ArrayDeque. Der Adapter leitet die Stack-Methoden wie folgt weiter:
Stack.push() → ArrayDeque.addFirst()
Stack.pop() → ArrayDeque.removeFirst()
Stack.peek() → ArrayDeque.getFirst()
Stack.isEmpty() → ArrayDeque.isEmpty()
Hier zunächst ein Klassendiagramm, das das Adapter-Pattern darstellt:
ArrayDequeStack als Adapter um ein ArrayDeque
Und hier die Implementierung des Adapters (Klasse ArrayDequeStack im GitHub-Repo):
publicclassArrayDequeStack<E> implementsStack<E> {
privatefinal Deque<E> deque = new ArrayDeque<>();
@Overridepublicvoidpush(E item){
deque.addFirst(item);
}
@Overridepublic E pop(){
return deque.removeFirst();
}
@Overridepublic E peek(){
return deque.getFirst();
}
@OverridepublicbooleanisEmpty(){
return deque.isEmpty();
}
}Code-Sprache:Java(java)
Das folgende Beispielprogramm (Klasse StackDemo in GitHub) zeigt eine beispielhafte Benutzung der ArrayDequeStack-Klasse.
Der Test-Code ist so konzipiert, dass wir ohne großen Aufwand zusätzliche Stack-Implementierungen testen können (indem wir runDemo() für Instanzen anderer Stack-Klassen aufrufen).
Wir haben mit wenigen Zeilen Code eine eigene (nicht threadsichere) Stack-Klasse implementiert.
Um einen threadsicheren Stack zu implementieren können wir analog einen Adapter um ein threadsicheres Deque – wie ConcurrentLinkedDeque (nicht blockierend) oder LinkedBlockingDeque (blockierend) – legen.
Im nächsten Teil des Tutorials zeige ich dir, wie du einen Stack mit einem Array implementierst.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Ebenso alt wie Java selbst ist die seit der Version 1.0 vorhandene Klasse java.util.Stack – eine Implementierung des abstrakten Datentyps Stack.
Stack erbt von java.util.Vector und implementiert damit zahlreiche Interfaces des Java Collections Frameworks. Das folgende Diagramm zeigt die Klassenhierarchie:
java.util.Stack – Klassendiagramm
Java Stack Methoden
Stack erweitert Vector um die folgenden Methoden:
push() – legt ein Element auf den Stack
pop() – entnimmt das oberste Element vom Stack
peek() – gibt das oberste Element des Stacks zurück, ohne es vom Stack zu entfernen
empty() – prüft, ob der Stack leer ist; da Stack bereits die isEmpty()-Methode von Vector erbt, ist die empty()-Methode überflüssig; warum die JDK-Entwickler sie eingebaut haben, ist mir ein Rätsel.
search() – sucht ein Element auf dem Stack und gibt dessen Entfernung zur Spitze des Stacks zurück
Die Funktionsweise der Methoden zeige ich im folgenden Beispiel.
Genau wie Vector ist auch Stack threadsicher: Alle Methoden sind synchronized.
Java Stack Beispiel
Die folgenden Code-Schnipsel zeigen eine beispielhafte Verwendung von Stack (den kompletten Code findest du in der Klasse JavaStackDemo im GitHub-Repo).
Zuerst legen wir einen Stack an und schieben per push() die Elemente „apple“, „orange“ und „pear“ auf den Stack:
Stack<String> stack = new Stack<>();
stack.push("apple");
stack.push("orange");
stack.push("pear");Code-Sprache:Java(java)
Danach geben wir den Inhalt des Stacks auf der Konsole aus – sowie die Ergebnisse von peek() und empty():
Die toString()-Methode von Stack gibt die Elemente also von unten nach oben aus. Das zuletzt eingefügte Element „pear“ liegt auf der Spitze des Stacks.
Mit search() können wir nach einem Element suchen:
Das bedeutet, dass „apple“ an dritter Position im Stack steht. Das liegt daran, dass wir nach „apple“ zwei weitere Element auf den Stack geschoben haben.
Da der Stack jetzt leer ist, wird eine EmptyStackException geworfen:
Exception in thread "main" java.util.EmptyStackException
at java.base/java.util.Stack.peek(Stack.java:101)
at java.base/java.util.Stack.pop(Stack.java:83)
at eu.happycoders.demos.stack.JavaStackDemo.main(JavaStackDemo.java:28)Code-Sprache:Klartext(plaintext)
Genau wie pop() würde auch peek() bei einem leerem Stack eine EmptyStackException werfen.
Warum man Stack nicht (mehr) verwenden sollte
Die Java-Entwickler empfehlen java.util.Stack nicht mehr zu verwenden. Das Javadoc besagt:
„A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class.“
Was genau bedeutet das? Meiner Meinung nach sollte Stack aus den folgenden Gründen nicht verwendet werden:
Durch die Erweiterung von Vector stellt Stack Operationen zur Verfügung, die in einem Stack nichts zu suchen haben, so wie der Zugriff auf Elemente über deren Index oder das Einfügen und Löschen von Elementen an beliebigen Positionen.
Stack implementiert kein Interface. Mit der Verwendung von Stack legt man sich also auf eine bestimmte Implementierung fest.
Die Verwendung von synchronized bei jedem Methodenaufruf ist kein besonders performantes Mittel, um eine Datenstruktur threadsicher zu machen. Besser ist in der Regel optimistisches Locking durch CAS („Compare-and-swap“)-Operationen, wie sie in den threadsicheren Queue- und Deque-Implementierungen zu finden sind.
Stack-Alternativen
Stattdessen empfehlen die Java-Entwickler eine der Deque-Implementierungen wie bspw. ArrayDeque zu verwenden.
Wie du siehst, ist der Code nahezu identisch zum vorherigen Beispiel.
Allerdings ist zu bedenken, dass auch Deques Operationen anbieten, die ein Stack eigentlich nicht zur Verfügung stellen sollte, wie z. B. das Einfügen und Entfernen von Elementen am Boden des Stacks.
Alternativ kann man eine eigene Stack-Klasse implementieren.
In den nächsten Teile dieses Tutorials stelle ich verschiedene Stack-Implementierungen vor:
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
In diesem Tutorial lernst du alles über den abstrakten Datentyp „Stack“ (deutsch: „Stapelspeicher“, „Kellerspeicher“ oder kurz „Stapel“, „Keller“):
Wie funktioniert ein Stack?
Was sind die Anwendungsgebiete für Stacks?
Wie verwendet man die Java-Klasse „Stack“?
Wie implementiert man einen eigenen Stack in Java?
Was ist ein Stack?
Ein Stack ist eine Sammlung von Elementen, bei der die Elemente nur auf einer Seite (in grafischen Darstellungen klassischerweise oben) eingefügt und wieder entnommen werden können.
Am besten stellt man sich einen Stack wie einen Tellerstapel vor:
Tellerstapel
Neue Teller können nur oben auf den Stapel gelegt werden, und Teller können auch nur von oben wieder entnommen werden.
Da dadurch der zuletzt hinzugefügte Teller als erstes wieder entnommen wird, spricht man vom Last-in-First-out-Prinzip (LIFO).
LIFO-Prinzip beim Stack
Beim abstrakten Datentyp „Stack“ könnte das dann in etwa wie folgt aussehen:
Stack-Datenstruktur
Die Grafik zeigt einen Stack, der einige Strings enthält. Als nächstes Element wird „grape“ auf den Stack gelegt. Danach würden wir „grape“ auch als erstes wieder entnehmen müssen.
Eine Stack-Datenstruktur bietet in der Regel die folgenden Operationen an:
„Push“: Hinzufügen eines Elements auf den Stack
„Pop“: Entnehmen eines Elements von der Oberseite des Stacks
„Peek“ oder „Top“: Betrachten des obersten Elements des Stapels, ohne es zu entnehmen
Eine Prüfung, ob der Stack leer ist
Anwendungsgebiete für Stacks
Du kannst dir z. B. die Webseiten-Historie innerhalb eines Browser-Tabs als Stack vorstellen: Jedesmal, wenn du einen Link anklickst, wird die vorherige URL auf einen Stack gelegt. Beim Betätigen des Zurück-Buttons wird die oberste URL des Stacks entnommen und wieder angezeigt.
In ähnlicher Weise werden bei der Ausführung eines Computerprogramms die Rücksprungsadressen beim Aufruf von Methoden auf den sogennanten Call Stack gelegt (deutsch: „Aufrufstapel“), so dass nach Ausführung der Methode an die Aufrufposition zurückgesprungen werden kann. Der durch eine zu tiefe Verschachtelung verursachte StackOverflowError ist dir vielleicht schon mal begegnet.
Auch Compiler und Parser verwenden Stacks, z. B. bei der Verarbeitung von XML- und JSON-Dokumenten oder der Evaluierung von mathematischen Ausdrücken.
In der Regel wird ein Stack mit einem Array oder einer verketteten Liste implementiert. Bei beiden Varianten ist der Aufwand für das Einfügen oder Entnehmen eines Elements konstant und hängt nicht von der Anzahl der im Stack vorhandenen Elemente ab.
Die Zeitkomplexität lautet somit: O(1).
Stacks können auch mit Queues implementiert werden – das aber eher zu Schulungszwecken. Die Zeitkomplexität ist dann höher. Mehr dazu liest du im entsprechenden Teil des Tutorials.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Der Rot-Schwarz-Baum ist eine weit verbreitete konkrete Implementierung eines selbstbalancierenden binären Suchbaums. Im JDK wird er in der TreeMap und seit Java 8 auch bei Bucket-Kollisionen in der HashMap verwendet. Wie funktioniert er?
In diesem Artikel erfährst du:
Was ist ein Rot-Schwarz-Baum?
Wie fügt man Elemente in einen Rot-Schwarz-Baum ein? Wie entfernt man sie?
Nach welchen Regeln wird ein Rot-Schwarz-Baum balanciert?
Wie implementiert man einen Rot-Schwarz-Baum in Java?
Wie bestimmt man die Zeitkomplexität?
Was unterscheidet einen Rot-Schwarz-Baum von anderen Datenstrukturen?
Ein Rot-Schwarz-Baum ist ein selbstbalancierender binärer Suchbaum, d. h. ein binärer Suchbaum, der automatisch eine gewisse Balance aufrechterhält.
Jedem Knoten ist eine Farbe (rot oder schwarz) zugewiesen. Ein Satz von Regeln legt fest, wie diese Farben angeordnet sein müssen (z. B. darf ein roter Knoten keine roten Kinder haben). Durch diese Anordnung wird sichergestellt, dass der Baum eine gewisse Balance erhält.
Nach dem Einfügen und Löschen von Knoten werden recht komplexe Algorithmen angewendet, um die Einhaltung der Regeln zu überprüfen – und bei Abweichungen die vorgeschriebenen Eigenschaften durch Umfärben von Knoten und Rotationen wiederherzustellen.
NIL-Knoten im Rot-Schwarz-Baum
Rot-Schwarz-Bäume werden in der Literatur mit und ohne sogenannte NIL-Knoten dargestellt. Ein NIL-Knoten ist ein Blatt, das keinen Wert enthält. NIL-Knoten werden im späteren Verlauf für die Algorithmen relevant, um z. B. Farben von Onkel- oder Geschwister-Knoten zu bestimmen.
In Java können NIL-Knoten einfach durch null-Referenzen dargestellt werden; dazu später mehr.
Beispiel für einen Rot-Schwarz-Baum
Im folgenden Beispiel siehst du zwei mögliche Darstellungen eines Rot-Schwarz-Baums. Die erste Grafik zeigt den Baum ohne (d. h. mit impliziten) NIL- Blättern; die zweite Grafik zeigt den Baum mit expliziten NIL-Blättern.
Rot-Schwarz-Baum mit impliziten NIL-Blättern
Rot-Schwarz-Baum mit expliziten NIL-Blättern
Im Verlauf dieses Artikels werde ich auf die Darstellung der NIL-Blätter in der Regel verzichten. Bei der Erklärung der Einfüge- und Löschoperationen werde ich sie vereinzelt anzeigen, wenn es das Verständnis des jeweiligen Algorithmus erleichert.
Eigenschaften eines Rot-Schwarz-Baums
Die Balance des Rot-Schwarz-Baums wird durch folgende Regeln sichergestellt:
Jeder Knoten ist entweder rot oder schwarz.
(Die Wurzel ist schwarz.)
Alle NIL-Blätter sind schwarz.
Ein roter Knoten darf keine roten Kinder haben.
Alle Pfade von einem Knoten zu den darunterliegenden Blättern enthalten die gleiche Anzahl schwarzer Knoten.
Regel 2 steht in Klammern, da sie auf die Balance des Baumes keinerlei Auswirkung hat. Wenn ein Kind einer roten Wurzel ebenfalls rot ist, muss die Wurzel laut Regel 4 schwarz gefärbt werden. Wenn eine rote Wurzel allerdings nur schwarze Kinder hat, bringt es keinen Vorteil die Wurzel schwarz zu färben.
Von daher wird Regel 2 in der Literatur oft weggelassen.
Ich werde in der Erklärung der Einfüge- und Löschoperationen und im Java-Code darauf hinweisen, wo es Unterschiede gäbe, wenn auch Regel 2 umgesetzt würde. Soviel im Voraus: Der Unterschied ist pro Operation nur eine Zeile Code :)
Aus Regeln 4 und 5 folgt übrigens, dass ein roter Knoten immer entweder zwei NIL-Blätter hat oder zwei schwarze Kind-Knoten mit Werten. Hätte er ein NIL-Blatt und ein schwarzes Kind mit Wert, dann würden die Pfade durch dieses Kind mindestens einen schwarzen Knoten mehr haben als der Pfad zum NIL-Blatt, und das würde Regel 5 verletzen.
Höhe des Rot-Schwarz-Baums
Als Höhe des Rot-Schwarz-Baums bezeichnen wir die maximale Anzahl an Knoten von der Wurzel bis zu einem NIL-Blatt, die Wurzel nicht eingerechnet. Die Höhe des Rot-Schwarz-Baums im Beispiel oben beträgt 4:
Höhe eines Rot-Schwarz-Baums
Aus Regeln 3 und 4 folgt:
Der längste Pfad von der Wurzel zu einem Blatt (die Wurzel nicht eingerechnet) ist maximal doppelt so lang wie der kürzeste Pfad von der Wurzel zu einem Blatt.
Dies ist einfach erklärt:
Nehmen wir an, der kürzeste Pfad hat (zusätzlich zur Wurzel) n schwarze und keine roten Knoten. Dann könnten wir noch einmal n rote Knoten vor jedem schwarzen Knoten einfügen, ohne Regel 3 zu brechen (die man auch umformulieren könnte in: es dürfen keine zwei rote Knoten aufeinander folgen).
Das folgende Beispiel zeigt links den kürzestestmöglichen Pfad und rechts den längstmöglichen Pfad durch einen Rot-Schwarz-Baum der Höhe 4:
Kürzester und längster Pfad in einem Rot-Schwarz-Baum
Die Pfade zu den NIL-Blättern links haben eine Länge (exklusive Wurzel) von 2; die Pfade zu den NIL-Blättern rechts unten haben eine Länge von 4.
Schwarz-Höhe des Rot-Schwarz-Baums
Als Schwarz-Höhe bezeichnet man die Anzahl schwarzer Knoten von einem bestimmten Knoten bis zu seinen Blättern. Die schwarzen NIL-Blätter werden dabei mitgezählt, der Startknoten nicht.
Die Schwarz-Höhe des gesamten Baumes ist die Anzahl der schwarzen Knoten von der Wurzel (diese wird nicht mitgezählt) bis zu den NIL-Blättern.
Die Schwarz-Höhe aller bisher gezeigten Rot-Schwarz-Bäume ist 2.
Implementierung eines Rot-Schwarz-Baums in Java
Als Ausgangspunkt für für die Implementierung des Rot-Schwarz-Baums in Java verwende ich den Java-Quellcode für den binären Suchbaum aus dem zweiten Teil der Binärbaum-Serie.
Knoten werden durch die Klasse Node dargestellt. Als Knotenwert verwenden wir der Einfachheit halber int-Primitive.
Neben den Kind-Knoten left und right benötigen wir für die Implementierung des Rot-Schwarz-Baums eine Referenz auf den Elternknoten parent sowie die Farbe des Knotens, color. Diese speichern wir in einem boolean, wobei wir rot als false festlegen und schwarz als true.
Den Rot-Schwarz-Baum implementieren wir in der Klasse RedBlackTree. Diese erweitert die im zweiten Teil der Serie vorgestellte Klasse BaseBinaryTree (die im Wesentlichen eine getRoot()-Funktion zur Verfügung stellt).
Die Operationen (Einfügen, Suche, Löschen) werden in den folgenden Abschnitten nach und nach hinzugefügt.
Doch zunächst müssen wir einige Hilfsfunktionen definieren.
Rot-Schwarz-Baum Rotation
Einfügen und Löschen funktioniert grundsätzlich so wie im Artikel über binäre Suchbäume beschrieben.
Nach dem Einfügen und Löschen werden die Rot-Schwarz-Regeln (s. o.) überprüft. Wenn diese verletzt wurden, müssen sie wiederhergestellt werden. Dies geschieht durch Umfärben von Knoten und durch Rotationen.
Die Rotation funktioniert exakt wie bei den AVL-Bäumen, die ich im vorangegangenen Tutorial beschrieben habe. Ich zeige dir hier noch einmal die entsprechenden Diagramme. Ausführliche Erklärungen findest du im Abschnitt „AVL-Baum-Rotationen“ des eben genannten Artikels.
Rechts-Rotation
Die folgende Grafik zeigt eine Rechts-Rotation. Die Farben haben keinen Bezug zu denen des Rot-Schwarz-Baumes. Sie dienen lediglich der besseren Nachverfolgung der Knotenbewegungen.
Der linke Knoten L wird zur neuen Wurzel, die Wurzel N zu dessen rechtem Kind. Das rechte Kind LR des vor der Rotation linken Knotens L wird zum linken Kind des nach der Rotation rechten Knotens N. Die zwei weißen Knoten LL und R ändern ihre relative Position nicht.
Rechts-Rotation im Rot-Schwarz-Baum
Der Java-Code ist etwas länger als beim AVL-Baum – aus folgenden zwei Gründen:
Wir müssen auch die parent-Referenzen der Knoten aktualisieren (im AVL-Baum haben wir ohne parent-Referenzen gearbeitet).
Wir müssen die Referenzen von und zum Eltern-Knoten desjenigen Knotens, der zu Beginn der Rotation oben liegt (in der Grafik N), aktualisieren. Dies geschah beim AVL-Baum indirekt durch das Zurückgeben der neuen Wurzel des rotierten Teilbaums und das „Einhängen“ der Rotation in den rekursiven Aufruf der Einfüge- und Lösch-Operationen.
Die am Ende aufgerufene Methode replaceParentsChild() setzt die Eltern-Kind-Beziehung zwischen dem Eltern-Knoten des ehemaligen Wurzelknotens N des rotierten Teilbaums und dessen neuen Wurzelknoten L. Du findest sie im Code ab Zeile 388:
privatevoidreplaceParentsChild(Node parent, Node oldChild, Node newChild){
if (parent == null) {
root = newChild;
} elseif (parent.left == oldChild) {
parent.left = newChild;
} elseif (parent.right == oldChild) {
parent.right = newChild;
} else {
thrownew IllegalStateException("Node is not a child of its parent");
}
if (newChild != null) {
newChild.parent = parent;
}
}Code-Sprache:Java(java)
Links-Rotation
Die Links-Rotation funktioniert analog: Der rechte Knoten R wandert hoch an die Spitze. Die Wurzel N wird zum linken Kind von R. Das linke Kind RL des ehemals rechten Knotens R wird zum rechten Kind des nach der Rotation linken Knotens N. L und RR ändern ihre relative Position nicht.
Wie jeder Binärbaum bietet auch der Rot-Schwarz-Baum Operationen zum Suchen, Einfügen und Löschen von Knoten. Diese gehen wir in den folgenden Abschnitten Schritt für Schritt durch.
An dieser Stelle möchte ich dir den Rot-Schwarz-Baum-Simulator von David Galles empfehlen. Mit diesem kannst du beliebige Einfüge-, Lösch- und Suchoperationen grafisch animiert darstellen.
Suche im Rot-Schwarz-Baum
Die Suche funktioniert wie in jedem binären Suchbaum: Wir vergleichen den Suchschlüssel zunächst mit der Wurzel. Ist der Suchschlüssel kleiner, setzen wir die Suche im linken Teilbaum fort; ist der Suchschlüssel größer, setzen wir die Suche im rechten Teilbaum fort.
Dies wiederholen wir solange, bis wir entweder den gesuchten Knoten gefunden haben – oder bis wir ein NIL-Blatt (im Java-Code: eine null-Referenz) erreicht haben. Das bedeutet dann, dass der gesuchte Schlüssel im Baum nicht existiert.
Im Abschnitt „Suche im binären Suchbaum“ des o. g. Artikels findest du auch eine rekursive Version der Suche.
Einfügen in einen Rot-Schwarz-Baum
Um einen neuen Knoten einzufügen, gehen wir zunächst so vor wie im Abschnitt „Einfügen im binären Suchbaum“ des entsprechenden Artikels beschrieben. D. h. wir suchen von der Wurzel abwärts die Einfügeposition und hängen den neuen Knoten an ein Blatt oder Halbblatt an.
publicvoidinsertNode(int key){
Node node = root;
Node parent = null;
// Traverse the tree to the left or right depending on the keywhile (node != null) {
parent = node;
if (key < node.data) {
node = node.left;
} elseif (key > node.data) {
node = node.right;
} else {
thrownew IllegalArgumentException("BST already contains a node with key " + key);
}
}
// Insert new node
Node newNode = new Node(key);
newNode.color = RED;
if (parent == null) {
root = newNode;
} elseif (key < parent.data) {
parent.left = newNode;
} else {
parent.right = newNode;
}
newNode.parent = parent;
fixRedBlackPropertiesAfterInsert(newNode);
}
Code-Sprache:Java(java)
Den neuen Knoten färben wir initial rot, so dass Regel 5 erfüllt ist, d. h. dass alle Pfade auch nach dem Einfügen die gleiche Anzahl schwarzer Knoten aufweisen.
Wenn der Elternknoten des eingefügten Knotens allerdings ebenfalls rot ist, haben wir Regel 4 verletzt. Wir müssen dann durch Umfärben und/oder Rotationen den Baum so reparieren, dass alle Regeln wieder erfüllt sind. Dies geschieht in der Methode fixRedBlackPropertiesAfterInsert(), die in der letzten Zeile der insertNode()-Methode aufgerufen wird.
Bei der Reparatur müssen wir fünf unterschiedliche Fälle behandeln:
Fall 1: Neuer Knoten ist die Wurzel
Fall 2: Elternknoten ist rot und die Wurzel
Fall 3: Elternknoten und Onkelknoten sind rot
Fall 4: Elternknoten ist rot, Onkelknoten ist schwarz, eingefügter Knoten ist „innerer Enkel“
Fall 5: Elternknoten ist rot, Onkelknoten ist schwarz, eingefügter Knoten ist „äußerer Enkel“
Die fünf Fälle werden im folgenden beschrieben.
Fall 1: Neuer Knoten ist die Wurzel
Sollte der neue Knoten die Wurzel sein, müssen wir nichts weiter tun. Es sein denn, wir arbeiten mit Regel 2 („die Wurzel ist immer schwarz“). Dann müssten wir die Wurzel schwarz färben.
Fall 2: Elternknoten ist rot und die Wurzel
In diesem Fall ist Regel 4 verletzt („kein rot-rot!“). Wir müssen nun lediglich die Wurzel schwarz färben. Dies führt dazu, dass Regel 4 wieder eingehalten wird.
Umfärben einer roten Wurzel
Und Regel 5? Da die Wurzel bei dieser Regel nicht mitgezählt wird, haben alle Pfade nach wie vor einen schwarzen Knoten (die in der Grafik nicht eingezeichneten NIL-Blätter). Und würden wir die Wurzel mitzählen, dann hätten alle Pfade jetzt zwei statt einen schwarze Knoten – auch das wäre erlaubt.
Wenn wir mit Regel 2 arbeiten („die Wurzel ist immer schwarz“), dann haben wir die Wurzel bereits in Fall 1 schwarz gefärbt, und Fall 2 kann nicht mehr eintreten.
Fall 3: Elternknoten und Onkelknoten sind rot
Als Onkelknoten bezeichnen wir den Geschwisterknoten des Elternknotens, also das zweite Kind des Großelternknotens neben dem Elternknoten. Die folgende Grafik sollte das verständlich machen: Eingefügt wurde die 81; deren Elternknoten ist die 75, der Großelternknoten die 19 und der Onkel die 18.
Sowohl der Elternknoten als auch der Onkelknoten sind rot. In diesem Fall machen wir folgendes:
Wir färben Eltern- und Onkelknoten (im Beispiel 18 und 75) schwarz und den Großelternknoten (im Beispiel 19) rot. Damit ist Regel 4 („kein rot-rot!“) am eingefügten Knoten wieder erfüllt. Die Anzahl schwarzer Knoten pro Pfad ändert sich nicht (im Beispiel bleibt sie bei 2).
Umfärben von Eltern-, Großeltern- und Onkelknoten
Allerdings könnte es nun am Großelternknoten zu zwei roten Knoten in Folge kommen – nämlich dann, wenn auch der Urgroßelternknoten (im Beispiel die 17) rot wäre. In diesem Fall müssten wir weitere Reparaturen vornehmen. Dies würden wir machen, indem wir die Reparaturfunktion rekursiv auf dem Großelternknoten aufrufen.
Fall 4: Elternknoten ist rot, Onkelknoten ist schwarz, eingefügter Knoten ist „innerer Enkel“
Diesen Fall muss ich zunächst erklären: „innerer Enkel“ bedeutet, dass der Weg vom Großeltern-Knoten zum eingefügten Knoten ein Dreieck bildet, wie in folgender Grafik anhand der 19, 75 und 24 gezeigt. In diesem Beispiel sieht man außerdem, dass auch ein NIL-Blatt als schwarzer Onkelknoten angesehen wird (entsprechend Regel 3).
(Die jeweils zwei NIL-Blätter der 9 und der 24, sowie das rechte NIL-Blatt der 75 habe ich der Übersicht halber nicht mit eingezeichnet.)
Fall 4: Schwarzer Onkelknoten, eingefügter Knoten ist „innerer“ Enkel
In diesem Fall rotieren wir zunächst am Elternknoten in entgegengesetzter Richtung des eingefügten Knotens.
Was bedeutet das?
Wenn der eingefügte Knoten linkes Kind seines Elternknotens ist, rotieren wir am Elternknoten nach rechts. Wenn der eingefügte Knoten rechtes Kind ist, dann rotieren wir nach links.
Im Beispiel ist der eingefügte Knoten (die 24) linkes Kind, also rotieren wir am Elternknoten (im Beispiel 75) nach rechts:
Schritt 1: Rechts-Rotation um Elternknoten
Als zweites rotieren wir am Großelternknoten in entgegengesetzter Richtung zur vorherigen Rotation (im Beispiel an der 19 linksherum):
Schritt 2: Links-Rotation um Großelternknoten
Zuletzt färben wir den gerade eingefügten Knoten (im Beispiel die 24) schwarz und den ursprünglichen Großelternknoten (im Beispiel die 19) rot:
Schritt 3: Umfärben des eingefügten und des ursprünglichen Großelternknotens
Da an der Spitze des zuletzt rotierten Teilbaumes jetzt ein schwarzer Knoten steht, kann es dort nicht zu einer Verletzung von Regel 4 („kein rot-rot!“) kommen.
Auch das Rotfärben des ursprünglichen Großelternknotens (19) kann nicht zu einer Verletzung von Regel 4 führen. Denn dessen linkes Kind ist der Onkelknoten, der per Definition dieses Falles schwarz ist. Und das rechte Kind ist als Folge der zweiten Rotation das linke Kind des eingefügten Knotens, also ein schwarzes NIL-Blatt.
Die eingefügte rote 75 hat als Kinder zwei NIL-Blätter, somit gibt es auch hier keinen Verstoß gegen Regel 4.
Die Reparatur ist damit abgeschlossen, ein rekursiver Aufruf der Reparaturfunktion ist nicht erforderlich.
Fall 5: Elternknoten ist rot, Onkelknoten ist schwarz, eingefügter Knoten ist „äußerer Enkel“
„Äußerer Enkel“ bedeutet, dass der Weg vom Großelternknoten zum eingefügten Knoten eine Linie bildet, wie in folgendem Beispiel die 19, die 75 und die gerade eingefügte 81:
Fall 5: Schwarzer Onkelknoten, eingefügter Knoten ist „äußerer“ Enkel
In diesem Fall rotieren wir am Großelternknoten (im Beispiel 19) in entgegengesetzter Richtung des Eltern- und eingefügten Knotens (beide gehen in diesem Fall ja in die gleiche Richtung). Im Beispiel sind Eltern- und eingefügter Knoten jeweils rechtes Kind, also rotieren wir am Großelternknoten nach links:
Schritt 1: Links-Rotation um Großelternknoten
Danach färben wir den ehemaligen Elternknoten (im Beispiel die 75) schwarz und den ehemaligen Großelternknoten (die 19) rot:
Schritt 2: Umfärben von ehemaligem Eltern- und Großelternknoten
Wie am Ende von Fall 4 haben wir an der Spitze der Rotation einen schwarzen Knoten, so dass es dort zu keiner Verletzung von Regel 4 („kein rot-rot!“) kommen kann.
Das linke Kind der 19 ist nach der Rotation der ursprüngliche Onkelknoten, also per Fall-Definition schwarz; das rechte Kind der 19 ist das ursprünglich linke Kind des Elternknotens (75), welches ebenfalls ein schwarzes NIL-Blatt sein muss, da sonst der rechte Platz, an dem wir die 81 eingefügt haben, nicht frei gewesen wäre (denn ein roter Knoten hat immer entweder zwei schwarze Kinder mit Wert oder zwei schwarze NIL-Kinder).
Die rote 81 ist der eingefügte Knoten und hat daher ebenfalls zwei schwarze NIL-Blätter.
Die Reparatur des Rot-Schwarz-Baumes ist an dieser Stelle abgeschlossen.
Wer genau aufgepasst hat, stellt fest: Fall 5 entspricht exakt der zweiten Rotation aus Fall 4. Im Code wird sich das dadurch zeigen, dass für Fall 4 nur die erste Rotation implementiert ist und danach zum Code von Fall 5 gesprungen wird.
Implementierung der Reparaturfunktion nach dem Einfügen
Die vollständige Reparaturfunktion findest du in RedBlackTree ab Zeile 64. Die Fälle 1 bis 5 sind durch Kommentare markiert. Die Fälle 4 und 5 sind in 4a/4b und 5a/5b aufgeteilt, je nachdem, ob der Elternknoten linkes (4a/5a) oder rechtes Kind (4b/5b) des Großelternknotens ist.
privatevoidfixRedBlackPropertiesAfterInsert(Node node){
Node parent = node.parent;
// Case 1: Parent is null, we've reached the root, the end of the recursionif (parent == null) {
// Uncomment the following line if you want to enforce black roots (rule 2):// node.color = BLACK;return;
}
// Parent is black --> nothing to doif (parent.color == BLACK) {
return;
}
// From here on, parent is red
Node grandparent = parent.parent;
// Case 2:// Not having a grandparent means that parent is the root. If we enforce black roots// (rule 2), grandparent will never be null, and the following if-then block can be// removed.if (grandparent == null) {
// As this method is only called on red nodes (either on newly inserted ones - or -// recursively on red grandparents), all we have to do is to recolor the root black.
parent.color = BLACK;
return;
}
// Get the uncle (may be null/nil, in which case its color is BLACK)
Node uncle = getUncle(parent);
// Case 3: Uncle is red -> recolor parent, grandparent and uncleif (uncle != null && uncle.color == RED) {
parent.color = BLACK;
grandparent.color = RED;
uncle.color = BLACK;
// Call recursively for grandparent, which is now red.// It might be root or have a red parent, in which case we need to fix more...
fixRedBlackPropertiesAfterInsert(grandparent);
}
// Parent is left child of grandparentelseif (parent == grandparent.left) {
// Case 4a: Uncle is black and node is left->right "inner child" of its grandparentif (node == parent.right) {
rotateLeft(parent);
// Let "parent" point to the new root node of the rotated sub-tree.// It will be recolored in the next step, which we're going to fall-through to.
parent = node;
}
// Case 5a: Uncle is black and node is left->left "outer child" of its grandparent
rotateRight(grandparent);
// Recolor original parent and grandparent
parent.color = BLACK;
grandparent.color = RED;
}
// Parent is right child of grandparentelse {
// Case 4b: Uncle is black and node is right->left "inner child" of its grandparentif (node == parent.left) {
rotateRight(parent);
// Let "parent" point to the new root node of the rotated sub-tree.// It will be recolored in the next step, which we're going to fall-through to.
parent = node;
}
// Case 5b: Uncle is black and node is right->right "outer child" of its grandparent
rotateLeft(grandparent);
// Recolor original parent and grandparent
parent.color = BLACK;
grandparent.color = RED;
}
}
Code-Sprache:Java(java)
Die Hilfsfunktion getUncle() findest du ab Zeile 152:
private Node getUncle(Node parent){
Node grandparent = parent.parent;
if (grandparent.left == parent) {
return grandparent.right;
} elseif (grandparent.right == parent) {
return grandparent.left;
} else {
thrownew IllegalStateException("Parent is not a child of its grandparent");
}
}Code-Sprache:Java(java)
Anmerkungen zur Implementierung
Im Gegensatz zum AVL-Baum können wir die Reparatur-Funktion des Rot-Schwarz-Baumes nicht ohne weiteres in die bestehende Rekursion aus BinarySearchTreeRecursive einhängen. Der Grund dafür ist, dass wir nicht nur an demjenigen Knoten rotieren müssen, unter dem wir den neuen Knoten eingefügt haben, sondern ggf. auch am Großelternknoten (Fälle 3 und 4).
Du wirst in der Literatur zahlreiche alternative Implementierungen finden. Diese sind teilweise minimal performanter als der hier vorgestellte Weg, da mehrere Schritte kombiniert werden. Das ändert nichts an der Größenordnung der Performance, kann aber ein paar Prozente herausholen. Mir war es in erster Linie wichtig den Algorithmus verständlich zu implementieren. Die performanteren Algorithmen sind immer auch komplexer.
Ich habe das iterative Einfügen hier in zwei Schritten implementiert – erst Suche, dann Einfügen – im Gegensatz zu BinarySearchTreeIterative, wo beides kombiniert war. Das macht das Lesen etwas einfacher, benötigt allerdings auch einen zusätzlichen „if (key < parent.data)„-Check, um zu bestimmen, ob der neue Knoten als linkes oder rechtes Kind unter seinen Elternknoten eingefügt werden muss.
Löschen aus einem Rot-Schwarz-Baum
Wenn du das Kapitel über das Einfügen gerade fertiggelesen hast, solltest du vielleicht eine kurze Pause machen. Denn das Löschen ist noch komplexer.
Zunächst gehen wir so vor, wie im Abschnitt „Löschen im binären Suchbaum“ des Artikels über binäre Suchbäume im Allgemeinen beschrieben.
Hier noch einmal eine kurze Zusammenfassung:
Hat der zu löschende Knoten keine Kinder, entfernen wir ihn einfach.
Hat der zu löschende Knoten ein Kind, dann entfernen wir den Knoten und lassen sein einziges Kind an dessen Position aufrücken.
Hat der zu löschende Knoten zwei Kinder, dann kopieren wir den Inhalt (nicht die Farbe!) des In-Order-Nachfolgers des rechten Kindes in den zu löschenden Knoten und löschen danach den In-Order-Nachfolger nach Vorschrift 1 oder 2 (der In-Order-Nachfolger hat per Definiton maximal ein Kind).
Danach müssen wir die Regeln des Baumes überprüfen und ggf. den Baum reparieren. Dazu müssen wir uns merken, welche Farbe der gelöschte Knoten hat und welchen Knoten wir haben aufrücken lassen.
Ist der gelöschte Knoten rot, dann können wir keine Regel verletzt haben: Weder kann es dadurch zu zwei aufeinanderfolgenden roten Knoten kommen (Regel 4), noch ändert sich die Anzahl schwarzer Knoten auf irgendeinem Pfad (Regel 5).
Ist der gelöschte Knoten allerdings schwarz, haben wir Regel 5 garantiert verletzt (außer der Baum enthielt nichts als eine schwarze Wurzel) und Regel 4 möglicherweise auch – nämlich dann, wenn sowohl Elternknoten als auch das aufgerückte Kind des gelöschten Knotens rot waren.
Hier zunächst der Code für das eigentliche Löschen eines Knotens (Klasse RedBlackTree, Zeile 163). Unter dem Code erkläre ich dir dessen Teile:
publicvoiddeleteNode(int key){
Node node = root;
// Find the node to be deletedwhile (node != null && node.data != key) {
// Traverse the tree to the left or right depending on the keyif (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
// Node not found?if (node == null) {
return;
}
// At this point, "node" is the node to be deleted// In this variable, we'll store the node at which we're going to start to fix the R-B// properties after deleting a node.
Node movedUpNode;
boolean deletedNodeColor;
// Node has zero or one childif (node.left == null || node.right == null) {
movedUpNode = deleteNodeWithZeroOrOneChild(node);
deletedNodeColor = node.color;
}
// Node has two childrenelse {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = findMinimum(node.right);
// Copy inorder successor's data to current node (keep its color!)
node.data = inOrderSuccessor.data;
// Delete inorder successor just as we would delete a node with 0 or 1 child
movedUpNode = deleteNodeWithZeroOrOneChild(inOrderSuccessor);
deletedNodeColor = inOrderSuccessor.color;
}
if (deletedNodeColor == BLACK) {
fixRedBlackPropertiesAfterDelete(movedUpNode);
// Remove the temporary NIL nodeif (movedUpNode.getClass() == NilNode.class) {
replaceParentsChild(movedUpNode.parent, movedUpNode, null);
}
}
}Code-Sprache:Java(java)
Die ersten Zeilen des Codes suchen den zu löschenden Knoten; wird dieser nicht gefunden, wird die Methode beendet.
Wie es weiter geht, hängt von der Anzahl der Kinder zu löschenden Knotens ab.
Löschen eines Knotens mit keinem oder einem Kind
Hat der gelöschte Knoten maximal ein Kind, wird die Methode deleteNodeWithZeroOrOneChild() aufgerufen. Diese findest du im Quellcode ab Zeile 221:
private Node deleteNodeWithZeroOrOneChild(Node node){
// Node has ONLY a left child --> replace by its left childif (node.left != null) {
replaceParentsChild(node.parent, node, node.left);
return node.left; // moved-up node
}
// Node has ONLY a right child --> replace by its right childelseif (node.right != null) {
replaceParentsChild(node.parent, node, node.right);
return node.right; // moved-up node
}
// Node has no children -->// * node is red --> just remove it// * node is black --> replace it by a temporary NIL node (needed to fix the R-B rules)else {
Node newChild = node.color == BLACK ? new NilNode() : null;
replaceParentsChild(node.parent, node, newChild);
return newChild;
}
}
Code-Sprache:Java(java)
Die hier mehrfach aufgerufene Methode replaceParentsChild() habe ich dir bereits bei der Rotation vorgestellt.
Der Fall, dass der gelöschte Knoten schwarz ist und keine Kinder hat, stellt eine Besonderheit dar. Dieser wird im letzten else-Block behandelt:
Wir haben oben festgestellt, dass das Löschen eines schwarzen Knotens dazu führt, dass die Anzahl schwarzer Knoten nicht mehr auf allen Pfaden gleich ist. D. h., wir werden den Baum reparieren müssen. Die Baumreparatur beginnt (wie du in Kürze sehen wirst) immer beim aufgerückten Knoten.
Wenn der gelöschte Knoten keine Kinder hat, rückt quasi eines seiner NIL-Blätter an seine Position auf. Um später von diesem NIL-Blatt zu seinem Elternknoten navigieren zu können, brauchen wir einen speziellen Platzhalter. Dieser ist in der Klasse NilNode implementiert, die du im Quellcode ab Zeile 349 findest:
Die Methode deleteNodeWithZeroOrOneChild() gibt schließlich den aufgerückten Knoten zurück, den sich die aufrufende Methode deleteNode() in der Variablen movedUpNode merkt.
Löschen eines Knotens mit zwei Kindern
Hat der zu löschende Knoten zwei Kinder, suchen wir zunächst mit der Methode findMinimum() (Zeile 244) den In-Order-Nachfolger des Teilbaumes, der am rechten Kind beginnt:
Daraufhin kopieren wir die Daten des In-Order-Nachfolgers in den zu löschenden Knoten und rufen die oben vorgestellte Methode deleteNodeWithZeroOrOneChild() auf, um den In-Order-Nachfolger aus dem Baum zu entfernen. Wiederum merken wir uns den aufgerückten Knoten in movedUpNode.
Reparatur des Baumes
Hier noch einmal der letzte if-Block der deleteNode()-Methode:
Wie oben bereits festgestellt, werden durch das Löschen eines roten Knotens keine Regeln verletzt. Wenn der gelöschte Knoten hingegen schwarz ist, rufen wir die Reparaturmethode fixRedBlackPropertiesAfterDelete() auf.
Der ggf. in deleteNodeWithZeroOrOneChild() angelegte temporäre NilNode-Platzhalter wurde nur für den Aufruf der Reparaturfunktion benötigt und kann daher im Anschluss entfernt werden.
Beim Löschen müssen wir noch einen Fall mehr beachten als beim Einfügen: nämlich sechs. Im Gegensatz zum Einfügen ist dabei nicht die Farbe des Onkelknotens relevant, sondern die des Geschwisterknotens des aufgerückten Knotens.
Fall 1: Aufgerückter Knoten ist die Wurzel
Fall 2: Geschwisterknoten ist rot
Fall 3: Geschwisterknoten ist schwarz und hat zwei schwarze Kinder, Elternknoten ist rot
Fall 4: Geschwisterknoten ist schwarz und hat zwei schwarze Kinder, Elternknoten ist schwarz
Fall 5: Geschwisterknoten ist schwarz und hat mind. ein rotes Kind, „äußerer Neffe“ ist schwarz
Fall 6: Geschwisterknoten ist schwarz und hat mind. ein rotes Kind, „äußerer Neffe“ ist rot
Die folgenden Abschnitte beschreiben die sechs Fälle im Detail:
Fall 1: Aufgerückter Knoten ist die Wurzel
Wurde die Wurzel entfernt, rückt ein anderer Knoten an deren Position auf. Das kann nur dann passieren, wenn die Wurzel kein oder nur ein Kind hatte. Denn hätte die Wurzel zwei Kinder gehabt, wäre letztendlich der In-Order-Nachfolger entfernt worden und nicht der Wurzelknoten.
Wenn die Wurzel kein Kind hatte, ist die neue Wurzel ein schwarzer NIL-Knoten. Somit ist der Baum leer und gültig:
Fall 1a: Entfernen einer Wurzel ohne Kind
Wenn die Wurzel ein Kind hatte, dann musste dies rot sein und keine weiteren Kinder haben.
Denn: Hätte das rote Kind ein weiteres rotes Kind, wäre Regel 4 („kein rot-rot!“) verletzt gewesen. Hätte das rote Kind ein schwarzes Kind, dann hätten die Pfade durch den roten Knoten wenigstens einen schwarzen Knoten mehr als der NIL-Teilbaum der Wurzel, und damit wäre Regel 5 verletzt gewesen.
Somit besteht der Baum nur noch aus einer roten Wurzel und ist damit ebenfalls gültig.
Fall 1b: Entfernen einer Wurzel mit einem Kind
Sollten wir mit Regel 2 arbeiten („die Wurzel ist immer schwarz“), dann würden wir an dieser Stelle die Wurzel schwarz färben.
Fall 2: Geschwisterknoten ist rot
Für alle anderen Fälle prüfen wir zunächst die Farbe des Geschwisterknotens. Dies ist das zweite Kind des Elternknotens des gelöschten Knotens. In folgendem Beispiel löschen wir die 9; deren Geschwisterknoten ist die rote 19:
Fall 2: Roter Geschwisterknoten
In diesem Fall färben wir zunächst den Geschwisterknoten schwarz und den Elternknoten rot:
Schritt 1: Umfärben von Geschwister- und Elternknoten
Dadurch wurde offensichtlich Regel 5 verletzt: Die Pfade im rechten Teilbaum des Elternknotens haben jeweils zwei schwarze Knoten mehr als die des linken Teilbaum. Dies beheben wir durch eine Rotation um den Elternknoten in Richtung des gelöschten Knotens.
Im Beispiel haben wir den linken Knoten des Elternknotens gelöscht – wir führen daher eine Links-Rotation durch:
Schritt 2: Rotation um Elternknoten
Jetzt haben wir auf dem rechten Pfad zwei schwarze Knoten, auf dem zur 18 ebenfalls zwei. Allerdings haben wir nur einen schwarzen Knoten auf dem Pfad zum linken NIL-Blatt der 17 (zur Erinnerung: die Wurzel zählt nicht mit, die NIL-Knoten zählen mit – auch die in der Grafik nicht eingezeichneten).
Wir schauen auf den neuen Geschwisterknoten des gelöschten Knotens (im Beispiel die 18). Dieser ist jetzt in jedem Fall schwarz, denn es handelt sich um ein ursprüngliches Kind des roten Geschwisterknotens vom Anfang des Falls.
Außerdem hat der neue Geschwisterknoten schwarze Kinder. Deshalb färben wir den Geschwisterknoten (die 18) rot und den Elternknoten (die 17) schwarz:
(Schritt 3: Umfärben von Eltern- und neuem Geschwisterknoten)
Jetzt haben alle Pfade zwei schwarze Knoten; wir haben also wieder einen gültigen Rot-Schwarz-Baum.
Fall 2 ‒ Fall-Through
Tatsächlich habe ich in diesem letzten Schritt etwas vorweggenommen. Wir haben nämlich die Regeln von Fall 3 ausgeführt (deswegen ist der Bilduntertitel auch in Klammern).
In diesem letzten Schritt von Fall 2 haben wir immer einen schwarzen Geschwisterknoten. Dass dieser zwei schwarze Kinder hatte, wie für Fall 3 gefordert, war Zufall. Tatsächlich kann am Ende von Fall 2 jeder der Fälle 3 bis 6 eintreten und muss entsprechend der folgenden Abschnitte behandelt werden.
Fall 3: Geschwisterknoten ist schwarz und hat zwei schwarze Kinder, Elternknoten ist rot
In folgendem Beispiel löschen wir die 75 und lassen eines seiner schwarzen NIL-Blätter aufrücken.
(Nochmal zur Erinnerung: Ich zeige in den Grafiken nur dann NIL-Blätter an, wenn diese für das Verständnis relevant sind.)
Fall 3: Schwarzer Geschwisterknoten mit schwarzen Kindern und rotem Elternknoten
Das führt zu einem Verstoß von Regel 5: Im ganz rechten Pfad haben wir jetzt einen schwarzen Knoten weniger als in allen anderen.
Der Geschwisterknoten (im Beispiel die 18) ist schwarz und hat zwei schwarze Kinder (die nicht dargestellten NIL-Blätter). Der Elternknoten (die 19) ist rot. In diesem Fall reparieren wir den Baum wie folgt:
Wir färben den Geschwisterknoten (die 18) rot und den Elternknoten (die 19) schwarz:
Umfärben von Eltern- und Geschwisterknoten
Somit haben wir wieder einen gültigen Rot-Schwarz-Baum. Die Anzahl der schwarzen Knoten ist auf allen Pfaden gleich (wie von Regel 5 gefordert). Und da der Geschwisterknoten nur schwarze Kinder hat, kann es durch das Rotfärben desselben nicht zu einer Verletzung von Regel 4 („kein rot-rot!“) kommen.
Fall 4: Geschwisterknoten ist schwarz und hat zwei schwarze Kinder, Elternknoten ist schwarz
Im nächsten Beispiel löschen wir die 18:
Fall 4: Schwarzer Geschwisterknoten mit schwarzen Kindern und schwarzem Elternknoten
Dies führt (genau wie bei Fall 3) zu einem Verstoß gegen Regel 5: Auf dem Pfad zum gelöschten Knoten haben wir jetzt einen schwarzen Knoten weniger als auf allen anderen Pfaden.
Im Gegensatz zu Fall 3 ist bei Fall 4 der Elternknoten des gelöschten Knotens schwarz. Wir färben zunächst den Geschwisterknoten rot:
Schritt 1: Umfärben des Geschwisterknotens
Damit ist die Schwarzhöhe in demjenigen Teilbaum, der am Elternknoten beginnt, wieder einheitlich (nämlich 2). Im linken Teilbaum ist sie allerdings eins höher (3). Gegen Regel 5 wird also noch immer verstoßen.
Fall 4 ‒ Rekursion
Dieses Problem lösen wir, indem wir so tun, als hätten wir zwischen der 17 und der 19 einen schwarzen Knoten gelöscht (was den gleichen Effekt gehabt hätte). Dementsprechend rufen wir die Reparaturfunktion rekursiv auf dem Elternknoten, also der 19 auf (was in diesem Fall der aufgerückte Knoten gewesen wäre).
Die 19 hat einen schwarzen Geschwisterknoten (die 9) mit zwei schwarzen Kindern (3 und 12) und einem roten Elternteil (17). Dementsprechend sind wir jetzt wieder bei Fall 3.
Fall 3 lösen wir, in dem wir den Geschwisterknoten rot und den Elternknoten schwarz färben:
(Schritt 2: Umfärben von Eltern- und Geschwisterknoten)
Die Schwarzhöhe beträgt nun auf allen Pfaden 2. Unser Rot-Schwarz-Baum ist damit wieder valide.
Fall 5: Geschwisterknoten ist schwarz und hat mindestens ein rotes Kind, „äußerer Neffe“ ist schwarz
In diesem Beispiel löschen wir die 18:
Fall 5: Schwarzer Geschwisterknoten mit mindestens einem roten Kind und schwarzem „äußeren Neffen“
Als Folge haben wir wieder einen Verstoß gegen Regel 5, da der Teilbaum, der am Geschwisterknoten beginnt, jetzt eine um eins größere Schwarzhöhe hat.
Wir betrachten den „äußeren Neffen“ des gelöschten Knotens. „Äußerer Neffe“ bezeichnet dasjenige Kind des Geschwisterknotens, das gegenüber dem gelöschten Knoten liegt. Im Beispiel ist das das rechte, per Definition schwarze, NIL-Blatt unter der 75.
In folgender Grafik siehst du, dass Elternknoten, Geschwisterknoten und Neffe gemeinsam eine Linie bilden (im Beispiel die 19, die 75 und dessen rechtes NIL-Kind).
Wir beginnen mit der Reparatur, indem wir den inneren Neffen (im Beispiel die 24) schwarz färben und den Geschwisterknoten (die 75) rot:
Schritt 1: Umfärben von Geschwisterknoten und innerem Neffen
Danach führen wir eine Rotation am Geschwisterknoten in entgegengesetzter Richtung des gelöschten Knotens durch. Im Beispiel wurde das linke Kind des Elternknotens gelöscht, also erfolgt am Geschwisterknoten (der 75) eine Rotation nach rechts:
Schritt 2: Rotation um Geschwisterknoten
Wir führen erneut ein paar Umfärbungen durch:
Wir färben den Geschwisterknoten in der Farbe des Elternknotens (im Beispiel die 24 rot).
Dann färben wir den Elternknoten (die 19) sowie den äußeren Neffen des gelöschten Knotens, also das rechte Kind des neuen Geschwisterknotens (im Beispiel die 75) schwarz:
Schritt 3: Umfärben von Eltern- Geschwister- und Neffenknoten
Als letztes führen wir eine Rotation am Elternknoten in Richtung des gelöschten Knotens durch. Im Beispiel war der gelöschte Knoten das linke Kind, dementsprechend führen wir eine Links-Rotation aus (im Beispiel an der 19):
Schritt 4: Rotation um Elternknoten
Damit werden alle Rot-Schwarz-Regeln wieder eingehalten. Es gibt keine zwei aufeinanderfolgenden roten Knoten, und die Anzahl schwarzer Knoten beträgt auf allen Pfaden einheitlich zwei. Die Reparatur des Baumes ist damit abgeschlossen.
Fall 6: Geschwisterknoten ist schwarz und hat mindestens ein rotes Kind, „äußerer Neffe“ ist rot
Im letzten Beispiel, welches Fall 5 stark ähnelt, löschen wir ebenfalls die 18:
Fall 6: Schwarzer Geschwisterknoten mit mindestens einem roten Kind und rotem „äußeren Neffen“
Als Folge haben wir, wie in Fall 5, einen Verstoß gegen Regel 5, da der Pfad zum gelöschten Knoten nun einen schwarzen Knoten weniger enthält.
Bei Fall 6 ist, im Gegensatz zu Fall 5, der äußere Neffe (im Beispiel die 81) rot und nicht schwarz.
Wir färben zunächst den Geschwisterknoten in der Farbe des Elternknotens (im Beispiel die 75 rot). Danach färben wir den Elternknoten (im Beispiel die 19) und den äußeren Neffen (die 81) schwarz:
Schritt 1: Umfärben von Eltern- Geschwister- und Neffenknoten
Als zweites führen wir am Elternknoten eine Rotation in Richtung des gelöschten Knotens durch. Im Beispiel wurde das linke Kind seines Elternknotens gelöscht; entsprechend vollziehen wir eine Links-Rotation um die 19:
Schritt 2: Rotation um Elternknoten
Damit sind die Rot-Schwarz-Regeln wiederhergestellt. Es folgen keine zwei roten Knoten aufeinander, und die Anzahl der schwarzen Knoten ist auf allen Pfaden gleich (nämlich 2).
Die Vorschriften in diesem letzten Fall gleichen den letzten zwei Schritten aus Fall 5. Im Quellcode wirst du sehen, dass für Fall 5 nur dessen ersten zwei Schritte implementiert sind und die Ausführung dann zu Fall 6 springt, um die letzten zwei Schritte auszuführen.
Damit haben wir alle sechs Fälle betrachtet. Kommen wir zur Implementierung der Reparaturfunktion in Java.
Implementierung der Reparaturfunktion nach dem Löschen
Du findest die Reparaturmethode fixRedBlackPropertiesAfterDelete()im Quellcode ab Zeile 252. Die Fälle 1 bis 6 sind durch Kommentare markiert.
privatevoidfixRedBlackPropertiesAfterDelete(Node node){
// Case 1: Examined node is root, end of recursionif (node == root) {
// Uncomment the following line if you want to enforce black roots (rule 2):// node.color = BLACK;return;
}
Node sibling = getSibling(node);
// Case 2: Red siblingif (sibling.color == RED) {
handleRedSibling(node, sibling);
sibling = getSibling(node); // Get new sibling for fall-through to cases 3-6
}
// Cases 3+4: Black sibling with two black childrenif (isBlack(sibling.left) && isBlack(sibling.right)) {
sibling.color = RED;
// Case 3: Black sibling with two black children + red parentif (node.parent.color == RED) {
node.parent.color = BLACK;
}
// Case 4: Black sibling with two black children + black parentelse {
fixRedBlackPropertiesAfterDelete(node.parent);
}
}
// Case 5+6: Black sibling with at least one red childelse {
handleBlackSiblingWithAtLeastOneRedChild(node, sibling);
}
}Code-Sprache:Java(java)
Die Hilfsmethoden getSibling() und isBlack() findest du ab Zeile 334:
private Node getSibling(Node node){
Node parent = node.parent;
if (node == parent.left) {
return parent.right;
} elseif (node == parent.right) {
return parent.left;
} else {
thrownew IllegalStateException("Parent is not a child of its grandparent");
}
}
privatebooleanisBlack(Node node){
return node == null || node.color == BLACK;
}Code-Sprache:Java(java)
Ein roter Geschwisterknoten (Fall 2) wird ab Zeile 289 behandelt:
Die Implementierung für einen schwarzen Geschwisterknoten mit wenigstens einem roten Kind (Fälle 5 und 6) findest du ab Zeile 302:
privatevoidhandleBlackSiblingWithAtLeastOneRedChild(Node node, Node sibling){
boolean nodeIsLeftChild = node == node.parent.left;
// Case 5: Black sibling with at least one red child + "outer nephew" is black// --> Recolor sibling and its child, and rotate around siblingif (nodeIsLeftChild && isBlack(sibling.right)) {
sibling.left.color = BLACK;
sibling.color = RED;
rotateRight(sibling);
sibling = node.parent.right;
} elseif (!nodeIsLeftChild && isBlack(sibling.left)) {
sibling.right.color = BLACK;
sibling.color = RED;
rotateLeft(sibling);
sibling = node.parent.left;
}
// Fall-through to case 6...// Case 6: Black sibling with at least one red child + "outer nephew" is red// --> Recolor sibling + parent + sibling's child, and rotate around parent
sibling.color = node.parent.color;
node.parent.color = BLACK;
if (nodeIsLeftChild) {
sibling.right.color = BLACK;
rotateLeft(node.parent);
} else {
sibling.left.color = BLACK;
rotateRight(node.parent);
}
}Code-Sprache:Java(java)
Genau wie für das Einfügen, wirst du auch für das Löschen in der Literatur zahlreiche alternative Vorgehensweisen finden. Ich habe mich bemüht den Code so zu strukturieren, dass du den Codefluss so gut wie möglich nachvollziehen kannst.
Traversierung durch den Rot-Schwarz-Baum
Wie jeden Binärbaum können wir auch den Rot-Schwarz-Baum in Pre-order-, Post-order-, In-order-, Reverse-in-order- und Level-order-Reihenfolge traversieren. Die Traversierung wird im Abschnitt „Binärbaum-Traversierung“ des Einführungsartikels über Binärbäume beschrieben.
Die Traversal-Methoden arbeiten auf dem BinaryTree-Interface. Da auch der RedBlackTree dieses Interface implementiert, können die Traversierungsmethoden ohne weiteres auch auf diesen angewendet werden.
Zeitkomplexität des Rot-Schwarz-Baums
Eine Einführung in das Thema der Zeitkomplexität und der O-Notation findest du in diesem Grundlagenartikel.
Den Aufwand für die Suche, das Einfügen und Löschen eines Knotens im Binärbaum können wir wie folgt bestimmen:
Aufwand für die Suche
Bei der Suche folgen wir einem Pfad von der Wurzel bis zum gesuchten Knoten (oder zu einem NIL-Blatt). Auf jeder Ebene führen wir einen Vergleich durch. Der Aufwand für den Vergleich ist konstant.
Der Aufwand für die Suche ist damit propertional zur Baumhöhe.
Wir bezeichnen mit n die Anzahl der Knoten des Baums. Wir haben im Abschnitt „Höhe des Rot-Schwarz-Baumes“ erkannt, dass der längste Pfad maximal doppelt so lang ist wie der kürzeste Pfad. Hieraus folgt, dass die Höhe des Baumes durch O(log n) begrenzt ist.
Der formale Beweis dafür würde den Rahmen dieses Artikels sprengen. Du kannst den Beweis auf Wikipedia nachlesen.
Die Zeitkomplexität für die Suche im Rot-Schwarz-Baum beträgt somit: O(log n)
Aufwand für das Einfügen
Beim Einfügen führen wir zunächst eine Suche durch. Derem Aufwand haben wir soeben als O(log n) bestimmt.
Als nächstes fügen wir einen Knoten ein. Der Aufwand hierfür ist unabhängig von der Baumgröße konstant, also O(1).
Danach überprüfen wir die Rot-Schwarz-Regeln und stellen diese ggf. wieder her. Dies tun wir beginnend beim eingefügten Knoten aufsteigend bis zur Wurzel. Auf jeder Ebene führen wir eine oder mehrere der folgenden Operationen durch:
Prüfung der Farbe des Elternknotens
Bestimmung des Onkelknotens und Prüfung dessen Farbe
Umfärbung von ein bis maximal drei Knoten
Durchführung von ein oder zwei Rotationen
Jede dieser Operationen hat in sich einen konstanten Aufwand O(1). Der Gesamtaufwand für das Überprüfen und die Reparatur des Baumes ist in Summe also ebenfalls proportional zu dessen Höhe.
Die Zeitkomplexität für das Einfügen in den Rot-Schwarz-Baum beträgt also ebenfalls: O(log n)
Aufwand für das Löschen
Genau wie beim Einfügen suchen wir zunächst den zu löschenden Knoten mit Aufwand O(log n).
Auch der Aufwand für das Löschen an sich ist unabhängig von der Baumgröße, also konstant O(1).
Für das Prüfen der Regeln und die Reparatur des Baumes fallen – maximal einmal pro Ebene – eine oder mehrere der folgenden Operationen an:
Prüfung der Farbe des gelöschten Knotens
Bestimmung des Geschwisterknotens und Prüfung dessen Farbe
Prüfung der Farben der Kinder des Geschwisterknotens
Umfärben des Elternknoten
Umfärben von Geschwisterknoten und ggf. einem seiner Kinder
Durchführung von ein oder zwei Rotationen
Auch diese Operationen haben in sich alle einen konstanten Aufwand. Somit ist also auch der Gesamtaufwand für das Prüfen und Wiederherstellen der Regeln nach dem Löschen eines Knotens proportional zur Baumhöhe.
Die Zeitkomplexität für das Löschen aus dem Rot-Schwarz-Baum beträgt also ebenfalls: O(log n)
Rot-Schwarz-Baum im Vergleich mit anderen Datenstrukturen
Die folgenden Abschnitte beschreiben die Unterschiede, sowie die Vor- und Nachteile des Rot-Schwarz-Baumes gegenüber alternativen Datenstrukturen.
Rot-Schwarz-Baum vs. AVL-Baum
Der Rot-Schwarz-Baum sowie der AVL-Baum sind selbstbalancierende binäre Suchbäume.
Beim Rot-Schwarz-Baum ist der längste Pfad zur Wurzel maximal doppelt so lang wie der kürzeste Pfad zur Wurzel. Beim AVL-Baum hingegen unterscheidet sich die Tiefe keiner zwei Teilbäume um mehr als 1.
Im Rot-Schwarz-Baum wird die Balance durch die Farben der Knoten, ein Set von Regeln, und durch Rotationen und Umfärben der Knoten sichergestellt. Im AVL-Baum hingegen werden die Höhen der Teilbäume verglichen und bei Bedarf Rotationen durchgeführt.
Diese Unterschiede in den Eigenschaften der zwei Baumarten fünren zu folgenden Unterschieden bzgl. Performance und Speicherbedarf:
Aufgrund der gleichmäßigeren Balancierung des AVL-Baums erfolgt die Suche in diesem in der Regel schneller als im Rot-Schwarz-Baum. Von der Größenordnung her liegen aber beide im Bereich O(log n).
Auch für das Einfügen und Löschen beträgt die Zeitkomplexität in beiden Bäumen O(log n). Im direkten Vergleich ist allerdings der Rot-Schwarz-Baum schneller, da dieser seltener rebalanciert wird.
Beide Bäume benötigen zusätzlichen Speicher: der AVL-Baum ein Byte pro Knoten für die Höhe des an einem Knoten beginnenden Teilbaums; der Rot-Schwarz-Baum ein Bit pro Knoten für die Farbinformation. In der Praxis macht dies selten einen Unterschied, da ein einzelnes Bit in der Regel mindestens ein Byte belegt.
Erwartet man viele Einfüge-/Löschoperationen, dann sollte man also eher einen Rot-Schwarz-Baum einsetzen. Geht man dagegen von mehr Suchoperationen aus, dann sollte die Wahl auf den AVL-Baum fallen.
Rot-Schwarz-Baum vs. Binärer Suchbaum
Der Rot-Schwarz-Baum ist eine konkrete Implementierung eines selbstbalancierenden binären Suchbaums. Jeder Rot-Schwarz-Baum ist also auch ein binärer Suchbaum.
Es gibt auch andere Arten von binären Suchbäumen, wie z. B. den oben genannten AVL-Baum – oder triviale nicht-balancierte Implementierungen. Somit ist also nicht jeder binäre Suchbaum auch ein Rot-Schwarz-Baum.
Fazit
In diesem Tutorial hast du gelernt, was ein Rot-Schwarz-Baum ist, welche Regeln in ihm gelten und wie diese Regeln nach dem Einfügen und Löschen von Knoten überprüft und ggf. wiederhergestellt werden. Außerdem habe ich dir eine möglichst einfach zu verstehende Java-Implementierung vorgestellt.
Im JDK werden Rot-Schwarz-Bäume in der TreeMap (hier der Quellcode auf GitHub) und bei Bucket Collisions in der HashMap (hier der Quellcode) eingesetzt.
Ein AVL-Baum ist eine konkrete Implementierung eines balancierten binären Suchbaums. Er wurde 1962 von den sowjetischen Informatikern Georgi Maximowitsch Adelson-Velski und Jewgeni Michailowitsch Landis entwickelt und nach deren Initialen benannt.
In diesem Artikel erfährst du:
Was ist ein AVL-Baum?
Wie berechnet man den Balance-Faktor in einem AVL-Baum?
Wie funktioniert eine AVL-Baum-Rotation?
Wie fügt man Elemente ein, und wie löscht man sie?
Wie implementiert man einen AVL-Baum in Java?
Welche Zeitkomplexität haben die Operationen des AVL-Baums?
Was unterscheidet den AVL-Baum vom Rot-Schwarz-Baum?
Ein AVL-Baum ist ein balancierter binärer Suchbaum – also ein binärer Suchbaum, in dem sich die Höhen der linken und rechten Teilbäume eines jeden Knotens um maximal eins unterscheiden.
Nach jeder Einfüge- und Löschoperation wird diese Eigenschaft überprüft und die Balance ggf. durch AVL-Rotation wiederhergestellt.
Höhe eines AVL-Baums
Die Höhe eines (Teil-)baums gibt an, wie weit die Wurzel vom tiefsten Knoten entfernt ist. Ein (Teil-)Baum, der nur aus einem Wurzelknoten besteht, hat demnach die Höhe 0.
Höhe eines AVL-Baums und seiner Teilbäume
AVL-Baum Balance-Faktor
Der Balance-Faktor „BF“ eines Knotens „node“ bezeichnet die Differenz der Höhen „H“ des rechten und linken Teilbaums („node.right“ und „node.left“):
BF(node) = H(node.right) – H(node.left)
Die Höhe eines nicht vorhandenen Teilbaums ist -1 (eins weniger als die Höhe eines Teilbaums, der aus nur einem Knoten besteht).
Man unterscheidet drei Fälle:
Bei einem Balance-Faktor von < 0 spricht man von einem linkslastigen Knoten.
Bei einem Balance-Faktor von > 0 spricht man von einem rechtslastigen Knoten.
Ein Balance-Faktor von 0 steht für einen höhengleichen oder ausgewogenen Knoten.
In einem AVL-Baum ist der Balance-Faktor an jedem Knoten -1, 0 oder 1.
AVL-Baum-Beispiel
Das folgende Beispiel zeigt einen AVL-Baum mit Angabe von Höhe und Balance-Faktor an jedem Knoten:
Beispiel-AVL-Baum mit Angabe von Höhe und Balance-Faktor
Knoten 2 und 7 sind in diesem Beispiel rechtslastig, Knoten 4 ist linkslastig. Alle anderen Knoten sind ausgewogen.
Der folgende Baum hingegen ist kein AVL-Baum, da das AVL-Kriterum (-1 ≤ BF ≤ 1) an Knoten 4 nicht erfüllt ist. Dessen linker Teilbaum hat die Höhe 1 und der rechte, leere Teilbaum die Höhe -1. Die Differenz daraus ist -2.
Binärer Suchbaum, der das AVL-Kriterium nicht erfüllt
Implementierung eines AVL-Baums in Java
Als Basis für die Implementierung des AVL-Baums in Java verwenden wir den Java-Quellcode für den binären Suchbaum aus dem vorangegangenen Tutorial der Binärbaum-Serie.
Knoten werden durch die Klasse Node dargestellt. Für den Knotenwert data verwenden wir der Einfachheit halber int-Primitive. In height speichern wir die Höhe des Teilbaums, dessen Wurzel dieser Knoten darstellt.
publicclassNode{
int data;
Node left;
Node right;
int height;
publicNode(int data){
this.data = data;
}
}Code-Sprache:Java(java)
Der AVL-Baum wird durch die Klasse AvlTree implementiert. Diese erweitert die im vorangegenen Teil vorgestellte Klasse BinarySearchTreeRecursive. Wir werden einen Großteil deren Funktionalität wiederverwenden.
Für die Balancierung des AVL-Baums benötigen wir folgende drei zusätzliche Methoden:
height() liefert die in node.height hinterlegte Höhe eines Teilbaums ‒ oder -1 für einen leeren Teilbaum.
updateHeight() setzt node.height als maximale Höhe der Kinder plus 1.
balanceFactor() berechnet den Balance-Faktor eines Knotens.
Der Code wird in den folgenden Abschnitten Schritt für Schritt erweitert.
AVL-Baum Rotation
Einfügen in und Löschen aus einem AVL-Baum funktioniert grundsätzlich so wie im Artikel über binäre Suchbäume beschrieben.
Wenn nach einer Einfüge- oder Löschoperation das AVL-Kriterium nicht mehr erfüllt ist, muss der Baum rebalanciert werden. Dies geschieht durch sogenannte Rotationen.
Man unterscheidet zwischen Rechts- und Links-Rotation.
Rechts-Rotation
Die folgende Grafik zeigt eine Rechts-Rotation. Der dargestellte (Teil-)baum enthält folgende Knoten:
N: der Knoten, an dem ein Ungleichgewicht festgestellt wurde
L: der linke Kind-Knoten von N
LL: der linke Kind-Knoten von L
LR: der rechte Kind-Knoten von L
R: der rechte Kind-Knoten von N
Unter den Buchstaben wird jeweils in Klammern ein beispielhafter Knoten-Wert angezeigt. An diesem ist gut zu erkennen, dass vor der Rotation folgende In-Order-Reihenfolge gilt:
LL (1) < L (2) < LR (3) < N (4) < R (5)
Während der Rotation wandert Knoten L an die Wurzel, und die vorherige Wurzel N wird zum rechten Kind von L. Das vorherige rechte Kind von L, LR wird zum neuen linken Kind von N. Die zwei restlichen Knoten, LL und R bleiben unverändert relativ zu ihrem Elternknoten.
Rechts-Rotation im AVL-Baum
An den Beispiel-Werten in Klammern sieht man gut, dass sich durch die Rotation die In-Order-Reihenfolge der Knoten nicht verändert hat.
Wir merken uns das linke Kind leftChild (in der Grafik L) von node (in der Grafik N), ersetzen das linke Kind von node durch das rechte Kind des linken Kindes leftChild.right (in der Grafik LR) und setzen dann node als neues rechtes Kind des linken Kindes.
Danach aktualisieren wir die Höhen der Teilbäume in der gezeigten Reihenfolge. Die updateHeight()-Methode habe ich bereits im Abschnitt Implementierung eines AVL-Baums in Java vorgestellt.
Rückgabewert ist der neue Wurzelknoten leftChild (in der Grafik L).
Links-Rotation
Die Links-Rotation funktioniert analog:
Knoten R wird zur Wurzel; die vorherige Wurzel N wird zum linken Kind von R. Das vorherige linke Kind von R, RL wird zum neuen rechten Kind von N. Die relativen Positionen der Knoten RR und L ändern sich nicht.
Links-Rotation im AVL-Baum
Auch bei der Links-Rotation bleibt die In-Order-Reihenfolge der Knoten (L < N < RL < R < RR) erhalten.
Nach dem Einfügen in oder Löschen aus dem AVL-Baum berechnen wir die Höhe und den Balance-Faktor vom eingefügten oder gelöschten Knoten aus aufwärts bis zur Wurzel.
Wenn wir an einem Knoten feststellen, dass das AVL-Kriterium nicht mehr erfüllt ist (der Balance-Faktor also kleiner als -1 oder größer als +1 ist), müssen wir rebalancieren. Dabei unterscheiden wir vier Fälle:
Linkslastigen Knoten ausgleichen:
Rechts-Rotation
Links-Rechts-Rotation
Rechtslastigen Knoten ausgleichen:
Links-Rotation
Rechts-Links-Rotation
Im folgenden beschreibe ich die vier Fälle an verschiedenen Beispielen.
Rebalancieren durch Rechts-Rotation
Wir fügen in einen leeren Baum die Knoten 3, 2 und 1 ein. Ohne Rebalancierung sieht der Baum dann wie folgt aus:
Unbalancierter AVL-Baum nach dem Einfügen von 3, 2, 1
Wir prüfen den Balance-Faktor vom zuletzt eingefügten Knoten 1 aus aufwärts:
Der Balance-Faktor an Knoten 1 beträgt 0.
Der Balance-Faktor an Knoten 2 beträgt -1; Knoten 2 ist also linkslastig. Das AVL-Kriterium (-1 ≤ BF ≤ 1) ist aber noch erfüllt.
Der Balance-Faktor an Knoten 3 beträgt -2; hier ist das AVL-Kriterium nicht mehr erfüllt.
In diesem Fall müssen wir eine Rechts-Rotation um Knoten 3 ausführen:
Rebalancierung des AVL-Baums durch Rechts-Rotation
Die neue Wurzel ist Knoten 2, und dessen Balance-Faktor ist 0. Der AVL-Baum ist wieder balanciert.
Rebalancieren durch Links-Rechts-Rotation
In folgendem Beispiel haben wir ebenfalls eine linkslastige Wurzel, allerdings sieht die Situation etwas anders aus. Dieses mal fügen wir die Knoten in der Reihenfolge 3, 1, 2 ein:
Unbalancierter AVL-Baum nach dem Einfügen von 3, 1, 2
Wir stellen fest, dass an der Wurzel (mit einem Balance-Faktor von -2) das AVL-Kriterium nicht erfüllt ist. Würden wir jetzt – wie im vorangegangenen Beispiel – eine Rechts-Rotation ausführen, sähe der Baum danach wie folgt aus:
AVL-Baum ist nach Rechts-Rotation nicht balanciert
Das rechte Kind der 1 – die 2 – wurde zum linken Kind der 3. Anstatt einer linkslastigen Wurzel mit BF -2 haben wir nun eine rechtslastige Wurzel mit BF +2. Wir sind am Ziel vorbeigeschossen.
Was können wir stattdessen tun?
Die korrekte Vorgehensweise für diesen Fall (linkes Kind der Wurzel ist rechtslastig) ist eine sogenannte Links-Rechts-Rotation. Zuerst rotieren wir nach links um Knoten 1 und danach nach rechts um Knoten 3:
Rebalancierung des AVL-Baums durch Links-Rechts-Rotation
Mit einem Balance-Faktor von 0 an der neuen Wurzel 2 ist der AVL-Baum wieder balanciert.
Rebalancieren durch Links-Rotation
Für rechtslastige Knoten gehen wir analog vor. Wir fügen zunächst Knoten in der Reihenfolge 1, 2, 3 ein und erhalten den folgenden unbalancierten Baum:
Unbalancierter AVL-Baum nach dem Einfügen von 1, 2, 3
Der Balance-Faktor an der Wurzel beträgt +2. Wir können die Balance durch einfache Links-Rotation wiederherstellen:
Rebalancierung des AVL-Baums durch Links-Rotation
Rebalancieren durch Rechts-Links-Rotation
Das vierte und letzte Beispiel zeigt einen AVL-Baum, in den die Knoten in der Reihenfolge 1, 3, 2 eingefügt wurden:
Unbalancierter AVL-Baum nach dem Einfügen von 1, 3, 2
Der Balance-Faktor an der Wurzel beträgt auch hier +2. Doch bei einer Links-Rotation wie im vorangegangenen Beispiel würde folgendes passieren:
AVL-Baum ist nach Links-Rotation nicht balanciert
Das linke Kind der 3 – die 2 – wurde zum rechten Kind der 1. Statt einer rechtslastigen haben wir jetzt eine linkslastige Wurzel mit dem Balance-Faktor -2.
Analog zum zweiten Fall ist die korrekte Vorgehensweise in diesem Fall (rechts Kind der Wurzel ist linkslastig) eine Rechts-Links-Rotation. Wir rotieren nach rechts um Knoten 3 und dann nach links um Knoten 1:
Rebalancierung des AVL-Baums durch Rechts-Links-Rotation
Damit hast du alle Varianten der Balancierung des AVL-Baums kennengelernt.
Java-Code für die Rebalancierung
Die vier vorangegangenen Abschnitte zusammengefasst ergeben folgende Rebalancierungs-Vorschrift. BF steht dabei für Balance-Funktion, N für den betrachteten Knoten, und L und R für dessen linkes bzw. rechtes Kind.
Fall
Bedingung
Rebalancierung
1.
BF(N) < -1 und BF(L) ≤ 0
Rechts-Rotation um N
2.
BF(N) < -1 und BF(L) > 0
Links-Rotation um L gefolgt von Rechts-Rotation um N
3.
BF(N) > 1 und BF(R) ≥ 0
Links-Rotation um N
4.
BF(N) > 1 und BF(R) < 0
Rechts-Rotation um R gefolgt von Links-Rotation um N
Im Java-Code implementieren wir den Rebalancierungs-Algorithmus in der folgenden rebalance()-Methode (Klasse AvlTree, ab Zeile 41):
private Node rebalance(Node node){
int balanceFactor = balanceFactor(node);
// Left-heavy?if (balanceFactor < -1) {
if (balanceFactor(node.left) <= 0) { // Case 1// Rotate right
node = rotateRight(node);
} else { // Case 2// Rotate left-right
node.left = rotateLeft(node.left);
node = rotateRight(node);
}
}
// Right-heavy?if (balanceFactor > 1) {
if (balanceFactor(node.right) >= 0) { // Case 3// Rotate left
node = rotateLeft(node);
} else { // Case 4// Rotate right-left
node.right = rotateRight(node.right);
node = rotateLeft(node);
}
}
return node;
}Code-Sprache:Java(java)
Der Code entspricht dem oben beschriebenen Algorithmus; die vier Fälle sind jeweils als Kommentar im Code referenziert. Die Methode liefert den neuen Wurzelknoten des (Teil-)baums zurück.
Operationen im AVL-Baum
Da wir nun das Werkzeug für die Rebalancierung des Baums haben (die rebalance()-Methode aus dem vorherigen Abschnitt), können wir die Methoden zum Einfügen und Löschen zusammenbauen.
Da unsere AvlTree-Klasse von BinarySearchTreeRecursive erbt, erfolgt der Aufruf der Einfüge-Methode über super.insertNode() (definiert in BinarySearchTreeRecursive ab Zeile 34):
Beim Suchen, Einfügen und Löschen fallen folgende Operationen an:
Die maximale Anzahl an Knoten-Vergleichsoperationen entspricht der Höhe des AVL-Baumes.
Die maximale Anzahl an Berechnungen des Balance-Faktors ist doppelt so hoch, da auch immer der Balance-Faktor eines Kindes mit berücksichtigt werden muss.
Die maximale Anzahl an Rotationen entspricht ebenfalls der doppelten Höhe des AVL-Baumes, da pro Ebene keine, eine oder zwei Rotationen durchgeführt werden.
Pro Rotation wird für zwei Knoten die Höhe neu berechnet. Die maximale Anzahl an Höhen-Berechnungen beträgt also das Vierfache der Baumhöhe.
Da es sich bei einem AVL-Baum um einen balancierten Binärbaum handelt – bei Verdoppelung der Knotenzahl also lediglich eine Ebene hinzukommt – liegt die Höhe des AVL-Baumes in der Größenordnung O(log n).
Da die Kosten aller oben genannten Operationen konstant sind und die Anzahl ihrer Ausführungen jeweils proportional zur Baumhöhe ist, beträgt auch die Zeitkomplexität für das Suchen, Einfügen und Löschen jeweils O(log n).
AVL-Baum im Vergleich mit anderen Datenstrukturen
In den folgenden Abschnitten findest du die Vor- und Nachteile des AVL-Baums gegenüber vergleichbaren Datenstrukturen.
AVL-Baum vs. Rot-Schwarz-Baum
Sowohl der AVL-Baum als auch der Rot-Schwarz-Baum sind selbst-balancierende binäre Suchbäume.
Beim AVL-Baum erfolgt die Rebalancierung durch Berechnung von Balance-Faktoren und nachfolgenden Rotationen. Die absolute Höhendifferenz ist an keinem Knoten größer als 1.
Im Rot-Schwarz-Baum werden die Knoten durch Farben (rot / schwarz) gekennzeichnet. Rotationen erfolgen, wenn bestimmte Kriterien für Farbfolgen nicht mehr eingehalten sind. Die absolute Höhendifferenz an einem Knoten kann auch größer als 1 sein. Genauer gesagt: das tiefste Blatt kann von der Wurzel bis zu doppelt so weit entfernt sein wie das höchste Blatt.
Diese Eigenschaften führen zu folgenden Unterschieden:
Die Suche im AVL-Baum ist in der Regel schneller als im Rot-Schwarz-Baum, da der AVL-Baum besser balanciert ist.
Das Einfügen und Löschen ist hingegen im Rot-Schwarz-Baum schneller, da dieser seltener rebalanciert wird.
AVL-Bäume benötigen ein Extra-Byte pro Knoten für das Speichern der jeweiligen Höhe. Rot-Schwarz-Bäume benötigen lediglich ein Bit pro Knoten für die Farb-Information. In der Java-Praxis macht dies keinen Unterschied, da für das Bit mindestens ein Byte belegt wird.
AVL-Baum vs. Binärer Suchbaum
Ein AVL-Baum ist ein binärer Suchbaum, der nach jeder Einfüge- und Lösch-Operation durch Rotation das AVL-Kriterium wiederherstellt.
Ein binärer Suchbaum muss nicht zwingend balanciert sein. Ebenso kann die Balancierung durch andere Algorithmen als beim AVL-Baum erreicht werden.
Jeder AVL-Baum ist also ein binärer Suchbaum. Aber nicht jeder binäre Suchbaum ist ein AVL-Baum.
Fazit
In diesem Tutorial hast du erfahren, was ein AVL-Baum ist und wie dieser nach Einfüge- oder Löschoperationen durch Einfach- oder Doppelrotation rebalanciert wird. Außerdem hast du gelernt, wie man einen AVL-Baum in Java implementiert.
Im nächsten Teil wird es um eine weitere konkrete Art des binären Suchbaums gehen: den Rot-Schwarz-Baum.
Es gibt nur eine Datenstruktur, mit der man schnell sowohl Elemente anhand ihres Schlüssels finden kann – als auch über die Elemente in Schlüsselreihenfolge iterieren kann: den binären Suchbaum!
In diesem Artikel erfährst du:
Was ist ein binärer Suchbaum?
Wie fügt man neue Elemente ein, wie sucht man sie, und wie löscht man sie wieder?
Wie iteriert man über alle Elemente des binären Suchbaums?
Wie implementiert man einen binären Suchbaum in Java?
Welche Zeitkomplexität haben die Operationen des binären Suchbaums?
Was unterscheidet den binären Suchbaum von ähnlichen Datenstrukturen?
Ein binärer Suchbaum (englisch: binary search tree, abgekürzt: BST) ist ein Binärbaum, dessen Knoten einen Schlüssel (englisch: key) enthalten und in dem der linke Teilbaum eines Knotens nur Schlüssel enthält, die kleiner (oder gleich) als der Schlüssel des Elternknotens sind, und der rechte Teilbaum nur Schlüssel die größer (oder gleich) als der Schlüssel des Elternknotens sind.
Die Datenstruktur des binären Suchbaums ermöglicht es schnell¹ Schlüssel einzufügen, nachzuschlagen und zu entfernen (wie in einem Set in Java).
Um einen Knoten zu finden, muss man – bei der Wurzel beginnend – den Such-Schlüssel mit dem Knoten-Schlüssel vergleichen. Folgende drei Fälle können dabei eintreten:
Der Such-Schlüssel ist gleich dem Knoten-Schlüssel: Der Zielknoten ist erreicht.
Der Such-Schlüssel ist kleiner als der Knoten-Schlüssel: Die Suche muss im linken Teilbaum forgesetzt werden.
Der Such-Schlüssel ist größer als der Knoten-Schlüssel: Die Suche muss im rechten Teilbaum forgesetzt werden.
Die Knoten können neben dem Schlüssel auch einen Wert (englisch: value) enthalten. Dann kann man nicht nur prüfen, ob der Binäre Suchbaum einen Schlüssel enthält, sondern dem Schlüssel auch einen Wert zuordnen und diesen über den Schlüssel wieder auslesen (entsprechend einer Map).
Die Anordnung der Knoten im Binären Suchbaum ermöglicht es außerdem sehr effizient über die Schlüssel und deren Werte in Schlüssel-Reihenfolge zu iterieren.
Hier siehst du ein Beispiel eines binären Suchbaums:
Binärer Suchbaum – Beispiel
Um in diesem Beispiel die 11 zu finden, würde man wie folgt vorgehen:
Schritt 1: Vergleich des Such-Schlüssels 11 mit dem Wurzel-Schlüssel 5. Die 11 ist größer, die Suche muss somit im rechten Teilbaum fortgesetzt werden.
Schritt 2: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 9 (rechtes Kind der 5). Die 11 ist größer, die Suche muss im rechten Teilbaum unter der 9 fortgesetzt werden.
Schritt 3: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 15 (rechtes Kind der 9). Die 11 ist kleiner, die Suche muss im linken Teilbaum unter der 15 fortgesetzt werden.
Schritt 4: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 11 (linkes Kind der 15). Der gesuchte Knoten ist gefunden.
Im folgenden Diagramm sind die vier Schritte mit blau markierten Knoten und Kanten hervorgehoben:
Binärer Suchbaum – Pfad zum gesuchten Schlüssel
Eigenschaften von binären Suchbäumen
Die wichtigste Eigenschaft eines Binären Suchbaums ist der schnelle Zugriff auf einen Knoten über dessen Schlüssel. Der Aufwand hierfür hängt von der Struktur des Baumes ab: Knoten, die nahe der Wurzel liegen, werden nach weniger Vergleichen gefunden als Knoten, die weit von der Wurzel entfernt sind.
Je nach Einsatzzweck des binären Suchbaums ergeben sich unterschiedliche Anforderungen an dessen Form. Für bestimmte Einsatzformen soll die Höhe des binären Suchbaums möglichst gering sein (s. Abschnitt Balancierter binärer Suchbaum).
Für andere Einsatzformen ist es wichtiger, dass häufig nachgeschlagene Schlüssel nahe an der Wurzel liegen, während die Tiefe von Knoten, auf die seltener zugegriffen wird, weniger ins Gewicht fällt (s. Abschnitt Optimaler binärer Suchbaum).
Balancierter binärer Suchbaum
Ein balancierter binärer Suchbaum ist ein binärer Suchbaum, in dem sich die linken und rechten Teilbäume eines jeden Knotens in der Höhe um maximal eins unterscheiden.
Der oben gezeigte Beispielbaum ist nicht balanciert. Der linke Teilbaum des Knotens „9“ hat die Höhe eins und der rechte Teilbaum die Höhe drei. Die Höhendifferenz also größer als eins.
Nicht balancierter binärer Suchbaum
Wir können berechnen, wie viele Vergleiche wir in diesem Baum im Durchschnitt benötigen, um einen Schlüssel zu finden. Dazu multiplizieren wir auf jeder Knotenebene die Anzahl der Knoten mit der Anzahl der Vergleiche, die wir benötigen, um einen Knoten auf der entsprechenden Ebene zu erreichen:
Anzahl Vergleiche (= Knotentiefe + 1)
Anzahl Knoten auf dieser Ebene
Anzahl Vergleiche auf dieser Ebene
1 (Wurzel)
1 (5)
1 × 1 = 1
2
2 (2, 9)
2 × 2 = 4
3
4 (1, 4, 6, 15)
3 × 4 = 12
4
3 (3, 11, 16)
4 × 3 = 12
5
2 (10, 13)
5 × 2 = 10
Summen:
12
39
Wenn wir jeden Knoten genau einmal suchen würden, bräuchten wir in Summe 39 Vergleiche. 39 Vergleiche geteilt durch 12 Knoten = 3,25 Vergleiche pro Knoten. Im Durchschnitt brauchen wir also 3,25 Vergleiche, um einen Knoten zu finden.
Der folgende Beispielbaum enthält die gleichen Schlüssel, ist jedoch balanciert:
Balancierter binärer Suchbaum
Wir führen die gleiche Berechnung für den balancierten Suchbaum durch:
Anzahl Vergleiche (= Knotentiefe + 1)
Anzahl Knoten auf dieser Ebene
Anzahl Vergleiche auf dieser Ebene
1 (Wurzel)
1 (5)
1 × 1 = 1
2
2 (2, 11)
2 × 2 = 4
3
4 (1, 4, 9, 15)
3 × 4 = 12
4
5 (3, 6, 10, 13, 16)
4 × 5 = 20
Summen:
12
37
Im balancierten Baum benötigen wir nur noch 37 Vergleiche für 12 Knoten, das sind 3,08 Vergleiche pro Knoten.
Degenerierter Binärbaum
Die Struktur des binären Suchbaumes ergibt sich in erster Linie aus der Reihenfolge, in der die Knoten eingefügt und gelöscht werden. Im Extremfall – wenn die Knoten in auf- oder absteigender Reihenfolge eingefügt werden – könnte ein Baum wie der folgende entstehen:
Degenerierter Binärbaum
Wenn – wie in diesem Beispiel – jeder innere Knoten genau ein Kind hat, eine Baumstruktur also gar nicht mehr erkennbar ist, spricht man von einem degenerierten Baum.
Wenn wir in diesem Baum jeden Knoten einmal suchen würden, kämen wir auf
1×1 (für die 1) + 1×2 (für die 2) + 1×3 (für die 3) … + 1×10 (für die 13) + 1×11 (für die 15) + 1×12 (für die 16) = 78 Vergleiche
… für 12 Knoten. Im Durchschnitt bräuchten wir also 78 / 12 = 6,5 Vergleiche, um einen beliebigen Schlüssel zu finden – also deutlich mehr als im zufällig angeordneten und im balancierten Suchbaum.
Selbstbalancierender binärer Suchbaum
Ein selbstbalancierender (auch höhen-balancierter) binärer Suchbaum kann beim Einfügen und Löschen von Schlüsseln den Baum so transformieren, dass die Höhe des Baumes möglichst klein gehalten wird.
„Möglichst klein“ ist dabei nicht näher spezifiziert. Ein selbstbalancierender binärer Suchbaum muss also nicht zwingenderweise die Eigenschaften eines balancierten binären Suchbaums erreichen. (Die Höhendifferenz des linken und rechten Teilbaum eines Knotens darf also auch größer als eins sein.)
Da die Reorganisation des Baumes mit einem gewissen Zeit- und Platz-Overhead verbunden ist, gilt es eine Balance zwischen Aufwand und Ergebnis zu finden.
Es gibt zahlreiche Implementierungen von selbstbalancierenden binären Suchbäumen. Zu den bekanntesten gehören der AVL-Baum und der Rot-Schwarz-Baum.
Optimaler binärer Suchbaum
Im oben beschriebenen balancierten binären Suchbaum werden die durchschnittlichen Kosten für den Zugriff auf beliebige Knoten minimiert. Das ist dann sinnvoll, wenn die Suche nach allen Schlüsseln annähernd gleichverteilt (oder unbekannt) ist.
Es gibt auch Einsatzzwecke, in denen bekannt ist, dass auf bestimmte Knoten öfter zugegriffen wird als auf andere. Ein Beispiel wäre ein Wörterbuch, das zur Rechtschreibkontrolle verwendet wird. Auf die Knoten der häufig genutzten Wörter wird dabei öfter zugegriffen als auf die Knoten der selten genutzten Wörter.
Um die Suchkosten – also die Anzahl der Vergleiche – insgesamt zu minimieren, würde es also Sinn machen, Knoten mit häufig benutzten Wörtern näher an der Wurzel zu platzieren als Knoten mit selten genutzten Wörtern.
Wenn wir im Voraus wissen, wie oft (oder mit welcher Wahrscheinlichkeit) jeder Schlüssel des binären Suchbaums gesucht wird, können wir den Baum derart konstruieren, dass die Suchkosten für die Gesamtheit der Suchaufrufe minimal sind. Einen solchen Baum bezeichnet man als optimalen binären Suchbaum.
Optimaler binärer Suchbaum – Beispiel
Das folgende Beispiel zeigt an einem Wörterbuch mit ein paar Wörtern und deren Häufigkeiten in einem Textkorpus (Quelle: WaCky), wie sich die Gesamtkosten zwischen balanciertem und optimalen binären Suchbaum unterscheiden.
Wort
Häufigkeit im Textkorpus
der
41.943.869
die
38.527.491
das
11.839.666
an
5.932.812
mehr
2.332.783
zeit
1.163.141
euro
568.080
eltern
290.303
nacht
156.069
sehr
85.970
plan
59.900
los
26.990
Ein balancierter binärer Suchbaum mit den aufgelisteten Wörten könnte z. B. folgende Struktur haben:
Wörterbuch im balancierten binären Suchbaum
Da wir wissen, wie oft die einzelnen Wörter nachgeschlagen werden, können wir die durchschnittlichen Kosten pro Aufruf berechnen:
In diesem balancierten Baum benötigen wir durchschnittlich
311.255.458 / 102.927.074 = 3,02 Vergleiche pro Suche.
Es fällt auf, dass an der Baumwurzel das relativ selten benutzte Wort „euro“ liegt. Häufig verwendete Wörter wie „die“ und „das“ hingegen liegen relativ weit unten im Baum.
Wenn wir den Baum dahingenend optimieren, dass häufig verwendete Wörter näher an der Wurzel liegen, erreichen wir folgende Struktur:
Optimierter binärer Suchbaum
Dass dieser Baum nicht mehr balanciert ist, sieht man auf den ersten Blick. Dafür liegen die am häufigsten verwendeten Wörter „der“, „die“, „das“ in den ersten zwei Ebenen des Baumes. Und die am seltensten benutzten Wörter „sehr“, „plan“ und „los“ befinden sich sehr weit unten.
Berechnen wir noch einmal die durchschnittlichen Kosten:
Anzahl Vergleiche (Knotentiefe + 1)
Worthäufigkeiten auf dieser Tiefe
Summe der Worthäufigkeiten auf dieser Tiefe
Anzahl Vergleiche × Summe der Worthäufigkeiten
1 (Wurzel)
41.943.869 (der)
41.943.869
1 × 41.943.869 = 41.943.869
2
11.839.666 (das) + 38.527.491 (die)
50.367.157
2×50.367.157 = 100.734.314
3
5.932.812 (an) + 2.332.783 (mehr)
8.265.595
3 × 8.265.595 = 24.796.785
4
568.080 (euro) + 1.163.141 (zeit)
1.731.221
4 × 1.731.221 = 6.924.884
5
290.303 (eltern) + 26.990 (los) + 156.069 (nacht)
473.362
5 × 473.362 = 2.366.810
6
85.970 (sehr)
85.970
6 × 85.970 = 515.820
7
59.900 (plan)
59.900
7 × 59.900 = 419.300
Summen:
102.927.074
177.701.782
Im optimalen binären Suchbaum benötigen wir durchschnittlich
177.701.782 / 102.927.074 = 1,73 Vergleiche pro Suche.
Die Suche ist also fast doppelt so schnell wie im balancierten Baum.
Wie ein optimaler binären Suchbaum konstruiert wird, kannst du z. B. auf Techie Delight nachlesen.
Binärer Suchbaum in Java
Für die Implementierung des binären Suchbaums in Java verwenden wir die gleiche grundlegende Datenstruktur wie bei der Java-Implementierung des Binärbaums.
Knoten werden in der Klasse Node definiert. Den Schlüssel speichern wir im Feld data. Der Einfachheit halber verwenden wir int-Primitive anstatt konkreter oder generischer Klassen.
Da wir in diesem Artikel – und im weiteren Verlauf der Tutorial-Serie – verschiedene Arten von binären Suchbäumen implementieren werden, definieren wir ein Interface BinarySearchTree. Dieses erweitert das im ersten Teil der Serie angelegte Interface BinaryTree (welches lediglich die Methode getRoot() bereitstellt):
publicinterfaceBinaryTree{
Node getRoot();
}
publicinterfaceBinarySearchTreeextendsBinaryTree{
// operations will be added soon...
}Code-Sprache:Java(java)
Im Verlauf dieses Artikels wird das BinarySearchTree-Interface von folgenden zwei Klassen implementiert werden:
Beide Klassen erweitern BaseBinaryTree, eine Minimal-Implementierung des Binärbaums, die nur die Referenz auf den Wurzelknoten enthält:
publicclassBaseBinaryTreeimplementsBinaryTree{
protected Node root;
@Overridepublic Node getRoot(){
return root;
}
}
publicclassBinarySearchTreeIterativeextendsBaseBinaryTreeimplementsBinarySearchTree{
// operations will be added soon...
}
publicclassBinarySearchTreeRecursiveextendsBaseBinaryTreeimplementsBinarySearchTree{
// operations will be added soon...
}Code-Sprache:Java(java)
Das folgende UML-Klassendiagramm zeigt die angelegten Interfaces und Klassen für die Binäre-Suchbaum-Datenstruktur:
Binärer Suchbaum in Java – UML-Klassendiagramm
Wundere dich nicht, dass das BinarySearchTree-Interface und die implementierenden Klassen noch leer sind – das wird nicht lange so bleiben. In den folgenden Abschnitten werde ich die verschiedenen Operationen auf binären Suchbäumen vorstellen und schrittweise dem Code hinzufügen.
Operationen auf binären Suchbäumen
Binäre Suchbäume bieten Operationen zum Einfügen, Löschen und Suchen von Schlüsseln (und ggf. damit verknüpften Werten) an, sowie zum Traversieren über alle Elemente.
Suche im binären Suchbaum
Wie die Suche funktioniert, habe ich in der Einführung und anhand eines Beispiels detailliert gezeigt. Zusammengefasst: wir vergleichen den Such-Schlüssel mit den Knoten-Schlüsseln beginnend an der Wurzel und folgen wiederholt dem linken oder rechten Kindknoten, je nachdem, ob der Such-Schlüssel kleiner oder größer als der jeweilige Knoten-Schlüssel ist – solange bis wir den Knoten mit dem gesuchten Schlüssel gefunden haben.
Suche im binären Suchbaum – Java-Quellcode (rekursiv)
Der Java-Code für die Suche im BST (Abkürzung für „binary search tree“) kann rekursiv und iterativ implementiert werden. Beide Varianten sind unkompliziert. Die rekursive Variante findest du in der Klasse BinarySearchTreeRecursive ab Zeile 10:
Suche im binären Suchbaum – Java-Quellcode (iterativ)
Ebenso einfach ist die iterative Variante (BinarySearchTreeIterative ab Zeile 10). Anstatt die Suche rekursiv auf den Teilbäumen aufzurufen, wandert die node-Referenz entlang der betrachteten Knoten, bis derjenige mit dem gesuchten Schlüssel gefunden und zurückgegeben wird.
Beim Einfügen eines Schlüssels in den binären Suchbaum muss sichergestellt werden, dass die Reihenfolge der Schlüssel erhalten bleibt. Wie genau das erreicht wird, hängt von der konkreten Implementierung ab. Selbstbalancierende binäre Suchbäume setzen hier komplexe Algorithmen ein, auf die ich in späteren Artikeln der Serie eingehen werde.
Wir implementieren zunächst einen nicht selbstbalancierenden Suchbaum, der keine Duplikate zulässt. Das Einfügen neuer Schlüssel funktioniert wie folgt:
Genau wie bei der Suche folgen wir den Knoten – beginnend bei der Wurzel – nach links, wenn der einzufügende Schlüssel kleiner als der Knoten-Schlüssel ist, und nach rechts, wenn der einzufügende Schlüssel größer als der Knoten-Schlüssel ist. Irgendwann erreichen wir einen Blatt-Knoten. Ist der einzufügende Schlüssel kleiner als der Blatt-Schlüssel, fügen wir einen neuen Knoten als linkes Kind des Blatts ein; ist der einzufügende Schlüssel größer als der Blatt-Schlüssel, fügen wir den neuen Knoten als rechtes Kind ein.
(Sollten wir bei diesem Prozess einen Knoten finden, dessen Schlüssel der gleiche ist wie der einzufügende Schlüssel, dann quittieren wir den Einfügeversuch mit einer Fehlermeldung. Denn Duplikate sind nicht erlaubt.)
Das folgende Diagramm zeigt, wie wir in den Beispielbaum vom Beginn des Artikels den Schlüssel 8 einfügen:
Einfügen eines Knotens in einen binären Suchbaum
Die Einfüge-Operation geht dabei wie folgt vor:
Sie vergleicht die 8 mit dem Wurzel-Schlüssel 5. Die 8 ist größer, sie fährt daher beim rechten Kind der Wurzel, also der 9, fort.
Sie vergleicht die 8 mit der 9. Die 8 ist kleiner, die Operation wandert daher zum linken Kind der 9, also der 6.
Sie vergleicht die 8 mit der 6. Die 8 ist größer. Die 6 hat kein rechtes Kind. Die Operation hängt daher einen neuen Knoten mit dem einzufügenden Schlüssel 8 als rechtes Kind an die 6 an.
Einfügen im binären Suchbaum – Java-Quellcode (iterativ)
Auch das Einfügen können wir sowohl rekursiv als auch iterativ implementieren. Ich beginne mit der iterativen Implementierung. Diese ist zwar etwas länger, dafür einfacher zu verstehen als die rekursive Variante. Die iterative Einfüge-Operation findest du in BinarySearchTreeIterative ab Zeile 26:
publicvoidinsertNode(int key){
Node newNode = new Node(key);
if (root == null) {
root = newNode;
return;
}
Node node = root;
while (true) {
// Traverse the tree to the left or right depending on the keyif (key < node.data) {
if (node.left != null) {
// Left sub-tree exists --> follow
node = node.left;
} else {
// Left sub-tree does not exist --> insert new node as left child
node.left = newNode;
return;
}
} elseif (key > node.data) {
if (node.right != null) {
// Right sub-tree exists --> follow
node = node.right;
} else {
// Right sub-tree does not exist --> insert new node as right child
node.right = newNode;
return;
}
} else {
thrownew IllegalArgumentException("BST already contains a node with key " + key);
}
}
}Code-Sprache:Java(java)
Wir beginnen mit dem Erstellen des neuen Knotens. Wenn der Wurzelknoten noch nicht gesetzt ist, setzen wir diesen auf den neuen Knoten.
Andernfalls folgen wir in der while-Schleife den Knoten von der Wurzel beginnend, bis wir denjenigen Knoten finden, unter dem der neue Knoten als linkes oder rechtes Kind einzufügen ist. Das eigentliche Einfügen erledigen wir gleich mit in der Schleife, da wir an der entsprechenden Stelle noch wissen, ob der neue Knoten als linkes oder rechtes Kind eingefügt werden soll.
Einfügen im binären Suchbaum – Java-Quellcode (rekursiv)
publicvoidinsertNode(int key){
root = insertNode(key, root);
}
Node insertNode(int key, Node node){
// No node at current position --> store new node at current positionif (node == null) {
node = new Node(key);
}
// Otherwise, traverse the tree to the left or right depending on the keyelseif (key < node.data) {
node.left = insertNode(key, node.left);
} elseif (key > node.data) {
node.right = insertNode(key, node.right);
} else {
thrownew IllegalArgumentException("BST already contains a node with key " + key);
}
return node;
}Code-Sprache:Java(java)
Bei dieser Variante suchen wir die Einfügeposition rekursiv. Die rekursive Methode liefert den neuen Knoten zurück, wenn die Methode auf einer null-Referenz aufgerufen wurde. Der Aufrufer setzt dann die Referenz node.left oder node.right auf den zurückgegebenen Knoten.
Wird die rekursive Methode hingegen auf einem existierenden Knoten aufgerufen, wird (nach weiterem Abstieg in und Aufstieg aus der Rekursion) genau dieser wieder zurückgegeben. Die Zuweisung zu node.left bzw. node.right hat in diesem Fall keine Änderung zur Folge.
Löschen im binären Suchbaum
Genau wie beim Einfügen von Knoten hängt auch beim Löschen die konkrete Vorgehensweise von der Implementation ab. Selbstbalancierende Suchbäume verwenden komplexe Algorithmen, um die Balance aufrechtzuerhalten. Wir implementieren zunächst eine einfache Lösung. Dabei müssen wir – wie auch bei Binärbäumen im Allgemeinen – drei Fälle unterscheiden:
Fall A: Knoten ohne Kinder (Blatt) löschen
Liegt der zu löschende Schlüssel auf einem Blatt, dann können wir dieses einfach aus dem Baum entfernen. Die Reihenfolge der restlichen Knoten ändert sich dadurch nicht. Dazu setzen wir die left– oder right-Referenz des Elternknotens, die auf den zu löschenden Knoten zeigt, auf null.
Im folgenden Beispiel entfernen wir die den Knoten mit dem Schlüssel 10 aus dem Beispielbaum dieses Artikels. Das Diagramm zeigt der Übersicht halber nur den rechten Teilbaum an:
Knoten ohne Kinder (Blatt) aus binärem Suchbaum löschen
Fall B: Knoten mit einem Kind (Halbblatt) löschen
Wollen wir einen Knoten im binären Suchbaum löschen, der genau ein Kind hat, dann rückt das Kind an die gelöschte Position auf. Auch dabei bleibt die Reihenfolge aller anderen Knoten erhalten.
Das folgende Beispiel zeigt, wie wir nach dem Löschen der 10 im vorherigen Schritt nun auch den Knoten mit dem Schlüssel 11 löschen. Wir setzen die left– oder right-Referenz des Elternknotens (im Beispiel 15) auf das Kind des gelöschten Knotens (im Beispiel 13).
Die 13 rückt dadurch an die gelöschte Position auf:
Knoten mit einem Kind (Halbblatt) aus binärem Suchbaum löschen
Fall C: Knoten mit zwei Kindern löschen
Wenn wir einen Knoten aus einem binären Suchbaum löschen wollen, der zwei Kinder hat, wird es etwas komplizierter. Ein verbreiteter Ansatz ist der folgende:
Wir ermitteln im rechten Teilbaum den Knoten mit dem kleinsten Schlüssel. Dies ist der sogenannte „In-order-Nachfolger“ des zu löschenden Knotens.
Wir kopieren die Daten des In-order-Nachfolgers in den zu löschenden Knoten.
Wir entfernen den In-order-Nachfolger aus dem rechten Teilbaum. Da dies der Knoten mit dem kleinsten Schlüssel des rechten Teilbaums ist, kann er kein linkes Kind haben. Er hat also entweder gar kein Kind oder nur ein rechtes. Entsprechend können wir den In-order-Nachfolger wie in Fall A oder B entfernen.
Im folgenden Beispiel löschen wir den Wurzelknoten 5, indem In-order-Nachfolger 6 dessen Position einnimmt:
Knoten mit zwei Kindern aus binärem Suchbaum löschen
Alternativ kann natürlich auch der In-order-Vorgänger des linken Teilbaums an die Stelle des gelöschten Knotens tretens. Eine intelligente Auswahl von In-order-Vorgänger oder -Nachfolger erhöht die Wahrscheinlichkeit, dass der Baum einigermaßen ausbalanciert wird (und bleibt).
Löschen im binären Suchbaum – Java-Quellcode (rekursiv)
Wie alle anderen Operationen, kann auch das Löschen aus dem binären Suchbaum rekursiv und iterativ implementiert werden. Wenn Du die rekusive Methode zum Einfügen verstanden hast, wird es einfacher sein, auch beim Löschen mit der rekursiven Methode zu beginnen. Du findest sie in BinarySearchTreeRecursive ab Zeile 52:
publicvoiddeleteNode(int key){
root = deleteNode(key, root);
}
Node deleteNode(int key, Node node){
// No node at current position --> go up the recursionif (node == null) {
returnnull;
}
// Traverse the tree to the left or right depending on the keyif (key < node.data) {
node.left = deleteNode(key, node.left);
} elseif (key > node.data) {
node.right = deleteNode(key, node.right);
}
// At this point, "node" is the node to be deleted// Node has no children --> just delete itelseif (node.left == null && node.right == null) {
node = null;
}
// Node has only one child --> replace node by its single childelseif (node.left == null) {
node = node.right;
} elseif (node.right == null) {
node = node.left;
}
// Node has two childrenelse {
deleteNodeWithTwoChildren(node);
}
return node;
}Code-Sprache:Java(java)
In den ersten Zeilen (bis zum Kommentar „At this point…“) suchen wir die Löschposition, indem wir die Löschmethode rekursiv aufrufen, wenn der zu löschende Schlüssel kleiner oder größer als der des gerade betrachteten Knotens ist.
Haben wir den zu löschenden Knoten gefunden und hat dieser keine Kinder, gibt die Methode null zurück. Der Aufrufer setzt dann die left– oder right-Referenz des Parent-Knotens entsprechend auf null.
Hat der zu löschende Knoten genau ein Kind, wird eben dieses Kind zurückgegeben. Der Aufrufer setzt die left– oder right-Referenz des Parent-Knotens auf das zurückgegebene Kind. Als Folge dessen ist der zu löschende Knoten aus dem Baum entfernt.
Hat der zu löschende Knoten zwei Kinder, wird die folgende Methode aufgerufen:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = findMinimum(node.right);
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor recursively
node.right = deleteNode(inOrderSuccessor.data, node.right);
}
private Node findMinimum(Node node) {
while (node.left != null) {
node = node.left;
}
return node;
}Code-Sprache:GLSL(glsl)
Zuerst wird über die findMinimum()-Methode der In-order-Nachfolger gesucht. Dessen Daten werden in den zu löschenden Knoten kopiert. Danach wird der In-order-Nachfolger durch rekursiven Aufruf von deleteNode() aus dem rechten Teilbaum des zu löschenden Knoten entfernt.
Löschen im binären Suchbaum – Java-Quellcode (iterativ)
Die iterative Methode ist deutlich länger, da wir zum Löschen des In-order-Nachfolgers nicht einfach die Lösch-Methode rekursiv aufrufen können. Du findest die iterative Implementierung in BinarySearchTreeIterative ab Zeile 62:
publicvoiddeleteNode(int key){
Node node = root;
Node parent = null;
// Find the node to be deletedwhile (node != null && node.data != key) {
// Traverse the tree to the left or right depending on the key
parent = node;
if (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
// Node not found?if (node == null) {
return;
}
// At this point, "node" is the node to be deleted// Node has at most one child --> replace node by its single childif (node.left == null || node.right == null) {
deleteNodeWithZeroOrOneChild(key, node, parent);
}
// Node has two childrenelse {
deleteNodeWithTwoChildren(node);
}
}Code-Sprache:Java(java)
In der ersten Hälfte der Methode (bis zum Kommentar „At this point…“) wird – genau wie beim iterativen Suchen und Einfügen – der zu löschende Knoten gesucht. Dabei merken wir uns dessen Elternknoten.
Ein Blatt oder Halbblatt wird dann mit der Methode deleteNodeWithZeroOrOneChild() entfernt:
Je nachdem, ob der zu löschende Knoten linkes oder rechtes Kind seines Parents ist, wird die left– oder right-Referenz des Parents auf das verbleibende Kind des zu löschenden Knotens gesetzt. Hat der zu löschende Knoten kein Kind, dann ist child gleich null, und entsprechend wird auch die left– oder right-Referenz des Parents auf null gesetzt.
Hat der zu löschende Knoten zwei Kinder, dann wird die Methode deleteNodeWithTwoChildren() aufgerufen:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = node.right;
Node inOrderSuccessorParent = node;
while (inOrderSuccessor.left != null) {
inOrderSuccessorParent = inOrderSuccessor;
inOrderSuccessor = inOrderSuccessor.left;
}
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor// Case a) Inorder successor is the deleted node's right childif (inOrderSuccessor == node.right) {
// --> Replace right child with inorder successor's right child
node.right = inOrderSuccessor.right;
}
// Case b) Inorder successor is further down, meaning, it's a left childelse {
// --> Replace inorder successor's parent's left child// with inorder successor's right child
inOrderSuccessorParent.left = inOrderSuccessor.right;
}
}Code-Sprache:GLSL(glsl)
Wie auch bei der rekursiven Variante wird zunächst der In-order-Nachfolger gesucht und dessen Daten in den zu löschenden Knoten kopiert.
Das Entfernen des In-order-Nachfolgers aus dem rechten Teilbaum ist in der iterativen Variante allerdings aufwändiger. Hier müssen zwei Fälle unterschieden werden:
Der In-order-Nachfolger ist das rechte Kind des zu löschenden Knotens, also die Wurzel des rechten Teilbaums. In diesem Fall wird das rechte Kind des zu löschenden Knotens mit dem rechten Kind des In-order-Nachfolgers ersetzt.
Der In-order-Nachfolger ist weiter unten im rechten Teilbaum. In diesem Fall ist er das linke Kind seines Eltern-Knotens und wird durch sein eigenes rechtes Kind ersetzt.
Traversierung des binären Suchbaums
Genau wie bei Binärbäumen im Allgemeinen können auch in einem binären Suchbaum Pre-order-, Post-order-, In-order-, Reverse-in-order- und Level-order-Traversierungen durchgeführt werden.
Was diese Traversierungsarten bedeuten und wie sie in Java implementiert werden, erfährst du im Abschnitt Binärbaum-Traversierung des Artikels über Binärbäume.
Während pre-, post- und level-order wenig sinnvoll sind, ist die In-order-Traversierung im binären Suchbaum äußerst hilfreich: sie iteriert über alle Knoten des Baumes in Sortierreihenfolge ihrer Schlüssel:
Es gibt Situationen, in denen wir einen Binärbaum vorliegen haben und wir prüfen müssen, ob dieser ein valider binärer Suchbaum ist.
Die naheliegende Lösung – rekursiv zu prüfen, ob jeder Knoten größer als sein linkes Kind und kleiner als sein rechtes Kind ist – ist leider falsch. Denn diese Eigenschaft würde beispielsweise auch auf folgenden Binärbaum zutreffen:
Kein binärer Suchbaum
Die 6 ist in diesem Beispiel kleiner als die 12 – so weit, so gut. Sie befindet sich allerdings im rechten Teilbaum unter der 8. Dieser Teilbaum darf nur Schlüssel enthalten, die größer als 8 sind. Da dies auf die 6 nicht zutrifft, sind die Anforderungen für einen validen BST nicht erfüllt.
Wir haben stattdessen zwei Möglichkeiten:
Wir führen ein reguläres Pre-order-Traversal durch und prüfen dabei, ob die Schlüsselreihenfolge eingehalten wird, d. h. ob der Schlüssel eines Knotens größer (oder gleich) ist wie der Schlüssel des Vorgängerknotens.
Wir prüfen – von der Wurzel beginnend – den linken und rechten Teilbaum eines jeden Knoten rekursiv und geben dabei einen Bereich von Schlüssel an, die in diesem Teilbaum vorkommen dürfen.
Binären Suchbaum validieren – Java-Quellcode
Die zweite Variante lässt sich am einfachsten durch Lesen des Quellcodes verstehen (Klasse BinarySearchTreeValidator). Die folgende Variante erlaubt keine Schlüssel-Duplikate:
Wir übergeben der rekursiven isBstWithoutDuplicates()-Methode zunächst den Wurzelknoten und den Zahlenbereich aller Integer-Werte. Die Methode prüft, ob der Schlüssel des übergebenen Knotens im erlaubten Zahlenbereich liegt. Wenn nicht, gibt die Methode false zurück.
Wenn ja, wird die Methode rekursiv auf dem linken und rechten Teilbaum aufgerufen. Dabei wird der erlaubte Zahlenbereich entsprechend der BST-Eigenschaften immer weiter eingeschränkt.
Der Aufwand für das Suchen, Einfügen, und Löschen steigt linear mit der Tiefe des jeweiligen Knotens, da für jede Ebene, die der Knoten von der Wurzel entfernt ist, ein Vergleich durchgeführt werden muss.
In einem balancierten Binärbaum kann bei jedem Vergleich ungefähr die Hälfte des Baumes verworfen werden. Die Höhe eines balancierten Binärbaums mit n Knoten – und damit auch die Zeitkomplexität für die Such-, Einfüge- und Löschoperation – liegt also in der Größenordnung O(log n).
In einem degenerierten Binärbaum entspricht die Höhe der Anzahl der Knoten. Die Anzahl der Vergleiche – und damit auch die Zeitkomplexität für alle Operationen – liegt somit in der Größenordnung O(n).
Binärer Suchbaum im Vergleich
In den folgenden Abschnitten findest du die Vor- und Nachteile des Binären Suchbaums gegenüber anderen Datenstrukturen.
Binärbaum vs. binärer Suchbaum
Der Binäre Suchbaum ist eine Sonderform des Binärbaums, in dem die Binärbaum-Eigenschaften (s. Definiton) erfüllt sind.
Binärer Suchbaum vs. Heap
Im folgenden Vergleich von binärem Suchbaum und Heap gehe ich von einem balancierten binären Suchbaum aus. Bei einem degenerierten binären Suchbaum sind die angegebenen Zeitkomplexitäten entsprechend schlechter, nämlich O(n).
In einem binären Suchbaum kann über die Schlüssel in Sortierreihenfolge iteriert werden. Das ist in einem Heap nicht direkt möglich.
Einfügen und Löschen von Elementen ist in beiden Datenstrukturen mit logarithmischen Aufwand – O(log n) – möglich.
Die Suche nach einem Element ist im binären Suchbaum mit logarithmischen Aufwand – O(log n) – verbunden. Da der Heap nicht sortiert ist, bleibt nur ein Durchsuchen aller Elemente – also linearer Aufwand, O(n).
In einem Heap kann mit konstantem Aufwand – O(1) – auf das größte (Max-Heap) oder kleinste (Min-Heap) Element zugegriffen werden. In einem binären Suchbaum muss dazu entweder allen linken oder allen rechten Kindern gefolgt werden, was logarithmischen Aufwand – O(log n) – erfordert.
Der Aufbau eines Heaps kann in linearer Zeit – O(n) erfolgen – der Aufbau eines BST hat einen Aufwand von O(n log n).
Wann sollte also welche Datenstruktur verwendet werden?
Möchte man nach Elementen suchen oder über alle Elemente in Sortierreihenfolge iterieren, eignet sich der binäre Suchbaum. Interessiert man sich hingegen nur für das größte oder kleinste Element, eignet sich der Heap besser.
Binärer Suchbaum vs. Hashtable
Ich gehe auch in diesem Vergleich von einem balancierten binären Suchbaum aus. Hashtable bezeichnet hier die abstrakte Datenstruktur. Der Vergleich gilt z. B. auch für die konkreten Java-Typen HashMap und HashSet.
In einem binären Suchbaum kann über die Schlüssel in Sortierreihenfolge iteriert werden. Dies ist in einer Hashtable nicht möglich.
In einem binären Suchbaum ist eine Bereichssuche möglich (also die Suche nach allen Elementen, die in einem vorgegebenen Wertebereich liegen). Da die Hashtable unsortiert ist, ist das bei ihr nicht möglich.
In einer Hashtable können nur Elemente gespeichert werden, für die eine Hashfunktion definiert ist. In einem binären Suchbaum können nur Elemente gespeichert werden, für die eine Vergleichsfunktion definiert ist.
In einer Hashtable kann es zu „Bucket Collisions“ kommen. Diese müssen mit (mehr oder weniger) aufwändigen Algorithmen sowohl beim Einfügen als auch bei der Suche aufgelöst werden.
Einfügen, Suchen und Löschen sind in einer Hashtable mit konstantem Aufwand – O(1) – möglich, sofern die Hashtable ausreichend dimensioniert ist und eine geeignete Hashfunktion verwendet wird. Beim binären Suchbaum ist die Zeitkomplexität für alle drei Operationen O(log n). Moderne Hashtables verwenden innerhalb ihrer Buckets ebenfalls binäre Suchbäume, sodass die Zeitkomplexität bei vielen Kollisionen ebenfalls Richtung O(log n) geht.
Ein binärer Suchbaum ist effizienter bzgl. des Platzbedarfs, da er pro Element genau einen Knoten enthält. Eine Hashtable enthält in der Regel auch leere Buckets.
Wann sollte ein binärer Suchbaum eingesetzt werden und wann eine Hashtable?
Möchte man über alle Elemente in Sortierreihenfolge itererieren oder Bereichssuchen durchführen, eignet sich der binäre Suchbaum. Sollen lediglich Elemente eingefügt, gesucht und gelöscht werden, sollte die – bei diesen Operationen schnellere – Hashtable eingesetzt werden.
Binäre Suche vs. binärer Suchbaum
Und zu guter Letzt (da oft danach gefragt wird):
Ein binärer Suchbaum ist eine Datenstruktur wie in diesem Artikel beschrieben.
Die binäre Suche hingegen ist ein Algorithmus, mit der in einer sortierten Liste gesucht werden kann.
Fazit
Dieses Tutorial hat dir gezeigt, was ein binärer Suchbaum ist, und wie man in diesem schnell Elemente suchen, einfügen und löschen kann. Du hast beispielhafte Implementierungen in Java kennengelernt – eine rekursive und eine iterative. Und ich habe dir die Unterschiede des binären Suchbaums gegenüber anderen Datenstrukturen aufgelistet.
Im den nächsten Teilen der Serie werde ich dir die konkreten BST-Implementierungen AVL-Baum und Rot-Schwarz-Baum vorstellen.
Zwei der wichtigsten Themen in der Informatik sind das Sortieren und Suchen von Datensätzen. Eine Datenstruktur, die für beides häufig zum Einsatz kommt, ist der Binärbaum im Allgemeinen und seine Spezialfälle binärer Suchbaum und binärer Heap.
In diesem Artikel erfährst du:
Was ist ein Binärbaum?
Welche Arten von Binärbäumen gibt es?
Wie implementiert man einen Binärbaum in Java?
Welche Operationen stellen Binärbäume bereit?
Was bedeuten pre-order, in-order, post-order und level-order bei der Traversierung von Binärbäumen?
Ein Binärbaum ist eine Baum-Datenstruktur, in der jeder Knoten maximal zwei Kindknoten hat. Die Kindknoten werden als linkes und rechtes Kind bezeichnet.
Binärbaum Beispiel
Ein Binärbaum sieht beispielsweise wie folgt aus:
Binärbaum-Beispiel
Binärbaum Terminologie
Die folgenden Begriffe sollte man als Entwickler kennen:
Ein Knoten (englisch „node“) ist eine Struktur, die einen Wert enthält, sowie optionale Referenzen auf einen linken und einen rechten Kindknoten (oder nur Kind, englisch „child node“ oder „child“).
Die Verbindung zwischen zwei Knoten bezeichnet man als Kante (englisch „edge“).
Der oberste Knoten wird als Wurzel oder Wurzelknoten bezeichnet (englisch „root“ oder „root node“).
Ein Knoten, der Kinder hat, ist ein innerer Knoten (englisch „inner node“, kurz „inode“) und gleichzeitig der Elternknoten (englisch „parent“ oder „parent node“) des oder der Kinder.
Ein Knoten ohne Kinder wird äußerer Knoten (englisch „outer node“) oder auch Blatt (englisch „leaf“ oder „leaf node“) genannt.
Ein Knoten mit nur einem Kind ist ein Halbblatt (englisch „half node“). Achtung: diesen Begriff gibt es – im Gegensatz zu allen anderen – ausschließlich bei Binärbäumen, nicht bei Bäumen im Allgemeinen.
Die Anzahl der Kindknoten bezeichnet man auch als Ausgangsgrad eines Knotens (englisch „degree“).
Die Tiefe (englisch „depth“) eines Knotens gibt an, wie viele Ebenen der Knoten von der Wurzel entfernt ist. Die Wurzel hat also eine Tiefe von 0, die Kinder der Wurzel eine Tiefe von 1, usw.
Die Höhe (englisch „height“) des Binärbaums ist die maximale Tiefe aller Knoten.
Die folgende Grafik zeigt dieselbe Binärbaum-Datenstruktur wie zuvor, beschriftet mit Knotentypen, Knotentiefe und Höhe des Binärbaumes.
Binärbaum-Datenstruktur mit Knotentypen
Eigenschaften von Binärbäumen
Bevor wir zur Implementierung von Binärbäumen und deren Operationen kommen, zunächst eine kurze Übersicht über einige spezielle Arten von Binärbäumen.
Voller Binärbaum
In einem vollen Binärbaum (englisch: full binary tree) haben alle Knoten entweder keine oder zwei Kinder.
Voller Binärbaum
Vollständiger Binärbaum
Leider wird diese Bezeichnung in der Literatur nicht einheitlich verwendet. Manche Autoren bezeichnen einen kompletten Binärbaum als vollständig, andere bezeichnen einen perfekten Binärbaum als vollständig. Ich werde daher nur die Begriffe komplett und perfekt verwenden.
Kompletter Binärbaum
In einem kompletten Binärbaum (englisch: complete binary tree) sind alle Ebenen, außer möglicherweise die letzte, vollständig gefüllt. Wenn die letzte Ebene nicht vollständig gefüllt ist, dann sind deren Knoten so weit wie möglich links angeordnet.
Kompletter Binärbaum
Perfekter Binärbaum
Ein perfekter Binärbaum (englisch: perfect binary tree) ist ein voller Binärbaum, in dem alle Blätter die gleiche Tiefe haben.
Perfekter Binärbaum der Höhe 3
Ein perfekter Binärbaum der Höhe h hat n = 2h+1-1 Knoten und l = 2h Blätter.
Bei einer Höhe von 3 sind das 15 Knoten, davon 8 Blätter.
Balancierter Binärbaum
In einem balancierten Binärbaum (englisch: balanced binary tree) unterscheiden sich die linken und rechten Teilbäume eines jeden Knoten in der Höhe um maximal eins.
Balancierter Binärbaum
Sortierter Binärbaum
In einem sortierten Binärbaum (englisch: sorted binary tree) enthält der linke Teilbaum eines Knotens nur Werte die kleiner (oder gleich) als der Wert des Elternknotens sind, und der rechte Teilbaum nur Werte die größer (oder gleich) als der Wert des Elternknotens sind. Solch eine Datenstruktur wird auch binärer Suchbaum genannt.
Binärbaum in Java
Für die Binärbaum-Implementierung in Java definieren wir zunächst die Datenstruktur für die Knoten (Klasse Node im GitHub-Repository). Der Einfachheit halber verwenden wir int-Primitive als Werte. Wir können natürlich auch jeden anderen oder einen generischen Datentyp verwenden; mit einem int ist der Code allerdings leserlicher – und das ist für dieses Tutorial am wichtigsten.
Die parent-Referenz ist nicht zwingend nötig für die Speicherung und Darstellung des Baumes; sie ist allerdings – zumindest bei bestimmten Arten von Binärbäumen – hilfreich beim Löschen von Knoten.
Der Binärbaum selbst besteht zunächst einmal nur aus dem Interface BinaryTree und dessen Minimal-Implementierung BaseBinaryTree, welche lediglich eine Referenz auf den Wurzelknoten enthält:
Warum wir uns hier die Mühe machen ein Interface zu definieren, wird sich im weiteren Verlauf des Tutorials zeigen.
Die Binärbaum-Datenstruktur ist damit vollständig definiert.
Binärbaum-Traversierung
Eine der wichtigsten Operationen auf Binärbäumen ist die Traversierung aller Knoten, also das Besuchen aller Knoten in einer bestimmten Reihenfolge. Die gängigsten Arten der Traversierung sind:
In den folgenden Abschnitten werden die verschiedenen Arten an folgendem Beispiel gezeigt:
Beispiel für Binärbaum-Traversierung
Das oben erwähnte Besuchen während der Traversierung realisieren wir mit dem Visitor-Pattern, d. h. wir erstellen ein Visitor-Objekt, das wir an die Traversierungsmethode übergeben.
Tiefensuche im Binärbaum
Bei der Tiefensuche (englisch: depth-first search, DFS) wird in einer bestimmten Reihenfolge:
der aktuelle Knoten besucht (im folgenden als „N“ bezeichnet),
die Tiefensuche rekursiv auf das linke Kind aufgerufen (im folgenden „L“),
die Tiefensuche rekursiv auf das rechte Kind aufgerufen (im folgenden „R“).
Die gängigen Reihenfolgen sind:
Hauptreihenfolge (pre-order)
In der Hauptreihenfolge (Kennzeichnung: N–L–R) erfolgt die Traversierung in folgender Reihenfolge:
Besuchen des aktuellen Knotens „N“
Rekursiver Aufruf der Tiefensuche auf linken Teilbaum „L“
Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum „R“
Die Knoten des Beispielbaumes werden, wie in folgender Grafik zu sehen, in folgender Reihenfolge besucht: 3→1→13→10→11→16→15→2
Binärbaum-Traversierung in Hauptreihenfolge (pre-order)
Die Methode kann entweder direkt aufgerufen werden – dann muss ihr der Wurzelknoten übergeben werden – oder über die nicht-statische Methode traversePreOrder() der gleichen Klasse (DepthFirstTraversalRecursive ab Zeile 17):
Dazu muss eine Instanz von DepthFirstTraversalRecursive erstellt werden, wobei dem Konstruktur eine Referenz auf den Binärbaum übergeben wird:
new DepthFirstTraversalRecursive(tree).traversePreOrder(visitor);Code-Sprache:Java(java)
Eine iterative Implementierung ist mit einem Stack möglich (Klasse DepthFirstTraversalIterative ab Zeile 20). Die iterativen Implementierungen sind recht komplex, weshalb ich sie hier nicht mit abdrucke.
Die iterative Implementierung, die bei der Post-Order-Traversierung noch komplizierter ist als bei der Pre-Order-Traversierung, findest du in DepthFirstTraversalIterative ab Zeile 44.
Symmetrische Reihenfolge (in-order)
In der symmetrischen Reihenfolge (Kennzeichnung: L–N–R) erfolgt die Traversierung in folgender Reihenfolge:
Rekursiver Aufruf der Tiefensuche auf linken Teilbaum „L“
Besuchen des aktuellen Knotens „N“
Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum „R“
Die Knoten des Beispielbaumes werden in folgender Reihenfolge besucht: 13→1→3→11→10→15→16→2
Binärbaum-Traversierung in symmetrischer Reihenfolge (in-order)
Im binären Suchbaum werden bei der Reverse-In-Order-Traversierung die Knoten in absteigender Reihenfolge ihrer Sortierung besucht.
Breitensuche im Binärbaum
Bei der Breitensuche (englisch: breadth-first, BFS) – auch Level-Order-Traversierung genannt – werden die Knoten von der Wurzel beginnend, Ebene für Ebene, von links nach rechts besucht.
Es ergibt sich folgende Reihenfolge: 3→1→10→13→11→16→15→2
Binärbaum-Traversierung via Breitensuche (level-order)
Um die Knoten in dieser Reihenfolge zu besuchen, benötigen wir eine Queue, in der wir zuerst den Root-Knoten einfügen, und dann wiederholt das erste Element entnehmen, dieses besuchen und dessen Kinder in die Queue eintragen – solange bis die Queue wieder leer ist.
Neben der Traversierung sind weitere grundlegenden Operationen auf Binärbäumen das Einfügen sowie das Löschen von Knoten.
Operationen zum Suchen werden von speziellen Binärbäume wie z. B. dem binären Suchbaum bereitgestellt. Ohne spezielle Eigenschaften können wir im Binärbaum nur suchen, in dem wir über alle Knoten traversieren und diese mit dem gesuchten Element vergleichen.
Element einfügen
Beim Einfügen neuer Elemente müssen wir verschiedene Fälle unterscheiden:
Fall A: Knoten unter Blatt oder Halbblatt einfügen
Es ist leicht einen neuen Knoten an ein Blatt oder ein Halbblatt anzuhängen. Hierzu müssen wir lediglich die left– oder right-Referenz des Parent-Knotens P, an den wir den neuen Knoten N anhängen wollen, auf den neuen Knoten setzen. Wenn wir auch mit parent-Referenzen arbeiten, müssen wir diese im neuen Knoten N auf den Parent-Knoten P setzen.
Anhängen eines neuen Knotens an ein BlattAnhängen eines neuen Knotens an ein Halbblatt
Fall B: Knoten zwischen internen Knoten und dessen Kind einfügen
Doch wie geht man vor, wenn man einen Knoten zwischen einem internen Knoten und einem seiner Kinder einfügen will?
Neuen Knoten unter internen Knoten einfügen
Das ist nur mit einer Reorganisation des Baumes möglich. Wie genau der Baum reorganisiert wird, hängt von der konkreten Art des Binärbaumes ab.
Wir implementieren in diesem Tutorial einen sehr einfachen Binärbaum und gehen für die Reorganisation wie folgt vor:
Wenn der neue Knoten N als linkes Kind unter den internen Knoten P eingefügt werden soll, wird Ps aktueller linker Teilbaum L als linkes Kind unter den neuen Knoten N gesetzt. Entsprechend wird der Parent von L auf N gesetzt und der Parent von N auf P.
Wenn der neue Knoten N als rechtes Kind unter den internen Knoten P eingefügt werden soll, wird Ps aktueller rechter Teilbaum R als rechtes Kind unter den neuen Knoten N gesetzt. Entsprechend wird der Parent von R auf N gesetzt und der Parent von N auf P.
Die folgende Grafik zeigt den zweiten Fall: Wir fügen den neuen Knoten N zwischen P und R ein:
Einfügen eines neuen Knotens zwischen internem Knoten und seinem Kind
Das ist – wie gesagt – eine sehr einfache Implementierung. Im Beispiel oben resultiert diese in einem stark unbalancierten Binärbaum.
Spezielle Binärbäume gehen hier anders vor, um eine Baum-Struktur beizubehalten, die die speziellen Eigenschaften des jeweiligen Binärbaumes (Sortierung, Balancierung, etc.) erfüllt.
Baumknoten einfügen – Java-Quellcode
Hier siehst du den Code zum Einfügen eines neuen Knotens mit Wert data unter den gegebenen Knoten parent an die gegebene Seite side (links oder rechts) mit der im vorherigen Abschnitt festgelegten Reorganisations-Strategie (Klasse SimpleBinaryTree ab Zeile 18).
Auch beim Löschen eines Knotens müssen wir verschiedene Fälle unterscheiden.
Fall A: Knoten ohne Kinder (Blatt) löschen
Ist der zu löschende Knoten N ein Blatt, hat also selbst keine Kinder, dann wird der Knoten einfach entfernt. Dazu prüfen wir, ob der Knoten linkes oder rechtes Kind des Parents P ist und setzen entsprechend dessen left– oder right-Referenz auf null.
Knoten ohne Kind (Blatt) aus Binärbaum entfernen
Fall B: Knoten mit einem Kind (Halbblatt) löschen
Hat der zu löschende Knoten N selbst ein Kind C, dann rückt dieses an die gelöschte Position auf. Wir müssen wieder prüfen, ob der zu löschende Knoten N linkes oder rechtes Kind des Parents P ist. Danach setzen wir entsprechend die left– oder right-Referenz des Parents auf das Kind C des zu löschenden Knotens N (den vorherigen Enkel) – und die parent-Referenz des Kindes C auf den Parent P des zu löschenden Knotens N (den vorherigen Großeltern-Knoten).
Knoten mit einem Kind (Halbblatt) aus Binärbaum entfernen
Fall C: Knoten mit zwei Kindern löschen
Wie geht man vor, wenn man einen Knoten mit zwei Kindern löschen will?
Wie entfernt man einen internen Knoten aus einem Binärbaum?
Dies ist nur mit einer Umorganisation des Binärbaum möglich. Analog zum Einfügen gibt es auch für das Löschen – je nach konkreter Art des Binärbaumes – unterschiedliche Strategien. In einem Heap beispielsweise wird an die Position des gelöschten Knotens der letzte Knoten des Baums gesetzt und danach der Heap repariert.
Wir verwenden für unser Tutorial folgende, einfach zu implementierende Variante:
Wir ersetzen den gelöschten Knoten N durch dessen linken Teilbaum L.
Wir hängen den rechten Teilbaum R an den am weitesten rechts liegenden Knoten des linken Teilbaums an.
Knoten mit zwei Kindern aus Binärbaum entfernen
Es ist gut zu erkennen, wie diese Strategie zu einem sehr unbalancierten Binärbaum führt. Binärbäume wir der binäre Suchbaum und der Binäre Heap haben daher – wie auch beim Einfügen – komplexere Strategien.
Baumknoten löschen – Java-Quellcode
Die folgende Methode (Klasse SimpleBinaryTree ab Zeile 71) entfernt den übergebenen Knoten node aus dem Baum. Die Fälle A, B und C sind durch entsprechende Kommentare gekennzeichnet.
publicvoiddeleteNode(Node node){
if (node.parent == null && node != root) {
thrownew IllegalStateException("Node has no parent and is not root");
}
// Case A: Node has no children --> set node to null in parentif (node.left == null && node.right == null) {
setParentsChild(node, null);
}
// Case B: Node has one child --> replace node by node's child in parent// Case B1: Node has only left childelseif (node.right == null) {
setParentsChild(node, node.left);
}
// Case B2: Node has only right childelseif (node.left == null) {
setParentsChild(node, node.right);
}
// Case C: Node has two childrenelse {
removeNodeWithTwoChildren(node);
}
// Remove all references from the deleted node
node.parent = null;
node.left = null;
node.right = null;
}Code-Sprache:Java(java)
Die Methode setParentsChild() prüft, ob der zu löschende Knoten das linke oder rechte Kind seines Elternknotens ist und ersetzt die entsprechende Referenz im Elternknoten durch den Kindknoten child. Dieser ist null, wenn der zu löschende Knoten keine Kinder hat und entsprechend die Kind-Referenz im Elternknoten auf null gesetzt werden soll.
Für den Fall, dass der zu löschende Knoten die Wurzel ist, wird einfach die Wurzelreferenz neu gesetzt.
privatevoidsetParentsChild(Node node, Node child){
// Node is root? Has no parent, set root reference insteadif (node == root) {
root = child;
if (child != null) {
child.parent = null;
}
return;
}
// Am I the left or right child of my parent?if (node.parent.left == node) {
node.parent.left = child;
} elseif (node.parent.right == node) {
node.parent.right = child;
} else {
thrownew IllegalStateException(
"Node " + node.data + " is neither a left nor a right child of its parent "
+ node.parent.data);
}
if (child != null) {
child.parent = node.parent;
}
}Code-Sprache:Java(java)
In Fall C (Knoten mit zwei Kindern löschen) wird der Baum, wie im vorangegangenen Abschnitt beschrieben, umorganisiert. Dies geschieht in der separaten Methode removeNodeWithTwoChildren():
privatevoidremoveNodeWithTwoChildren(Node node){
Node leftTree = node.left;
Node rightTree = node.right;
setParentsChild(node, leftTree);
// find right-most child of left tree
Node rightMostChildOfLeftTree = leftTree;
while (rightMostChildOfLeftTree.right != null) {
rightMostChildOfLeftTree = rightMostChildOfLeftTree.right;
}
// append right tree to right child
rightMostChildOfLeftTree.right = rightTree;
rightTree.parent = rightMostChildOfLeftTree;
}Code-Sprache:Java(java)
Zum Abschluss möchte ich dir eine alternative Repräsentation des Binärbaums zeigen: die Speicherung in einem Array.
Dabei enthält das Array so viele Elemente wie ein perfekter Binärbaum der Höhe des zu speichernden Binärbaumes, also 2h+1-1 Elemente bei einer Höhe h (in der folgenden Grafik: 7 Elemente bei Höhe 2).
Die Knoten des Baumes werden von der Wurzel abwärts, Ebene für Ebene, von links nach rechts durchnummeriert und auf das Array abgebildet, wie folgende Grafik zeigt:
Array-Repräsentation eines Binärbaums
Nicht vorhandene Knoten können durch einen festgelegten Wert dargestellt werden. Sollte der Baum beispielsweise nur nicht-negative ganze Zahlen enthalten, könnte ein fehlender Knoten durch den Wert -1 dargestellt werden.
Bei einem kompletten Binärbaum kann alternativ das Array entsprechend verkürzt werden oder die Anzahl der Knoten als zusätzlicher Wert gespeichert werden.
Vor- und Nachteile der Array-Darstellung
Die Array-Darstellung hat folgende Vorteile:
Die Speicherung ist kompakter, da keine Referenzen auf Kinder (und ggf. Eltern) benötigt werden.
Trotzdem gelangt man schnell von Eltern zu Kindern und umgekehrt: Für einen Knoten an Index i befinden sich…
das linke Kind an Index 2i+1,
das rechte Kind an Index 2i+2,
der Elternknoten an Index i/2 abgerundet.
Eine Level-Order-Traversierung kann durch simple Iteration über das Array durchgeführt werden.
Dagegen aufwiegen muss man folgende Nachteile:
Wenn der Binärbaum nicht komplett ist, wird Speicherplatz durch ungenutzte Array-Felder verschwendet.
Wenn der Baum über die Array-Größe hinaus wächst, müssen die Daten in ein neues, größeres Array kopiert werden.
Wenn der Baum kleiner wird, sollten (mit einem gewissen Spielraum) die Daten in ein neues, kleineres Array kopiert werden, um ungenutzten Speicherplatz freizugeben.
Zusammenfassung
In diesem Artikel hast du erfahren, was ein Binärbaum ist, welche Arten von Binärbäumen es gibt, welche Operationen auf Binärbäume anwendbar sind und wie man Binärbäume in Java implementiert.
Wir Entwickler stehen oft vor der Aufgabe in einem sortierten Array (oder in einer Liste) die Position eines gesuchten Elements zu bestimmen. Der einfachste Ansatz wäre das Array von links nach rechts zu durchlaufen und dabei jedes Element mit dem gesuchten Element abzugleichen. Das nennt man „lineare Suche“.
Deutlich schneller geht es mit der „binären Suche“. In diesem Artikel erfährst du:
Wie funktioniert die Binärsuche?
Wie implementiert man die binäre Suche in Java (rekursiv und iterativ)?
Welche binären Suchfunktionen stellt das JDK zur Verfügung?
Wie schnell ist die binäre Suche im Vergleich zur linearen Suche?
Wann ist es sinnvoll in einer LinkedList binär zu suchen?
Wenn wir früher ein unbekanntes Wort übersetzen wollten, hatten wir dafür keine App, sondern mussten dieses in einem Wörterbuch nachschlagen. Theoretisch könnte man nun von vorne nach hinten jede Seite von links oben nach rechts unten nach dem gewünschten Wort durchsuchen.
Mit etwas Glück finden wir das Wort auf den ersten Seiten des Buches. Wenn wir Pech haben, finden wir es erst gegen Ende des Buches – oder gar nicht (das würden wir erst auf der allerletzten Seite feststellen). Auch bei relativ weit vorne liegenden Wörtern (wie z. B. „Binärsuche“) müssten wir so ziemlich lange suchen.
Diese Vorgehensweise nennt sich „lineare Suche“. Das folgende Bild zeigt ein vereinfachtes Beispiel mit Zahlen statt Wörtern. Gesucht werden soll die Position der Zahl 61 im dargestellten Array.
Lineare Suche in einem Zahlen-Array
In diesem vereinfachten Beispiel benötigen wir sechs Schritte, um die 61 zu finden.
Natürlich würde in einem Wörterbuch niemand auf diese Weise suchen. Stattdessen schlagen wir das Buch ungefähr in der Mitte auf und schauen, ob das Wort alphabetisch davor oder danach einzuordnen ist. Wir wissen somit, in welcher Hälfte des Buchs sich das Wort befindet und können die andere Hälfte ignorieren. Danach suchen wir wieder die Mitte und schränken den Suchbereich erneut auf die Hälfte (also insgesamt ein Viertel) ein. Mit jedem weiteren Suchschritt halbieren wir die Anzahl der verbleibenden Seiten. Auf diese Weise kommen wir in relativ wenigen Schritten zur Zielseite – und auf der Zielseite zum gesuchten Wort.
Das nennt sich dann „binäre Suche“. Das folgende Bild macht deutlich, dass die Suche so wesentlich schneller zum Ergebnis führt als die lineare Suche:
Binäre Suche in einem Zahlen-Array
Mit der Binärsuche brauchen wir lediglich drei Schritte:
Im ersten Schritt vergleichen wir den gesuchten Wert 61 mit dem mittleren Element 36. Der gesuchte Wert ist größer, muss sich also rechts von der 36 befinden.
Im zweiten Schritt vergleichen wir die 61 mit dem mittleren Element des rechten Bereichs, der 79. Der gesucht Wert ist kleiner, muss sich also links von der 79 befinden.
Zwischen 36 und 79 befindet sich nur noch ein Element. Auch dieses müssen wir noch einmal mit dem gesuchten Element vergleichen. In diesem Beispiel haben wir das gesuchte Element 61 gefunden. Hier hätte sich aber auch eine andere Zahl zwischen 36 und 79 befinden können. Das hätte bedeutet, dass das Array gar keine 61 enthält.
Die Binärsuche macht selbstverständlich nur dann Sinn, wenn die Wörter im Wörterbuch (so wie die Zahlen im Beispiel) sortiert sind. Würden die Wörter in zufälliger Reihenfolge abgedruckt sein, bliebe uns nichts anderes übrig als Wort für Wort – also linear – zu suchen.
Binäre Suche – Pseudocode
Im folgenden Pseudocode bezeichnen wir das gesuchte Element mit „Schlüssel“ (im Englischen wird es mit „key“ bezeichnet).
Bestimme die mittlere Position des zu durchsuchenden Bereichs des Arrays.
Lese das Element an der mittleren Position.
Vergleiche den Schlüssel mit dem mittleren Element:
Ist der Schlüssel gleich dem mittleren Element, dann haben wir das Ziel erreicht. Gebe die mittlere Position als Ergebnis zurück.
Ist der Schlüssel kleiner als das mittlere Element, dann führe die Binärsuche im Teilarray links von der mittleren Position aus. Es sei denn, dieses Teilarray hat die Länge 0, dann ist die Suche ohne Ergebnis beendet.
Ist der Schlüssel größer als das mittlere Element, dann führe die Binärsuche im Teilarray rechts von der mittleren Position aus. Es sei denn, dieses Teilarray hat die Länge 0, dann ist die Suche ohne Ergebnis beendet.
Implementierung von binärer Suche in Java
Die Binärsuche kann rekursiv oder iterativ implementiert werden.
Binäre Suche rekursiv
Die Pseudocode für die binäre Suche aus dem vorherigen Kapitel legt eine rekursive Implementierung nahe.
Die rekursive Implementierung in Java für ein Array von int-Primitiven sieht wie folgt aus:
publicstaticintbinarySearchRecursively(int[] array, int key){
return binarySearchRecursively(array, 0, array.length, key);
}
publicstaticintbinarySearchRecursively(
int[] array, int fromIndex, int toIndex, int key){
if (toIndex <= fromIndex) return -1;
int mid = (fromIndex + toIndex) >>> 1;
int midVal = array[mid];
if (key == midVal) {
return mid;
} elseif (key < midVal) {
return binarySearchRecursively(array, fromIndex, mid, key);
} else {
return binarySearchRecursively(array, mid + 1, toIndex, key);
}
}Code-Sprache:Java(java)
Wichtig ist hierbei die mittlere Position mid mittels „unsigned right shift“ zu berechnen:
int mid = (fromIndex + toIndex) >>> 1
Und nicht wie folgt:
int mid = (fromIndex + toIndex) / 2
Für den Fall dass die Summe größer ist als Integer.MAX_VALUE, würde die zweite Variante zu einem Overflow bzw. einem „Roll Over“ führen, und das Ergebnis wäre eine negative Zahl.
Ohne den >>>-Operator wäre auch folgender Weg korrekt:
int mid = fromIndex + (toIndex - fromIndex) / 2;
Aber das ist längst nicht so cool ;-)
Binäre Suche iterativ
Rekursion benötigt zusätzliche CPU-Zyklen und zusätzlichen Speicherplatz auf dem Heap. Daher sind iterative Implementierungen in der Regel vorzuziehen.
Die entsprechende iterative Java-Implementierung für ein int-Array sieht wie folgt aus:
publicstaticintbinarySearchIteratively(int[] array, int key){
return binarySearchIteratively(array, 0, array.length, key);
}
publicstaticintbinarySearchIteratively(
int[] array, int fromIndex, int toIndex, int key){
int low = fromIndex;
int high = toIndex;
while (low < high) {
int mid = (low + high) >>> 1;
int midVal = array[mid];
if (key == midVal) {
return mid;
} elseif (key < midVal) {
high = mid;
} else {
low = mid + 1;
}
}
return -1;
}Code-Sprache:Java(java)
Die Variablen low und high sind hier nicht zwingend erforderlich. Man könnte innerhalb der while-Schleife auch fromIndex und toIndex verändern. Methodenparameter zu ändern gilt jedoch in der Regel als unsauberes Design.
Binäre Suche in Arrays müssen wir natürlich nicht selbst implementieren. Das JDK bietet bereits entsprechende Methoden für Arrays aller primitiven Datentypen und für Objekt-Arrays in der java.util.Arrays-Klasse. Außerdem bietet es eine Methode für die Binärsuche in Listen in der java.util.Collections-Klasse.
Arrays.binarySearch()
In einem int-Array können wir beispielsweise wie folgt suchen:
In einer entsprechenden ArrayList von Integer-Objekten können wir wie folgt suchen:
List<Integer> list = new ArrayList<>(List.of(10, 19, 23, 25, 36, 61, 79, 81, 99));
int posOf36 = Collections.binarySearch(list, 36);Code-Sprache:Java(java)
Achtung: Die Methode Collections.binarySearch() kann für jede Klasse aufgerufen werden, die das List-Interface implementiert. Also beispielsweise auch für LinkedList.
In einer verketteten Liste kann allerdings nicht direkt, sondern nur per Iteration auf ein bestimmtes Element zugegriffen werden, womit wir (fast) wieder bei der linearen Suche angekommen sind. Mehr dazu – und warum die Binärsuche auf einer LinkedList dennoch sinnvoll sein kann – erfährst du im nächsten Kapitel.
Zeitkomplexität von binärer Suche
Bei der binären Suche halbieren wir mit jedem Suchschritt die Anzahl der noch zu durchsuchenden Einträge. Oder anders herum: wenn sich die Anzahl der Einträge verdoppelt, brauchen wir nur einen Suchschritt mehr.
Dies entspricht logarithmischem Aufwand, also O(log n).
Mit dem Programm BinarySearchRuntime aus dem GitHub-Repository können wir die theoretisch hergeleitete Zeitkomplexität überprüfen. Das Programm generiert zufällige Arrays mit 10.000 bis 200.000.000 Elementen und sucht darin nach einem zufällig ausgewählten Element.
Da die Zeiten im Bereich von Nanosekunden liegen, wird pro Messung nach 100 verschiedenen Keys gesucht. Die Messung wird für jede Array-Größe 100 mal wiederholt; danach wird der Median ausgegeben. Der folgende Graph zeigt die mittlere Laufzeit in Abhängigkeit von der Array-Größe:
Laufzeit der Binärsuche in Abhängigkeit von der Array-Größe
Der logarithmische Verlauf ist sehr gut zu erkennen.
Vergleich binäre Suche vs. lineare Suche
Bei der linearen Suche finden wir im best case das gesuchte Element im ersten Schritt. Im worst case müssen wir das komplette Array durchsuchen. Im average case die Hälfte der Einträge. Bei n Einträgen sind das n/2 Suchschritte. Die Dauer der Suche steigt also linear mit der Anzahl der Einträge. Wir sagen auch:
Die Zeitkomplexität der linearen Suche beträgt O(n).
Mit dem Programm LinearSearchRuntime können wir die Laufzeit der linearen Suche messen. Die folgende Grafik zeigt den Vergleich der Laufzeiten von binärer und der linearen Suche. Ich musste den Ausschnitt auf 100.000 Elemente verkleinern, um überhaupt noch einen Anstieg der Messwerte für die Binärsuche erkennen zu können:
Vergleich der Laufzeiten von binärer und linearer Suche
Der lineare Aufwand der linearen Suche ist sehr gut zu erkennen. Auch wird deutlich, dass die binäre Suche um Größenordnungen schneller ist als die lineare.
Laufzeit von binärer Suche für kleine Arrays
Aufgrund der höheren Komplexität des Codes der binären Suche kann die lineare Suche für sehr kleine Arrays schneller sein. Das folgende Diagramm zeigt einen Ausschnitt des Vergleichs der Laufzeiten für bis zu 500 Elemente. Jeder Messpunkt ist der Median aus 100 Messungen mit jeweils 10.000 Wiederholungen.
Binäre und lineare Suche für kleine Arrays
Das bestätigt die Vermutung. Für Arrays bis maximal ca. 230 Elemente ist die lineare Suche schneller als die binäre. Das ist natürlich keine allgemein gültige Aussage, sondern gilt erstmal nur für meinen Laptop und das verwendete JDK.
Man sieht auch noch einmal schön das lineare Wachstum – O(n) – im Vergleich zum logarithmischen Wachstum – O(log n).
Laufzeit von binärer Suche bei einer LinkedList
Im Kapitel Binäre Suche im JDK habe ich erwähnt, dass die Methode Collections.binarySearch() auch auf eine LinkedList angewendet werden kann. Collections.binarySearch() unterscheidet intern nach Listen, die das RandomAccess-Interface implementieren, wie z. B. ArrayList, und nach anderen Listen. Bei Listen mit „random access“ wird eine reguläre binäre Suche durchgeführt.
Um bei Listen ohne „random access“ auf das mittlere Element zugreifen zu können, müssen wir den Elementen vom Anfang bis zur Mitte Element für Element folgen. Von dort müssten wir dann wiederum zur Mitte der linken oder rechten Hälfte der Liste Element für Element folgen. Die folgende Grafik soll dies verdeutlichen:
Binärsuche in einer doppelt verketteten Liste
Um beispielsweise die Position der 19 zu suchen, müssten wir erst den orangenen Pfeilen zur Mitte folgen, dann den blauen Pfeilen zurück zur 23, und schließlich dem gelben Pfeil zur 19.
Das funktioniert so nur bei einer doppelt verketteten Liste. Bei einer einfach verketteten Liste müsste man für die Iteration nach links immer wieder an den Anfang springen und von dort wieder den Pfeilen nach rechts folgen.
Egal ob einfach oder doppelt verkettet – wir müssen auf jeden Fall über mehr Elemente iterieren als bei der linearen Suche. Während wir bei der linearen Suche im Durchschnitt n/2 Suchschritte haben, iterieren wir bei der binären Suche allein beim ersten Schritt zur Mitte schon über n/2 Elemente. Beim zweiten Schritt noch einmal über n/4 Elemente, beim dritten Schritt über n/8 Elemente, usw.
Auf den ersten Blick ergibt die Binärsuche in einer LinkedList also keinen Sinn.
Wann ist die Binärsuche in einer LinkedList sinnvoll?
Dennoch kann die Binärsuche für eine LinkedList schneller sein als eine lineare Suche. Zwar müssen wir (wie im vorherigen Abschnitt gezeigt) über mehr Elemente iterieren – die Anzahl der Vergleiche bleibt aber in der Größenordnung O(log n)!
Je nach Kosten der Vergleichsfunktion – bei einem Objekt können diese deutlich höher ausfallen als bei einem primitiven Datentyp – kann dies einen erheblichen Unterschied ausmachen. Solltest du also jemals in einer LinkedList suchen müssen, dann lohnt es sich auf jeden Fall die Binärsuche mit Collections.binarySearch() auszuprobieren und mit der linearen Suche zu vergleichen.
Fazit
Dieser Artikel hat die Funktionsweise der binären Suche und ihre Vorteile gegenüber linearer Suche bei sortierten Arrays und Listen aufgezeigt. Die theoretisch hergeleitete Zeitkomplexität wurde an einem Beispiel nachgewiesen. Außerdem wurde gezeigt, dass die Binärsuche auch bei einer doppelt verketten Liste sinnvoll sein kann.
Ein sehr ähnliches Verfahren ist die Suche in einem Binären Suchbaum.
In dieser Serie über Pathfinding-Algorithmen hast du bereits Dijkstras Algorithmus, den A*-Algorithmus und den Bellman-Ford-Algorithmus kennengelernt. In diesem letzten Teil erfährst du, wie der Floyd-Warshall-Algorithmus funktioniert und für welche Zwecke man ihn einsetzt.
Um folgende Themen geht es im einzelnen:
Was ist der Einsatzzweck des Floyd-Warshall-Algorithmus?
Wie unterscheidet sich der Floyd-Warshall-Algorithmus von den bisher vorgestellten Pathfinding-Algorithmen?
Wie funktioniert der Floyd-Warshall-Algorithmus (Schritt für Schritt an einem Beispiel erklärt)?
Wie implementiert man den Floyd-Warshall-Algorithmus in Java?
Wie bestimmt man die Zeitkomplexität des Floyd-Warshall-Algorithmus?
Den Quellcode der gesamten Artikelserie über Pathfinding-Algorithmen findest du in diesem GitHub-Repository.
Wann setzt man den Floyd-Warshall-Algorithmus ein?
Alle bisher vorgestellten Pathfinding-Algorithmen finden den kürzesten Weg von einem Ausgangsknoten zu einem Zielknoten (oder zu allen anderen Knoten eines Graphen).
Dijkstra priorisiert die Suche dabei nach Gesamtkosten vom Ausgangsknoten. A* priorisiert zusätzlich nach geschätzen Kosten bis zum Ziel. Und Bellman-Ford priorisiert gar nicht, kann dafür mit negativen Kantengewichten umgehen.
Floyd-Warshall hingegen findet die kürzesten Wege zwischen allen Paaren von Start- und Zielknoten (Floyds Variante).
Transitive Hülle eines Graphen
Alternativ berechnet Floyd-Warshall die sogenannte „transitive Hülle“ eines Graphen (Warshalls Variante). Die transitive Hülle erweitert einen Graphen um Kanten zwischen allen indirekt verbundenen Knotenpaaren. Wenn der Graph beispielsweise zwei Kanten hat – eine von A nach B und eine von B nach C – dann vervollständigt die transitive Hülle den Graphen um die Kante von A nach C (da ein Weg von A nach C über B existiert).
Die folgende Grafik zeigt ein etwas komplexeres Beispiel mit vier Knoten – links der Ausgangsgraph und rechts dessen transitive Hülle. Die blauen Pfeile stellen die hinzugekommenen, indirekten Verbindungen dar:
Transitive Hülle eines Graphen
Beide Aufgabenstellungen sind sehr ähnlich: Wenn ein kürzester Weg zwischen zwei Knotenpaaren existiert, dann gehört dieses Knotenpaar auch in die transitive Hülle – und vice versa. Daher werden die Varianten von Floyd und Warshall zu einem Algorithmus zusammengefasst.
Wie funktioniert der Floyd-Warshall-Algorithmus?
Der Algorithmus ist sehr einfach zu implementieren, wie du später feststellen wirst. Die Erklärung ist allerdings etwas knifflig. Ich werde den Algorithmus daher zuerst an einem Beispiel beschreiben.
Floyd-Warshall-Algorithmus – Beispiel
Der folgende Beispiel-Graph enthält fünf Knoten, bezeichnet mit A, B, C, D, E, und verschiedene gerichtete und gewichtete Kanten:
Floyd-Warshall-Algorithmus: Beispiel-Graph
Die Zahlen an den Kanten (die Kantengewichte) stellen die Kosten für den jeweiligen Weg dar. Die Kosten von E nach B betragen beispielsweise 4.
Vorbereitung – Matrix aller Knotenpaare
Als Vorbereitung erstellen wir eine n × n große Matrix (n ist die Anzahl der Knoten), in der wir für jedes Knotenpaar (i, j) das Gewicht der Kante von i nach j eintragen, falls diese existiert. Ansonsten tragen wir unendlich (∞) ein. Auf der Diagonalen (die Entfernung eines Knoten zu sich selbst) tragen wir jeweils 0 ein.
von / nach
A
B
C
D
E
A
0
2
∞
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
∞
∞
1
0
3
E
1
4
∞
∞
0
Aus der Tabelle können wir beispielsweise ablesen: Die Kosten von A nach B betragen 2 (Zeile A, Spalte B).
Floyd-Warshall-Algorithmus – Schritt für Schritt
Wir führen nun die folgenden fünf Iterationen aus. Dabei betrachten wir jeweils einen der Knoten als möglichen Zwischenknoten.
Iteration 1 – Indirekte Wege über Zwischenknoten A
Wir vergleichen für alle Knotenpaare (i, j) die eingetragenen Kosten des direkten Weges mit den Kosten des indirekten Weges von i nach j über Knoten A – also die Kosten von Knoten i nach Knoten A plus der Kosten von Knoten A nach Knoten j (sofern solch ein Weg existiert). Sind die Kosten über Zwischenknoten A geringer als die bisherigen, ersetzen wir die Kosten in der Matrix.
Knotenpaare, bei denen i = j ist oder i = A oder j = A können wir überspringen. Die Entfernung eines Knotens zu sich selbst ist immer 0. Und wenn Start oder Ziel bereits A sind, gibt es nicht auch noch einen indirekten Weg über A.
Wir beginnen somit mit dem Knotenpaar (B, C). Die Kosten des direkten Weges sind 6 (abzulesen in Zeile B, Spalte C). Von B nach A ist aktuell kein Weg bekannt (in Zeile B, Spalte A steht unendlich). Wir können also in diesem Schritt keinen kürzeren Weg über A finden. Dementsprechend können wir auch keine kürzeren Wege für (B, D) und (B, E) via A finden.
Auch von C und D gibt es aktuell keine bekannten Wege zu Knoten A (Zeilen C und D, jeweils Spalte A enthält unendlich). Wir können somit für (C, B), (C, D), (C, E), (D, B), (D, C), (D, E) aktuell keine kürzeren Wege finden.
Beim Knotenpaar (E, B) beginnt es interessant zu werden. Die aktuellen Kosten des direkten Weges E→B betragen 4. Gibt es einen kürzeren Weg über Knoten A? Hier noch mal der entsprechende Ausschnitt des Graphen:
Iteration 1: Vergleich Pfad E→B mit E→A→B
Die Kosten von E nach A betragen 1 (in der Tabelle Zeile E, Spalte A); die Kosten von A nach B betragen 2 (Zeile A, Spalte B). In Summe ergibt das 3. Die Kosten des indirekten Weges von E nach B über Knoten A sind also geringer als die des direkten Weges. Wir haben also folgenden, kürzeren Weg gefunden:
Iteration 1: Pfad E→B→A ist kürzer als E→B
Wir ersetzen daher in Zeile E, Spalte B die 4 durch eine 3 (in der Tabelle fett hervorgehoben):
von / nach
A
B
C
D
E
A
0
2
∞
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
∞
∞
1
0
3
E
1
3
∞
∞
0
Wir betrachten als nächsten Knotenpaar (E, C). Die aktuellen Kosten betragen unendlich, da noch kein Weg gefunden wurde. Gibt es einen indirekten Weg über A, also E→A→C? Da aktuell kein Weg von A nach C bekannt ist (Zeile A, Spalte C enthält unendlich), ist die Antwort „nein“.
Zuletzt schauen wir auf das Knotenpaar (E, D). Da auch von A nach D aktuell kein Weg bekannt ist, finden wir in diesem Schritt auch keinen indirekten Weg E→A→D.
Wir haben alle Knotenpaare betrachtet; Schritt 1 ist damit beendet. Wir kennen jetzt für alle Knotenpaare die niedrigsten Kosten, wenn wir auch indirekte Wege über Zwischenknoten A zulassen. Insbesondere haben wir in diesem Schritt einen kürzeren Weg von E nach B via Knoten A gefunden.
Iteration 2 – Indirekte Wege über Zwischenknoten B
In der zweiten Iteration vergleichen wir für alle Knotenpaare (i, j) wiederum die eingetragenen Kosten (dies sind nun entweder die Kosten des direkten Weges oder die über Zwischenknoten A – je nachdem welche geringer sind) mit den Kosten von i nach j über Knoten B.
Die Kosten zu und von Knoten B lesen wir aus der Matrix ab. Das heißt, dass dies nicht unbedingt die Kosten des direkten Weges zu/von Knoten B sein müssen. Es könnten auch die in Schritt 1 bestimmten, niedrigeren Kosten via Zwischenknoten A sein (z. B. von E nach B: 3 via A anstatt 4 direkt).
Wir beginnen mit Knotenpaar (A, C). Bisher wurde noch kein Weg gefunden (Zeile A, Spalte C enthält unendlich). Schauen wir uns den indirekten Weg über B an:
Iteration 2: von A nach C über B
Die Kosten von A nach B betragen 2, und die Kosten von B nach C betragen 6. Die Summe ist 8. Das ist auf jeden Fall besser als gar kein Weg. Wir tragen daher in Zeile A, Spalte C die 8 ein:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
∞
∞
1
0
3
E
1
3
∞
∞
0
Weiter geht es mit Knotenpaar (A, D). Auch hier ist bisher kein Weg bekannt. Gibt es einen Weg über Zwischenknoten B? Die Kosten von A nach B hatten wir eben bereits als 2 abgelesen. Von B nach D allerdings ist bisher kein Weg bekannt. Somit können wir auch keine Kosten für den Weg A→B→D bestimmen, und der Eintrag für Knotenpaar (A, D) bleibt unverändert (unendlich).
Genauso ergeht es uns mit Knotenpaar (A, E): Es gibt zwar nach wie vor den Weg A→B, aber keinen Weg B→E, somit auch keinen Weg A→B→E und damit keinen neuen Eintrag für Knotenpaar (A, E).
Wir kommen zu den Knotenpaaren (C, A), (C, D) und (C, E): Aktuell ist für alle drei Paare kein Weg bekannt. Es gibt einen Weg C→B mit Kosten von 7, aber von Zwischenknoten B weder einen Weg zu A, zu D oder zu E, somit also auch keine Wege C→B→A, C→B→D oder C→B→E. Die Einträge für die drei Knotenpaare bleiben daher unverändert (unendlich).
Knotenpaare (D, A), (D, C) und (D, E): Da es keinen Weg von Knoten D zu Zwischenknoten B gibt, können wir auch für diese drei Knotenpaare keine (oder keine kürzeren) Wege finden.
Knotenpaar (E, A): Es gibt zwar einen Weg von E nach B, aber keinen Weg von B nach A, somit auch keinen Weg E→B→A.
Bei Knotenpaar (E, C) kommt wieder etwas Schwung rein: Aktuell ist kein Weg bekannt. Gibt es einen Weg über B? Es gibt einen Weg E→B mit Kosten von 3 und einen Weg B→C mit Kosten von 6. Somit existiert ein Weg von E über B nach C mit Gesamtkosten von 9. Wir tragen die 9 in Zeile E, Spalte C ein:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
∞
∞
1
0
3
E
1
3
9
∞
0
Beachte, dass dies nicht heißt, dass der Weg von E nach C nur über Knoten B gehen muss. Denn der Weg von E nach B mit den Kosten 3 geht auch noch über den Knoten A (diesen hatten wir in Schritt 1 gefunden). Genau genommen haben wir jetzt also den Weg E→A→B→C gefunden:
Iteration 2: von E nach C über B (und damit auch über A)
Betrachten wir das letzte Knotenpaar in dieser Iteration, (E, D). Existiert ein Weg über Zwischenknoten B? Es existiert zwar ein Weg E→B mit Kosten 3, allerdings kein Weg B→D, somit also auch kein Weg E→B→D.
Die zweite Iteration ist beendet. Wir kennen nun für alle Knotenpaare die niedrigsten Kosten, wenn wir auch indirekte Wege über Knoten B – und damit auch indirekt über Knoten A – zulassen.
Iteration 3 – Indirekte Wege über Zwischenknoten C
Wir wiederholen das ganze: Jetzt vergleichen wir für alle Knotenpaare die eingetragenen Kosten mit denen über Zwischenknoten C. Die Kosten zu/von Knoten C, die wir wiederum aus der Matrix ablesen, können die des direkten Weges zu/von Knoten C sein, aber auch die in den vorherigen Iterationen bestimmten Kosten von indirekten Wegen via Knoten A und/oder B.
Wir beginnen mit Knotenpaar (A, B). Die Kosten von A nach Zwischenknoten C betragen 8 (diesen Weg hatten wir am Anfang der zweiten Iteration via B gefunden). Die Kosten von C nach B betragen 7. Der Weg über Zwischenknoten C hat also Gesamtkosten von 8 + 7 = 15. Dieser Weg ist deutlich länger als der aktuell hinterlegte mit Kosten von 2. Das ist in der Grafik auch gut zu erkennen: Der Weg A→B ist natürlich deutlich kürzer als A→B→C→B. Wir belassen den Eintrag für (A, B) also auf 2.
Knotenpaare (A, D) und (A, E): Die Kosten für A→C haben wir gerade abgelesen, es existieren allerdings keine Wege C→D bzw. C→E, somit also auch keine von A via C nach D bzw. von A via C nach E.
Knotenpaar (B, A), (B, D), (B, E): Die Kosten von B nach C betragen 6, von C existiert allerdings weder ein Pfad zu A, zu D oder zu E. Somit finden wir in dieser Iteration auch keinen der Wege B→C→A, B→C→D und B→C→E.
Knotenpaar (D, A): Es existiert ein Pfad von D nach C, allerdings keiner von C nach A, somit auch keiner von D via C nach A.
Für Knotenpaar (D, B) ist aktuell als Kosten unendlich hinterlegt, d. h. es ist noch kein Pfad bekannt. Das ändert sich jetzt: Es existiert der Pfad D→C mit Kosten 1 und der Pfad C→B mit Kosten 7. In Summe ergibt das 8:
Iteration 3: von D nach B über C
Wir tragen somit in Zeile D, Spalte B die 8 ein:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
∞
8
1
0
3
E
1
3
9
∞
0
Knotenpaar (D, E): Es ist kein Weg von Zwischenknoten C nach E bekannt, somit finden wir in dieser Iteration auch keinen Weg von D via C nach E.
Knotenpaare (E, A) und (E, D): Da keine Wege von Zwischenknoten C nach A bzw. nach D existieren, finden wir aktuell auch keinen Weg von E via C nach A bzw. von E via C nach D.
Knotenpaar (E, B): Die Kosten für den Weg E→C betragen 9, die Kosten für C→B betragen 7. In Summe also 16. Für den Weg E→B sind bereits Kosten von 3 hinterlegt. 16 ist deutlich schlechter, wir lassen also die 3 unverändert stehen.
Am Ende von Iteration 3 angekommen kennen wir die niedrigsten Kosten für alle Knotenpaare, wenn wir auch indirekte Wege über Knoten C – und damit auch über A und B – zulassen.
Iteration 4 – Indirekte Wege über Zwischenknoten D
Iteration 4 können wir abkürzen: Von keinem der Knoten gibt es einen Weg zu Zwischenknoten D. Somit werden wir für kein Knotenpaar einen Weg via D finden.
Iteration 5 – Indirekte Wege über Zwischenknoten E
In der letzten Iteration prüfen wir für alle Knotenpaare, ob wir einen kürzeren Weg über Zwischenknoten E finden.
Die Knotenpaare mit Startknoten A, B und C können wir schnell abhandeln: Von keinem dieser Knoten existiert ein Weg zu Zwischenknoten E, somit werden wir für keines dieser Knotenpaare einen Weg via E finden.
Knotenpaar (D, A): Die Kosten für den Pfad D→E betragen 3, die Kosten für E→A betragen 1. Es existiert also ein Weg von D via E nach A mit Gesamtkosten von 4:
Iteration 5: von D nach A via E
Wir tragen die 4 in Zeile D, Spalte A ein:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
4
8
1
0
3
E
1
3
9
∞
0
Knotenpaar (D, B): Die Kosten für den Pfad D→E betragen weiterhin 3, die Kosten für E→B betragen ebenfalls 3. Ergibt in Summe 6. Wir haben also einen Weg von D via E nach B gefunden mit Gesamtkosten von 6. Aktuell sind hier Gesamtkosten von 8 eingetragen. Wir ersetzen die 8 durch 6:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
4
6
1
0
3
E
1
3
9
∞
0
Auch dieser Fall ist wieder ein Beispiel dafür, dass der Weg via Zwischenknoten E nicht der direkte Weg D→E→B ist, sondern tatsächlich D→E→A→B, da der kürzeste Weg von E nach B über A geht (den Weg E→A→B hatten wir in der ersten Iteration gefunden):
Iteration 5: von D nach B via E (und A)
Das finale Knotenpaar ist (D, C): Die Kosten für den Pfad D→E betragen immer noch 3, die Kosten für E→C betragen 9. Ergibt in Summe 12. Dies ist schlechter als die für (D, C) aktuell hinterlegten Kosten von 1, die wir somit stehen lassen.
Wir haben das Ende der fünften Iteration erreicht und kennen nun die niedrigsten Kosten für alle Knotenpaare, wenn wir auch indirekte Wege über Knoten E (und damit auch über A, B, C, D) – also über beliebige anderen Knoten – zulassen.
Ein negativer Zyklus von einem beliebigen Knoten aus führt dazu, dass die Kosten von diesem Knoten zu sich selbst negativ sind. Der Floyd-Warshall-Algorithmus macht es uns sehr leicht das zu erkennen. Die Kosten aller Knoten zu sich selbst lassen sich an der Matrix-Diagonalen direkt ablesen. Hier noch einmal die Matrix aus dem Beispiel von oben nach Durchlauf aller Iterationen:
von / nach
A
B
C
D
E
A
0
2
8
∞
∞
B
∞
0
6
∞
∞
C
∞
7
0
∞
∞
D
4
6
1
0
3
E
1
3
9
∞
0
In der Diagonalen (fett hervorgehoben) befinden sich ausschließlich Nullen. Das heißt: Es existiert kein negativer Zyklus.
Sollte sich in wenigstens einem Feld auf der Diagonalen eine negative Zahl befinden, wäre ein negativer Zyklus erkannt. Der Algorithmus würde dann mit einer Fehlermeldung terminieren.
Floyd-Warshall-Algorithmus – Bestimmung der kürzesten Pfade
In der oben beschriebenen Grundform berechnet der Floyd-Warshall-Algorithmus nur die Kosten der kürzesten Pfade zwischen zwei Knoten, nicht jedoch die Pfade selbst (d. h. über welche Zwischenknoten der kürzeste Pfad führt).
Man kann den Algorithmus jedoch relativ einfach erweitern, so dass die Bestimmung des kürzesten Pfades zwischen zwei Knoten leicht möglich ist.
Dazu benötigen wir eine zweite Matrix der Größe n × n, die sogenannte „Nachfolgermatrix“. Hier tragen wir für jedes Knotenpaar (i, j) initial den jeweiligen Endknoten j ein. Das bedeutet, dass der Weg von i nach j initial über den Nachfolger j führt.
Sobald wir für ein beliebiges Paar (i, j) einen kürzeren Weg über Zwischenknoten k finden, tragen wir in der Matrix an Position (i, j) den aktuellen Wert der Matrix von Position (i, k) ein. Das bedeutet, dass der Weg von i nach j nun über denselben Nachfolger führt wie der Weg von i nach k. Der Nachfolger kann k selbst sein, aber auch ein weiterer Zwischenknoten auf dem kürzesten Weg zu k.
Im Beispiel oben würden wir die Nachfolgermatrix initial wie folgt befüllen:
von / nach
A
B
C
D
E
A
–
B
–
–
–
B
–
–
C
–
–
C
–
B
–
–
–
D
–
–
C
–
E
E
A
B
–
–
–
In Iteration 1 finden wir von E nach B einen kürzeren Weg über A. Der Nachfolger von E auf dem Weg zu A (Zeile E, Spalte A) ist A; somit tragen wir A auch als Nachfolger von E auf dem Weg nach B (Zeile E, Spalte B) ein:
von / nach
A
B
C
D
E
A
–
B
–
–
–
B
–
–
C
–
–
C
–
B
–
–
–
D
–
–
C
–
E
E
A
A
–
–
–
Versuche gerne einmal selbst (als Übung) die Matrix über alle fünf Iterationen zu aktualisieren.
Am Ende sollte sie wie folgt aussehen (alle Änderungen sind fett markiert):
von / nach
A
B
C
D
E
A
–
B
B
–
–
B
–
–
C
–
–
C
–
B
–
–
–
D
E
E
C
–
E
E
A
A
A
–
–
Wie können wir daraus kürzeste Wege ablesen?
Nehmen wir den Weg von D nach B, den wir in der fünften Iteration berechnet hatten.
Wir lesen Schritt für Schritt aus der Matrix ab:
Zeile D, Spalte B: Der direkte Nachfolger von D auf dem Weg zu B ist: E
Zeile E, Spalte B: Der direkte Nachfolger von E auf dem Weg zu B ist: A
Zeile A, Spalte B: Der direkte Nachfolger von A auf dem Weg zu B ist: B (Zielknoten erreicht)
Der vollständige kürzeste Weg lautet also D→E→A→B.
Hier noch einmal zum Vergleich die Grafik aus der fünften Iteration:
Kürzester Weg von D nach B: D→E→A→B
Der aus der Nachfolgermatrix abgelesene Pfad stimmt mit dem eingezeichneten Pfad überein.
Die informelle Beschreibung – und auch der Code (dieser folgt im nächsten Kapitel) – sind überraschend einfach. Die Schritte für das Bestimmen der vollständigen Wege sind als optional gekennzeichnet. Um die zwei Matrizen nicht zu verwechseln, bezeichne ich sie im Folgenden als Kostenmatrix und Nachfolgermatrix.
Vorbereitung:
Erstelle die Kostenmatrix der Größe n × n (n ist die Anzahl der Knoten).
Trage für jedes Knotenpaar (i, j) die Kosten des direkten Pfades von i nach j ein, falls dieser existiert; trage ansonsten unendlich ein.
Trage auf der Diagonalen Nullen ein.
Optionale Vorbereitung: Erstellung der Nachfolgermatrix
Erstelle die Nachfolgermatrix der Größe n × n.
Trage für jedes Knotenpaar (i, j) den Wert j ein.
Führe folgende Iteration n mal aus; k sei dabei der Schleifenzähler und stehe für den Zwischenknoten:
Für jedes Knotenpaar (i, j):
Berechne die Summe der Kosten des Weges i→k (abzulesen in Zeile i, Spalte k der Kostenmatrix) und der Kosten des Weges k→j (abzulesen in Zeile k, Spalte j der Kostenmatrix).
Ist die Summe kleiner als die Kosten des Weges i→j (abzulesen in Zeile i, Spalte j der Kostenmatrix), dann
trage die neuen, niedrigeren Kosten in Zeile i, Spalte j der Kostenmatrix ein;
(optional) kopiere in der Nachfolgermatrix den Wert aus Feld (i, k) ins Feld (i, j).
Prüfe abschließend, ob auf der Diagonalen der Kostenmatrix eine negative Zahl vorkommt. Wenn ja, beende den Algorithmus mit der Fehlermeldung „Negativer Zyklus erkannt“. Ansonsten ist der Algorithmus erfolgreich durchgelaufen.
Wie auch in den vorangegangenen Teilen der Serie verwenden wir den MutableValueGraph aus den Google Core Libraries for Java (Guava). Im folgenden Code-Ausschnitt siehst du, wie man den gerichteten Graphen aus dem Beispiel oben erstellt (Methode TestWithSampleGraph.createSampleGraph()):
Typ der Knoten: wir verwenden hier String für die Knotennamen „A“ bis „E“.
Typ der Kantengewichte: für das Beispiel verwenden wir Integer.
In der putEdgeValue()-Methode wird zuerst der Startknoten angegeben, gefolgt vom Zielknoten und dem Kantengewicht.
Datenstruktur für die Kosten- und Nachfolgermatrix
Als Datenstruktur für die Matrizen bieten sich zweidimensionale Arrays an:
int n = graph.nodes().size();
int[][] costs = newint[n][n];
int[][] successors = newint[n][n];Code-Sprache:Java(java)
Da unser Algorithmus am Ende beide Matrizen zurückgeben soll, kapseln wir beide in der Klasse FloydWarshallMatrices. Im Repository siehst du, dass diese Klasse auch eine print()-Methode hat, mit der wir zum Test die Matrizen auf der Konsole ausgeben können.
Indizierung der Knoten im Graphen
Die Zeilen und Spalten der zweidimensionalen Arrays werden mit Index 0 bis n-1 adressiert. Unsere Knoten werden allerdings durch Namen identifiziert, nicht durch Zahlen. Wir benötigen also eine Abbildungsvorschrift zwischen Index und Knotenname.
Die Methode graph.nodes() liefert ein Set der Knoten, also eine nicht indizierbare Datenstruktur.
Wir können das Set jedoch sehr einfach in ein Array konvertieren:
Mittels nodes[i] können wir nun für die Zeile oder Spalte i den zugehörigen Knotennamen bestimmen.
Vorbereitung: Füllen der Matrizen
Die Matrizen füllen wir initial wie folgt (Methode FloydWarshall.findShortestPaths()). Die Variable m steht hier für die Instanz des FloydWarshallMatrices-Klasse, die die zwei Matrizen enthält.
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
Optional<Integer> edgeValue = graph.edgeValue(nodes[i], nodes[j]);
m.costs[i][j] = i == j ? 0 : edgeValue.orElse(Integer.MAX_VALUE);
m.successors[i][j] = edgeValue.isPresent() ? j : -1;
}
}Code-Sprache:Java(java)
In der Kostenmatrix verwenden wir Integer.MAX_VALUE als Repräsentation für unendlich. Das funktioniert natürlich nur, solange wir mit den Kosten nicht in die Nähe dieses Wertes (231-1) kommen. Für die Demonstration des Algorithmus ist es eine ausreichende Abstraktion.
In der Nachfolgermatrix tragen wir -1 ein, wenn es für ein Knotenpaar keinen Pfad gibt.
Wir könnten bei beiden Matrizen auch mit Integer-Objekten und null-Werten arbeiten oder gar mit Optional<Integer>, das wäre allerdings weniger performant.
Iterationen
Für die Iterationen verschalteln wir drei Schleifen ineinander:
Die äußere, mit Schleifenzähler k, iteriert über die Zwischenknoten.
Die zwei inneren, mit Schleifenzählern i und j, iterieren über alle Knotenpaare.
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
int costViaNodeK = addCosts(m.costs[i][k], m.costs[k][j]);
if (costViaNodeK < m.costs[i][j]) {
m.costs[i][j] = costViaNodeK;
m.successors[i][j] = m.successors[i][k];
}
}
}
}Code-Sprache:Java(java)
Innerhalb der Schleifen addieren wir die Kosten der Wege i→k und k→j und vergleichen die Summe mit den Kosten des Weges i→j. Ist die Summe über Zwischenknoten k kleiner, dann setzen wir die Kosten für den Weg i→j auf die neu berechneten, geringeren Kosten, und wir setzen als Nachfolgerknoten für den Weg i→j den Nachfolgerknoten des Weges i→k.
Die Methode addCosts() liefert unendlich (in Form von Integer.MAX_VALUE) zurück, wenn einer der beiden Summanden unendlich ist:
privatestaticintaddCosts(int a, int b){
if (a == Integer.MAX_VALUE || b == Integer.MAX_VALUE) {
return Integer.MAX_VALUE;
}
return a + b;
}Code-Sprache:Java(java)
Erkennung von negativen Zyklen
Nach Durchlauf der Iterationen prüfen wir auf negative Zyklen:
for (int i = 0; i < n; i++) {
if (m.costs[i][i] < 0) {
thrownew IllegalArgumentException("Graph has a negative cycle");
}
}Code-Sprache:Java(java)
Am Ende liefert die findShortestPaths()-Methode die FloydWarshallMatrices-Instanz m zurück.
Bestimmung des kürzesten Pfades zwischen zwei Knoten
Die Berechnung des kürzesten Pfades von einem Knoten zu einem anderen habe ich in der Methode FloydWarshallMatrices.getPath() implementiert. i und j sind dabei die Indizes von Start- und Endknoten:
if (successors[i][j] == -1) {
return Optional.empty();
}
List<String> path = new ArrayList<>();
path.add(nodes[i]);
while (i != j) {
i = successors[i][j];
path.add(nodes[i]);
}
return Optional.of(List.copyOf(path));Code-Sprache:Java(java)
Zuerst wird geprüft, ob successors[i][j] gleich -1 ist. Wenn das der Fall ist, existiert kein Pfad von i nach j, und die Methode gibt ein leeres Optional zurück.
Ansonsten wird eine Liste path angelegt und mit dem Ausgangsknoten und dann – nach und nach – mit den Folgeknoten des Weges befüllt. Schließlich wird eine nicht modifizierbare Kopie der Liste (Stichwort „defensive copy“) zurückgeliefert.
Aufruf der findShortestPaths()-Methode
Folgende drei Beispiele im Repository zeigen den Aufruf der findShortestPaths()-Methode:
TestWithSampleGraph: In diesem Test werden die kürzesten Pfade des Beispielgraphen aus diesem Artikel berechnet.
Die Zeitkomplexität des Floyd-Warshall-Algorithmus ist schnell bestimmt. Wir haben drei ineinander geschachtelte Schleifen, die jeweils n Durchläufe zählen. In der innersten Schleife haben wir einen Vergleich, der mit konstantem Aufwand durchführbar ist. Der Vergleich wird also n × n × n mal – oder n³ mal – ausgeführt.
Die Zeitkomplexität von Floyd-Warshall beträgt somit: O(n³)
Laufzeit des Floyd-Warshall-Algorithmus
Mit dem Programm TestFloydWarshallRuntime können wir prüfen, ob die Laufzeit des Algorithmus zur hergeleiteten Zeitkomplexität O(n³) passt. Das Programm erstellt zufällige Graphen verschiedener Größen und berechnet darin die kürzesten Pfade. Das Programm wiederholt jeden Test 50 mal und gibt den Median aller Messwerte aus.
Das folgende Diagramm zeigt die Laufzeit in Abhängigkeit von der Größe des Graphen:
Zeitkomplexität des Floyd-Warshall-Algorithmus
Das kubische Wachstum ist gut zu erkennen: Bei Verdopplung der Anzahl der Knoten (z. B. von 1.000 auf 2.000) verachtfacht sich die benötigte Zeit (von 700 ms auf etwa 6 s).
Floyd-Warshall vs. Bellman-Ford vs. Dijkstra
Im folgenden Diagramm habe ich die Laufzeiten von Floyd-Warshall, Bellman-Ford (optimiert und nicht optimiert) und Dijkstra (mit Fibonacci Heap) gegenübergestellt:
Zeitkomplexität Floyd-Warshall-Algorithmus vs. Bellman-Ford vs. Dijkstra
Floyd-Warshall ist, wie aufgrund der Zeitkomplexität zu erwarten war, noch einmal langsamer als Bellman-Ford.
Wann sollte also welcher Algorithmus eingesetzt werden?
Floyd-Warshall sollte nur dann eingesetzt werden, wenn die kürzesten Wege zwischen allen Knotenpaaren gesucht werden.
Bellman-Ford sollte eingesetzt werden, wenn der Graph negative Kantengewichte enthält.
A* sollte eingesetzt werden, wenn der Graph keine negativen Kantengewichte enthält und sich eine Heuristik definieren lässt.
Ohne negative Kantengewichte und ohne Heuristik sollte Dijkstras Algorithmus eingesetzt werden.
Zusammenfassung
Dieser Artikel hat dir gezeigt, wann man den Floyd-Warshall-Algorithmus einsetzt (wenn man die kürzesten Entfernungen zwischen allen Knotenpaaren benötigt), wie er funktioniert und wie er negative Zyklen identifiziert.
Die Zeitkomplexität ist mit O(n³) deutlich schlechter als die aller bisher vorgestellten Pathfinding-Algorithmen. Floyd-Warshall sollte daher wirklich nur für den vorgesehenen Einsatzzweck verwendet werden.
Damit endet die Serie über Pathfinding-Algorithmen. Hast du Fragen oder Anregungen? Dann hinterlasse mir gerne einen Kommentar.
In den ersten zwei Teilen dieser Serie über Shortest-Path-Algorithmen hast du den Dijkstra- und den A*-Algorithmus kennengelernt.
Beide Algorithmen sind nur auf Graphen anwendbar, die keine negativen Kantengewichte haben. Was das bedeutet – und wie der Bellman-Ford-Algorithmus damit umgeht, erfährst du in diesem Artikel.
Folgende Fragen werden geklärt:
Was bedeutet „negatives Kantengewicht“?
Wo kommen negative Kantengewichte in der Praxis vor?
Warum sind Dijkstra und A* bei negativen Kantengewichten nicht anwendbar?
Wie funktioniert der Bellman-Ford-Algorithmus (Schritt für Schritt an einem Beispiel erklärt)?
Was ist ein „negativer Zyklus“, und wie geht man damit um?
Wie implementiert man den Bellman-Ford-Algorithmus in Java?
Wie bestimmt man die Zeitkomplexität des Bellman-Ford-Algorithmus?
Den Quellcode der gesamten Artikelserie über Pathfinding-Algorithmen findest du in diesem GitHub-Repository.
Was ist ein negatives Kantengewicht?
In den vorangegangenen Teilen habe ich beispielhaft gezeigt, wie eine Straßenkarte auf einen gewichteten Graphen abgebildet wird:
Pathfinding: Abbildung einer Straßenkarte auf einen kantengewichteten Graphen
In diesem Graphen geben die Gewichte (die Zahlen an den Kanten) an, wie hoch die Kosten für einen bestimmten Pfad sind. Dies kann beispielsweise die Zeit in Minuten sein, die man für das Zurücklegen dieses Weges mit einem bestimmten Fortbewegungsmittel benötigt.
Der Graph ist ein mathematisches Modell, und in der Mathematik können Zahlen auch negativ sein. Steht an einer Kante im Graph eine Zahl kleiner als Null, dann sprechen wir demzufolge von einem negativen Kantengewicht.
Beispiel für negative Kantengewichte
Hier ein Beispiel:
Graph mit negativen Kantengewichten
In diesem Beispiel hat der Pfad von E nach B ein negatives Kantengewicht von -3, und der Pfad von C nach F hat ein negatives Kantengewicht von -2.
Dieser Graph unterscheidet sich von den vorherigen nicht nur durch die negativen Kantengewichte, sondern auch durch die Pfeile. Diese geben die Richtungen an, in denen man den Pfaden folgen kann.
Gerichtete Kanten in einem gerichteten Graph
Wir sprechen hier von gerichteten Kanten. Ein Graph, der gerichtete Kanten enthält, ist ein gerichteter Graph.
In einem gerichteten Graphen können wir – im Gegensatz zum ungerichteten Graphen – auch Pfade darstellen, die nur in einer Richtung verlaufen (z. B. von Knoten A nach B oder von Knoten E nach F) – sowie Verbindungen, deren Gewicht je nach Richtung unterschiedlich ist (z. B. zwischen Knoten A und D und zwischen C und F).
Für beides gibt es naheliegende Anwendungsbeispiele:
Verbindung in nur einer Richtung: Einbahnstraßen.
Verbindung mit unterschiedlichen Gewichten je Richtung: Straßen, die in einer Richtung zweispurig sind und in der anderen einspurig. Oder Autobahnen, auf der in einer Richtung ein Stau herrscht, auf der anderen aber freie Fahrt.
Aber negative Kantengewichte?
Wo kommen negative Kantengewichte in der Praxis vor?
Ein Graph mit negativen Kantengewichten erscheint auf den ersten Blick wie ein realitätsfernes, mathematisches Modell. Schließlich kann die benötigte Zeit für einen Weg ja nicht negativ sein.
Die Zeit nicht – aber die Kosten!
Stell dir vor, unser Fahrzeug ist ein Elektroauto. In einem Straßennetz mit Steigungen und Gefällen soll eine Route von A nach B gefunden werden, auf dem das Fahrzeug am wenigsten Energie verbraucht.
Auf einem Gefälle kann das E-Auto seine Batterie aufladen. Und die dabei zurückgewonnene Energie können wir durch negative Kantengewichte repräsentieren.
Warum sind Dijkstra und A* bei negativen Kantengewichten nicht anwendbar?
Bei Dijkstras und dem A*-Algorithmus werden die Knoten der Reihe nach abgearbeitet. Wenn ein Knoten abgearbeitet wurde, wird er nicht weiter betrachtet.
Negative Kantengewichte könnten allerdings dazu führen, dass die Gesamtkosten vom Start zu einem bereits abgearbeiteten Knoten reduziert werden. Die reduzierten Gesamtkosten würden ignoriert und eine evtl. kürzere Route nicht gefunden werden.
Des weiteren: Wenn die Gesamtkosten vom Start zu einem bestimmten Knoten höher sind als die einer bereits gefundenen Route zum Ziel, dann betrachten Dijkstra und A* die von diesem Knoten ausgehenden Wege nicht weiter.
Sollte ein solcher Weg ein negatives Kantengewicht haben, wäre es jedoch möglich, dass dieser Weg mit geringeren Gesamtkosten zum Ziel führt (da die Kosten durch das negative Gewicht ja wieder reduziert werden).
Schauen wir uns das am Beispiel von oben an. Es soll die kürzeste Route von A nach F gesucht werden.
Dijkstra würde zunächst folgende zwei (noch unvollständige) Wege finden:
A→B→C mit Gesamtkosten vom Start von 4+5 = 9
A→D→E mit Gesamtkosten vom Start von 3+3 = 6
Einsatz von Dijkstras Algorithmus bei negativen Kantengewichten – vorletzter Schritt
Dijkstra würde als nächstes Knoten E untersuchen (da 6 kleiner ist als 9) und von hier aus einen Weg zu B mit Gesamtkosten von 3+3+(-3) = 3 finden. Dieser Weg ist kürzer als der bisher gefundene (4 via A). Da B bereits abgearbeitet ist, würde diese Änderung wirkungslos sein.
Des weiteren würde Dijkstra einen Weg von E zum Zielknoten F entdecken mit Gesamtkosten von 3+3+2 = 8:
Einsatz von Dijkstras Algorithmus bei negativen Kantengewichten – letzter Schritt
Da bei Knoten C bereits Gesamtkosten in Höhe von 9 aufgelaufen sind, würde Dijkstra die von C ausgehenden Wege nicht weiter prüfen und die Suche beenden.
Was Dijkstra übersehen würde: Durch das negative Gewicht von C nach F würden sich die Gesamtkosten des Weges A→B→C→F auf 4+5+(-2) = 7 reduzieren.
Und die Gesamtkosten des Weges A→D→E→B→C→F liegen sogar noch niedriger bei 3+3+(-3)+5+(-2) = 6.
Dijkstras Algorithmus hätte bei diesem Beispiel also nicht den kürzesten, sondern nur den drittkürzesten Weg gefunden.
Für den A*-Algorithmus gilt ähnliches, wobei es bei der Existenz negativer Kantengewichte ohnehin schwer fallen dürfte eine sinnvolle Heuristik-Funktion zu definieren.
Wie funktioniert der Bellman-Ford-Algorithmus?
Der Bellman-Ford-Algorithmus ähnelt dem von Dijkstra stark. Der Unterschied ist, dass wir bei Bellman-Ford die Knoten nicht priorisieren, sondern dass wir in jeder Iteration allen Kanten des Graphen folgen und die Gesamtkosten vom Start im Kanten-Zielknoten aktualisieren, wenn diese eine Verbesserung gegenüber des aktuellen Zustands darstellen.
Ich erkläre den Algorithmus in den folgenden Abschnitten am oben vorgestellten Graphen Schritt für Schritt.
Vorbereitung – Tabelle der Knoten
Wir beginnen – genau wie bei Dijkstra – mit dem Erstellen einer Tabelle aller Knoten mit dem jeweiligen Vorgänger-Knoten und den Gesamtkosten vom Startknoten. Die Vorgänger-Spalte lassen wir leer, und als Gesamtkosten tragen wir beim Startknoten 0 ein und bei allen anderen Knoten unendlich (∞):
Knoten
Vorgänger
Gesamtkosten vom Start
A
–
0
B
–
∞
C
–
∞
D
–
∞
E
–
∞
F
–
∞
Im folgenden ist es wichtig die Begriffe Kosten und Gesamtkosten zu differenzieren:
Kosten bezeichnet die Kosten von einem Knoten zu einem Nachbarknoten.
Gesamtkosten bezeichnet die Summe aller Teilkosten vom Startknoten über eventuelle Zwischenknoten zu einem bestimmten Knoten.
Bellman-Ford-Algorithmus – Schritt für Schritt
Die folgenden Ausschnitte des Graphen zeigen zu jedem Knoten den jeweiligen Vorgängerknoten (wenn vorhanden) und die Gesamtkosten vom Start mit an. Diese Daten sind in der Regel nicht im Graph enthalten, sondern nur in der zuvor angelegten, separaten Tabelle. Ich zeige sie hier der Übersicht halber mit an.
Wir führen nun n-1 mal (n ist die Anzahl der Knoten) die folgende Iteration durch. Wir haben sechs Knoten, also fünf Iterationen.
Iteration 1 von 5
In jeder Iteration betrachten wir alle Kanten des Graphen. Die Kanten werden mit zwei Kleinbuchstaben in Klammern gekennzeichnet. Die Kante von Knoten A nach B beispielsweise mit (a, b).
Da weder Kanten noch Knoten priorisiert sind, betrachten wir die Kanten in alphabetischer Reihenfolge. Wir beginnen also mit Kante (a, b):
Kante (a, b)
Iteration 1, Kante (a, b)
Wir berechnen die Summe aus Gesamtkosten vom Start zu A (diese betragen 0, da A selbst der Startknoten ist) und den Kosten der betrachteten Kante (a, b):
Kante (a, b)
0 (Gesamtkosten vom Start zu A) + 4 (Kosten A→B) = 4
Die Gesamtkosten für B sind aktuell noch unendlich. Das bedeutet, dass noch keine Route zu B gefunden wurde. Soeben haben wir eine Route entdeckt und tragen daher bei Knoten B als Vorgänger den Knoten A ein und als Gesamtkosten vom Start die eben berechnete Summe 4:
Gesamtkosten und Vorgänger von Knoten B wurden aktualisiert
Kante (a, d)
Wir betrachten als nächstes die Kante (a, d):
Iteration 1, Kante (a, d)
Wir berechnen die Gesamtkosten zu D:
Kante (a, d)
0 (Gesamtkosten vom Start zu A) + 3 (Kosten A→D) = 3
Da auch die Gesamtkosten bei D noch unendlich sind, tragen wir dort als Gesamtkosten 3 und als Vorgänger A ein:
Gesamtkosten und Vorgänger von Knoten D wurden aktualisiert
Von Knoten A führt keine weitere Kante weg. Fahren wir mit den Kanten fort, die von Knoten B aus fortführen.
Kante (b, c)
Wir betrachten Kante (b, c):
Iteration 1, Kante (b, c)
Wir berechnen die neue Gesamtkosten für Knoten C:
Kante (b, c)
4 (Gesamtkosten vom Start zu B) + 5 (Kosten B→C) = 9
Auch C hat noch Gesamtkosten von unendlich; wir tragen als neue Gesamtkosten bei Knoten C eine 9 ein und als Vorgänger Knoten B:
Gesamtkosten und Vorgänger von Knoten C wurden aktualisiert
Kante (b, e)
Die nächste Kante in alphabetischer Reihenfolge ist Kante (b, e):
Iteration 1, Kante (b, e)
Wir rechnen:
Kante (b, e)
4 (Gesamtkosten vom Start zu B) + 4 (Kosten B→E) = 8
Und wir aktualisieren Knoten E:
Gesamtkosten und Vorgänger von Knoten E wurden aktualisiert
Kante (c, b)
Als nächstes kommen wir zu Kante (c, b). Dass wir die entgegengesetzte Kante (b, c) bereits betrachtet haben, ist an dieser Stelle irrelevant.
Iteration 1, Kante (c, b)
Wir sehen natürlich sofort intuitiv, dass es keinen Sinn macht, diesen Weg wieder zurückzulaufen. Damit der Algorithmus dies auch sieht, muss er diesen Pfad dennoch überprüfen. Wir berechnen also die Gesamtkosten für Knoten B, wenn wir diesen über die Kante (c, b) erreichen würden:
Kante (c, b)
9 (Gesamtkosten vom Start zu C) + 5 (Kosten C→B) = 14
Wir könnten Knoten B von C aus also mit Gesamtkosten von 14 erreichen. Wir haben aber bereits eine Route zu B mit Gesamtkosten von nur 4 gefunden. Den neu gefundenen Weg ignorieren wir daher und fahren stattdessen mit der nächsten Kante fort.
Kante (c, f)
Wir betrachten die erste Kante mit einem negativen Gewicht, Kante (c, f):
Iteration 1, Kante (c, f)
Wir berechnen die neuen Gesamtkosten für F:
Kante (c, f)
9 (Gesamtkosten vom Start zu C) – 2 (Kosten C→F) = 7
Wir aktualisieren Gesamtkosten und Vorgänger in Knoten F:
Gesamtkosten und Vorgänger von Knoten F wurden aktualisiert
Wir haben die erste Route zum Ziel gefunden. Da es bei Bellman-Ford keine Priorisierung gibt, könnte dieser Weg der kürzeste sein, der längste, oder irgendeiner dazwischen. Wir müssen daher mit der Abarbeitung der Kanten fortfahren.
Kante (d, a)
Iteration 1, Kante (d, a)
Wir berechnen die Gesamtkosten für A über D:
Kante (d, a)
3 (Gesamtkosten vom Start zu D) + 4 (Kosten D→A) = 7
Die neu berechneten Gesamtkosten (7) sind höher als die bei A bereits hinterlegten (0). Der Weg über D zu A ist also nicht kürzer als der bereits bekannte und wird somit nicht weiter beachtet.
Kante (d, e)
Iteration 1, Kante (d, e)
Wir berechnen die Gesamtkosten für E über D:
Kante (d, e)
3 (Gesamtkosten vom Start zu D) + 3 (Kosten D→E) = 6
Die neu berechneten Gesamtkosten (6) sind niedriger als die bei Knoten E hinterlegten (8). Wir haben also einen kürzeren Weg zu E entdeckt. Wir reduzieren daher die Gesamtkosten in Knoten E von 8 auf 6 und ersetzen Vorgänger B durch D:
Gesamtkosten und Vorgänger von Knoten E wurden aktualisiert
Kante (e, b)
Iteration 1, Kante (e, b)
Wir berechnen die Gesamtkosten über E zu B:
Kante (e, b)
6 (Gesamtkosten vom Start zu E) – 3 (Kosten E→B) = 3
Auch hier sind die neu berechneten Gesamtkosten zu B (3) niedriger als die aktuell hinterlegten (4). Wir haben also auch zu B einen kürzeren Weg gefunden. Wir aktualisieren Vorgänger und Gesamtkosten in Knoten B:
Gesamtkosten und Vorgänger von Knoten B wurden aktualisiert
Kante (e, f)
Mit der Kante (e, f) betrachten wir die zweite Kante, die zum Zielknoten F führt:
Iteration 1, Kante (e, f)
Wir berechnen:
Kante (e, f)
6 (Gesamtkosten vom Start zu E) + 2 (Kosten E→F) = 8
Wir haben eine weitere Route zum Zielknoten F über Knoten E gefunden. Dieser Weg ist mit Gesamtkosten von 8 jedoch länger als der bisherige (7). Somit ignorieren wir ihn.
Kante (f, c)
Als letztes betrachten wir die Kante (f, c):
Iteration 1, Kante (f, c)
Wir berechnen:
Kante (f, c)
7 (Gesamtkosten vom Start zu F) + 4 (Kosten F→C) = 11
Die neu berechneten Gesamtkosten (11) für Knoten C sind niedriger als die hinterlegten (9). Wir ignorieren also auch diese letzte Kante.
Ende der ersten Iteration
Wir haben nun alle Kanten des Graphen genau einmal betrachtet und eine Route mit Gesamtkosten von 7 zum Ziel gefunden. Mit der Kante (e, b) haben wir allerdings auch die Kosten von Knoten B, dessen ausgehende Kanten wir zuvor schon bearbeitet hatten, noch einmal verringert.
Dies könnte dazu führen, dass wir einen noch kürzeren Weg zum Ziel finden. Wir wiederholen daher die gesamte Iteration.
Der Übersicht halber habe ich während der ersten Iteration die Änderungen von Gesamtkosten und Vorgängern direkt im Graphen notiert. Tatsächlich werden diese Änderungen in die zuvor angelegte Tabelle eingetragen. Diese sieht am Ende der Iteration wie folgt aus:
Knoten
Vorgänger
Gesamtkosten vom Start
A
–
0
B
E
3
C
B
9
D
A
3
E
D
6
F
C
7
Der Graph sieht aktuell so aus:
Gesamtkosten und Vorgänger am Ende von Iteration 1
Iteration 2 von 5
In der zweiten Iteration betrachten wir erneut alle Kanten des Graphen und führen die gleichen Berechnungen durch wie in der ersten Iteration. Ich werde die Schritte daher etwas weniger detailreich beschreiben.
Kanten (a, b) und (a, d)
Kante (a, b)
0 (Gesamtkosten vom Start zu A) + 4 (Kosten A→B) = 4
Kante (a, d)
0 (Gesamtkosten vom Start zu A) + 3 (Kosten A→D) = 3
Da sich in der vorangegangenen Iteration die Gesamtkosten von Knoten A nicht geändert haben, sind die Berechnungen für die von Knoten A wegführenden Kanten gleich geblieben. Es ergeben sich keine niedrigeren Gesamtkosten für die Knoten B und D.
Kante (b, c)
Knoten B ist derjenige, dessen Gesamtkosten wir in der ersten Iteration von 4 auf 3 reduziert haben, nachdem wir alle von ihm ausgehenden Kanten bereits betrachtet hatten. Daher schauen wir uns diese Kante noch einmal detailliert an:
Iteration 2, Kante (b, c)
Wir berechnen:
Kante (b, c)
3 (Gesamtkosten vom Start zu B) + 5 (Kosten B→C) = 8
Die neu berechneten Gesamtkosten (8) sind niedriger als die hinterlegten (9). Das war zu erwarten, da wir ja die Gesamtkosten von B um 1 reduziert haben, nachdem wir die Gesamtkosten von C über B schon berechnet hatten.
Wir aktualisieren die Gesamtkosten in Knoten C; der Vorgänger bleibt unverändert:
Gesamtkosten von Knoten C wurden aktualisiert
Kanten (b, e) und (c, b)
Die nächsten zwei Kanten können wir wieder im Schnellverfahren abhandeln:
Kante (b, e)
3 (Gesamtkosten vom Start zu B) + 4 (Kosten B→E) = 7
Kante (c, b)
8 (Gesamtkosten vom Start zu C) + 5 (Kosten C→B) = 13
In beiden Fällen ergeben sich für den Kanten-Endknoten höhere Gesamtkosten als aktuell hinterlegt sind (6 bei E und 3 bei B). Wir haben also keine kürzeren Wege gefunden und ignorieren diese zwei Kanten.
Kante (c, f)
Da wir das Gesamtgewicht von Knoten C eben verändet haben, betrachten wir auch diese Kante noch einmal genauer:
Iteration 2, Kante (c, f)
Wir berechnen:
Kante (c, f)
8 (Gesamtkosten vom Start zu C) – 2 (Kosten C→F) = 6
Die Gesamtkosten sind niedriger als die hinterlegten. Wir haben also einen kürzeren Weg gefunden und aktualisieren die Gesamtkosten in Knoten F von 7 auf 6:
Gesamtkosten von Knoten F wurden aktualisiert
Kanten (d, a), (d, e), (e, b), (e, f) und (f, c)
Auch die verbleibenden fünf Kanten können wir schnell erledigen:
Kante (d, a)
3 (Gesamtkosten vom Start zu D) + 4 (Kosten D→A) = 7
Kante (d, e)
3 (Gesamtkosten vom Start zu D) + 3 (Kosten D→E) = 6
Kante (e, b)
6 (Gesamtkosten vom Start zu E) – 3 (Kosten E→B) = 3
Kante (e, f)
6 (Gesamtkosten vom Start zu E) + 2 (Kosten E→F) = 8
Kante (f, c)
6 (Gesamtkosten vom Start zu F) + 4 (Kosten F→C) = 10
In allen fünf Fällen sind die neu berechneten Gesamtkosten für den Kanten-Endknoten größer oder gleich den aktuellen Werten. Somit gibt es keine weiteren Änderungen.
Ende der zweiten Iteration
Wir haben nun ein zweites Mal alle Kanten betrachtet. Bei zwei Knoten (C und F) hat dies zur Reduzierung der Gesamtkosten geführt. Und wir haben einen kürzeren Weg zum Ziel gefunden als in der ersten Iteration.
Die Tabelle sieht aktuell so aus:
Knoten
Vorgänger
Gesamtkosten vom Start
A
–
0
B
E
3
C
B
8
D
A
3
E
D
6
F
C
6
Und noch einmal die Gesamtkosten und Vorgänger im Graphen:
Gesamtkosten und Vorgänger am Ende von Iteration 2
Um zu prüfen, ob wir ein weiteres mal Gesamtkosten reduzieren können, führen wir eine dritte Iteration durch.
Iteration 3 von 5
Ich mache es kurz: Nach der dritten Prüfung aller Kanten wird der Algorithmus keine weiteren Kostenreduktionen festgestellt haben.
In der Originalvariante würde der Algorithmus noch eine vierte und fünfte Iteration durchführen. Doch wenn in einer Iteration keine kürzeren Wege gefunden werden können, dann ändert sich die Ausgangssituation nicht für die Folgeiteration. Demzufolge können auch in der Folgeiteration (und allen weiteren) keine kürzeren Routen mehr gefunden werden.
Eine entsprechend optimierte Variante des Algorithmus wird daher am Ende von Iteration 3 vorzeitig terminieren.
Backtrace zur Bestimmung des vollständigen Weges
Wir können nun aus der Tabelle oder dem Graphen direkt ablesen, dass der kürzeste Weg zu F über Knoten C führt und dass die Gesamtkosten 6 betragen. Doch wie lautet der vollständige Pfad?
Diesen ermitteln wir mit Hilfe des sogenannten „Backtrace“: Wir folgen den Knoten – Vorgänger für Vorgänger – vom Ziel zum Start:
Backtrace zur Bestimmung des vollständigen Pfades
Der Vorgänger von F ist C; der Vorgänger von C ist B; der Vorgänger von B lautet E; der Vorgänger von E ist D, und der Vorgänger von D ist der Startknoten A. Der gesamte Pfad lautet also: A→D→E→B→C→F
Kürzeste Wege zu allen Knoten finden
Tatsächlich können wir nicht nur den kürzesten Pfad zum Zielknoten F ablesen, sondern den kürzesten Pfad zu jedem beliebigen Knoten. Im aktuellen Beispiel, in dem der kürzeste Pfad über alle Knoten des Graphen führt, mag das naheliegend sein. Dies gilt jedoch allgemein, da der Algorithmus ja erst dann endet, wenn er im gesamten Graphen keine weitere Kostenreduktion mehr feststellt.
Maximale Anzahl Iterationen
Zu Beginn des Beispiels habe ich erklärt, dass es maximal n-1 Iterationen gibt. Warum ist das so?
Der längstmögliche Pfad durch den Graphen führt genau einmal durch alle n Knoten, enthält also n-1 Kanten. Im Worst Case werden in jeder Iteration die Kanten in genau entgegengesetzter Richtung zur gesuchten Route geprüft. Dies wiederum führt dazu, dass in jeder Iteration die Gesamtkosten nur für eine Kante in Richtung Ziel berechnet werden können. Bei n-1 Kanten sind somit n-1 Iterationen nötig.
Am folgende Beispiel ist das gut zu erkennen. Wir suchen in folgendem Graphen den kürzesten Weg von A nach D:
Worst-Case-Beispiel
Iteration 1
Im schlechtesten Fall besuchen wir die Kanten von rechts nach links, wir beginnen also mit der Kante (c, d). Da die Gesamtkosten von Knoten C noch unendlich sind (s. vorheriges Bild), ignorieren wir diese Kante. Gleiches gilt für die Kante (b, c). Erst bei der Kante (a, b) können wir die Gesamtkosten für B berechnen (0+2 = 2) und aktualisieren:
Iteration 1: Gesamtkosten und Vorgänger von Knoten B aktualisiert
Iteration 2
Wieder beginnen wir bei Kante (c, d). Die Gesamtkosten für Knoten C sind nach wie vor nicht berechnet (s. vorheriges Bild), also ignorieren wir die Kante auch in dieser Iteration. Die Gesamtkosten für Knoten B sind berechnet, daher können wir anhand der Kante (b, c) jetzt die Gesamtkosten für Knoten C berechnen (2+3 = 5):
Iteration 2: Gesamtkosten und Vorgänger von Knoten C aktualisiert
Iteration 3
Nachdem wir in der zweiten Iteration die Gesamtkosten für Knoten C berechnet haben, können wir schließlich anhand der Kante (c, d) auch die Gesamtkosten für Knoten D berechnen (5+2 = 7):
Iteration 3: Gesamtkosten und Vorgänger von Knoten D aktualisiert
Für vier Knoten (n = 4) haben wir also drei (n – 1) Iterationen benötigt.
Identifizierung negativer Zyklen in gerichteten Graphen
Ein Problem, mit dem wir im gezeigten Beispiel nicht konfrontiert wurden, ist das Vorhandensein negativer Zyklen im Graph. Dieser Abschnitt beschreibt, was ein negativer Zyklus ist, warum dieser eine Herausforderung darstellt und wie der Bellman-Ford-Algorithmus diese löst.
Was ist ein negativer Zyklus?
In einem negativen Zyklus kann man von einem Knoten aus denselben Knoten wieder erreichen über einen Pfad mit negativen Gesamtkosten. Z. B. in folgendem Graph:
Graph mit negativem Zyklus
In diesem Beispiel hat der zyklische Pfad B→C→D→B Gesamtkosten von 1+2+(-4) = -1
Warum ist ein negativer Zyklus problematisch?
Wir können den negativen Zyklus beliebig oft traversieren. Mit jeder Runde reduzieren wir die Gesamtkosten auf allen beteiligten Knoten weiter.
Nehmen wir an, wir suchen im Beispiel oben den Pfad mit den geringsten Gesamtkosten von A nach E. Der naheliegende Weg wäre A→B→C→D→E mit Gesamtkosten von 5+1+2+3 = 11.
Wir könnten von Knoten D aber auch zurück zu B gehen und folgenden Weg zurücklegen: A→B→C→D→B→C→D→E. Die Gesamtkosten dieses Weges belaufen sich auf 5+1+2+(-4)+1+2+3 = 10. Durch einmaliges Durchlaufen des negativen Zyklus haben wir die Gesamtkosten um 1 reduziert.
Wenn wir dem negativen Zyklus 11 mal durchlaufen, liegen die Gesamtkosten bei 0. Das ist aber nicht das Ende der Fahnenstange. Wir können dem negativen Zyklus auch 1.000 mal folgen und die Gesamtkosten auf -989 reduzieren. Oder 1.000.000 mal… es gibt unendlich viele Möglichkeiten: mit jedem weiteren Durchlauf des negativen Zyklus reduzieren wir die Gesamtkosten weiter.
Der Algorithmus würde also nie enden. Oder er würde, wenn wir ihn nach einer bestimmten Anzahl Iterationen abbrechen, nicht den kürzesten Pfad liefern.
Wie wird ein negativer Zyklus identifiziert?
Im Abschnitt „Maximale Anzahl Iterationen“ habe ich gezeigt, dass Bellman-Ford maximal n-1 Iterationen durchlaufen muss (n ist die Anzahl der Knoten), um den kürzesten Weg zu finden.
Der Algorithmus führt nun eine weitere Iteration durch, in der er prüft, ob sich an einem beliebigen Knoten noch einmal die Gesamtkosten reduzieren würden. Sollte das der Fall sein, ist die Schlussfolgerung, dass es im Graphen einen negativen Zyklus geben muss.
Der Algorithnmus endet dann mit einer entsprechenden Fehlermeldung.
Erstelle eine Tabelle aller Knoten mit Vorgängerknoten und Gesamtkosten vom Start.
Setze die Gesamtkosten des Startknotens auf 0 und die aller anderer Knoten auf unendlich.
Führe folgendes n-1 mal aus (n ist die Anzahl der Knoten):
Für jede Kante des Graphen:
Berechne die Summe aus Gesamtkosten zum Kanten-Startknoten und Kantengewicht.
Ist diese Summe niedriger als die aktuellen Gesamtkosten des Kanten-Endknotens, dann setze den Vorgänger des Endknotens auf den Kanten-Startknoten und die Gesamtkosten des Endknotens auf die eben berechnete Summe.
Wurden in dieser Iteration keine Änderungen durchgeführt, beende den Algorithmus vorzeitig (in der optimierten Version des Algorithmus).
Wenn der Algorithmus nicht vorzeitig beendet wurde, prüfe auf negative Zyklen:
Für jede Kante des Graphen:
Berechne die Summe aus Gesamtkosten zum Kanten-Startknoten und Kantengewicht.
Ist diese Summe niedriger als die aktuellen Gesamtkosten des Kanten-Endknotens, dann beende den Algorithmus mit der Meldung, dass ein negativer Zyklus entdeckt wurde.
Zunächst benötigen wir eine Datenstruktur für den Graph. Diese brauchen wir nicht selbst zu schreiben. Stattdessen verwenden wir den ValueGraph aus den Google Core Libraries for Java, genauer gesagt den MutableValueGraph. (Die verschiedenen Graph-Klassen werden hier erläutert.)
Der folgende Code zeigt, wie man den gerichteten Graphen aus dem Artikelbeispiel erstellt (du findest die Methode am Ende der Klasse TestWithSampleGraph im GitHub-Repository):
Typ der Knoten: im Beispielcode String für die Knotennamen „A“ bis „F“
Typ der Kantenwerte: im Beispielcode Integer für die Kosten der Kanten
Da der Graph gerichtet ist, ist es wichtig, in welcher Reihenfolge die Knoten jeweils angegeben werden. Für Kanten, die in beiden Richtungen existieren (z. B. zwischen den Knoten B und C) muss dementsprechend auch zweimal putEdgeValue() aufgerufen werden.
Datenstruktur für die Knoten: NodeWrapper
Als nächstes benötigen wir eine Datenstruktur, die für jeden Knoten dessen Gesamtkosten vom Start sowie dessen Vorgängerknoten speichert. Diese Aufgabe erledigt die Klasse NodeWrapper:
classNodeWrapper<N> {
privatefinal N node;
privateint totalCostFromStart;
private NodeWrapper<N> predecessor;
NodeWrapper(N node, int totalCostFromStart, NodeWrapper<N> predecessor) {
this.node = node;
this.totalCostFromStart = totalCostFromStart;
this.predecessor = predecessor;
}
// getter for node// getters and setters for totalCostFromStart and predecessor // equals() and hashCode()
}Code-Sprache:Java(java)
Der Typparameter <N> steht für den Knotentyp und ist in unserem Beispiel String für die Knotennamen.
Vorbereitung: Füllen der Tabelle
Der Algorithmus selbst wird in der Methode findShortestPath(ValueGraph<N, Integer> graph, N source, N target) der Klasse BellmanFord implementiert.
Als Datenstruktur für die Tabelle verwenden wir eine HashMap. Wir iterieren über alle Knoten des Graphen, verpacken jeden Knoten in einen NodeWrapper und setzen die Gesamtkosten des Startknotens auf 0 und die aller anderen Knoten auf Integer.MAX_VALUE:
Map<N, NodeWrapper<N>> nodeWrappers = new HashMap<>();
for (N node : graph.nodes()) {
int initialCostFromStart = node.equals(source) ? 0 : Integer.MAX_VALUE;
NodeWrapper<N> nodeWrapper = new NodeWrapper<>(node, initialCostFromStart, null);
nodeWrappers.put(node, nodeWrapper);
}Code-Sprache:Java(java)
Iterationen
Die Logik in den ersten n-1 Iterationen und die Logik zum Auffinden von negativen Zyklen sind größtenteils gleich. Daher fasse ich beides in eine Schleife zusammen, die nicht n-1 mal ausgeführt wird, sondern n mal:
// Iterate n-1 times + 1 time for the negative cycle detectionint n = graph.nodes().size();
for (int i = 0; i < n; i++) {
// Last iteration for detecting negative cycles?boolean lastIteration = i == n - 1;
boolean atLeastOneChange = false;
// For all edges...for (EndpointPair<N> edge : graph.edges()) {
NodeWrapper<N> edgeSourceWrapper = nodeWrappers.get(edge.source());
int totalCostToEdgeSource = edgeSourceWrapper.getTotalCostFromStart();
// Ignore edge if no path to edge source was found so farif (totalCostToEdgeSource == Integer.MAX_VALUE) continue;
// Calculate total cost from start via edge source to edge targetint cost = graph.edgeValue(edge).orElseThrow(IllegalStateException::new);
int totalCostToEdgeTarget = totalCostToEdgeSource + cost;
// Cheaper path found?// a) regular iteration --> Update total cost and predecessor// b) negative cycle detection --> throw exception
NodeWrapper edgeTargetWrapper = nodeWrappers.get(edge.target());
if (totalCostToEdgeTarget < edgeTargetWrapper.getTotalCostFromStart()) {
if (lastIteration) {
thrownew IllegalArgumentException("Negative cycle detected");
}
edgeTargetWrapper.setTotalCostFromStart(totalCostToEdgeTarget);
edgeTargetWrapper.setPredecessor(edgeSourceWrapper);
atLeastOneChange = true;
}
}
// Optimization: terminate if nothing was changedif (!atLeastOneChange) break;
}Code-Sprache:Java(java)
Zu Beginn der Schleife prüfen wir, ob wir in der letzten Iteration sind.
Dann iterieren wir über alle Kanten des Graphen und berechnen die über die jeweilige Kante erreichten Gesamtkosten für den Kanten-Endknoten. Sollten diese geringer sein als die bisher gespeicherten, dann aktualisieren wir den Endknoten bzw. – wenn wir in der letzten Iteration sind – werfen wir eine Exception aufgrund des erkannten negativen Zyklus.
Zuletzt prüfen wir, ob ein Weg zum Ziel gefunden wurde. Wenn ja, rufen wir die Backtrace-Funktion buildPath() auf und geben deren Ergebnis zurück – andernfalls ist der Rückgabewert null:
Die Backtrace-Methode buildPath() folgt den Knoten Vorgänger für Vorgänger und trägt diese dabei in eine Liste ein. Schließlich wird die Liste in umgekehrter Reihenfolge zurückgegeben:
Den Aufruf der findShortestPath()-Methode findest du in zwei Beispielen:
TestWithSampleGraph: Dieser Test erstellt den Beispiel-Graphen dieses Artikels und sucht darin die kürzeste Route von A nach F.
TestWithNegativeCycle: Dieser Test erstellt den Beispiel-Graphen aus dem Abschnitt über negative Zyklen und sucht darin den kürzesten Weg von A nach E.
Kommen wir nun zu einem eher theoretischen Thema: der Zeitkomplexität von Bellman-Ford.
Zeitkomplexität des Bellman-Ford-Algorithmus
Zeitkomplexität der nicht optimierten Variante
Die Zeitkomplexität des nicht optimierten Bellman-Ford-Algorithmus ist sehr einfach zu bestimmen.
Aus dem Abschnitt „Maximale Anzahl Iterationen“ wissen wir bereits, dass der Algorithmus n-1 Iterationen durchläuft, wobei n die Anzahl der Knoten ist. In einer weiteren Iteration wird geprüft, ob es negative Zyklen gibt.
In jeder Iteration werden alle Kanten des Graphen betrachtet. Wir bezeichnen die Anzahl der Kanten mit m.
Der Aufwand für das Behandeln einer Kante ist konstant:
Wir führen eine Addition durch und einen Vergleich.
Ggf. ändern wir Vorgänger und Gesamtkosten des Kanten-Endknotens.
Bei Verwendung einer geeigneten Datenstruktur (z. B. einer HashMap) ist das Auffinden des Knoten-Datensatzes in der Tabelle ebenfalls konstant*.
Es ergibt sich eine Gesamt-Zeitkomplexität von:
O(n · m)
Für den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist – in Landau-Notation: m ∈ O(n) – können wir m und n bei der Berechnung der Zeitkomplexität gleichsetzen.
Aus der Formel wird dann:
O(n²) für m ∈ O(n)
Der Aufwand ist also quadratisch.
* Das ist vereinfacht ausgedrückt und gilt bei ausreichender Kapazität der HashMap und bei Verwendung einer geeigneten Hash-Funktion. Im Worst Case würde sich der Aufwand für das Auffinden eines Datensatzes auf O(log n) verschlechtern (binäre Suche innerhalb der Buckets). Bei Millionen von Knoten wäre daher abzuwägen, ob man Gesamtkosten und Vorgänger direkt in den Knoten hinterlegt anstatt in einer separaten Datenstruktur.
Zeitkomplexität der optimierten Variante
In der optimierten Variante müssen wir best, worst und average case separat betrachten.
Zeitkomplexität der optimierten Variante – Worst Case
Bei einem Fall wie im Abschnitt „Maximale Anzahl Iterationen“ beschrieben kommt die Optimierung nicht zum Tragen, da in jeder Iteration Änderungen erfolgen. Die Zeitkomplexität entspricht somit der des nicht optimierten Algorithmus:
O(n · m)
bzw. O(n²) für m ∈ O(n)
Zeitkomplexität der optimierten Variante – Best Case
Im Best Case werden nur in der ersten Iteration Änderungen durchgeführt. Die Anzahl der Knoten ist damit für die Zeitkomplexität irrelevant, und der Aufwand wächst linear mit der Anzahl der Kanten:
O(m)
Zeitkomplexität der optimierten Variante – Average Case
Im durchschnittlichen Fall reduziert sich die Anzahl der Änderungen mit jeder Iteration rasch, so dass der Algorithmus nach nur wenigen Iterationen endet. Die Reduktion erfolgt um einen relativ konstanten Faktor, so dass die Anzahl der Iterationen im Average Case in der Größenordnung O(log n) liegt. Einen formalen Beweis dafür konnte ich in der Literatur nicht finden, die Experimente im folgenden Kapitel werden es aber bestätigen.
Die Zeitkomplexität des gesamten Algorithmus wird damit zu:
O(log n · m)
bzw. O(n · log n) für m ∈ O(n)
Im durchschnittlichen Fall haben wir also quasilinearen Aufwand.
Laufzeit des Bellman-Ford-Algorithmus
Mit dem Tool TestBellmanFordRuntime können wir prüfen, ob die theoretisch hergeleitete Zeitkomplexität mit der Praxis übereinstimmt. Das Programm erstellt Zufallsgraphen verschiedener Größen und sucht darin den kürzesten Weg zwischen zwei zufällig ausgewählten Knoten.
Die Optimierung des Algorithmus können wir für den Test abschalten, indem wir in der Klasse BellmanFord Zeile 69 auskommentieren.
Das Tool wiederholt jeden Test 50 mal und gibt anschließend den Median der Messwerte aus. Die folgenden zwei Grafiken zeigen die Messwerte im Verhältnis zur Anzahl der Knoten mit und ohne Optimierung. Da die Messwerte sehr weit auseinanderliegen, habe ich in der ersten Grafik den Fokus auf den Standard-Algorithmus gelegt, in der zweiten Grafik auf den optimierten.
Zeitkomplexität des Bellman-Ford-Algorithmus (Ausschnitt: Standardvariante)Zeitkomplexität des Bellman-Ford-Algorithmus (Ausschnitt: optimierte Variante)
Sowohl das quadratische Wachstum ohne Optimierung als auch das quasilineare Wachstum mit Optimierung sind gut zu erkennen. Dies entspricht den hergeleiteten Zeitkomplexitäten O(n²) für den ursprünglichen Algorithmus und O(n · log n) in der optimierten Variante – jeweils für m ∈ O(n).
Bellman-Ford vs. Dijkstra
Die folgende Grafik zeigt die Messungen für Bellman-Ford und Dijkstra gegenübergestellt (die für Dijkstra haben ich mit dem Tool TestDijkstraRuntime ermittelt):
Zeitkomplexität Bellman-Ford-Algorithmus vs. Dijkstra-Algorithmus
Es ist gut zu sehen, dass der nicht optimierte Bellman-Ford-Algorithmus um Größenordnungen langsamer ist als Dijkstras Algorithmus. Auch der optimierte Bellman-Ford-Algorithmus braucht rund zehnmal länger als Dijkstra (mit Fibonacci Heap).
Sofern wir keine negativen Kantengewichte in unserem Graphen haben, sollten wir also immer Dijkstra oder A* (sofern sich eine Heuristik definieren lässt) vorziehen.
Zusammenfassung und Ausblick
In diesem Artikel hast du gelernt (oder aufgefrischt), was negative Kantengewichte sind, wie der Bellman-Ford-Algorithmus den kürzesten Weg in einem gerichteten Graphen mit negativen Kantengewichten findet und wie er negative Zyklen identifiziert.
Die Zeitkomplexität der ursprünglichen Variante – sowie die Worst-Case-Zeitkomplexität der optimierten Variante – ist mit O(n · m) bzw. O(n²) für m ∈ O(n) deutlich schlechter als die von Dijkstra und A*. Dort liegt die Zeitkomplexität beim Einsatz eines Fibonacci-Heaps bei O(n · log n + m) bzw. O(n · log n) für m ∈ O(n).
Im average case schafft die optimierte Variante ebenfalls quasilinearen Aufwand, ist im Experiment aber dennoch etwa zehnmal langsamer als Dijkstra. Bellman-Ford sollte daher nur dann eingesetzt werden, wenn der Graph negative Kantengewichte enthält.
Vorschau: Floyd-Warshall-Algorithmus
Im nächsten und abschließenden Artikel der Pathfinding-Serie stelle ich den Floyd-Warshall-Algorithmus vor. Dieser wird benutzt, um die kürzesten Routen zwischen allen Knotenpaaren eines Graphen zu finden (Floyds Variante) – oder, um festzustellen, zwischen welchen Knotenpaaren es überhaupt Routen gibt (Warshalls Variante).
Wie findet ein Navigationssystem den schnellsten Weg vom Start zum Ziel in möglichst geringer Zeit? Dieser Frage (und ähnlichen) geht diese Artikelserie über „Shortest Path“-Algorithmen nach.
Im vorangegangenen Teil über Dijkstras Algorithmus haben wir festgestellt, dass dieser vom Startpunkt aus erreichbaren Pfaden in alle Richtungen folgt – und zwar unabhängig davon, in welcher Richtung sich das Ziel befindet. Das ist natürlich nicht optimal.
Der A*-Algorithmus (ausgesprochen „A Stern“ oder englisch „A Star“) ist eine Weiterentwicklung des Dijkstra-Algorithmus. Der A*-Algorithmus beendet die Prüfung von Pfaden, die in die falsche Richtung führen, vorzeitig. Dazu verwendet er eine Heuristik, die mit minimalem Aufwand für jeden Knoten die kürzestmögliche Entfernung zum Ziel berechnen kann. Wie das genau funktioniert, erfährst du in diesem Artikel.
Die Themen im Einzelnen:
Wie funktioniert der A*-Algorithmus (Schritt für Schritt an einem Beispiel erklärt)
Was unterscheidet den A*-Algorithmus von Dijkstras Algorithmus?
Wie implementiert man den A*-Algorithmus in Java?
Wie bestimmt man die Zeitkomplexität?
Messung der Laufzeit der Java-Implementierung
Den Quellcode zur gesamten Artikelserie findest du in meinem GitHub-Repository.
A*-Algorithmus – Beispiel
Wir beginnen mit einem Beispiel. Der Einfachheit halber verwenden wir das gleiche Beispiel wie bei der Erklärung des Dijkstra-Algorithmus. Die folgende Zeichnung stellt eine Straßenkarte dar:
Straßenkarte
Orte werden durch Kreise mit Buchstaben dargestellt. Die Linien dazwischen sind Schnellstraßen (dicke Linien), Dorfstraßen (dünne Linien) und Feldwege (gestrichelte Linien).
Die Straßenkarte bilden wir auf den folgenden Graphen ab. Orte werden zu Knoten; Straße und Wege werden zu Kanten:
Straßenkarte als gewichteter Graph
Die Gewichte der Kanten stellen die Kosten eines Weg dar. Das ist beispielsweise die Zeit in Minuten, die man für das Zurücklegen eines Weges benötigt.
Ein kürzerer Weg führt nicht zwingendermaßen zu niedrigeren Kosten. Es kann z. B. deutlich länger dauern einen kurzen Feldweg zu passieren als eine lange Schnellstraße.
Wir können nun z. B. ablesen, dass der kürzeste Weg von D nach H über F führt und insgesamt 11 Minuten dauert (gelbe Strecke). Über die längere Strecke über C und G (blaue Strecke) brauchen wir hingegen nur 9 Minuten:
Straßenkarte: schnellster Weg und kürzester Weg
Wir Menschen schaffen das mit einem Blick. Auch auf komplexeren Straßenkarten können wir relativ problemlos navigieren. Die erfahreneren von uns können sich sicher noch gut an die Zeiten erinnern, zu denen wir im Auto auf eine Straßenkarte blickten anstatt auf ein Navigationssystem.
Ein Computer braucht hierfür einen Algorithmus, z. B. den A*-Algorithmus.
A*-Algorithmus – Heuristik-Funktion
In der Einleitung habe ich eine Heuristik-Funktion erwähnt, die den schnellstmöglichen Weg von allen Knoten des Graphen zum Zielknoten berechnen kann. Da unser Graph eine zweidimensionale Landkarte repräsentiert, eignet sich für die Heuristik-Funktion die euklidische Distanz oder – lapidar gesagt – die Luftlinie zum Ziel-Knoten.
Die Heuristik wird im späteren Verlauf dafür sorgen, dass der Algorithmus bei der Wegsuche diejenigen Knoten priorisiert, die grob in die richtige Richtung führen.
Wichtig ist dabei, dass die Heuristik die tatsächlichen Kosten, die bis zum Ziel anfallen könnten, niemals überschätzen darf. Damit wir im Beispiel die tatsächlichen Kosten zum Ziel nicht überschätzen, berechnen wir als Heuristik die Anzahl der Minuten, die man auf einer der Luftlinie folgenden Schnellstraße zum Ziel benötigen würde.
Um Entfernungen messen zu können, fügen wir ein Koordinatensystem hinzu:
Straßenkarte mit Koordinatensystem
Wir berechnen nun die Länge der zwei Schnellstraßen von A nach C und von C nach G mit Hilfe des Satzes des Pythagoras. Dann teilen wir die Länge durch die Kosten der Strecke, um die Geschwindigkeit zu erhalten:
Weg A–C
Entfernung: 3,414 km Kosten: 2 min Geschwindigkeit: 3,414 km / 2 min = 1,707 km/min (= 102,42 km/h)
Weg C–G
Entfernung: 3,406 km Kosten: 2 min Geschwindigkeit: 3,406 km / 2 min = 1,703 km/min (= 102,18 km/h)
Die schnellstmögliche Geschwindigkeit (vmax) auf unserer Karte wird also auf der Strecke A–C erreicht und beträgt etwa 1,7 km/min (dies entspricht 102 km/h).
Eigentlich müssten wir die Geschwindigkeit für alle Wege berechnen. Aber wir hatten die Karte ja initial so konstruiert, dass alle anderen Straßen langsamer sind. Deshalb sparen wir uns das an dieser Stelle.
In einem Navigationssystem ist die schnellstmögliche Geschwindigkeit vorberechnet und in den Kartendaten enthalten.
Anwendung der Heuristik-Funktion
Mit Hilfe der schnellstmöglichen Geschwindigkeit vmax berechnen wir nun die kürzest mögliche Fahrtzeit von jedem Punkt der Karte zum Zielpunkt. Dazu berechnen wir jeweils die Entfernung in Form der euklidische Distanz und teilen diese durch vmax.
Für Knoten A beispielsweise wie folgt:
Knoten A
Entfernung zu Zielknoten H: 6,588 km vmax: 1,707 km/min Minimale Kosten: 6,588 km / 1,707 km/min = 3,859 min ≈ 3,9 min
Genauso gehen wir für alle anderen Knoten vor. Es ergeben sich folgende kürzestmögliche Fahrtzeiten (auf eine Nachkommastelle gerundet):
Durch die Heuristik-Funktion berechnete Restkosten
Vorbereitung – Tabelle der Knoten
Zur weiteren Vorbereitung erstellen wir eine Tabelle der Knoten. Die Tabelle hat folgende Spalten:
Knotenname
Vorgänger-Knoten
Gesamtkosten vom Start-Knoten
Minimale Restkosten zum Ziel-Knoten
Summe beider Kosten
Die Vorgänger-Knoten bleiben zunächst leer. Als Gesamtkosten vom Start tragen wir für den Startknoten selbst eine 0 ein; für alle anderen Knoten unendlich, da wir noch nicht wissen, ob diese vom Startknoten überhaupt erreichbar sind.
Als minimale Restkosten tragen wir die im vorherigen Abschnitt berechneten Restkosten zum Zielknoten ein.
Die Tabelle wird letztlich nach der Summe der zwei Kostenspalten (Gesamtkosten vom Start-Knoten + Minimale Restkosten zum Ziel-Knoten) sortiert. Die Knoten, bei der die Summe der Kosten unendlich ist, bleiben unsortiert (im Beispiel sind sie alphabetisch sortiert):
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
D
–
0,0
2,5
2,5
A
–
∞
3,9
∞
B
–
∞
4,3
∞
C
–
∞
3,2
∞
E
–
∞
2,5
∞
F
–
∞
1,5
∞
G
–
∞
2,8
∞
H
–
∞
0,0
∞
I
–
∞
1,6
∞
Im folgenden ist es wichtig die Begriffe Kosten, Gesamtkosten und Restkosten zu unterscheiden:
Kosten bezeichnet die Kosten von einem Knoten zu seinen Nachbarknoten.
Gesamtkosten bezeichnet die Summe aller Teilkosten vom Startknoten über eventuelle Zwischenknoten zu einem bestimmten Knoten.
Restkosten bezeichnet die durch die Heuristik-Funktion berechneten Kosten, die auf dem Weg zum Ziel noch mindestens entstehen werden.
A*-Algorithmus Schritt für Schritt – Abarbeitung der Knoten
In den folgenden Grafiken stelle ich in den Knoten den jeweiligen Vorgängerknoten sowie die Gesamt- und Restkosten mit dar. Diese Daten sind in der Regel nicht im Graph enthalten, sondern nur in der oben beschriebenen Tabelle. Sie hier mit anzuzeigen wird das Verständnis erleichtern.
Schritt 1: Betrachten aller Nachbarn des Startpunkts
Wir entnehmen das erste Element – Knoten D – aus der Tabelle und betrachten seine Nachbarn, also C, E und F:
Von D aus erreichbare Knoten
Die Gesamtkosten der Nachbarknoten stehen zu diesem Zeitpunkt noch auf dem Initialwert unendlich, was bedeutet, dass wir bisher noch keine Wege dorthin gefunden haben. Nun haben wir Wege dorthin gefunden – nämlich direkt vom Ausgangspunkt D.
Wir tragen daher als Gesamtkosten vom Start die Kosten von D zum jeweiligen Knoten ein und bilden die Summe mit den Restkosten. Außerdem hinterlegen wir Knoten D als Vorgänger.
Für C beispielsweise ergeben sich folgende Werte:
Gesamtkosten vom Start: 3,0 (die Kosten von D zu C)
Restkosten: 3,2 (diese haben wir im vorherigen Abschnitt für alle Knoten berechnet)
Summe aller Kosten: 3,0 + 3,2 = 6,2
Für E und F gehen wir genauso vor. Für ein einfaches Verständnis trage ich die Ergebnisse in den Graph ein:
Kosten und Vorgänger der Knoten C, E, F wurden aktualisiert
Die aktualisierte Tabelle sortieren wir erneut nach der Summe der Kosten (die geänderten Einträge sind fett markiert):
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
E
D
1,0
2,5
3,5
F
D
4,0
1,5
5,5
C
D
3,0
3,2
6,2
A
–
∞
3,5
∞
B
–
∞
3,8
∞
G
–
∞
2,8
∞
H
–
∞
0,0
∞
I
–
∞
1,6
∞
Die Änderungen sind so lesen: Knoten E, F und C wurden entdeckt. Sie können über D in 1, 4 bzw. 3 Minuten erreicht werden. Addiert man die minimalen Restkosten zum Ziel, ergeben sich 3,5, 5,5 und 6,2 Minuten, die man über die jeweiligen Knoten mindestens brauchen würde, um das Ziel zu erreichen.
Unterschied zum Dijkstra-Algorithmus: Umwege werden gemieden
Hier wird bereits der Unterschied zum Dijkstra-Algorithmus deutlich. Dort hatten wir die Tabelle nach Gesamtkosten sortiert, weshalb Knoten C (Gesamtkosten 3,0) vor Knoten F (Gesamtkosten 4,0) einsortiert wurde.
Durch die heuristische Komponente liegt beim A*-Algorithmus Knoten F (Kostensumme 5,3) vor Knoten C (Kostensumme 5,8). Der A*-Algorithmus hält es also für wahrscheinlicher das Ziel schneller über Knoten F zu erreichen als über Knoten C. Wenn wir noch einmal einen Blick auf denjenigen Ausschnitt der Karte werden, den der Algorithmus bis jetzt betrachtet hat, macht das Sinn:
Bisher betrachteter Ausschnitt der Karte
Knoten F liegt in der direkten Richtung zum Zielknoten H, während der Weg über Knoten C in die falsche Richtung führt.
Dass der Umweg über Knoten C letztendlich schneller ist, wird A* bald feststellen. In der Regel sind Umwege aber länger. Deshalb ist es gerechtfertig, diese niedriger zu priorisieren.
Schritt 2: Betrachten aller Nachbarn von Knoten E
Wir wiederholen den Prozess für denjenigen Knoten, der jetzt an erster Stelle der Tabelle steht. Das ist Knoten E. Wir entnehmen ihn und betrachten seine Nachbarn, A, B, D und F:
Von E aus erreichbare Knoten
Knoten D ist in der Tabelle nicht mehr enthalten. Dies bedeutet, dass wir den kürzesten Weg dorthin bereits entdeckt haben (es ist der Startknoten, den wir im vorangegangenen Schritt behandelt haben). Wir können ihn daher an dieser Stelle ignorieren.
Knoten A und B haben als Gesamtkosten unendlich, d. h. zu ihnen wurde noch kein Weg gefunden. Wir berechnen für diese Knoten die Gesamtkosten vom Start, in dem wir die Gesamtkosten des aktuellen Knotens E und die Kosten von Knoten E zu Knoten A bzw. B addieren:
Knoten A
1,0 (Gesamtkosten vom Start zu E) + 3,0 (Kosten E–A) = 4,0
Knoten B
1,0 (Gesamtkosten vom Start zu E) + 5,0 (Kosten E–B) = 6,0
Zu den jeweiligen Gesamtkosten addieren wir die vorab berechneten minimalen Restkosten zum Ziel:
Knoten A
4,0 (Gesamtkosten vom Start zu A) + 3,9 (minimale Restkosten von A zum Ziel) = 7,9
Knoten B
6,0 (Gesamtkosten vom Start zu B) + 4,3 (minimale Restkosten von B zum Ziel) = 10,3
Wir aktualisieren die Einträge in der Grafik:
Kosten und Vorgänger der Knoten A, B wurden aktualisiert
Zu Knoten F wurde bereits ein Weg gefunden mit Gesamtkosten von 4. Es wäre möglich, dass der Weg über den aktuellen Knoten E schneller ist. Um dies zu prüfen, berechnen wir auch für Knoten F die Gesamtkosten über E:
Knoten F
1,0 (Gesamtkosten vom Start zu E) + 6,0 (Kosten E–F) = 7,0
Die über E berechneten Gesamtkosten (7,0) sind höher als die bisher hinterlegten Gesamtkosten (4,0). Das bedeutet: Wir konnten zwar einen neuen Weg zu F finden, allerdings ist dieser teurer als der bisher bekannte. Somit ignorieren wir ihn, d. h. wir lassen die Tabelleneinträge für Knoten F unverändert.
Die Tabelle sieht nun wie folgt aus (die Änderungen sind wieder fett markiert):
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
F
D
4,0
1,5
5,5
C
D
3,0
3,2
6,2
A
E
4,0
3,9
7,9
B
E
6,0
4,3
10,3
G
–
∞
2,8
∞
H
–
∞
0,0
∞
I
–
∞
1,6
∞
Die neuen Einträge sind so lesen: Knoten A und B wurden entdeckt. Sie können über Knoten E in 4 bzw. 6 Minuten erreicht werden. Addiert man die minimalen Restkosten zum Ziel, ergeben sich 7,9 bzw. 10,3 Minuten, die man über die jeweiligen Knoten mindestens brauchen würde, um das Ziel zu erreichen. Diese Werte sind höher als die der Knoten F und C, weshalb die Knoten A und B in der Tabelle hinter F und C bleiben.
Schritt 3: Betrachten aller Nachbarn von Knoten F
Wir wiederholen das Ganze für Knoten F und betrachten dessen Nachbarn D, E und H:
Von F aus erreichbare Knoten
Knoten D und E sind nicht mehr in der Tabelle. Wir haben die kürzesten Wege dorthin bereits entdeckt (in den vorangegangenen zwei Schritten).
Wir müssen also nur Knoten H betrachten. Wir berechnen, wie zuvor, die Gesamtkosten vom Start zu Knoten H:
Knoten H
4,0 (Gesamtkosten vom Start zu F) + 7,0 (Kosten F–H) = 11,0
Knoten H ist das Ziel. Daher existieren keine Restkosten, die wir noch addieren müssten. Wir tragen Vorgänger und Gesamtkosten ein:
Kosten und Vorgänger von Knoten H wurde aktualisiert
Wir haben also einen Weg zum Zielknoten H gefunden. Dieser führt über Knoten F und hat Gesamtkosten von 11,0. Wir aktualisieren Knoten H in der Tabelle:
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
C
D
3,0
3,2
6,2
A
E
4,0
3,9
7,9
B
E
6,0
4,3
10,3
H
F
11,0
0,0
11,0
G
–
∞
2,8
∞
I
–
∞
1,6
∞
In der Tabelle existieren noch drei Knoten mit einer Kostensumme von weniger als 11,0. Das bedeutet, dass wir über diese drei Knoten möglicherweise einen schnelleren Weg zum Ziel finden könnten. Wir müssen den Prozess so lange weiterführen, bis der Zielknoten die erste Position der Tabelle erreicht hat.
Schritt 4: Betrachten aller Nachbarn von Knoten C
Der nächste Knoten in der Tabelle ist Knoten C. Wir entfernen ihn und betrachten seine Nachbarn, A, D und G:
Von C aus erreichbare Knoten
Knoten D (unser Startknoten) ist nicht mehr in der Tabelle.
Wir berechnen, wie schon zuvor, die Gesamtkosten vom Start über den aktuellen Knoten C zu den Knoten A und G:
Knoten A
3,0 (Gesamtkosten vom Start zu C) + 2,0 (Kosten C–A) = 5,0
Knoten G
3,0 (Gesamtkosten vom Start zu C) + 2,0 (Kosten C–G) = 5,0
Zu Knoten A hatten wir bereits einen Weg über E mit Gesamtkosten vom Start von 4 entdeckt. Die Gesamtkosten über den neuen Weg zu A sind mit 5 höher, wir ignorieren also den neu entdeckten Weg zu A.
Zu Knoten G hatten wir noch keinen Weg entdeckt. Zu den soeben berechneten Gesamtkosten vom Start addieren wir noch die vorab berechneten Restkosten zum Ziel:
Knoten G
5,0 (Gesamtkosten vom Start zu G) + 2,8 (minimale Restkosten von G zum Ziel) = 7,8
Wir tragen Vorgänger und Kosten für Knoten G in die Grafik ein:
Kosten und Vorgänger von Knoten G wurde aktualisiert
Und wir aktualisieren Knoten G in der Tabelle:
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
G
C
5,0
2,8
7,8
A
E
4,0
3,9
7,9
B
E
6,0
4,3
10,3
H
F
11,0
0,0
11,0
I
–
∞
1,6
∞
Knoten G ist in der Tabelle auf Platz eins vorgerückt. Der A*-Algorithmus geht nun also – mit Hilfe der Heuristik – davon aus, über Knoten G den schnellsten Weg zum Ziel zu finden.
(Dijkstras Algorithmus würde – aufgrund der niedrigeren Gesamtkosten vom Start – mit Knoten A fortfahren.)
Schritt 5: Betrachten aller Nachbarn von Knoten G
Wir entnehmen also Knoten G und betrachten dessen Nachbarn, C und H:
Von G aus erreichbare Knoten
Knoten C ist nicht mehr in der Tabelle, diesen hatten wir im vorangegangenen Schritt abgearbeitet.
Wir berechnen die Gesamtkosten vom Start über Knoten G zu Knoten H:
Knoten H
5,0 (Gesamtkosten vom Start zu G) + 4,0 (Kosten G–H) = 9,0
Die aktuell in Knoten H hinterlegten Kosten betragen 11,0. Wir haben also über Knoten G einen schnelleren Weg zum Zielknoten H entdeckt. Wir aktualisieren Vorgänger und Kosten in Knoten H:
Kosten und Vorgänger von Knoten H wurde aktualisiert
Restkosten existieren im Zielknoten keine.
Die aktualisierte Tabelle sieht wie folgt aus:
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
A
E
4,0
3,9
7,9
H
G
9,0
0,0
9,0
B
E
6,0
4,3
10,3
I
–
∞
1,6
∞
Knoten A ist in der Tabelle noch vor dem Zielknoten. Die Summe aller Kosten in diesem Knoten ist mit 7,9 niedriger als die eben berechnete Kostensumme zu Knoten H. Das bedeutet: Würden es eine Luftlinienverbindung von Knoten A zum Ziel H geben, dann wäre der Weg über A schneller als der eben gefundene über G.
Im nächsten Schritt wird der Algorithmus herausfinden, ob es einen solchen Weg gibt oder nicht.
Schritt 6: Betrachten aller Nachbarn von Knoten A
Gehen wir es also an: Wir entnehmen Knoten A und betrachten dessen Nachbarn, C und E:
Von A aus erreichbare Knoten
Beide Knoten sind nicht mehr in der Tabelle enthalten. Wir haben beide schon bearbeitet. Einen unentdeckten Weg zum Ziel finden wir in diesem Schritt also nicht.
Die Tabelle sieht nun so aus:
Knoten
Vorgänger
Gesamtkosten vom Start
Minimale Restkosten zum Ziel
Summe aller Kosten
H
G
9,0
0,0
9,0
B
E
6,0
4,3
10,3
I
–
∞
1,6
∞
Unser Zielknoten hat Platz 1 der Tabelle erreicht.
Schnellster Weg zum Ziel wurde gefunden
Das bedeutet: Es gibt keinen Knoten, über den ein noch kürzerer Weg zum Ziel gefunden werden könnte.
Auch nicht über Knoten B?
Die Gesamtkosten vom Start zu Knoten B betragen zwar nur 6,0, doch mit den minimalen Restkosten zum Ziel von 4,3 ergeben sich Gesamtkosten von mindestens 10,3, so dass der bisherige Bestwert 9,0 nicht mehr eingeholt werden kann.
Backtrace zur Bestimmung des vollständigen Weges
Aus der Tabelle können wir ablesen: Der Zielknoten H ist am schnellsten über Knoten G erreichbar. Doch wie bestimmen wir den vollständigen Weg vom Startknoten D zum Ziel? Hierzu führen wir einen sogenannten „Backtrace“ durch: Wir beginnen beim Zielknoten und folgen allen Vorgängerknoten, bis wir den Startknoten erreichen.
Am einfachsten lässt sich das am Graph demonstrieren:
Backtrace zur Bestimmung des vollständigen Weges
Der Vorgänger des Zielknotens H ist G; der Vorgänger von G ist C; und der Vorgänger von C ist der Startknoten D. Der schnellste Weg lautet also: D–C–G–H.
Unterschied A*-Algorithmus zu Dijkstras Algorithmus
Im letzten Schritt wurde der Unterschied zu Dijkstras Algorithmus noch einmal deutlich: Knoten B hat niedrigere Gesamtkosten vom Start (6) als Knoten H (9). Dijkstras Algorithmus würde an dieser Stelle noch prüfen müssen, ob das Ziel über Knoten B schneller erreicht werden könnte.
Durch die Heuristik weiß der A*-Algorithmus an dieser Stelle, dass die Gesamtkosten des Weges über Knoten B mindestens 10,3 betragen würden (Kosten vom Start 6,0 plus minimale Restkosten 4,3). Die Kosten des aktuellen Weges (9,0) sind also außer Reichweite.
Der A*-Algorithmus hat den schnellsten Weg zum Ziel somit in einem Schritt weniger gefunden als Dijkstras Algorithmus benötigt hätte. Wir werden später sehen, dass der Unterschied bei komplexeren Graphen (wie beispielsweise bei echten Straßenkarten) deutlich höher ausfallen wird.
A*-Algorithmus – Informelle Beschreibung
Vorbereitung:
Erstelle eine Tabelle aller Knoten mit Vorgängerknoten, Gesamtkosten vom Start, minimalen Restkosten zum Ziel und Kostensumme.
Setze die Gesamtkosten des Startknotens auf 0 und die aller anderer Knoten auf unendlich.
Berechne über die Heuristik-Funktion die minimalen Restkosten zum Ziel für alle Knoten.
Abarbeitung der Knoten:
Solange die Tabelle nicht leer ist, entnehme das Element mit der kleinsten Kostensumme und mache damit folgendes:
Ist das entnommene Element der Zielknoten? Wenn ja, ist die Abbruchbedingung erfüllt. Folge dann den Vorgängerknoten zurück zum Startknoten, um den kürzesten Weg zu bestimmen.
Andersfalls betrachte alle Nachbarknoten des entnommenen Elements, die sich noch in der Tabelle befinden. Für jeden Nachbarknoten:
Berechne die Gesamtkosten vom Start als Summe der Gesamtkosten vom Start zum entnommenen Knoten plus der Kosten vom entnommenen Knoten zum betrachteten Nachbarknoten.
Sind die neu berechneten Gesamtkosten vom Start niedriger als die bisher gespeicherten? Wenn nein, dann ignoriere diesen Nachbarknoten. Wenn ja, dann:
Berechne für den Nachbarknoten die Summe aus den soeben berechneten Gesamtkosten vom Start und den Restkosten zum Ziel.
Trage als Vorgänger des Nachbarknotens den entnommenen Knoten ein.
Trage für den Nachbarknoten die neu berechneten Gesamtkosten und die Kostensumme ein.
A*-Algorithmus – Java-Quellcode
Im folgenden zeige ich dir, Schritt für Schritt, wie man den A*-Algorithmus in Java implementiert und welche Datenstrukturen man dafür optimalerweise verwendet.
Die hier nicht mit abgedruckten Methoden equals(), hashCode() und compareTo() basieren auf dem Namen des Knoten.
Datenstruktur für den Graph: Guava ValueGraph
Als Datenstruktur für den Graph verwenden wir die Klasse ValueGraph der Google Core Libraries for Java. Diese stellt verschiedene Graph-Typen bereit, welche hier erläutert werden. Wir verwenden einen MutableValueGraph.
Der folgende Code zeigt, wie wir einen Graph erstellen, der dem aus dem Beispiel oben entspricht. Die X- und Y-Koordinaten habe ich aus der Grafik mit dem Koordinatensystem abgelesen. Die Einheit ist Meter; tatsächlich ist die Einheit aber irrelevant für das Finden des schnellsten Weges.
privatestatic ValueGraph<NodeWithXYCoordinates, Double> createSampleGraph(){
MutableValueGraph<NodeWithXYCoordinates, Double> graph =
ValueGraphBuilder.undirected().build();
NodeWithXYCoordinates a = new NodeWithXYCoordinates("A", 2_410, 6_230);
NodeWithXYCoordinates b = new NodeWithXYCoordinates("B", 8_980, 6_080);
NodeWithXYCoordinates c = new NodeWithXYCoordinates("C", 560, 3_360);
NodeWithXYCoordinates d = new NodeWithXYCoordinates("D", 2_980, 3_900);
NodeWithXYCoordinates e = new NodeWithXYCoordinates("E", 4_220, 4_280);
NodeWithXYCoordinates f = new NodeWithXYCoordinates("F", 4_000, 2_600);
NodeWithXYCoordinates g = new NodeWithXYCoordinates("G", 0, 0);
NodeWithXYCoordinates h = new NodeWithXYCoordinates("H", 4_850, 110);
NodeWithXYCoordinates i = new NodeWithXYCoordinates("I", 7_500, 0);
graph.putEdgeValue(a, c, 2.0);
graph.putEdgeValue(a, e, 3.0);
graph.putEdgeValue(b, e, 5.0);
graph.putEdgeValue(b, i, 15.0);
graph.putEdgeValue(c, d, 3.0);
graph.putEdgeValue(c, g, 2.0);
graph.putEdgeValue(d, e, 1.0);
graph.putEdgeValue(d, f, 4.0);
graph.putEdgeValue(e, f, 6.0);
graph.putEdgeValue(f, h, 7.0);
graph.putEdgeValue(g, h, 4.0);
graph.putEdgeValue(h, i, 3.0);
return graph;
}Code-Sprache:Java(java)
Die Typparameter des ValueGraph sind:
Typ der Knoten: im Beispiel NodeWithXYCoordinates für die Knoten mitsamt ihren X- und Y-Koordinaten
Typ der Kantenwerte: im Beispiel Double für die Kosten zwischen zwei Knoten
Der Graph ist ungerichtet; es spielt also keine Rolle, in welcher Reihenfolge wir die Knoten in der putEdgeValue()-Methode angeben.
Die Heuristik-Funktion muss zu einem gegebenen Knoten die minimalen Restkosten zum Ziel berechnen können. Es bietet sich an das Function-Interface zu implementieren (im GitHub-Repository findest du die Klasse HeuristicForNodesWithXYCoordinates mit zusätzlichen Kommentaren und Debug-Ausgaben):
Dem Konstrukor werden der Graph und der Zielknoten übergeben. In der Methode calculateMaxSpeed() wird für alle Kanten die Geschwindigkeit und davon das Maximum bestimmt. Maximalgeschwindigkeit und Zielknoten werden in Instanzvariablen gespeichert.
In der apply()-Methode wird letztendlich die Heuristik auf den übergebenen Knoten angewendet: Es wird die euklidische Distanz zum Zielknoten berechnet und diese durch die Maximalgeschwindigkeit geteilt, um die minimalen Restkosten vom übergebenen Knoten zum Ziel zu berechnen.
Datenstruktur: Tabelleneinträge
Für die Tabelle der Knoten benötigen wir eine Datenstruktur, in der wir zu jedem Knoten dessen Vorgänger speichern, sowie die Gesamtkosten vom Start, die minimalen Restkosten zum Ziel und die Kostensumme. Der folgende Code zeigt die dafür implementierte Klasse AStarNodeWrapper:
Der Typparameter N steht für den Typ der Knoten – in unserem Beispiel wird das NodeWithXYCoordinates sein. Die Parametrisierung erlaubt es uns auch andere Typen zu verwenden, z. B. einen Knoten mit Längen- und Breitengraden – oder einen mit zusätzlicher Z-Koordinate).
Im Konstruktor sowie in der Methode setTotalCostFromStart() wird calculateCostSum() aufgerufen, um die Summe aus Gesamtkosten vom Start und minimalen Restkosten zum Ziel zu berechnen.
Diese Summe wird wiederum in der compareTo()-Methode verwendet, um die natürliche Ordnung der Wrapper-Klasse so zu definieren, dass diese nach Kostensumme aufsteigend sortiert wird. Bei gleicher Kostensumme werden die Knoten selbst verglichen. Im Fall von NodeWithXYCoordinates würde dann nach Knotenname sortiert werden. (Warum der zweite Vergleich bei gleicher Kostensumme unbedingt nötig ist, wirst du weiter unten erfahren.)
Datenstruktur: TreeSet als Tabelle
Wer den Artikel über Dijkstras Algorithmus gelesen hat, weiß, dass die in Pathfinding-Tutorials häufig eingesetzte PriorityQueue nicht die optimale Datenstruktur für diese Tabelle ist. Warum das so ist, werde ich im Abschnitt über die Zeitkomplexität noch einmal zeigen. Wir verwenden stattdessen ein TreeSet.
Das TreeSet liefert mit der pollFirst()-Methode das kleinste Elemente zurück. Durch die oben beschriebene natürliche Ordnung der AStarNodeWrapper-Objekte wird dies immer der Knoten mit der geringsten Summe aus Gesamtkosten vom Start und minimalen Restkosten zum Ziel sein.
TreeSet<AStarNodeWrapper<N>> queue = new TreeSet<>();Code-Sprache:GLSL(glsl)
Datenstruktur: Lookup Map für Wrapper
Im weiteren Verlauf benötigen eine Map, die für einen Knoten des Graphen den dazugehörigen Wrapper liefert. Hierfür verwenden wir eine HashMap:
Map<N, AStarNodeWrapper<N>> nodeWrappers = new HashMap<>();Code-Sprache:GML(gml)
Datenstruktur: Abgearbeitete Knoten
Um prüfen zu können, ob wir einen Knoten bereits abgearbeitet haben, d. h. den kürzesten Weg dorthin gefunden haben, legen wir ein HashSet an:
Set<N> shortestPathFound = new HashSet<>();Code-Sprache:Java(java)
Vorbereitung: Füllen der Tabelle
Kommen wir zum vorbereitenden Schritt, dem Füllen der Tabelle.
An dieser Stelle können wir eine Optimierung gegenüber der informellen Beschreibung des Algorithmus vornehmen. Anstatt alle Knoten in die Tabelle zu schreiben, schreiben wir zunächst nur den Startknoten. Alle weiteren Knoten fügen wir erst dann in die Tabelle ein, wenn wir einen Weg dorthin gefunden haben.
Hierdurch schlagen wir drei Fliegen mit einer Klappe:
Wir sparen Tabelleneinträge für diejenigen Knoten, die vom Startpunkt aus nicht erst erreichbar sind oder nur über solche Zwischenknoten, deren Kostensumme höher ist als die Kosten eines bereits gefundenen Weges (wie im Beispiel der Knoten I).
Auf ebendiese Knoten brauchen wir auch die Heuristik-Funktion nicht anzuwenden.
Wenn wir die Kostensumme eines Knotens, der sich bereits in der Tabelle befindet, neu berechnen, müssen wir den Knoten aus der Tabelle entfernen und ihn neu einfügen, damit er an die richtige Position sortiert wird. Auch diesen Mehraufwand sparen wir uns, wenn wir die Knoten erst dann einfügen, wenn wir einen Weg dorthin entdeckt haben.
Wir beginnen also damit unseren Startknoten in einen AStarNodeWrapper einzupacken – und fügen diesen in Lookup-Map und Tabelle ein:
while (!queue.isEmpty()) {
AStarNodeWrapper<N> nodeWrapper = queue.pollFirst();
N node = nodeWrapper.getNode();
shortestPathFound.add(node);
// Have we reached the target? --> Build and return the pathif (node.equals(target)) {
return buildPath(nodeWrapper);
}
// Iterate over all neighbors
Set<N> neighbors = graph.adjacentNodes(node);
for (N neighbor : neighbors) {
// Ignore neighbor if shortest path already foundif (shortestPathFound.contains(neighbor)) {
continue;
}
// Calculate total cost from start to neighbor via current nodedouble cost =
graph.edgeValue(node, neighbor).orElseThrow(IllegalStateException::new);
double totalCostFromStart = nodeWrapper.getTotalCostFromStart() + cost;
// Neighbor not yet discovered?
AStarNodeWrapper<N> neighborWrapper = nodeWrappers.get(neighbor);
if (neighborWrapper == null) {
neighborWrapper =
new AStarNodeWrapper<>(
neighbor, nodeWrapper, totalCostFromStart, heuristic.apply(neighbor));
nodeWrappers.put(neighbor, neighborWrapper);
queue.add(neighborWrapper);
}
// Neighbor discovered, but total cost via current node is lower?// --> Update total cost and predecessorelseif (totalCostFromStart < neighborWrapper.getTotalCostFromStart()) {
// The position in the TreeSet won't change automatically;// we have to remove and reinsert the node.// Because TreeSet uses compareTo() to identity a node to remove,// we have to remove it *before* we change the cost!
queue.remove(neighborWrapper);
neighborWrapper.setTotalCostFromStart(totalCostFromStart);
neighborWrapper.setPredecessor(nodeWrapper);
queue.add(neighborWrapper);
}
}
}
// All nodes were visited but the target was not foundreturnnull;Code-Sprache:Java(java)
Den Code versteht man am besten, wenn man ihn sich Block für Block mitsamt der Kommentare anschaut.
Backtrace: Bestimmung des Weges vom Start zum Ziel
In dem mit „Have we reached the target?“ kommentierten if-Block wird die Methode buildPath() aufgerufen. Diese folgt den Vorgängern vom Zielknoten zurück zum Startknoten, trägt dabei alle Knoten in eine Liste ein und gibt diese in umgekehrter Reihenfolge zurück:
Die vollständige findShortestPath()-Methode findest Du in der Klasse AStarWithTreeSet im GitHub-Repository. Aufrufen kannst Du die Methode dann beispielsweise so:
Dieses und andere Beispiele findest du in der Klasse TestWithSampleGraph im GitHub-Repository.
Kommen wir nun zur Zeitkomplexität.
Zeitkomplexität des A*-Algorithmus
Zur Bestimmung der Zeitkomplexität des A*-Algorithmus schauen wir uns den Code Block für Block an, bestimmen für jeden Block die Teilkomplexität und addieren diese im Anschluss.
Wir bezeichnen dabei die Anzahl der Knoten des Graphes mit n und die Anzahl der Kanten mit m.
Die Berechnung der maximalen Geschwindigkeit im Graphen brauchen wir hier nicht zu berücksichtigen, da diese pro Graph nur einmalig erfolgen muss und dann als Teil der Graphdaten gespeichert werden kann.
Einfügen des Startknotens in die Tabelle: Der Aufwand ist unabhängig von der Größe des Graphen, also konstant – O(1).
Entnehmen der Knoten aus der Tabelle: Der Aufwand für das Entnehmen des kleinsten Elements der Tabelle ist abhängig von der verwendeten Datenstruktur – wir bezeichnen ihn mit Tem („extract minimum“). Jeder Knoten wird maximal einmal entnommen, die Komplexität beträgt also O(n · Tem).
Prüfen, ob der kürzeste Pfad zu einem Knoten bereits gefunden wurde: Für jeden Knoten im Graph erfolgt diese Prüfung maximal einmal für alle angrenzenden Knoten. Die Anzahl der angrenzenden Knoten entspricht der Anzahl von wegführenden Kanten. Da jede Kante genau an zwei Knoten angrenzt, gibt es doppelt so viele wegführende Kanten wie Knoten, also 2 · m. Für die Prüfung verwenden wir ein Set, sie erfolgt also in konstanter Zeit. Insgesamt kommen wir also auf eine Komplexität von O(2 · m) = O(m).
Berechnung der Gesamtkosten vom Start: Die Berechnung ist eine einfache Addition und hat damit den Aufwand O(1). Die Berechnung erfolgt maximal einmal pro Kante, da wir jeder Kante maximal einmal folgen. Die Komplexität ist also auch für diesen Block O(m).
Zugriff auf NodeWrapper: Der Zugriff auf die Lookup-Map für NodeWrapper erfolgt jeweils nach Berechnung der Gesamtkosten. Der Zugriff ist ebenfalls konstant, die Komplexität für diesen Schritt also auch O(m).
Berechnung der Heuristik: Die Heuristik-Funktion ist mit konstantem Aufwand berechenbar. Sie muss maximal einmal pro Knoten durchgeführt werden. Die Komplexität beträgt also O(n).
Einfügen in die Tabelle: Der Aufwand für das Einfügen ist – genau wie der Aufwand für das Entnehmen – abhängig von der verwendeten Datenstruktur. Wir bezeichnen ihn mit Ti („insert“). Jeder Knoten wird maximal einmal eingefügt. Die Komplexität beträgt demnach O(n · Ti).
Aktualisieren der Gesamtkosten und damit der Kostensumme in der Tabelle: Auch dieser Aufwand hängt von der Datenstruktur ab. Beim TreeSet beispielsweise mussten wir den Knoten entnehmen und wieder einfügen. Andere Datenstrukturen (eine wirst du gleich kennenlernen) haben eine eigenständige Funktion hierfür. Wir bezeichnen den Aufwand allgemein mit Tdk („decrease key“). Die Funktion wird maximal so oft aufgerufen wie wir die Gesamtkosten vom Start berechnen, also maximal m mal. Die Komplexität für diesen Block lautet also O(m · Tdk).
Konstanter Aufwand O(1) kann vernachlässigt werden; ebenso sind O(m) gegenüber O(m · Tdk) vernachlässigbar und O(n) gegenüber O(n · Tem) und O(n · Ti). Wir können den Term daher kürzen zu O(n · Tem) + (n · Ti) + O(m · Tdk) und dann weiter zusammenfassen zu:
O(n · (Tem+Ti) + m · Tdk)
In den folgenden Abschnitten schauen wir uns an, was die Werte für Tem, Ti und Tdk für die verschiedenen Datenstrukturen sind – und was sich daraus für Gesamtkomplexitäten ergeben.
A*-Algorithmus mit TreeSet
Das im Quellcode verwendete TreeSet hat folgenden Komplexitäten (diese können der TreeSet-Dokumentation entnommen werden). Für ein besseres Verständnis gebe ich die T-Werte hier mit voller Bezeichnung an:
Kleinsten Eintrag entnehmen mit pollFirst(): TextractMinimum = O(log n)
Wert einfügen mit add(): Tinsert = O(log n)
Kosten verringen mit remove() und add(): TdecreaseKey = O(log n) + O(log n) = O(log n)
Wir setzen diese Werte in die allgemeine Formel des vorherigen Abschnitts ein und erhalten:
O(n · log n + m · log n)
Für den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist – in Landau-Notation: m ∈ O(n) – können wir m und n bei der Berechnung der Zeitkomplexität gleichsetzen.
Die Formel vereinfacht sich dann zu:
O(n · log n) – für m ∈ O(n)
Der Aufwand ist also quasilinear.
Bei der Verwendung von TreeSet ist zu beachten, dass dieses die Interface-Definition der remove()-Methode der Collection– und Set-Interfaces verletzt, da es das zu löschende Element nicht anhand der equals()-Methode identifiziert, sondern über die compareTo()-Methode. Es muss also sichergestellt sein, dass die compareTo()-Methode der verwendeten Knotenklasse dann – und nur dann – 0 zurückliefert, wenn auch die equals()-Methode true ergibt.
Laufzeit mit TreeSet
Mit dem Programm TestAStarRuntime können wir messen, wie lange der A*-Algorithmus benötigt, um in Graphen verschiedener Größen den kürzesten Weg zwischen zwei Punkten zu finden. Das Programm generiert zufällige Graphen und misst dann die Ausführungszeit von AStarWithTreeSet.findShortestPath().
Für jede Graphengröße werden 50 Tests mit unterschiedlichen Graphen durchgeführt und schließlich der Median der Messwerte ausgegeben. Das folgende Diagramm zeigt die Messungen der Laufzeit im Verhältnis zur Graphengröße für das TreeSet:
Zeitkomplexität des A*-Algorithmus mit TreeSet
Das vorhergesagte quasilineare Wachstum ist einigermaßen gut zu erkennen.
A*-Algorithmus mit PriorityQueue
Bei der Auswahl der Datenstruktur hatte ich bereits die gerne eingesetzte PriorityQueue angesprochen. Warum ist diese keine gute Wahl?
Kleinsten Eintrag entnehmen mit poll(): TextractMinimum = O(log n)
Wert einfügen mit offer(): Tinsert = O(log n)
Kosten verringen mit remove() und offer(): TdecreaseKey = O(n) + O(log n) = O(n)
Die ersten zwei Parameter, Tem und Ti gleichen denen des TreeSets.
Der dritte Parameter, Tdk hingegen ist bei der PriorityQueue allerdings O(n) – im Gegensatz zum deutlich günstigeren O(log n) beim TreeSet.
Was bedeutet das für die Zeitkomplexität des A*-Algorithmus? Wir tragen die Parameter in die allgemeine Formel O(n · (Tem+Ti) + m · Tdk) ein und erhalten:
O(n · (log n + log n) + m · n)
log n + log n ist 2 · log n, und Konstanten können wir weglassen. Der Term verkürzt sich somit auf:
O(n · log n + m · n)
Für den Sonderfall m ∈ O(n) (die Anzahl der Kanten ist ein Vielfaches der Anzahl der Knoten), können wir die Formel vereinfachen zu O(n · log n + n²). Neben dem quadratischen Anteil n² können wir den quasilinearen Anteil n · log n vernachlässigen. Es bleibt:
O(n²) – für m ∈ O(n)
Der Einsatz einer PriorityQueue führt also zu quadratischem Aufwand, einer deutlich schlechteren Komplexitätsklasse als quasilinearer Aufwand.
Laufzeit mit PriorityQueue
Wenn wir im Programm TestAStarRuntime in Zeile 79 die Klasse AStarWithTreeSet durch AStarWithPriorityQueue (Klasse in GitHub) ersetzen, können wir die Laufzeiten unter Verwendung der PriorityQueue messen.
Das folgende Diagramm zeigt das Messergebnis:
Zeitkomplexität des A*-Algorithmus mit PriorityQueue
Das quadratische Wachstum ist sehr gut zu erkennen.
A*-Algorithmus mit Fibonacci-Heap
Es gibt eine noch besser geeignete Datenstruktur: den Fibonacci-Heap. Dieser garantiert folgende Laufzeiten:
Diese Klasse und die entsprechende A*-Implementierung habe ich aus Copyright-Gründen nicht in mein Repository kopiert. Du kannst die Klasse unter dem angegebenen Link herunterladen und zur Übung selbst eine AStarWithFibonacciHeap-Klasse schreiben.
Mit dem Fibonacci-Heap erhalte ich folgende Messergebnisse:
Zeitkomplexität des A*-Algorithmus mit Fibonacci Heap
Der A*-Algorithmus ist also mit dem FibonacciHeap noch einmal leicht schneller als mit dem TreeSet.
Zeitkomplexität – Zusammenfassung
Die folgende Tabelle zeigt zusammengefasst die Zeitkomplexität des A*-Algorithmus in Abhängigkeit von der eingesetzten Datenstruktur:
Datenstruktur
Tem
Ti
Tdk
Zeitkomplexität allgemein
Zeitkomplexität für m ∈ O(n)
PriorityQueue
O(log n)
O(log n)
O(n)
O(n · log n + m · n)
O(n²)
TreeSet
O(log n)
O(log n)
O(log n)
O(n · log n + m · log n)
O(n · log n)
FibonacciHeap
O(log n)
O(1)
O(1)
O(n · log n + m)
O(n · log n)
Zeitkomplexität A*-Algorithmus vs. Dijkstras Algorithmus
Die Zeitkomplexitätsklassen bei A* sind die gleichen wie bei Dijkstra. Doch wie sieht es mit der Laufzeit aus?
Im folgenden Diagramm siehst du zusätzlich zu den oben gemessenen Laufzeiten diejenigen des Dijkstra-Algorithmus aus dem vorherigen Artikel:
Zeitkomplexität des A*-Algorithmus verglichen mit Dijkstras Algorithmus
Die Laufzeiten sind beim A*-Algorithmus also deutlich besser (zwischen Faktor 2 und 4). Dies ist allerdings keine allgemeingültige Aussage. Ob und inwieweit A* schneller ist als Dijkstra hängt stark von der Struktur des Graphen ab. Für Straßenkarten ist A* in der Regel deutlich schneller.
In einem Labyrinth, in dem der kürzeste Weg oft nicht in die direkte Richtung zum Ziel führt, kann das ganz anders aussehen.
Zusammenfassung und Ausblick
Dieser Artikel hat an einem Beispiel, mit einer informellen Beschreibung und mit Java-Quellcode gezeigt, wie der A*-Algorithmus funktionert.
Für die Zeitkomplexität haben wir zunächst eine allgemeine Landau-Notation hergeleitet und diese anschließend für die Datenstrukturen TreeSet, PriorityQueue und FibonacciHeap konkretisiert.
Die Zeitkomplexitäten entsprechen denen des Dijkstra-Algorithmus; die Laufzeiten sind bei A* deutlich besser als bei Dijkstra. Wenn eine Heuristik-Funktion definiert werden kann und der schnellste Weg in der Regel grob in die Richtung des Ziels führt, ist also immer der A*-Algorithmus vorzuziehen.
Vorschau: Bellman-Ford-Algorithmus
Es gibt allerdings auch Situationen, in denen weder Dijkstra noch A* ein geeigneter Algorithmus sind: Wenn es Kanten mit negativen Gewichten gibt, würden Dijkstra und A* diese ignorieren, wenn diese auf einen Knoten folgen würden, zu dem die Kosten höher sind als die eines bereits entdeckten Weges zum Ziel.
Wie negative Kantengewichte in der Realität (und nicht nur in einem konstruierten mathematischen Modell) überhaupt existieren können – und wie man das Kürzeste-Wege-Problem in so einem Fall löst, erfährst Du im nächsten Artikel über den Bellman-Ford-Algorithmus.
Wie findet ein Navigationssystem den kürzesten Weg vom Start zum Ziel in möglichst geringer Zeit? Dieser Frage (und ähnlichen) geht diese Artikelserie über „Shortest Path“-Algorithmen nach.
Dieser Teil behandelt den Dijkstra-Algorithmus (englisch: „Dijkstra’s algorithm“) – benannt nach dessen Erfinder, Edsger W. Dijkstra. Dijkstras Algorithmus findet in einem Graphen zu einem gegebenen Startknoten die kürzeste Entfernung zu allen anderen Punkten (oder zu einem vorgegebenen Endpunkt).
Die Themen des Artikels im Einzelnen:
Schritt-für-Schritt-Beispiel zur Erklärung der Funktionsweise des Algorithmus
Quellcode des Dijkstra-Algorithmus (mit PriorityQueue)
Bestimmung der Zeitkomplexität des Algorithmus
Messung der Laufzeit – mit PriorityQueue, TreeSet und FibonacciHeap
Fangen wir an mit dem Beispiel!
Dijkstras Algorithmus – Beispiel
Den Dijkstra-Algorithmus erklärt man am besten an einem Beispiel. Die folgende Grafik zeigt eine fiktive Straßenkarte. Orte werden durch Kreise mit Buchstaben dargestellt; die Linien sind Straßen und Wege, die diese Orte verbinden.
Straßenkarte
Die dicken Linien stellen eine Schnellstraße dar; die etwas dünneren Linien sind die Landstraßen, und die gestrichelten Linien sind schwer passierbare Feldwege.
Die Straßenkarte bilden wir nun auf einen Graphen ab. Dörfer werden dabei zu Knoten, Straßen und Wege werden zu Kanten.
Die Gewichte der Kanten geben an, wie viele Minuten es dauert von einem Ort zum anderen zu kommen. Dabei spielt sowohl die Länge als auch die Beschaffenheit der Wege eine Rolle, d. h. eine lange Hauptstraße ist möglicherweise schneller passierbar als ein deutlich kürzerer Feldweg.
Es ergibt sich folgender Graph:
Straßenkarte als gewichteter Graph
Aus dem Graph kann man nun z. B. ablesen, dass der Weg von D nach H auf der kürzesten Strecke – also auf dem Feldweg über Knoten F – 11 Minuten dauert (gelb hinterlegte Strecke). Über die deutlich längere Route über die Land- und Schnellstraßen über Knoten C und G (blaue Strecke) dauert es nur 9 Minuten:
Straßenkarte: schnellster Weg und kürzester Weg
Das menschliche Gehirn ist sehr gut darin, solche Muster zu erkennen. Einem Computer müssen wir dies erst mit geeigneten Mitteln beibringen. Hier kommt der Dijkstra-Algorithmus ins Spiel.
Vorbereitung – Tabelle der Knoten
Zuerst müssen wir einige Vorbereitungen treffen: Wir erstellen eine Tabelle der Knoten mit zwei zusätzlichen Attributen: Vorgänger-Knoten und Gesamtdistanz zum Startknoten. Die Vorgänger-Knoten bleiben zunächst leer; die Gesamtdistanz zum Startknoten wird im Startknoten selbst auf 0 gesetzt, in allen anderen Knoten auf ∞ (unendlich).
Die Tabelle wird nach Gesamtdistanz zum Startknoten aufsteigend sortiert, d. h. der Startknoten selbst (Knoten D) steht ganz vorne in der Tabelle; die übrigen Knoten sind unsortiert. Im Beispiel belassen wir sie in alphabetischer Reihenfolge:
Knoten
Vorgänger
Gesamtdistanz
D
–
0
A
–
∞
B
–
∞
C
–
∞
E
–
∞
F
–
∞
G
–
∞
H
–
∞
I
–
∞
Im folgenden ist es wichtig die Begriffe Distanz und Gesamtdistanz zu unterscheiden:
Distanz bezeichnet die Distanz von einem Knoten zu seinen Nachbarknoten;
Gesamtdistanz bezeichnet die Summe aller Teildistanzen vom Startknoten über eventuelle Zwischenknoten zu einem bestimmten Knoten.
Dijkstras Algorithmus Schritt für Schritt – Abarbeitung der Knoten
In den folgenden Darstellungen der Graphen werden Vorgänger der Knoten und Gesamtdistanz mit angezeigt. Diese Daten sind in der Regel nicht im Graph selbst enthalten, sondern ausschließlich in der oben beschriebenen Tabelle. Ich zeige sie hier mit an, um das Verständnis zu erleichtern.
Schritt 1: Betrachten aller Nachbarn des Startpunkts
Nun entnehmen wir das erste Element – Knoten D – aus der Liste und betrachten dessen Nachbarn, also C, E und F.
Von D aus erreichbare Knoten
Da die Gesamtdistanz in all diesen Nachbarn noch unendlich ist (d. h. wir haben noch keinen Weg dorthin entdeckt), setzen wir die Gesamtdistanz der Nachbarn auf die Distanz von D zum jeweiligen Nachbarn und tragen jeweils D als Vorgänger ein.
Gesamtdistanz und Vorgänger der Knoten C, E, F wurden aktualisiert
Die Liste sortieren wir wieder nach Gesamtdistanz (die geänderten Einträge sind fett hervorgehoben):
Knoten
Vorgänger
Gesamtdistanz
E
D
1
C
D
3
F
D
4
A
–
∞
B
–
∞
G
–
∞
H
–
∞
I
–
∞
Die Liste ist so zu lesen: Knoten E, C und F sind entdeckt und können über D in 1, 3 bzw. 4 Minuten erreicht werden.
Schritt 2: Betrachten aller Nachbarn von Knoten E
Nun wiederholen wir, was wir eben für den Startknoten D getan haben, für den nächsten Knoten der Liste, Knoten E. Wir entnehmen E und betrachten dessen Nachbarn A, B, D und F:
Von E aus erreichbare Knoten
Für Knoten A und B ist die Gesamtdistanz nach wie vor unendlich. Daher setzen wir deren Gesamtdistanz auf die Gesamtdistanz des aktuellen Knotens E (also 1) plus der Distanz von E zum jeweiligen Knoten:
Knoten D ist in der Tabelle nicht mehr enthalten. Das bedeutet, dass der kürzeste Weg dorthin bereits entdeckt wurde (es ist der Startknoten). Wir brauchen den Knoten daher nicht weiter zu betrachten.
Hier noch einmal der Graph mit aktualisierten Einträgen für A und B:
Gesamtdistanz und Vorgänger der Knoten A, B wurden aktualisiert
Zu Knoten F ist bereits eine Gesamtdistanz eingetragen (4 über Knoten D). Um zu prüfen, ob F über den aktuellen Knoten E schneller erreicht werden kann, berechnen wir die Gesamtdistanz zu F über E:
Wir vergleichen diese Gesamtdistanz mit der für F eingetragenen Gesamtdistanz. Die neu berechnete Gesamtdistanz 7 ist größer als die gespeicherte Gesamtdistanz 4. Der Weg über E ist also länger als der zuvor entdeckte. Er interessiert uns damit nicht weiter, und wir lassen den Tabelleneintrag für F unverändert.
Es ergibt sich folgender Zwischenstand in der Tabelle (die Änderungen sind fett hervorgehoben):
Knoten
Vorgänger
Gesamtdistanz
C
D
3
F
D
4
A
E
4
B
E
6
G
–
∞
H
–
∞
I
–
∞
Die neuen Einträge sind so zu lesen: A und B wurden entdeckt; A ist über Knoten E in insgesamt 4 Minuten erreichbar, B ist über Knoten E in insgesamt 6 Minuten erreichbar.
Schritt 3: Betrachten aller Nachbarn von Knoten C
Wir wiederholen den Prozess für den nächsten Knoten in der Liste: Knoten C. Wir entfernen ihn aus der Liste und betrachten dessen Nachbarn, A, D und G:
Von C aus erreichbare Knoten
Knoten D wurde bereits aus der Liste entfernt und wird ignoriert.
Wir berechnen die Gesamtdistanzen über C zu A und G:
Knoten A
3 (kürzeste Gesamtdistanz zu C) + 2 (Distanz C–A) = 5
Knoten G
3 (kürzeste Gesamtdistanz zu C) + 2 (Distanz C–G) = 5
Für A ist bereits ein kürzerer Weg über E mit Gesamtdistanz 4 eingetragen. Wir ignorieren also den neu entdeckten Weg über C zu A mit der größeren Gesamtdistanz 5 und lassen den Tabelleneintrag für A unverändert.
Knoten G hat noch die Gesamtdistanz unendlich. Wir tragen daher für G Gesamtdistanz 5 via Vorgänger C ein:
Gesamtdistanz und Vorgänger von Knoten G wurde aktualisiert
G hat nun eine kürzere Gesamtdistanz als B und rutscht in der Tabelle eine Position nach oben:
Knoten
Vorgänger
Gesamtdistanz
F
D
4
A
E
4
G
C
5
B
E
6
H
–
∞
I
–
∞
Schritt 4: Betrachten aller Nachbarn von Knoten F
Wir entfernen den nächsten Knoten der Liste, F, und betrachten dessen Nachbarn D, E und H:
Von F aus erreichbare Knoten
Zu Knoten D und E wurden die kürzesten Wege bereits entdeckt; wir müssen die Gesamtdistanz über den aktuellen Knoten F also nur für H berechnen:
Knoten H hat noch die Gesamtdistanz unendlich; wir tragen daher als Vorgänger den aktuellen Knoten F und als Gesamtdistanz 11 ein:
Gesamtdistanz und Vorgänger von Knoten H wurde aktualisiert
H ist unser Zielknoten. Wir haben also einen Weg zum Ziel gefunden, mit der Gesamtdistanz 11. Wir wissen allerdings noch nicht, ob dies der kürzeste Weg ist. Wir haben in der Tabelle noch drei weitere Knoten mit kürzeren Gesamtdistanz als 11: A, G und B:
Knoten
Vorgänger
Gesamtdistanz
A
E
4
G
C
5
B
E
6
H
F
11
I
–
∞
Eventuell gibt es ja von einem dieser Knoten noch einen kurzen Weg zum Ziel, über den wir auf eine Gesamtdistanz von weniger als 11 kommen könnten.
Wir müssen daher den Prozess so lange weiterführen, bis es in der Tabelle keine Einträge vor dem Zielknoten H gibt.
Schritt 5: Betrachten aller Nachbarn von Knoten A
Wir entfernen Knoten A und betrachten dessen Nachbarn C und E:
Von A aus erreichbare Knoten
Beide sind nicht mehr in der Tabelle enthalten, für beide wurden also bereits die kürzesten Wege entdeckt – wir können sie somit ignorieren. Über Knoten A führt also kein Weg zum Ziel. Damit ist Schritt 6 beendet.
Schritt 6: Betrachten aller Nachbarn von Knoten G
Wir entnehmen Knoten G und betrachten dessen Nachbarn C und H:
Von G aus erreichbare Knoten
C wurde bereits bearbeitet; es bleibt die Berechnung der Gesamtdistanz zu Knoten H über G:
Knoten H hat aktuell eine Gesamtdistanz von 11 über Knoten F. In Schritt 5 hatten wir den entsprechenden Weg entdeckt. Mit einer Gesamtdistanz von 9 haben wir nun einen kürzeren Weg gefunden! Wir ersetzen daher in H die 11 durch 9 und den bisherigen Vorgänger F durch den aktuellen Knoten G:
Gesamtdistanz und Vorgänger von Knoten H wurde aktualisiert
Die Tabelle sieht nun so aus:
Knoten
Vorgänger
Gesamtdistanz
B
E
6
H
G
9
I
–
∞
Über Knoten B könnten wir einen noch kürzeren Weg zum Ziel finden, wir müssen also zuletzt auch noch diesen betrachten.
Schritt 7: Betrachten aller Nachbarn von Knoten B
Wir entnehmen also Knoten B und schauen uns dessen Nachbarn E und I an:
Von B aus erreichbare Knoten
Zu E wurde der kürzeste Weg bereits entdeckt; für I berechnen wir die Gesamtdistanz über B:
Knoten I
6 (kürzeste Gesamtdistanz zu B) + 15 (Distanz B–I) = 21
Wir tragen für Knoten I die berechnete Gesamtdistanz und den aktuellen Knoten als Vorgänger ein:
Gesamtdistanz und Vorgänger von Knoten I wurde aktualisiert
In der Tabelle bleibt I hinter H:
Knoten
Vorgänger
Gesamtdistanz
H
G
9
I
B
21
Kürzester Weg zum Ziel wurde gefunden
Der erste Eintrag der Liste ist nun unser Zielknoten H. Es sind keine unentdeckten Knoten mit kürzerer Gesamtdistanz mehr vorhanden, von denen aus wir einen noch kürzeren Weg finden könnten.
Wir können aus der Tabelle ablesen: Der kürzeste Weg zum Zielknoten H führt über G und hat eine Gesamtdistanz von 9.
Backtrace zur Bestimmung des vollständigen Weges
Doch wie bestimmen wir den vollständigen Weg vom Startknoten D zum Zielknoten H? Dazu müssen wir uns Schritt für Schritt an den Vorgängern entlanghangeln.
Diesen sogenannten „Backtrace“ führen wir anhand der in der Tabelle gespeicherten Vorgängerknoten durch. Der Übersicht halber stelle ich diese Daten hier noch einmal im Graphen dar:
Backtrace zur Bestimmung des vollständigen Weges
Der Vorgänger des Zielknotens H ist G; der Vorgänger von G ist C; und der Vorgänger von C ist der Startpunkt D. Der kürzeste Weg lautet also: D–C–G–H.
Kürzeste Wege zu allen Knoten finden
Wenn wir den Algorithmus an dieser Stelle nicht abbrechen, sondern solange fortfahren, bis die Tabelle nur noch einen einzigen Eintrag enthält, haben wir die kürzesten Wege zu allen Knoten gefunden!
Im Beispiel müssen wir dazu nur noch die Nachbarknoten von Knoten H betrachten – G und I:
Von H aus erreichbare Knoten
Knoten G wurde bereits abgearbeitet; wir berechnen die Gesamtdistanz zu I über H:
Erstelle eine Tabelle aller Knoten mit Vorgängerknoten und Gesamtdistanz.
Setze die Gesamtdistanz des Startknotens auf 0 und die aller anderer Knoten auf unendlich.
Abarbeitung der Knoten:
Solange die Tabelle nicht leer ist, entnehme das Element mit der kleinsten Gesamtdistanz und mache damit folgendes:
Ist das entnommene Element der Zielknoten? Wenn ja, ist die Abbruchbedingung erfüllt. Folge dann den Vorgängerknoten zurück zum Startknoten, um den kürzesten Weg zu bestimmen.
Andersfalls betrachte alle Nachbarknoten des entnommenen Elements, die sich noch in der Tabelle befinden. Für jeden Nachbarknoten:
Berechne die Gesamtdistanz als Summe der Gesamtdistanz des entnommenen Knotens plus der Distanz zum betrachteten Nachbarknoten.
Ist diese Gesamtdistanz kürzer als die bisher gespeicherte, setze den Vorgänger des Nachbarknotens auf den entnommenen Knoten und die Gesamtdistanz auf die neu berechnete.
Dijkstras Algorithmus – Java-Quellcode mit PriorityQueue
Wie implementiert man Dijkstras Algorithmus am besten in Java?
Im folgenden stelle ich dir den Quellcode Schritt für Schritt vor. Den vollständigen Code findest Du in meinem GitHub-Repository. Die einzelnen Klassen sind im folgenden ebenfalls verlinkt.
Datenstruktur für den Graph: Guava ValueGraph
Als allererstes benötigen wir eine Datenstruktur, die den Graph, also die Knoten und die sie verbindenden Kanten mit ihren Gewichten speichert.
Hierfür eignet sich beispielsweise der ValueGraph der Google Core Libraries for Java. Die verschiedenen Typen von Graphen, die die Library bereitstellt, werden hier erläutert.
Einen ValueGraph, der dem Beispiel oben entspricht, können wir wie folgt erstellen (Klasse TestWithSampleGraph im GitHub-Repository):
Typ der Knoten: in unserem Fall String für die Knotennamen „A“ bis „I“
Typ der Kantenwerte: in unserem Fall Integer für die Entfernungen zwischen den Knoten
Da der Graph ungerichtet ist, spielt die Reihenfolge, in der die Knoten angegeben werden, keine Rolle.
Datenstruktur: Knoten, Gesamtdistanz und Vorgänger
Neben dem Graph benötigen wir eine Datenstruktur, die die Knoten und die zugehörige Gesamtdistanz vom Startpunkt sowie den Vorgängerknoten aufnimmt. Hierfür erstellen wir den folgenden NodeWrapper (Klasse im GitHub-Repository). Die Typvariable N ist dabei der Typ der Knoten – in unserem Beispiel wird das String sein für die Knotennamen.
classNodeWrapper<N> implementsComparable<NodeWrapper<N>> {
privatefinal N node;
privateint totalDistance;
private NodeWrapper<N> predecessor;
NodeWrapper(N node, int totalDistance, NodeWrapper<N> predecessor) {
this.node = node;
this.totalDistance = totalDistance;
this.predecessor = predecessor;
}
// getter for node// getters and setters for totalDistance and predecessor@OverridepublicintcompareTo(NodeWrapper<N> o){
return Integer.compare(this.totalDistance, o.totalDistance);
}
// equals(), hashCode()
}Code-Sprache:Java(java)
Der NodeWrapper implementiert das Comparable-Interface: über die compareTo()-Methode definieren wir die natürliche Ordnung derart, dass NodeWrapper-Objekte entsprechend der Gesamtentfernung aufsteigend sortiert werden.
Der in den folgenden Abschnitten gezeigte Code bildet die findShortestPath()-Methode der Klasse DijkstraWithPriorityQueue (Klasse in GitHub).
Datenstruktur: PriorityQueue als Tabelle
Des Weiteren benötigen wir eine Datenstruktur für die Tabelle.
Hierfür wird häufig eine PriorityQueue verwendet. Die PriorityQueue hält am Kopf immer das kleinste Element bereit, welches wir mit der poll()-Methode entnehmen können. Die natürliche Ordnung der NodeWrapper-Objekte wird später dafür sorgen, dass poll() immer denjenigen NodeWrapper mit der geringsten Gesamtdistanz zurückliefert.
Tatsächlich ist die PriorityQueuenicht die optimale Datenstruktur. Ich werde sie dennoch vorerst einsetzen. Später im Abschnitt „Laufzeit mit PriorityQueue“ werde ich die Performance der Implementierung messen, dann erklären, warum die PriorityQueue zu einer schlechten Performance führt – und schließlich eine besser geeignete Datenstruktur mit einer um Größenordnungen besseren Performance zeigen.
PriorityQueue<NodeWrapper<N>> queue = new PriorityQueue<>();Code-Sprache:Java(java)
Datenstruktur: Lookup Map für NodeWrapper
Wir benötigen außerdem eine Map, die uns für einen Knoten des Graphen den entsprechenden NodeWrapper liefert. Hierfür eignet sich eine HashMap:
Map<N, NodeWrapper<N>> nodeWrappers = new HashMap<>();Code-Sprache:Java(java)
Datenstruktur: Erledigte Knoten
Wir müssen im Verlauf des Algorithmus prüfen können, ob wir einen Knoten bereits erledigt haben, d. h. den kürzesten Weg dorthin gefunden haben. Dafür eignet sich ein HashSet:
Set<N> shortestPathFound = new HashSet<>();Code-Sprache:Java(java)
Vorbereitung: Füllen der Tabelle
Kommen wir zum ersten Schritt des Algorithmus, dem Füllen der Tabelle.
Hier optimieren wir direkt ein bisschen. Wir brauchen nämlich gar nicht alle Knoten in die Tabelle zu schreiben – es reicht der Startknoten. Die weiteren Knoten schreiben wir erst dann in die Tabelle, wenn wir einen Weg dorthin finden.
Dies hat zwei Vorteile:
Wir sparen uns Tabelleneinträge für Knoten, die vom Startpunkt entweder gar nicht erreichbar sind – oder nur über solche Zwischenknoten, die vom Startpunkt weiter entfernt sind als das Ziel.
Wenn wir im späteren Verlauf die Gesamtdistanz eines Knotens berechnen, wird dieser in der PriorityQueuenicht automatisch umsortiert. Stattdessen muss man den Knoten entfernen und wieder einfügen. Da für alle entdeckten Knoten die Gesamtdistanz kleiner als unendlich sein wird, werden wir dementsprechend auch alle Knoten wieder aus der Queue entfernen und sie neu einfügen müssen. Auch dies können wir uns sparen, wenn wir die Knoten in der Vorbereitungsphase gar nicht erst einfügen.
Wir verpacken also zunächst nur unseren Startknoten in ein NodeWrapper-Objekt (mit Gesamtdistanz 0 und ohne Vorgänger) und fügen dieses in die Lookup-Map und die Tabelle ein:
NodeWrapper<N> sourceWrapper = new NodeWrapper<>(source, 0, <strong>null</strong>);
nodeWrappers.put(source, sourceWrapper);
queue.add(sourceWrapper);Code-Sprache:Java(java)
Iteration über alle Knoten
Kommen wir zum Herzen des Algorithmus: der schrittweisen Abarbeitung der Tabelle (bzw. der Queue, die wir als Datenstruktur für die Tabelle gewählt haben):
while (!queue.isEmpty()) {
NodeWrapper<N> nodeWrapper = queue.poll();
N node = nodeWrapper.getNode();
shortestPathFound.add(node);
// Have we reached the target? --> Build and return the pathif (node.equals(target)) {
return buildPath(nodeWrapper);
}
// Iterate over all neighbors
Set<N> neighbors = graph.adjacentNodes(node);
for (N neighbor : neighbors) {
// Ignore neighbor if shortest path already foundif (shortestPathFound.contains(neighbor)) {
continue;
}
// Calculate total distance to neighbor via current nodeint distance =
graph.edgeValue(node, neighbor).orElseThrow(IllegalStateException::new);
int totalDistance = nodeWrapper.getTotalDistance() + distance;
// Neighbor not yet discovered?
NodeWrapper<N> neighborWrapper = nodeWrappers.get(neighbor);
if (neighborWrapper == <strong>null</strong>) {
neighborWrapper = new NodeWrapper<>(neighbor, totalDistance, nodeWrapper);
nodeWrappers.put(neighbor, neighborWrapper);
queue.add(neighborWrapper);
}
// Neighbor discovered, but total distance via current node is shorter?// --> Update total distance and predecessorelseif (totalDistance < neighborWrapper.getTotalDistance()) {
neighborWrapper.setTotalDistance(totalDistance);
neighborWrapper.setPredecessor(nodeWrapper);
// The position in the PriorityQueue won't change automatically;// we have to remove and reinsert the node
queue.remove(neighborWrapper);
queue.add(neighborWrapper);
}
}
}
// All reachable nodes were visited but the target was not foundreturn <strong>null</strong>;Code-Sprache:Java(java)
Der Code sollte dank der Kommentare keiner weiteren Erklärung bedürfen.
Backtrace: Bestimmung des Weges vom Start zum Ziel
Wenn der aus der Queue entnommene Knoten der Zielknoten ist (Block „Have we reached the target?“ in der while-Schleife oben), wird die Methode buildPath() aufgerufen. Diese folgt dem Pfad entlang der Vorgänger rückwärts vom Ziel- zum Startknoten, schreibt dabei die Knoten in eine Liste und gibt diese in umgekehrter Reihenfolge zurück:
Die createSampleGraph()-Methode hatte ich am Anfang dieses Kapitels gezeigt.
Kommen wir als nächstes zur Zeitkomplexität.
Zeitkomplexität von Dijkstras Algorithmus
Um die Zeitkomplexität des Algorithmus zu bestimmen, schauen wir uns den Code blockweise an. Im folgenden bezeichnen wir mit m die Anzahl der Kanten und mit n die Anzahl der Knoten.
Einfügen des Startknotens in die Tabelle: Der Aufwand ist unabhängig von der Größe des Graphen, also konstant: O(1).
Entnehmen der Knoten aus der Tabelle: Jeder Knoten wird maximal einmal aus der Tabelle entnommen. Der Aufwand hierfür hängt von der verwendeten Datenstruktur ab; wir bezeichnen ihn mit Tem („extract minimum“). Der Aufwand für alle Knoten ist somit O(n · Tem).
Prüfen, ob der kürzeste Pfad zu einem Knoten bereits gefunden wurde: Diese Prüfung erfolgt für jeden Knoten und alle Kanten, die von diesen wegführen. Da jede Kante an zwei Knoten anschließt, geschieht dies also maximal zweimal pro Kante, also 2m mal. Da wir für die Prüfung ein Set verwenden, erfolgt dies mit konstantem Aufwand; für 2m Knoten beträgt der Gesamtaufwand damit O(m).
Berechnung der Gesamtdistanz: Die Gesamtdistanz wird maximal einmal pro Kante berechnet, da wir maximal einmal pro Kante einen neuen Weg zu einem Knoten finden. Die Berechnung selbst erfolgt mit konstantem Aufwand, der Gesamtaufwand für diesen Schritt ist somit auch O(m).
Zugriff auf NodeWrapper: Auch dies passiert mit konstantem Aufwand maximal einmal pro Kante; somit haben wir auch hier O(m).
Einfügen in die Tabelle: Jeder Knoten wird maximal einmal in die Queue eingetragen. Der Aufwand für das Eintragen hängt von der verwendeten Datenstruktur ab. Wir bezeichnen ihn mit Ti („insert“). Der Gesamtaufwand für alle Knoten ist also O(n · Ti).
Aktualisieren der Gesamtdistanz in der Tabelle: Dies geschieht für jede Kante maximal einmal; es gilt die gleiche Begründung wie bei der Berechnung der Gesamtdistanz. Wir haben dies im Quellcode durch Entfernen und Neueinfügen gelöst. Es gibt allerdings auch Datenstrukturen, die das in einem Schritt optimiert ausführen können. Wir bezeichnen daher den Aufwand hierfür allgemein Tdk („decrease key“). Für m Kanten also O(m · Tdk).
Den konstantem Aufwand O(1) können wir vernachlässigen; ebenso wird O(m) gegenüber O(m · Tdk) vernachlässigbar. Der Term verkürzt sich somit auf:
O(n · (Tem+Ti) + m · Tdk)
Wie die Werte für Tem, Ti, Tdk für die PriorityQueue und andere Datenstrukturen lauten – und was das für die Gesamtkomplexität bedeutet, erfährst du in den folgenden Abschnitten.
Dijkstra-Algorithmus mit PriorityQueue
Für die Java-PriorityQueue gelten folgende Werte, die man der Dokumentation der Klasse entnehmen kann. (Für ein leichteres Verständnis gebe ich die T-Parameter hier mit voller Schreibweise an.)
Kleinsten Eintrag entnehmen mit poll(): TextractMinimum = O(log n)
Wert einfügen mit offer(): Tinsert = O(log n)
Gesamtdistanz verringen mit remove() und offer(): TdecreaseKey = O(n) + O(log n) = O(n)
Setzen wir diese Werte in die Formel von oben ein – Tem+Ti = log n + log n können wir dabei zu einmal log n zusammenfassen – dann ergibt sich:
O(n · log n + m · n)
Für den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist – in Landau-Notation: m ∈ O(n) – können m und n bei der Betrachtung der Zeitkomplexität gleichgesetzt werden. Dann vereinfacht sich die Formel zu O(n · log n + n²). Der quasilineare Anteil kann neben dem quadratischen vernachlässigt werden, und es bleibt:
O(n²) – für m ∈ O(n)
Genug der Theorie … im nächsten Abschnitt prüfen wir unsere Annahme in der Praxis!
Laufzeit mit PriorityQueue
Um zu prüfen, ob die theoretisch bestimmte Zeitkomplexität korrekt ist, habe ich das Programm TestDijkstraRuntime geschrieben. Dieses erstellt zufällige Graphen verschiedener Größen von 10.000 bis etwa 300.000 Knoten und sucht darin den kürzesten Weg zwischen zwei zufällig ausgewählten Knoten.
Die Graphen enthalten jeweils viermal so viele Kanten wie Knoten. Dies soll einer Straßenkarte nahe kommen, auf der im Mittel grob geschätzt vier Straßen von jeder Kreuzung wegführen.
Jeder Test wird 50 mal wiederholt; folgende Grafik zeigt den Median der gemessenen Zeiten im Verhältnis zur Graphengröße:
Zeitkomplexität von Dijkstras Algorithmus mit PriorityQueue
Das vorhergesagte quadratische Wachstum ist gut zu erkennen – unsere Herleitung der Zeitkomplexität von O(n²) war also korrekt.
Dijkstra-Algorithmus mit TreeSet
Wir haben bei der Bestimmung der Zeitkomplexität erkannt, dass die PriorityQueue.remove()-Methode eine Zeitkomplexität von O(n) hat. Dies führt für den Gesamtalgorithmus zu quadratischem Aufwand.
Eine besser geeignete Datenstruktur ist das TreeSet. Dieses bietet uns mit der pollFirst()-Methode ebenfalls eine Möglichkeit das kleinste Element zu entnehmen. Für das TreeSet gelten laut Dokumentation folgende Laufzeiten:
Kleinsten Eintrag entnehmen mit pollFirst(): TextractMinimum = O(log n)
Wert einfügen mit add(): Tinsert = O(log n)
Gesamtdistanz verringen mit remove() und add(): TdecreaseKey = O(log n) + O(log n) = O(log n)
Setzen wir diese Werte in die allgemeine Formel O(n · (Tem+Ti) + m · Tdk) ein, erhalten wir:
O(n · log n + m · log n)
Betrachten wir wieder den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist, m und n also gleichgesetzt werden können, kommen wir auf:
O(n · log n) – für m ∈ O(n)
Bevor wir dies in der Praxis überprüfen, zunächst noch ein paar Anmerkungen zum TreeSet.
Nachteil des TreeSet
Das TreeSet ist beim Hinzufügen und Entnehmen von Elementen etwas langsamer als die PriorityQueue, da es intern eine TreeMap verwendet. Diese wiederum arbeitet mit einem Rot-Schwarz-Baum, welcher mit Knotenobjekten und Referenzen arbeitet, während der in der PriorityQueue verwendete Heap auf ein Array gemappt ist.
Bei ausreichend großen Graphen fällt dies jedoch nicht mehr ins Gewicht, wie wir in den folgenden Messungen sehen werden.
TreeSet verletzt die Interface-Definition!
Eine Sache müssen wir beim Einsatz des TreeSets beachten: Es verletzt die Schnittstellendefinition der remove()-Methode sowohl des Collection– als auch des Set-Interfaces!
Und zwar prüft das TreeSet auf Gleichheit zweier Objekte nicht – wie in Java sonst üblich und wie in der Interface-Methode spezifiziert – mittels der equals()-Methode, sondern über Comparable.compareTo() – bzw. Comparator.compare() bei Verwendung eines Comparators. Zwei Objekte werden als gleich angesehen, wenn compareTo() bzw. compare() 0 zurückliefert.
Dies ist beim Löschen von Elementen in zweierlei Hinsicht relevant:
Wenn es mehrere Knoten mit derselben Gesamtdistanz gibt, könnte beim Versuch solch einen Knoten zu entfernen „versehentlich“ ein anderer Knoten mit gleicher Gesamtdistanz entfernt werden.
Wichtig ist außerdem, dass wir den Knoten entfernen, bevor wir dessen Gesamtdistanz ändern. Ansonsten wird die remove()-Methode ihn nicht mehr finden.
Implementierung: NodeWrapperForTreeSet
Deshalb müssen wir für die Verwendung eines TreeSets die compareTo()-Methode dahingehend erweitern, dass sie bei gleicher Gesamtdistanz auch noch den Knoten vergleicht.
Da dazu auch die Knoten (und damit der Typparameter N) das Interface Comparable implementieren müssen, legen wir eine neue Klasse NodeWrapperForTreeSet an (Klasse im GitHub-Repository):
Des weiteren müssen wir sicherstellen, dass wir als Knotentyp nur solche Klassen verwenden, bei denen compareTo() genau dann 0 liefert, wenn auch equals() die Objekte als gleich wertet. In unseren Beispielen verwenden wir String, was diese Forderung erfüllt.
Vollständiger Code in GitHub
Den Algorithmus mit TreeSet findest du in der Klasse DijkstraWithTreeSet im GitHub-Repository. Dieser unterscheidet sich in nur wenigen Punkten von DijkstraWithPriorityQueue:
Der Knotentyp N erweitert Comparable<N>.
Statt der PriorityQueue wird ein TreeSet erstellt.
Das erste Element wird mit pollFirst() entnommen anstatt mit poll().
Statt NodeWrapper wird NodeWrapperForTreeSet verwendet.
Sollten wir nicht Code-Duplikation vermeiden und die gemeinsame Funktionalität in einer einzigen Klasse unterbringen? Ja, wenn beide Varianten in der Praxis eingesetzt werden sollen. Hier sollen aber lediglich beide Ansätze verglichen werden.
Laufzeit mit TreeSet
Um die Laufzeit zu messen, brauchen wir nur in TestDijkstraRuntime in Zeile 71 die Klasse DijkstraWithPriorityQueue durch DijkstraWithTreeSet zu ersetzen.
Der folgende Graph zeigt das Testergebnis im Vergleich zur vorherigen Implementierung:
Zeitkomplexität von Dijkstras Algorithmus mit TreeSet
Das erwartete quasilineare Wachstum ist gut zu erkennen, die Zeitkomplexität ist wie vorhergesagt O(n · log n).
Dijkstra-Algorithmus mit Fibonacci-Heap
Eine noch besser geeignete, im JDK allerdings nicht verfügbare Datenstruktur ist der Fibonacci-Heap. Dessen Operationen weisen folgenden Laufzeiten auf:
In die allgemeine Formel O(n · (Tem+Ti) + m · Tdk) eingesetzt, ergibt das:
O(n · log n + m)
Für den Spezialfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist, kommen wir wie beim TreeSet auf quasilinearen Aufwand:
O(n · log n) – für m ∈ O(n)
Laufzeit mit Fibonacci-Heap
Mangels passender Datenstruktur im JDK, habe ich die Fibonacci-Heap-Impementierung von Keith Schwarz verwendet. Da ich den Code nicht einfach kopieren wollte, habe ich den entsprechenden Test nicht in mein GitHub-Repository hochgeladen. Das Ergebnis siehst du hier im Vergleich zu den zwei vorherigen Tests:
Zeitkomplexität von Dijkstras Algorithmus mit Fibonacci-Heap
Dijkstras Algorithmus ist mit Fibonacci-Heap also noch einmal einen Tick schneller als mit dem TreeSet.
Zeitkomplexität – Zusammenfassung
In der folgenden Tabelle findest du eine Übersicht der Zeitkomplexität von Dijkstras Algorithmus in Abhängigkeit der verwendeten Datenstruktur. Dijkstra selbst hatte den Algorithmus übrigens mit einem Array implementiert, dieses habe ich der Vollständigkeithalber ebenfalls mit aufgeführt:
Datenstruktur
Tem
Ti
Tdk
Zeitkomplexität allgemein
Zeitkomplexität für m ∈ O(n)
Array
O(n)
O(1)
O(1)
O(n² + m)
O(n²)
PriorityQueue
O(log n)
O(log n)
O(n)
O(n · log n + m · n)
O(n²)
TreeSet
O(log n)
O(log n)
O(log n)
O(n · log n + m · log n)
O(n · log n)
FibonacciHeap
O(log n)
O(1)
O(1)
O(n · log n + m)
O(n · log n)
Zusammenfassung und Ausblick
Dieser Artikel hat an einem Beispiel, mit einer informellen Beschreibung und mit Java-Quellcode gezeigt, wie Dijkstras Algorithmus funktionert.
Für die Zeitkomplexität wurde zunächst eine allgemeine Landau-Notation hergeleitet, und diese wurde für die Datenstrukturen PriorityQueue, TreeSet und FibonacciHeap konkretisiert.
Nachteil des Dijkstra-Algorithmus
Der Algorithmus hat allerdings ein Manko: Er folgt den Kanten in alle Richtungen, unabhängig davon, in welcher Richtung der Zielknoten liegt. Das Beispiel in diesem Artikel war recht klein, so dass dies nicht aufgefallen ist.
Schau dir einmal folgende Straßenkarte an:
Für Dijkstras Algorithmus ungeeigneter Graph
Die Strecken von A nach D und von D nach H sind Schnellstraßen; von D nach E führt ein schwer passierbarer Feldweg. Wenn wir jetzt von D nach E kommen wollen, sehen wir sofort, dass wir keine andere Wahl haben als diesen Feldweg zu nehmen.
Doch was macht der Dijkstra-Algorithmus?
Da dieser sich ausschließlich an Kantenlängen orientiert, prüft er die Knoten C und F (Gesamtdistanz 2), B und G (Gesamtdistanz 4) und A und H (Gesamtdistanz 6), bevor er sicher ist, keinen kürzeren Weg zu H zu finden als den direkten Weg mit der Länge 5.
Vorschau: A*-Suchalgorithmus
Es gibt eine Weiterentwicklung des Dijkstra-Algorithmus, die mit Hilfe einer Heuristik das Prüfen von Pfaden in die falsche Richtung vorzeitig beendet und trotzdem deterministisch den kürzesten Weg findet: der A*-Algorithmus (ausgesprochen „A Stern“ oder englisch „A Star“). Diesen stelle ich im nächsten Teil der Artikelserie vor.
Wie findet ein Navigationssystem den kürzesten Weg vom Start zum Ziel? Wie orientieren sich Bot-Gegner im Ego-Shooter? Diesen Problemstellungen geht diese Artikelserie über Shortest-Path-Algorithmen (und allgemeiner: Pathfinding-Algorithmen) nach.
Dieser erste Artikel behandelt folgende Themen:
Was ist der Unterschied zwischen „Shortest Path“ und „Pathfinding“?
Welche Shortest-Path-Algorithmen gibt es?
Beispiel: Wie findet man den kürzesten Weg zwischen zwei Punkten in einem Labyrinth?
Ein Shortest-Path-Algorithmus löst das Problem der Suche nach dem kürzesten Weg zwischen zwei Punkten in einem Graph (z. B. auf einer Straßenkarte). Der Begriff „kurz“ meint damit nicht unbedingt die physische Distanz. Es kann sich dabei beispielsweise auch um Zeit (Autobahnen werden bevorzugt) oder Kosten (Maut-Straßen werden gemieden) oder eine Kombination aus mehreren Faktoren handeln.
Graphen können sehr komplex sein und Millionen von Knoten und Kanten enthalten (beispielsweise in einer Videospiel-Welt, in der sich hunderte oder tausende Charaktere frei bewegen können), so dass die Suche nach dem optimalen Weg sehr aufwändig wäre.
Für bestimmte Anwendungsgebiete genügt es einen einigermaßen kurzen (oder sogar irgendeinen) Weg zu finden. Hier spricht man dann allgemein von Pathfinding.
Auf zweidimensionalen, in Kacheln unterteilte Karten, wie sie in frühen Computerspielen üblich waren, kann auch eine Form der Breitensuche – bekannt als Lee-Algorithmus – durchgeführt werden.
Eine optimierte Variante davon erläutere ich im verbleibenden Teil dieses Artikels an einem Beispiel mit Animationen und Java-Quellcode.
Labyrinth-Algorithmus: Wie findet man den kürzesten Weg in einem Labyrinth?
Mein persönliches Lieblingsbeispiel für die Lösung des Shortest-Path-Problems ist das Spiel „FatCat“ auf dem HP-85, einem Computer aus den 1980er Jahren, mit dem ich als Kind bei meinem Onkel experimentieren durfte.
„FatCat“ auf einem HP85-Emulator (Kassette „GamesPac2“)
Aufgabe war es (wie bei Pac-Man) eine Maus alle Käsestücke in einem Labyrinth fressen zu lassen, ohne selbst von der Katze gefressen zu werden. Das Schwierige dabei war (abgesehen von der Steuerung mit nur zwei Tasten zum Drehen der Maus nach links und rechts), dass die Katze (im Gegensatz zu den Geistern bei Pac-Man) immer auf dem kürzesten Weg zur Maus lief.
Lediglich durch ein Mauseloch, dass den linken und rechten Rand verband, konnte man der Katze ausweichen. Darüber hinaus konnte man die Maus einmal pro Leben an eine andere Stelle beamen – was insbesondere in Sackgassen hilfreich war:
Beamen an eine zufällige Zielposition
Ich hatte mich damals (ich war etwa zehn) schon für Programmierung interessiert und wollte das Spiel auf meinem C64 nachprogrammieren. Die Anzeige der Labyrinthe und die Steuerung der Maus hatte ich schnell implementiert. Doch die Berechnung des kürzesten Weges zwischen Katze und Maus bereitete mir monatelang Kopfzerbrechen.
Letztlich löste ich es – wie ich Jahre später in meinem Informatikstudium herausfinden sollte – mit einer Variante des Lee-Algorithmus. Ohne Kenntnis dieses Algorithmus hatte ich eine optimierte Variante davon entwickelt, die ich im Folgenden Schritt für Schritt vorstelle.
Optimierter Lee-Algorithmus
Der Lee-Algorithmus hat den Nachteil, dass man am Ende den gefundenen Weg zurückgehen muss („Backtrace“), um herauszufinden, welche Richtung die Katze einschlagen muss.
Außerdem spezifiziert der Algorithmus nicht, wie man „Felder, deren Nachbar mit i markiert ist“ findet. Es wäre unperformant in jedem Schritt das gesamte Labyrinth zu durchsuchen. An dieser Stelle verwende ich eine aus der Breitensuche bekannte Queue, um die jeweils im nächsten Schritt zu überprüfenden Felder zu speichern.
Die folgenden Grafiken und Animationen verwenden das oben gezeigte Labyrinth mit der Katze an Position (15,7) und der Maus an Position (11,5). Das Koordinatensystem startet an der linken oberen Ecke des Labyrinths mit (0,0).
Vorbereitung
Das Labyrinth wird in einem zweidimensionalen boolean-Array namens lab gespeichert. Wände werden durch den Wert true gekennzeichnet. Die äußere Wand mit in diesem Array abzuspeichern vereinfacht den Code, der so keine separaten Prüfungen auf das Erreichen des Randes benötigt.
boolean-Array „lab“
Um bei der Suche nicht im Kreis zu laufen, wird ein weiteres zweidimensionales boolean-Array mit dem Namen discovered erstellt, in dem diejenigen Felder markiert werden, die bei der Suche bereits entdeckt wurden. Die aktuelle Position der Katze wird darin initial auf true gesetzt.
Die Wände des Labyrinths habe ich etwas dunkler gefärbt, die Position der Katze ist rot markiert, die der Maus gelb. Diese Informationen sind im discovered-Array nicht enthalten. Sie werden im Folgenden mit angezeigt, um das Verständnis zu erleichtern.
boolean-Array „discovered“ mit markierter Katzenposition
Weiterhin wird die Queue für die als nächstes zu besuchenden Felder angelegt. In diese wird die aktuelle Position der Katze (15,7) ohne Richtungsangabe (daher „null“) eingefügt:
Pathfinding-Queue mit erstem Element: Position der Katze
Das soeben in die Queue gelegte Element (also die Startposition der Katze) wird wieder entnommen:
Pathfinding-Queue: erstes Element wieder entnommen
Dann werden alle von der Katze in einem Schritt erreichbaren Felder in die Queue geschrieben – mit ihren X- und Y-Koordinaten sowie der jeweiligen Richtung relativ zum Startpunkt:
Pathfinding-Queue: im ersten Schritt erreichbare Felder
Diese Felder werden ebenfalls als „entdeckt“ markiert:
boolean-Array „discovered“ mit im nächsten Schritt erreichbaren Feldern
Schritte 2 bis n
Solange die Queue nicht leer ist, wird nun jeweils ein Positions-Element entnommen und alle wiederum von dieser Position erreichbaren Felder in die Queue geschrieben – es sei denn sie sind bereits als „entdeckt“ markiert.
Dabei wird nicht die in diesem Schritt gegangene Richtung gespeichert, sondern die Richtung des entnommenen Elements kopiert. Denn wir wollen ja wissen, welche Richtung die Katze von ihrer Ausgangsposition aus einschlagen muss.
Das erste Element in der Queue ist die Position (15,6) oberhalb der Katze:
Pathfinding-Queue: Feld (15,6) entnommen
Von dieser Position sind wiederum die Felder darüber (15,5) und darunter (15,7) erreichbar:
Pathfinding: Von der Katze im zweiten Schritt erreichbare Felder
Das untere Feld (15,7) ist bereits als „entdeckt“ markiert (von dort sind wir gekommen) und wird ignoriert. Das obere Feld (15,5) wird in die Queue geschrieben und ebenfalls als „entdeckt“ markiert:
boolean-Array „discovered“ mit neu entdecktem Feld (15,5)Pathfinding-Queue: Feld (15,5) eingefügt
Dieser Prozess wird nun so lange wiederholt, bis die Position der Maus „entdeckt“ wurde. Die folgende Animation zeigt, wie sich das discovered-Array dabei nach und nach füllt:
Pathfinding: Entdecken der erreichbaren Felder
Abbruchbedingung
Sobald die Position der Maus erreicht wird, ist der Algorithmus beendet. Der zuletzt entnommene Queue-Eintrag zeigt die Richtung an, in die die Katze gehen muss. Im Beispiel ist das (11,4)/LEFT (das Feld über der Maus):
Pathfinding-Queue: das zuletzt entnommene Element zeigt die einzuschlagene Richtung an
Der kürzeste Weg von der Katze zur Maus führt also nach links. In der folgenden Grafik habe ich den Weg gelb markiert:
Abbruchbedingung erreicht – Kürzester Weg gefunden
Der Weg kann den Daten zu diesem Zeitpunkt nicht mehr entnommen werden. Er ist irrelevant, da die Katze nur einen einzigen Schritt machen muss, und danach der kürzeste Weg neu berechnet wird (denn die Maus bewegt sich ja auch, und der kürzeste Weg könnte im nächsten Schritt in eine andere Richtung führen).
Sollte der Fall eintreten, dass die Queue leer ist, ohne dass die Maus gefunden wurde, bedeutet dies, dass es keinen Weg zwischen Katze und Maus gibt. Dieser Fall kann im FatCat-Spiel nicht eintreten, sollte für andere Anwendungen allerdings behandelt werden.
Shortest Path Java Code
Quellcode von 1990
Den C64-Code habe ich leider nicht mehr. Ein paar Jahre später habe ich das Spiel auf einem 286er in Turbo Pascal neu implementiert, und diesen Code konnte ich tatsächlich wiederfinden. Du findest ihn – gekürzt auf die relevanten Teile – hier: KATZE.PAS
Der Pascal-Code ist etwas in die Jahre gekommen und für Ungeübte schwer zu lesen. Daher habe ich den Quellcode – ohne Änderung der Algorithmen und Datenstrukturen – in Java übersetzt. Die Java-Adaption findest du hier: CatAlgorithmFrom1990.java
Der folgende Code implementiert den Algorithmus mit modernen Sprachmitteln und Datenstrukturen wie dem ArrayDeque als Queue. Du findest ihn im GitHub-Repository in der Klasse CatAlgorithmFrom2020.
/**
* Finds the shortest path from cat to mouse in the given labyrinth.
*
* @param lab the labyrinth's matrix with walls indicated by {@code true}
* @param cx the cat's X coordinate
* @param cy the cat's Y coordinate
* @param mx the mouse's X coordinate
* @param my the mouse's Y coordinate
* @return the direction of the shortest path
*/private Direction findShortestPathToMouse(boolean[][] lab, int cx, int cy, int mx, int my){
// Create a queue for all nodes we will process in breadth-first order.// Each node is a data structure containing the cat's position and the// initial direction it took to reach this point.
Queue<Node> queue = new ArrayDeque<>();
// Matrix for "discovered" fields// (I know we're wasting a few bytes here as the cat and mouse can never// reach the outer border, but it will make the code easier to read. Another// solution would be to not store the outer border at all - neither here nor// in the labyrinth. But then we'd need additional checks in the code// whether the outer border is reached.)boolean[][] discovered = newboolean[23][31];
// "Discover" and enqueue the cat's start position
discovered[cy][cx] = true;
queue.add(new Node(cx, cy, null));
while (!queue.isEmpty()) {
Node node = queue.poll();
// Go breath-first into each directionfor (Direction dir : Direction.values()) {
int newX = node.x + dir.getDx();
int newY = node.y + dir.getDy();
Direction newDir = node.initialDir == null ? dir : node.initialDir;
// Mouse found?if (newX == mx && newY == my) {
return newDir;
}
// Is there a path in the direction (= is it a free field in the labyrinth)?// And has that field not yet been discovered?if (!lab[newY][newX] && !discovered[newY][newX]) {
// "Discover" and enqueue that field
discovered[newY][newX] = true;
queue.add(new Node(newX, newY, newDir));
}
}
}
thrownew IllegalStateException("No path found");
}
privatestaticclassNode{
finalint x;
finalint y;
final Direction initialDir;
publicNode(int x, int y, Direction initialDir){
this.x = x;
this.y = y;
this.initialDir = initialDir;
}
}Code-Sprache:Java(java)
Testen kannst du den Code mit der Klasse CatAlgorithmsTest. Diese erstellt ein Labyrinth, platziert Katze und Maus an zufälligen Positionen und lässt die Katze auf kürzestem Weg zur Maus laufen.
Das Demo-Programm visualisiert das Labyrinth mit ASCII-Blöcken, und die einzelnen Schritte werden der Einfachheit halber untereinander gedruckt (der Pathfinding-Algorithmus steht im Vordergrund, nicht die Darstellung). Die folgende Animation zeigt die ausgegebenen Schritte in zeitlicher Abfolge:
Pathfinding im Labyrinth: Test-Ausgabe des Java-Programms
Performance des Algorithmus
Mit dem Tool CatAlgorithmsBenchmark lässt sich die Performance der alten und neuen Implementierung vergleichen. Folgende Tabelle zeigt den Median der Messwerte aus 20 Test-Iterationen mit jeweils 100.000 Berechnungen des kürzesten Pfades. Dem Test gingen 10 Warmup-Runden voraus.
Algorithmus
Zeit für 100.000 Pfad-Berechnungen
CatAlgorithmFrom1990
530 ms
CatAlgorithmFrom2020
662 ms
Der Algorithmus, den ich als 15-jähriger geschrieben habe, ist auf den ersten Blick schneller als mein neuer Algorithmus. Wie kann das sein?
Optimierung für Katze-und-Maus-Labyrinthe
Ein erneuter Blick in den alten Code zeigt, dass während des Pathfindings nur jeder zweite Wegpunkt betrachtet wird. Dies macht insoweit Sinn, als dass durch den spezifischen Aufbau der Labyrinthe die Katze nur nach jedem zweiten Schritt ihre Richtung ändern kann:
Nur jeder zweite Wegpunkt ist ein Knoten des Graphs
Ich habe den Java-Code noch einmal dahingehend optimiert. Es ändert sich nur der Teil innerhalb der Schleife. Die Zwischenschritte der Katze dürfen dabei nicht komplett außer Acht gelassen werden – denn dort könnte ja die Maus sitzen.
Den optimierten Code findest du im folgenden Listing und in der Klasse CatAlgorithmFrom2020Opt im GitHub-Repository.
while (!queue.isEmpty()) {
Node node = queue.poll();
// Go *two* steps breath-first into each directionfor (Direction dir : Direction.values()) {
// First stepint newX = node.x + dir.getDx();
int newY = node.y + dir.getDy();
Direction newDir = node.initialDir == null ? dir : node.initialDir;
// Mouse found after first step?if (newX == mx && newY == my) {
return newDir;
}
// Is there a path in the direction (= is it a free field in the labyrinth)?// No -> continue to next directionif (lab[newY][newX]) continue;
// Second step
newX += dir.getDx();
newY += dir.getDy();
// Mouse found after second step?if (newX == mx && newY == my) {
return newDir;
}
// Target field has not yet been discovered?if (!discovered[newY][newX]) {
// "Discover" and enqueue that field
discovered[newY][newX] = true;
queue.add(new Node(newX, newY, newDir));
}
}
}Code-Sprache:Java(java)
Und hier das Ergebnis eines erneuten Performance-Vergleichs:
Algorithmus
Zeit für 100.000 Pfad-Berechnungen
CatAlgorithmFrom1990
540 ms
CatAlgorithmFrom2020
687 ms
CatAlgorithmFrom2020Opt
433 ms
Der neue Code ist nun etwa 25 % schneller als der von 1990.
Falls du in den Code von 1990 geschaut hast: Der Grund liegt darin, dass ich damals keine Queue verwendet habe, sondern zwei separate Datenstrukturen für die Ausgangs- und Endpunkte jedes Pathfinding-Schritts. Nach jedem Schritt wurden alle Endpunkte in die Datenstruktur der Ausgangspunkte kopiert.
Dass ich mit 15 nicht an die Verwendung einer Queue gedacht habe (die ich damals auch gar nicht einfach aus dem Werkzeugkoffer hätte ziehen können), möge man mir verzeihen ;-)
Zusammenfassung und Ausblick
Dieser Artikel hat das „Shortest-Path-Problem“ beschrieben und am Beispiel des „FatCat“-Spiels (bei uns hieß das Spiel übrigens „Katze und Maus“) gezeigt, wie man die Problemstellung mit einem Pathfinding-Algorithmus in Java lösen kann.
Der hier vorgestellte Algorithmus kann nur auf kachelbasierte Karten, bzw. auf Graphen, die kachelbasierte Karten repräsentieren, angewendet werden.
In den folgenden Teilen der Serie werde ich allgemeine Shortest-Path-Algorithmen wie den Dijkstra-Algorithmus und den A*-Algorithmus vorstellen.
Alle bisher in dieser Artikelserie behandelten Sortierverfahren basieren auf dem Vergleich, ob zwei Zahlen kleiner, größer oder gleich sind. Counting Sort basiert auf einer komplett anderen, nicht-vergleichsbasierten Herangehensweise.
Dieser Artikel beantwortet folgende Fragen:
Wie funktioniert Counting Sort?
Was unterscheiden sich die vereinfachte Form von Counting Sort und die allgemeine Form?
Wie sieht der Quellcode von Counting Sort aus?
Wie bestimmt man die Zeitkomplexität von Counting Sort?
Warum ist Counting Sort trotz exakt gleicher Anzahl an Operationen für vorsortierte Zahlenfolgen fast zehn Mal schneller als für unsortierte?
Counting Sort Algorithmus (Vereinfachte Form)
Anstatt Elemente zu vergleichen, wird bei Counting Sort gezählt, wie oft welche Elemente in der zu sortierenden Menge vorkommen.
Eine vereinfachte Form von Counting Sort kann angewendet werden, wenn Zahlen (z. B. int-Primitive) sortiert werden sollen – für Objekte, die entsprechend ihrer Keys sortiert werden sollen, wirst du im Anschluss die allgemeine Form von Counting Sort kennenlernen.
Die vereinfachte Form besteht aus zwei Phasen:
Counting Sort Algorithmus – Phase 1: Elemente zählen
Zunächst wird ein zusätzliches Array angelegt, dessen Länge der Größe des Zahlenraums entspricht (z. B. ein Array der Größe 256, um Bytes zu sortieren). Dann iteriert man einmal über die zu sortierenden Elemente und erhöht für jedes Element den Wert im Array an derjenigen Position, die der zu sortierenden Zahl entspricht, um eins.
Hier ein Beispiel mit dem Zahlenraum 0–9 (d. h. in dem zu sortierenden Array kommen nur Zahlen von 0 bis 9 vor).
Folgendes Array soll sortiert werden:
Wir erstellen ein zusätzliches Array der Länge 10, das mit Nullen initialisiert ist. In der Grafik wird unter der Linie der Array-Index mit angezeigt:
Nun iterieren wir über das zu sortierende Array. Das erste Element ist eine 3 – dementsprechend erhöhen wir den Wert im Hilfsarray an der Position 3 um eins:
Das zweite Element ist eine 7. Wir erhöhen im Hilfsarray das Feld an Position 7 um eins:
Es folgen die Elementen 4 und 6 – dementsprechend erhöhen wir auch die Werte an den Positionen 4 und 6 jeweils um eins:
Mit den nächsten zwei Elementen – der 6 und der 3 – folgen zwei Elemente, die schon einmal vorkamen. Entsprechend werden die Felder im Hilfsarray von 1 auf 2 erhöht:
Das Prinzip sollte nun klar sein. Nachdem auch die Hilfsarray-Werte für die restlichen zu sortierenden Elemente entsprechend erhöht wurden, sieht das Hilfsarray am Ende wie folgt aus:
Aus diesem sogenannten Histogramm lässt sich folgendes ablesen:
Die zu sortierenden Elemente enthalten:
1 mal die 0,
0 mal die 1,
1 mal die 2,
3 mal die 3,
1 mal die 4,
0 mal die 5,
5 mal die 6,
1 mal die 7,
2 mal die 8 und
1 mal die 9.
Diese Informationen werden wir in Phase 2 verwenden, um das zu sortierende Array neu anzuordnen.
Counting Sort Algorithmus – Phase 2: Elemente neu anordnen
In Phase zwei iterieren wir einmal über das Histogramm-Array. Dabei schreiben wir den jeweiligen Array-Index so oft in das zu sortierende Array, wie es das Histogramm an der entsprechenden Stelle anzeigt.
Im Beispiel starten wir an Position 0 im Hilfsarray. Dort steht die 1, wir schreiben daher die 0 genau ein Mal in das zu sortierende Array.
(Die restlichen Zahlen habe ich ausgegraut, da sie zwar nach wie vor im Array stehen, wir sie aber nicht mehr benötigen, da wir diese Informationen jetzt komplett im Histogramm haben.)
An Position 1 im Histogramm steht eine 0, d. h. wir überspringen dieses Feld – es wird keine 1 in das zu sortierende Array geschrieben.
Position 2 des Histogramms enthält wieder eine 1; wir schreiben also einmal eine 2 in das zu sortierende Array:
Kommen wir zu Position 3, diese enthält eine 3, wir schreiben also drei Mal eine 3 in das Array:
Und so geht es weiter… wir schreiben einmal die 4, fünfmal die 6, einmal die 7, zweimal die 8 und zuletzt einmal die 9 in das zu sortierende Array:
Die Zahlen sind sortiert, der Algorithmus ist beendet.
Counting Sort Java Code Beispiel (Vereinfachte Form)
Im folgenden findest du eine sehr einfache Form des Counting Sort-Quellcodes – diese funktioniert ausschließlich für nicht-negative int-Primitive (z. B. für das Array aus dem Beispiel oben).
Zunächst wird über die findMax()-Methode das größte Element im Array gefunden. Dann wird das Hilfsarray counts der entsprechenden Größe angelegt, wobei die Größe um eins größer ist als das größte Element, um auch die 0 mitzählen zu können.
(Bei kleineren Zahlenräumen wie byte und short kann das Ermitteln des Maximums auch weggelassen werden und direkt ein Array in der Größe des Zahlenraums erstellt werden.)
Im mit „Phase 1“ kommentierten Block werden die Elemente gezählt, so dass das counts-Array schließlich das Histogramm enthält.
Im mit „Phase 2“ kommentierten Block werden die Elemente in aufsteigender Reihenfolge und entsprechend der im Histogramm hinterlegten Häufigkeit zurück in das zu sortierende Array geschrieben.
publicclassCountingSortSimple{
publicvoidsort(int[] elements){
int maxValue = findMax(elements);
int[] counts = newint[maxValue + 1];
// Phase 1: Countfor (int element : elements) {
counts[element]++;
}
// Phase 2: Write results backint targetPos = 0;
for (int i = 0; i < counts.length; i++) {
for (int j = 0; j < counts[i]; j++) {
elements[targetPos++] = i;
}
}
}
privateintfindMax(int[] elements){
int max = 0;
for (int element : elements) {
if (element < 0) {
thrownew IllegalArgumentException("This implementation does not support negative values.");
}
if (element > max) {
max = element;
}
}
return max;
}
}Code-Sprache:Java(java)
Das Maximum könnte auch mittels Arrays.stream(elements).max().getAsInt() ermittelt werden. Dann müssten wir allerdings die Prüfung auf negative Werte entweder weglassen oder in einem separaten Schritt durchführen.
Den Code findest du im GitHub-Repository in der Klasse CountingSortSimple.
Counting Sort Quellcode auch für negative Zahlen
Sollen auch negative Zahlen erlaubt sein, wird der Code etwas komplizierter, da wir mit einem sogenannten Offset arbeiten müssen, um die zu sortierende Zahl auf die Position im Hilfsarray zu mappen.
Berechnung des Offset
Der Offset ist: null minus die kleinste zu sortierende Zahl.
Ist beispielsweise -5 die kleinste zu sortierende Zahl, dann ist der Offset 5, d. h. der Index im Hilfsarray ist jeweils die zu sortierende Zahl plus 5.
Die -5 wird also beispielsweise an Position -5+5 = 0 gezählt; die 0 wird an Position 0+5 = 5 gezählt; die 11 wird an Position 11+5 = 16 gezählt.
Quellcode
Den folgenden Quellcode findest du in der Klasse CountingSort im GitHub-Repository. Er ähnelt dem oben gezeigte Quellcode bis auf folgende Unterschiede:
Die Methode findMax() ist ersetzt durch die Methode findBoundaries(), die nicht nur den Maximal-, sondern auch den Minimalwert zurückgibt (bei kleinen Zahlenräumen wie byte und short kann das Ermitteln der Grenzwerte weggelassen werden und direkt ein Array in der Größe des Zahlenraums erstellt werden).
Beim Zugriff auf das counts-Array in der Zählphase wird dem jeweiligen Index der Offset -boundaries.min hinzuaddiert (bzw. -Byte.MIN_VALUE oder -Short.MIN_VALUE).
Beim Zurückschreiben der sortierten Zahlen in das Array wird der Offset wieder abgezogen, indem boundaries.min (bzw. Byte.MIN_VALUE oder Short.MIN_VALUE) addiert wird.
publicclassCountingSort{
privatestaticfinalint MAX_VALUE_TO_SORT = Integer.MAX_VALUE / 2;
privatestaticfinalint MIN_VALUE_TO_SORT = Integer.MIN_VALUE / 2;
publicvoidsort(int[] elements){
Boundaries boundaries = findBoundaries(elements);
int[] counts = newint[boundaries.max - boundaries.min + 1];
// Phase 1: Countfor (int element : elements) {
counts[element - boundaries.min]++;
}
// Phase 2: Write results backint targetPos = 0;
for (int i = 0; i < counts.length; i++) {
for (int j = 0; j < counts[i]; j++) {
elements[targetPos++] = i + boundaries.min;
}
}
}
private Boundaries findBoundaries(int[] elements){
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int element : elements) {
if (element > MAX_VALUE_TO_SORT) {
thrownew IllegalArgumentException("Element " + element +
" is greater than maximum " + MAX_VALUE_TO_SORT);
}
if (element < MIN_VALUE_TO_SORT) {
thrownew IllegalArgumentException("Element " + element +
" is less than minimum " + MIN_VALUE_TO_SORT);
}
if (element > max) {
max = element;
}
if (element < min) {
min = element;
}
}
returnnew Boundaries(min, max);
}
privatestaticclassBoundaries{
privatefinalint min;
privatefinalint max;
publicBoundaries(int min, int max){
this.min = min;
this.max = max;
}
}
}Code-Sprache:Java(java)
Diese Variante hat nicht nur den Vorteil auch negative Zahlen zählen zu können, sondern belegt auch weniger zusätzlichen Speicher als die erste Variante, falls der Zahlenraum nicht bei 0 beginnt: Für Zahlen von 1.000 bis 2.000 beispielweise würde die erste Variante ein Hilfsarray mit 2.001 Feldern benötigen, Variante 2 hingegen nur 1.001 Felder.
Counting Sort Algorithmus (Allgemeine Form)
Mit Counting Sort können nicht nur Arrays von Primitiven (also bytes, ints, longs, doubles, etc.) sortiert werden, sondern auch Arrays von Objekten. Dazu müssen wir den Algorithmus, wie im folgenden Abschnitt beschrieben, erweitern.
Allgemeiner Algorithmus – Phase 1: Elemente zählen
Phase 1, die Zählphase bleibt quasi unverändert. Statt der Objekte selbst werden nun deren Schlüsselwerte (z. B. ermittelt durch eine getKey()-Methode) gezählt.
Das Array in der folgenden Grafik referenziert Objekte, deren Keys den Zahlen aus dem vorherigen Beispiel entsprechen, also 3, 7, 4, 6, 6, usw:
Entsprechend gleicht das daraus entstandene Histogramm dem aus dem ersten Beispiel:
Jetzt wird der Unterschied zum vereinfachten Algorithmus deutlich: Wir wissen jetzt zwar, dass das Element mit dem Key 0 ein Mal vorkommt, können aber nicht einfach eine 0 in das zu sortierende Array schreiben – vielmehr benötigen wir das Objekt mit dem Key 0!
Um dies effizient zu finden, aggregieren wir zunächst die Werte im Histogramm. Dazu iterieren wir, beginnend bei Index 1, über das Hilfsarray und addieren zu jedem Feld den Wert des linken Nachbarfeldes.
An Position 1 addieren wir zur 0 den Wert von Feld 0, also die 1. Die Summe ist 1:
An Position 2 addieren wir zur 1 die 1 von Feld 1 und erhalten eine 2:
Zur 3 an Position 3 addieren wir die 2 von Feld 2 – die Summe ist 5:
Und so fahren wir fort, bis wir letztendlich zur 1 in Feld 9 die 14 von Feld 8 addieren und 15 erhalten:
Dieses aggregierte Histogramm sagt uns jetzt nicht mehr, wie oft die Objekte mit bestimmten Keys vorkommen, sondern an welche Position das letzte Element mit dem entsprechenden Key gehört. Die Position ist hierbei 1-basiert, nicht 0-basiert.
Beispielsweise gehört das Objekt mit Key 0 an Position 1 (entspricht Index 0 im Array), das Objekt mit Key 2 an Position 2 (Array-Index 1) und die drei Objekte mit Key 3 an die Positionen 3, 4 und 5 (Array-Indexe 2, 3, 4).
Um die Objekte zu sortieren, benötigen wir ein zusätzliches Array in der Größe des Eingabearrays:
Wir iterieren nun rückwärts über das zu sortierende Array und schreiben jedes Objekt im Zielarray an diejenige Position, die durch das Hilfsarray angezeigt wird. Wir dekrementieren den entsprechenden Wert im Hilfsarray um 1, um ggf. das nächste Objekt mit demselben Key ein Feld weiter links einzusortieren.
Beginnen wir im Eingabearray ganz rechts – mit dem Objekt mit dem Key 8. Im Hilfsarray steht an Position 8 der Wert 14. Wir dekrementieren den Wert auf 13 und kopieren das Objekt mit dem Key 8 in das Zielarray an Position 13 (zur Erinnerung: die Positionsangaben im Hilfsarray sind 1-basiert, deshalb schreiben wir auf Position 13, nicht 14).
Das zweite Objekt von rechts hat den Key 2. Im Hilfsarray steht an Position 2 der Wert 2. Wir dekrementieren den Wert im Hilfsarray auf 1 und kopieren das Objekt an die entsprechende Position im Zielarray:
Das nächste Objekt hat den Key 6. Im Hilfsarray steht an Position 6 die 11. Wir dekrementieren das Feld auf 10 und kopieren das Objekt nach Feld 10 im Zielarray:
Derselben Logik folgend kopieren wir das Objekt mit dem Key 9 an Position 14 des Zielarrays:
Es folgt eine weitere 6. Im Hilfsarray steht an Position 6 jetzt die 10 (nachdem wir zuvor dort die 11 dekrementiert hatten). Wir dekrementieren das Feld erneut auf 9 und kopieren das Objekt nach Position 9 im Zielarray, also links neben das andere Objekt mit dem Key 6:
Wir wiederholen diese Schritte für alle Elemente und kommen als letztes zum Objekt mit dem Key 3. An Feld 3 im Hilfsarray steht nun eine 3. Diese dekrementieren wir auf 2 und kopieren das Objekt auf Position 2, die letzte freie Position, des Zielarrays:
Die Objekte sind sortiert, der Algorithmus ist beendet.
Counting Sort Java Code Beispiel (Allgemeine Form)
Der folgende Code demonstriert die allgemeine Form von Counting Sort der Einfachheit halber an int-Primitiven. Die findMax()-Methode gleicht der im ersten Quellcode-Beispiel, ich habe sie daher hier nicht noch einmal mit abgedruckt.
publicclassCountingSortGeneral{
publicvoidsort(int[] elements){
int maxValue = findMax(elements);
int[] counts = newint[maxValue + 1];
// Phase 1: Countfor (int element : elements) {
counts[element]++;
}
// Phase 2: Aggregatefor (int i = 1; i <= maxValue; i++) {
counts[i] += counts[i - 1];
}
// Phase 3: Write to target arrayint[] target = newint[elements.length];
for (int i = elements.length - 1; i >= 0; i--) {
int element = elements[i];
target[--counts[element]] = element;
}
// Copy target back to input array
System.arraycopy(target, 0, elements, 0, elements.length);
}
[...]
}Code-Sprache:Java(java)
Du findest den Quellcode in der Klasse CountingSortGeneral im GitHub-Repository.
Counting Sort Zeitkomplexität
Die Zeitkomplexität von Counting Sort ist aufgrund des sehr einfachen Algorithmus leicht bestimmbar.
Sei n die Anzahl der zu sortierenden Elemente und k die Größe des Zahlenraums der Elemente.
Der Algorithmus enthält eine oder mehrere Schleifen, die bis n iterieren und eine Schleife, die bis k iteriert.
Konstante Faktoren sind für die Zeitkomplexität irrelevant; somit gilt:
Die Zeitkomplexität von Counting Sort beträgt: O(n + k)
Laufzeit des Java Counting Sort Beispiels
Das GitHub-Repository enthält das Programm UltimateTest, mit dem wir die Geschwindigkeit von Counting Sort und aller anderen Sortieralgorithmen dieser Artikelserie messen können.
Die folgende Tabelle zeigt die benötigte Zeit zum Sortieren von unsortierten sowie aufsteigend und absteigend vorsortierten Elementen für die jeweils angegebene Anzahl von Elementen n, die in diesen Messungen auch der Größe des Zahlenraums k entspricht:
n, k
unsortiert
aufsteigend
absteigend
…
…
…
…
33.554.432
1.276 ms
195 ms
210 ms
67.108.864
2.857 ms
381 ms
388 ms
134.217.728
6.087 ms
745 ms
766 ms
268.435.456
12.684 ms
1.477 ms
1.529 ms
536.870.912
27.249 ms
2.945 ms
3.039 ms
Das vollständige Ergebnis findest du in der Datei Test_Results_Counting_Sort.log. Das folgende Diagramm stellt die Messwerte grafisch dar:
Es lässt sich folgendes ablesen:
Vorsortierte Ausgangsfolgen mit einer halben Milliarde Elemente werden etwa neun mal so schnell sortiert wie unsortierte.
Bei vorsortierten Ausgangsfolgen entsprechen die Messwerte der erwarteten linearen Zeitkomplexität O(n + k).
Für unsortierte Ausgangsfolgen liegen die Messwerte etwas darüber: Bei einer Verdopplung der Arraygröße nimmt die benötigte Zeit etwa um Faktor 2,1 bis 2,2 zu.
Absteigend sortierte Ausgangsfolgen werden minimal langsamer sortiert als aufsteigend vorsortierte.
Wenn Elemente nicht umsortiert, sondern gezählt und einmal komplett neu angeordnet werden, dürfte doch die Ausgangsreihenfolge keine Auswirkung auf die zum Sortieren benötigte Zeit haben!?
Mit dem Programm CountOperations können wir messen, wie viele Operationen für das Sortieren benötigt werden. Und tatsächlich bestätigt das Ergebnis (s. Datei CountOperations_Counting_Sort.log):
Die Anzahl der Operationen ist unabhängig von der Ausgangsreihenfolge der Elemente.
Die Anzahl der Operationen entspricht der erwarteten Zeitkomplexität O(n + k), steigt also linear mit der Anzahl der zu sortierenden Elememte und der Größe des Zahlenraums.
Wie kommen dann diese abweichenden Messwerte zustande? Erklärungen findest du in den folgenden Abschnitten.
Warum ist Counting Sort für vorsortierte Elemente schneller als für unsortierte Elemente?
Ein Hilfsarray mit einer halben Milliarde Elemente ist 2 GB groß. Wenn dessen Elemente in zufälliger Reihenfolge inkrementiert werden, muss beinahe für jedes Element eine neue Cache-Line (typischerweise 64 Byte groß) zwischen RAM und CPU-Cache ausgetauscht werden. Die Wahrscheinlichkeit, dass die benötigte Cache-Line im CPU-Cache liegt, ist umso niedriger, je größer das Array ist.
Wird das Array hingegen von vorne nach hinten (oder von hinten nach vorne) inkrementiert, können jeweils 16 aufeinanderfolgende int-Werte in einem 64-Byte-Block aus dem RAM geladen und wieder dorthin geschrieben werden.
Es wird nicht ganz eine Beschleunigung um Faktor 16 erreicht, aber zumindest eine um ca. Faktor neun.
Warum erreicht Counting Sort in der Praxis keine lineare Zeitkomplexität für unsortierte Ausgangsfolgen?
Je größer das zu sortierende Array, desto höher wird bei einem unsortierten Ausgangsarray das Verhältnis von Cache Misses zu Cache Hits beim Zugriff auf das Hilfsarray (denn die Größe des CPU-Caches bleibt ja gleich).
Bei einem doppelt so großen Array haben wir also nicht doppelt so viele Cache Misses, sondern etwas mehr als doppelt so viele. Dementsprechend erhöht sich die benötigte Zeit auch um etwas mehr als Faktor zwei.
Warum ist Counting Sort für aufsteigend sortierte Elemente schneller als für absteigend sortierte?
Bei aufsteigend sortierten Elementen werden diese nicht verändert, müssen also nicht zurück in den RAM geschrieben werden. Bei absteigend sortierten Elementen ändert sich jedes Element des Arrays, entsprechend muss das gesamte Array einmal zurück in den RAM geschrieben werden.
Weitere Eigenschaften von Counting Sort
In diesem Kapitel bestimmen wir die Platzkomplexität, die Stabilität und die Parallelisierbarkeit von Counting Sort.
Platzkomplexität von Counting Sort
Der vereinfachte Algorithmus benötigt ein zusätzliches Array der Größe k; es gilt entsprechend:
Die Platzkomplexität des vereinfachten Counting Sort Algorithmus ist: O(k)
Der allgemeine Algorithmus benötigt neben dem Hilfsarray der Größe k ein temporäres Zielarray der Größe n; somit gilt:
Die Platzkomplexität des allgemeinen Counting Sort Algorithmus ist: O(n + k)
Stabilität von Counting Sort
Die allgemeine Form des Counting Sort Algorithmus iteriert in Phase 3 von rechts nach links über das Eingabearray und kopiert dabei Objekte mit demselben Key ebenfalls von rechts nach links in das Ausgabearray. Somit gilt:
Counting Sort ist ein stabiler Sortieralgorithmus.
Parallelisierbarkeit von Counting Sort
Counting Sort kann parallelisiert werden, in dem das Eingabearray in so viele Partitionen geteilt wird, wie Prozessoren zur Verfügung stehen.
In Phase 1 zählt jeder Prozessor die Elemente „seiner“ Partition in einem separatem Hilfsarray.
In Phase 2 werden alle Hilfsarrays zu einem aufaddiert.
In Phase 3 kopiert jeder Prozessor die Elemente „seiner“ Partition ins Zielarray. Das Dekrementieren und Auslesen der Felder im Hilfsarray muss dabei atomar erfolgen.
Durch die Parallelisierung kann nicht mehr garantiert werden, dass Elemente mit gleichem Key in ihrer ursprünglichen Reihenfolge ins Zielarray kopiert werden.
Paralleles Counting Sort ist dementsprechend nicht stabil.
Zusammenfassung
Counting Sort ist ein sehr effizienter, stabiler Sortieralgorithmus mit einer Zeit- und Platzkomplexität von O(n + k).
Counting Sort wird hauptsächlich für kleine Zahlenräume eingesetzt. Im JDK beispielsweise für:
byte-Arrays mit mehr als 64 Elementen (darunter wird Insertion Sort eingesetzt)
short– oder char-Arrays mit mehr als 1.750 Elementen (darunter wird Insertion Sort oder Dual-Pivot Quicksort verwendet)
Bei Heapsort denkt jeder Java-Entwickler zunächst an den Java-Heap. Dass Heapsort damit nichts zu tun hat – und wie Heapsort genau funktioniert – zeigt dir dieser Artikel.
Im Detail erfährst du:
Was ist ein Heap?
Wie funktioniert der Heapsort-Algorithmus?
Wie sieht der Quellcode von Heapsort aus?
Wie bestimmt man die Zeitkomplexität von Heapsort?
Was ist Bottom-Up-Heapsort und welche Vorteile hat es?
Wie schlägt sich Heapsort im Vergleich zu Quicksort und Mergesort?
Was ist ein Heap?
Ein „Heap“ (deutsch: „Haufen“ oder „Halde“) bezeichnet einen Binärbaum, in dem jeder Knoten entweder größer/gleich seiner Kinder ist („Max Heap“) – oder kleiner/gleich seiner Kinder („Min Heap“).
Hier ist ein einfaches Beispiel für einen „Max Heap“:
Die 9 ist größer als die 8 und die 5; die 8 ist größer als die 7 und die 2; usw.
Ein Heap wird auf ein Array projiziert, indem dessen Elemente von oben links zeilenweise nach rechts unten in das Array übertragen werden:
Der oben gezeigte Heap sieht als Array also so aus:
Bei einem „Max Heap“ ist das größte Element immer ganz oben – in der Array-Form ist es folglich ganz links. Wie man diese Eigenschaft zum Sortieren verwenden kann, erfährst du im folgenden Abschnitt.
Heapsort-Algorithmus
Der Heapsort-Algorithmus besteht aus zwei Phasen: In der ersten Phase wird das zu sortierende Array in einen Max Heap umgewandelt. Und in der zweiten Phase wird jeweils das größte Element (also das an der Baumwurzel) entnommen und aus den restlichen Elementen erneut ein Max Heap hergestellt.
Die folgenden Abschnitte erklären die zwei Phasen im Detail anhand eines Beispiels:
Phase 1: Heap erstellen
Das zu sortierende Array muss zunächst in einen Heap umgewandelt werden. Dazu wird keine neue Datenstruktur angelegt, sondern die Zahlen werden innerhalb des Arrays so umsortiert, dass die oben beschriebene Heap-Struktur entsteht.
Wie dies geschieht erkläre ich in folgendem Beispiel anhand der aus den vorangegangenen Teilen der Artikelserie bekannten Zahlenfolge [3, 7, 1, 8, 2, 5, 9, 4, 6].
Diese „projizieren“ wir wie oben beschrieben auf einen Binärbaum. Dabei ist der Binärbaum keine separate Datenstruktur, sondern lediglich ein Gedankenkonstrukt – im Speicher liegen die Elemente ausschließlich in dem Array.
Dieser Baum entspricht noch keinem Max Heap. Dessen Definiton lautet ja, dass Eltern immer größer oder gleich ihrer Kinder sind.
Um einen Max Heap herzustellen, besuchen wir nun alle Elternknoten – rückwärts vom letzten bis zum ersten – und sorgen dafür, dass die Heap-Bedingung für den jeweiligen Knoten und die darunter erfüllt ist. Dies machen wir mit der sogenannten heapify()-Funktion.
Aufruf Nr. 1 der heapify-Funktion
Die heapify()-Funktion wird zuerst für den letzten Elternknoten aufgerufen. Elternknoten sind 3, 7, 1 und 8. Der letzte Elternknoten ist die 8. Die heapify()-Funktion prüft, ob die Kinder kleiner sind als der Elternknoten. 4 und 6 sind kleiner als 8. An diesem Elternknoten ist die Heap-Bedingung also erfüllt, und die heapify()-Funktion ist beendet.
Aufruf Nr. 2 der heapify-Funktion
Als zweites wird heapify() für den vorletzten Knoten aufgerufen: die 1. Die Kinder 5 und 9 sind beide größer als die 1, die Heap-Bedingung ist also verletzt. Um die Heap-Bedingung wiederherzustellen, tauschen wir nun das größere Kind mit dem Elternknoten, also die 9 mit der 1. Die heapify()-Funktion ist damit wieder beendet.
Aufruf Nr. 3 der heapify-Funktion
Nun wird heapify() auf der 7 aufgerufen. Kindknoten sind 8 und 2, nur die 8 ist größer als der Elternknoten. Wir tauschen also die 7 mit der 8:
Da der Kindknoten, den wir eben getauscht haben, selbst zwei Kinder hat, muss die heapify()-Funktion nun prüfen, ob die Heap-Bedingung für diesen Kindknoten noch erfüllt ist. In diesem Fall ist die 7 größer als 4 und 6, die Heap-Bedingung ist also erfüllt; die heapify()-Funktion ist damit beendet.
Aufruf Nr. 4 der heapify-Funktion
Jetzt sind wir bereits am Wurzelknoten mit dem Element 3 angekommen. Beide Kindknoten, 8 und 9 sind größer, wobei die 9 das größte Kind ist und daher mit dem Elternknoten vertauscht wird:
Wiederum hat der getauschte Kindknoten selbst Kinder, so dass wir die Heap-Bedingung an diesem Kindknoten überprüfen müssen. Die 5 ist größer als die 3, d. h. die Heap-Bedingung ist nicht erfüllt und muss durch Tauschen der 5 und der 3 wiederhergestellt werden:
Damit ist auch der vierte und letzte Aufruf der heapify()-Funktion beendet. Ein Max Heap ist entstanden:
Damit gehen wir über in Phase zwei des Heapsort-Algorithmus.
Phase 2: Sortieren des Arrays
In Phase 2 machen wir uns die Tatsache zunutze, dass das größte Element des Max Heaps immer an dessen Wurzel (bzw. im Array ganz links) steht.
Phase 2, Schritt 1: Root und letztes Element tauschen
Das Wurzelelement (die 9) tauschen wir nun mit dem letzten Element (der 6), so dass die 9 an ihrer finalen Position am Ende des Arrays steht (im Array blau markiert). Außerdem entfernen wir dieses Element gedanklich aus dem Baum (im Baum grau dargestellt):
Nachdem wir die 6 an die Wurzel des Baumes gesetzt haben, ist dieser kein Max Heap mehr. Im nächsten Schritt „reparieren“ wir den Heap.
Um die Heap-Bedingung wiederherzustellen, rufen wir die aus Phase 1 bekannte heapify()-Funktion auf dem Wurzelknoten auf. Wir vergleichen also die 6 mit ihren Kindern, 8 und 5. Die 8 ist größer, wir tauschen sie daher mit der 6:
Der getauschte Kindknoten hat wiederum zwei Kinder, die 7 und die 2. Die 7 ist größer als die 6, daher tauschen wir auch diese zwei Elemente:
Der getauschte Kindknoten hat auch noch ein Kind, die 4. Die 6 ist größer als die 4, die Heap-Bedingung ist an diesem Knoten also erfüllt, so dass die heapify()-Funktion beendet ist und wir wieder einen Max Heap haben:
Wiederholung der Schritte
Damit steht nun wieder die größte Zahl des verbleibenden Arrays, die 8, an erster Stelle. Diese wird wieder mit dem letzten Element des Baums vertauscht. Da wir den Baum um ein Element gekürzt haben, liegt das letzte Element des Baumes auf dem vorletzten Feld des Arrays:
Damit sind die letzten zwei Felder des Arrays sortiert.
An der Wurzel ist nun wieder die Heap-Bedingung verletzt, und wir reparieren den Baum, indem wir heapify() auf dem Wurzelelement aufrufen (das folgende Bild zeigt alle heapify-Schritte auf einmal).
Wir wiederholen den Prozess solange, bis der Baum nur noch ein Element enthält:
Dieses ist das kleinste und verbleibt am Anfang des Arrays. Der Algorithmus ist beendet, das Array ist sortiert:
Heapsort Java Code Beispiel
Im folgenden findest du den Quellcode von Heapsort.
Die sort()-Methode ruft zunächst buildHeap() auf, um den Heap initial aufzubauen.
In der darauf folgenden Schleife iteriert die Variable swapToPos rückwärts vom Ende des Arrays bis zum zweiten Feld. Im Schleifenkörper wird das erste Element mit demjenigen an der Position swapToPos vertauscht und danach die heapify()-Methode auf dem Sub-Array bis zur (ausschließlichen) Position swapToPos aufgerufen:
Die buildHeap()-Methode ruft für jeden Elternknoten – beginnend beim letzten – heapify() auf und übergibt dieser Methode das Array, die Länge des Sub-Arrays, das den Heap darstellt und die Position des Elternknotens, an dem heapify() starten soll:
voidbuildHeap(int[] elements){
// "Find" the last parent nodeint lastParentNode = elements.length / 2 - 1;
// Now heapify it from here on backwardsfor (int i = lastParentNode; i >= 0; i--) {
heapify(elements, elements.length, i);
}
}Code-Sprache:Java(java)
Die heapify()-Methode prüft, ob ein Kindknoten größer ist als der Elternknoten. Wenn das der Fall ist, wird das Elternelement mit dem größeren Kindelement vertauscht, und der Prozess wird auf dem Kindknoten wiederholt.
(Hier könnte man auch mit Rekursion arbeiten, was sich allerdings negativ auf die Platzkomplexität auswirken würde.)
voidheapify(int[] heap, int length, int parentPos){
while (true) {
int leftChildPos = parentPos * 2 + 1;
int rightChildPos = parentPos * 2 + 2;
// Find the largest elementint largestPos = parentPos;
if (leftChildPos < length && heap[leftChildPos] > heap[largestPos]) {
largestPos = leftChildPos;
}
if (rightChildPos < length && heap[rightChildPos] > heap[largestPos]) {
largestPos = rightChildPos;
}
// largestPos is now either parentPos, leftChildPos or rightChildPos.// If it's the parent, we're doneif (largestPos == parentPos) {
break;
}
// If it's not the parent, then switch!
ArrayUtils.swap(heap, parentPos, largestPos);
// ... and fix again starting at the child we moved the parent to
parentPos = largestPos;
}
}Code-Sprache:Java(java)
Du findest den Quellcode in der Klasse HeapSort im GitHub-Repository. Diese unterscheidet sich leicht von der hier abgedruckten Klasse: Die Klasse im Repository implementiert das Interface SortAlgorithm, um innerhalb des Testframeworks austauschbar zu sein.
Fangen wir mit der heapify()-Funktion an, da diese auch für den initialen Aufbau des Heaps benötigt wird.
In der heapify()-Funktion hangeln wir uns einmal von oben nach unten durch den Baum. Die Höhe eines Binärbaumes (die Wurzel wird nicht mitgezählt) der Größe n ist maximal log2 n, d. h. bei einer Verdopplung der Anzahl Elemente wird der Baum lediglich eine Ebene tiefer:
Die Komplexität für die heapify()-Funktion ist entsprechend O(log n).
Zeitkomplexität der buildHeap()-Methode
Für den erstmaligen Aufbau des Heaps wird für jeden Elternknoten – rückwärts, beginnend beim letzten Knoten und endend an der Baumwurzel – die heapify()-Methode aufgerufen.
Ein Heap der Größe n hat n/2 (abgerundet) Elternknoten:
Da die Komplexität der heapify()-Methode, wie oben gezeigt, O(log n) ist, ist die Komplexität für die buildHeap()-Methode also maximal* O(n log n).
* Im übernächsten Abschnitt werde ich zeigen, dass die Zeitkomplexität der buildHeap()-Methode sogar O(n) ist. Da dies an der Gesamt-Zeitkomplexität nichts ändert, ist es nicht zwingend erforderlich, diese detailliertere Analyse durchzuführen.
Gesamt-Zeitkomplexität von Heapsort
Die heapify()-Funktion wird n-1 mal aufgerufen. Die Gesamtkomplexität für das Reparieren des Heaps ist also ebenfalls O(n log n).
Beide Teilalgorithmen haben also die gleiche Zeitkomplexität. Es gilt somit:
Die Zeitkomplexität von Heapsort beträgt: O(n log n)
Zeitkomplexität für den Aufbau des Heaps – genauer analysiert
Dieser Abschnitt ist sehr mathematisch und für die Herleitung der Zeitkomplexität des Gesamtalgorithmus (die wir ja bereits abgeschlossen haben) nicht zwingend erforderlich. Du kannst diesen Abschnitt daher auch überspringen.
Wir haben oben festgestellt, dass die buildHeap()-Methode für jeden Elternknoten heapify() aufruft. Was wir bisher nicht berücksichtigt haben ist, dass die Tiefe der Teilbäume, auf denen heapify() aufgerufen wird, unterschiedlich ist. Folgende Grafik soll das verdeutlichen (d steht für die Tiefe der Teilbäume):
Die heapify()-Methode wird also maximal für n/4 Bäume der Tiefe 1 aufgerufen, für n/8 Bäume der Tiefe 2, für n/16 Bäume der Tiefe 3, usw.
Die maximale Anzahl der Tauschoperationen in der heapify()-Methode entspricht der Tiefe des Teilbaums, auf der diese aufgerufen wird.
Die maximale Anzahl der Tauschoperationen Smax (S steht für „Swap“) für den Aufbau des Heaps beträgt somit:
Beide Terme enthalten n/4, n/8, n/16 usw. mit jeweils einem um die Konstante 1 unterschiedlichen Faktor. Wenn wir die Terme subtrahieren, erhalten wir:
Der Term 1/2 + 1/4 + 1/8 + 1/16 + … nähert sich an 1 an, wie folgende Darstellung zeigt:
Somit lässt sich die Formel abschließend vereinfachen auf:
Smax ≤ n
Damit haben wir gezeigt, dass der Aufwand für den Aufbau des Heaps linear ist, die Zeitkomplexität also O(n) beträgt.
Die oben genannte Gesamtkomplexität von O(n log n) ändert sich durch die niedrigere Komplexitätsklasse eines Teilalgorithmus nicht.
Laufzeit des Java Heapsort Beispiels
Mit der Klasse UltimateSort kann die Laufzeit verschiedener Sortieralgorithmen für unterschiedliche Eingabegrößen ermittelt werden.
Die folgende Tabelle zeigt die Mediane der Laufzeiten für das Sortieren von zufällig angeordneten, sowie aufsteigend und absteigend vorsortierten Elementen, nach 50 Wiederholungen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
n
unsortiert
aufsteigend
absteigend
…
…
…
…
2.097.152
369,5 ms
198,8 ms
198,8 ms
4.194.304
870,2 ms
410,4 ms
412,7 ms
8.388.608
2.052,4 ms
848,9 ms
852,9 ms
16.777.216
4.686,9 ms
1.752,6 ms
1.775,3 ms
33.554.432
10.508,2 ms
3.623,5 ms
3.668,7 ms
67.108.864
23.459,9 ms
7.492.4 ms
7.605,5 ms
Hier die vollständigen Messwerte als Diagramm:
Es lässt sich gut sehen:
Bei Verdopplung der Eingabemenge dauert das Sortieren etwas mehr als doppelt so lange; dies entspricht der erwarteten quasi-linearen Laufzeit O(n log n).
Für vorsortierte Eingabedaten ist Heapsort etwa drei mal so schnell wie für unsortierte.
Aufsteigend sortierte Eingabedaten werden etwa gleich schnell sortiert wie absteigend sortierte.
Warum ist Heapsort für vorsortierte Eingabedaten schneller?
Um dieser Frage auf den Grund zu gehen, verwende ich das Programm CountOperations, um die Anzahl von Vergleichs-, Lese- und Schreiboperationen von Heapsort für unsortierte, aufsteigend und absteigend sortierte Daten, für die jeweiligen Phasen, zu messen.
Wenn die Eingabedaten absteigend sortiert sind, gibt es in Phase 1 nur etwa halb so viele Vergleiche wie bei unsortierten oder aufsteigend sortierten Daten; außerdem gibt es keine Tauschoperationen. Dies liegt daran, dass ein absteigend sortiertes Array bereits einem Max Heap entspricht.
Aufsteigend sortierte Eingabedaten hingegeben entsprechen einem Min Heap. Dieser muss in der buildHeap()-Phase komplett umgedreht werden, deshalb haben wir in diesem Fall etwa ein Drittel mehr Tauschoperationen als bei zufällig angeordneten Daten, in denen die Heap-Bedingung bereits an einigen Teilbäumen erfüllt ist.
In Phase 2 unterscheidet sich die Anzahl der Operationen nur minimal.
Wie lässt sich dann erklären, dass Heapsort sowohl für aufsteigend als auch für absteigend vorsortierte Eingabedaten etwa drei mal so schnell ist?
Die Antwort finden wir in der sogenannten Sprungvorhersage (englisch „branch prediction“).
Bei vorsortierten Eingabedaten führen die Vergleichsoperationen immer wieder zum selben Ergebnis. Wenn die Sprungvorhersage nun davon ausgeht, dass die Vergleiche auch in Zukunft zum selben Ergebnis führen, können die Befehls-Pipelines der CPU voll ausgenutzt werden.
Bei unsortierten Eingabedaten hingegen kann keine zuverlässige Aussage über zukünftige Vergleichsergebnisse getroffen werden. Entsprechend muss die Befehls-Pipeline häufig gelöscht und wieder neu gefüllt werden.
Bottom-Up-Heapsort
Bottom-Up-Heapsort ist eine Variante, bei die heapify()-Methode durch geschickte Optimierung mit weniger Vergleichen auskommt. Dies ist vorteilhaft, wenn nicht beispielsweise int-Primitive verglichen werden, sondern Objekte mit einer aufwändigen compareTo()-Funktion.
Im regulären heapify() führen wir von oben nach unten an jedem Knoten zwei Vergleiche aus, um das größte von drei Elementen zu finden:
Elternknoten mit linkem Kind
Der größere Knoten aus dem ersten Vergleich mit dem zweiten Kind
Bottom-Up-Heapsort Algorithmus
Bottom-Up-Heapsort hingegen vergleicht nur die zwei Kinder miteinander und folgt dem jeweils größeren Kind bis zum Ende des Baumes („top-down“). Von dort geht der Algorithmus wieder zurück Richtung Baumwurzel („bottom-up“) und sucht das erste Element, das größer als die Wurzel ist. Von hier ab werden alle Elemente jeweils um eine Position Richtung Wurzel verschoben, und das Wurzelelement wird auf das freigewordene Feld gesetzt.
Das folgendes Beispiel soll das Verständnis erleichern.
Bottom-Up-Heapsort Beispiel
In folgendem Beispiel werden die 9 und 4 verglichen, dann die Kinder der 9 – die 8 und die 6, und zuletzt die Kinder der 8 – die 7 und die 3:
Wir erreichen auf diese Weise die 7 und vergleichen diese mit der Baumwurzel, der 5:
Die 5 ist kleiner als die 7. Das bedeutet, dass das Wurzelelement bis ganz nach unten durchgereicht werden muss:
Im Endeffekt führt dies zum gleichen Ergebnis wie das reguläre heapify().
Bottom-Up-Heapsort macht sich zunutze, dass das Wurzelelement in der Regel sehr weit nach unten geschoben wird, da dieses nach jeder Iteration vom Ende des Baumes kommt und daher relativ klein ist.
Somit sind weniger Vergleiche nötig, wenn einmal bis ganz nach unten verglichen wird und dann wieder ein kurzes Stück nach oben, als wenn von oben bis nach ganz unten jeweils zwei Vergleiche durchgeführt werden:
Bottom-Up-Heapsort Quellcode
Die Klasse BottomUpHeapsort erbt von Heapsort und überschreibt lediglich deren heapify()-Methode mit der folgenden:
@Overridevoidheapify(int[] heap, int length, int rootPos){
int leafPos = findLeaf(heap, length, rootPos);
int nodePos = findTargetNodeBottomUp(heap, rootPos, leafPos);
if (rootPos == nodePos) return;
// Move all elements starting at nodePos to parent, move root to nodePosint nodeValue = heap[nodePos];
heap[nodePos] = heap[rootPos];
while (nodePos > rootPos) {
int parentPos = getParentPos(nodePos);
int parentValue = heap[parentPos];
heap[parentPos] = nodeValue;
nodePos = getParentPos(nodePos);
nodeValue = parentValue;
}
}Code-Sprache:Java(java)
Die findLeaf()-Methode vergleicht jeweils zwei Kinder und folgt dem jeweils größeren, bis das Ende des Baumes erreicht ist (bzw. ein Knoten, der nur noch ein Kind enthält):
intfindLeaf(int[] heap, int length, int rootPos){
int pos = rootPos;
int leftChildPos = pos * 2 + 1;
int rightChildPos = pos * 2 + 2;
// Two child exist?while (rightChildPos < length) {
if (heap[rightChildPos] > heap[leftChildPos]) {
pos = rightChildPos;
} else {
pos = leftChildPos;
}
leftChildPos = pos * 2 + 1;
rightChildPos = pos * 2 + 2;
}
// One child exist?if (leftChildPos < length) {
pos = leftChildPos;
}
return pos;
}Code-Sprache:Java(java)
Die Methode findTargetNodeBottomUp() sucht von unten nach oben das erste Element, das nicht kleiner als der Wurzelknoten ist:
intfindTargetNodeBottomUp(int[] heap, int rootPos, int leafPos){
int parent = heap[rootPos];
while (leafPos != rootPos && heap[leafPos] < parent) {
leafPos = getParentPos(leafPos);
}
return leafPos;
}Code-Sprache:Java(java)
Die Performance von Bottom-Up-Heapsort kann ebenfalls mit dem UltimateTest gemessen werden. Die Messwerte findest Du in ebenfalls in UltimateTest_Heapsort.log. Das folgende Diagramm zeigt die Laufzeiten von Bottom-Up-Heapsort im Vergleich mit dem regulären Heapsort:
Wie man sieht benötigt Bottom-Up-Heapsort für unsortierte Daten bis zu doppelt so lange wie das reguläre Heapsort, während es bei sortierten Daten in etwa gleich schnell ist.
Bevor wir der Ursache dafür auf den Grund gehen, schauen wir uns zunächst einen kleineren Ausschnitt des Diagramms an:
Bottom-Up-Heapsort wird also erst ab etwa zwei Millionen Elementen langsamer als das reguläre Heapsort.
Worin liegt die Ursache?
Das Ergebnis des oben erwähnten CountOperations-Programms zeigt, dass Bottom-Up-Heapsort weniger Vergleichs-, Lese und Schreiboperationen benötigt als das reguläre Heapsort – und zwar unabhängig von der Anzahl der zu sortierenden Elemente.
Warum ist es dennoch langsamer?
Bottom-up-Heapsort basiert auf der Annahme, dass das Wurzelelement immer bis zur Blattebene verschoben wird. Diese Annahme kann sich auch die Sprungvorhersage der CPU zunutze machen und damit diesen Vorteil relativieren.
Des weiteren müssen wir bei Bottom-Up-Heapsort zweimal durch den Baum gehen: einmal von oben nach unten und einmal zurück nach oben. Dies wirkt sich zwar nicht negativ auf die Anzahl der Operation aus, wohl aber auf den Zugriff auf den Hauptspeicher!
Denn während beim einmaligen Traversieren des Baumes Speicherseiten nur einmal vom Hauptspeicher in den CPU-Cache geladen werden müssen, sind bei entsprechend großen Bäumen auf dem Rückweg die meisten Speicherseiten bereits wieder aus dem Cache entfernt und müssen erneut gelesen werden.
Daher nähern wir uns bei hinreichend großen Bäumen an den Geschwindigkeitsfaktor zwei an.
Bottom-Up-Heapsort mit teuren Vergleichsoperationen
Bottom-Up-Heapsort optimiert dahingehend, dass weniger Vergleiche ausgeführt werden müssen. Bei int-Primitiven fallen Vergleiche nicht ins Gewicht, daher kann Bottom-Up-Heapsort hier seine Vorteile nicht ausspielen.
Ich habe daher einen weiteren Test ausgeführt, indem ich die Vergleichsoperationen künstlich verteuert habe. Du findest die angepassten Algorithmen in den Klassen HeapsortSlowComparisons und BottomUpHeapsortSlowComparisons im GitHub-Repository.
Bottom-Up-Heapsort schneidet bei diesem Vergleich deutlich besser ab:
Weitere Eigenschaften von Heapsort
Im folgenden werden die Platzkomplexität von Heapsort, dessen Stabilität und Parallelisierbarkeit betrachtet.
Platzkomplexität von Heapsort
Heapsort ist ein In-Place-Sortierverfahren, d. h. außer für Schleifen- und Hilfsvariablen wird kein zusätzlicher Speicherplatz benötigt. Die Anzahl dieser Variablen ist immer gleich, egal ob wir zehn Elemente sortieren oder zehn Millionen. Daher gilt:
Die Platzkomplexität von Heapsort ist: O(1)
Stabilität von Heapsort
Es lassen sich sehr leicht Beispiele konstruieren, die zeigen, dass Elemente mit gleichem Key ihre Position zueinander ändern können:
Beispiel 1
Wenn wir das Array [3, 2a, 2b, 1] mit Heapsort sortieren, sehen die Schritte wie folgt aus (2a und 2b stellen zwei Elemente mit demselben Key dar; hellgelb markiert sind die Elemente, die im nächsten Schritt vertauscht werden; blau markiert sind fertig sortierte Elemente):
An dieser Stelle können wir abbrechen, denn wir sehen bereits jetzt, dass das Ziel-Array auf [2a, 3] enden wird, d. h. die 2a wird rechts neben der 2b im Ziel-Array landen.
Algorithmus anpassen?
Im zweiten Schritt haben wir entsprechend des Algorithmus die 1 mit der 2a vertauscht. Könnten wir den Algorithmus so ändern, dass bei Kindknoten mit gleichem Key, nicht mit dem linken Kind getauscht wird, sondern mit dem rechten?
In dem Fall würde das Array oben stabil sortiert werden, da die 1 nicht mit der 2a, sondern mit der 2b getauscht werden würde, und daraufhin die 2b an der vorletzte Stelle des Arrays landen würde.
Beispiel 2
Versuchen wir das einmal mit einem anderen Eingabearray, mit [4, 3, 2a, 2b, 1]:
Nach Schritt 2 wurde der Stand erreicht, den wir zuvor als Ausgangsarray hatten, wobei jedoch 2a und 2b ihre Positionen getauscht haben. Wenn wir im nächsten Schritt die 1 nun mit dem rechten Kind tauschen, passiert das gleiche wie oben: die 2a landet zuerst im Ziel-Array und damit rechts von der 2b.
Wir haben für beide Algorithmus-Varianten Gegenbeispiele gezeigt und können daher feststellen:
Heapsort ist kein stabiles Sortierverfahren.
Parallelisierbarkeit von Heapsort
Bei Heapsort wird das gesamte Array ständig verändert, so dass es keine naheliegenden Lösungen gibt den Algororithmus zu parallelisieren.
Vergleich von Heapsort mit anderen effizienten Sortierverfahren
Im folgenden Diagramm siehst du die Ergebnisse des UltimateTests von Heapsort im Vergleich zu den Messwerten von Quicksort und Mergesort (im englischen in der Regel „Merge Sort“) aus den jeweiligen Artikeln:
Heapsort ist bei zufällig verteilten Eingabedaten um Faktor 3,6 langsamer als Quicksort und um Faktor 2,4 langsamer als Merge Sort. Bei sortierten Daten ist Heapsort um Faktor 8 bis 9 langsamer als Quicksort und um Faktor 2 langsamer als Merge Sort.
Heapsort vs. Quicksort
Wie im vorangegangenen Abschnitt gezeigt, ist Quicksort in der Regel deutlich schneller als Heapsort.
Aufgrund der worst-case Zeitkomplexität bei Quicksort von O(n²) wird in der Praxis in manchen Fällen Heapsort gegenüber Quicksort vorgezogen.
Wie im Artikel über Quicksort gezeigt, ist bei geeigneter Wahl des Pivot-Elements der Eintritt des worst cases unwahrscheinlich. Dennoch besteht ein gewisses Risiko, welches ein potentieller Angreifer mit ausreichend Kenntnis der verwendeten Quicksort-Implementierung ausnutzen kann, um eine Anwendung mit entsprechend präparierten Eingabedaten in die Knie zu zwingen.
Heapsort vs. Mergesort
Auch Mergesort ist in der Regel schneller als Heapsort. Außerdem ist Mergesort im Gegensatz zu Heapsort stabil.
Heapsort hat gegenüber Mergesort den Vorteil, dass es keinen zusätzlichen Speicherbedarf hat, während Mergesort zusätzlichen Speicher in der Größenordnung O(n) benötigt.
Zusammenfassung
Heapsort ist ein effizienter, nicht stabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n log n) im average, best und worst case.
Heapsort ist deutlich langsamer als Quicksort und Mergesort, weshalb man Heapsort in der Praxis seltener antrifft.
Mergesort funktioniert nach dem „Teile-und-herrsche“-Prinzip („divide and conquer“):
Zunächst werden die zu sortierenden Elemente in zwei Hälften geteilt. Die entstandenen Sub-Arrays werden dann wieder geteilt – und wieder, bis Sub-Arrays der Länge 1 entstanden sind:
Nun werden in umgekehrter Richtung jeweils zwei Teil-Arrays so zusammengeführt („gemerged“), dass jeweils ein sortiertes Array entsteht. Im letzten Schritt werden die zwei Hälften des ursprünglichen Arrays gemerged, so dass dieses letztendlich sortiert ist.
Wie genau zwei Teil-Arrays zu einem gemerged werden, wirst du in folgendem Beispiel sehen.
Mergesort Merge Beispiel
Das Mergen an sich funktioniert ganz einfach: Für beide Arrays wird ein Merge-Index festgelegt, der zunächst auf das erste Element des jeweiligen Arrays zeigt. Am einfachsten lässt sich das an einem Beispiel zeigen (die Pfeile stellen den jeweiligen Merge-Index dar):
Die Elemente, auf die die Merge-Zeiger zeigen, werden verglichen. Das kleinere von beiden (im Beispiel die 1) wird an ein neues Arrays angehängt und der Zeiger, der auf dieses Element gezeigt hat, wird um ein Feld nach rechts verschoben:
Jetzt werden erneut die Elemente über den Zeigern verglichen. Dieses mal ist die 2 kleiner als die 4, somit wird die 2 an das neue Array angehängt:
Jetzt liegen die Zeiger auf der 3 und der 4. Die 3 ist kleiner und wird an das Ziel-Array angehängt:
Jetzt ist die 4 am kleinsten:
Jetzt die 5:
Und im letzten Schritt bleibt die 6 übrig und wird an das neue Array angehängt:
Die zwei sortierten Teil-Arrays wurden durch das Mergen zu einem sortierten Gesamt-Array.
Mergesort Beispiel
Hier noch mal ein Beispiel für den Gesamt-Algorithmus. Sortiert werden soll das aus den anderen Teilen der Serie bekannte Array [3, 7, 1, 8, 2, 5, 9, 4, 6].
Dieses wird zunächst solange geteilt, bis Arrays der Länge 1 entstehen. Die Anordnung der Elemente ändert sich dabei nicht:
Jetzt werden die Teil-Arrays in umgekehrter Richtung nach dem oben beschriebenen Prinzip gemerged. Im ersten Schritt werden die 4 und die 6 zum Teil-Array [4, 6] zusammengefasst:
Als nächstes werden die 3 und die 7 zum Teil-Array [3, 7] gemerged, 1 und 8 zum Teil-Array [1, 8], die 2 und die 5 werden zu [2, 5]. Bis hierhin standen die gemergeten Elemente zufällig in der richtigen Reihenfolge zueinander und wurden daher nicht verschoben.
Das ändert sich jetzt: Die 9 wird mit dem Teil-Array [4, 6] gemerged – dabei wandert die 9 ans Ende des neuen Teil-Arrays [4, 6, 9]:
[3, 7] und [1, 8] werden nun zu [1, 3, 7, 8] gemerged. [2, 5] und [4, 6, 9] werden zu [2, 4, 5, 6, 9]:
Und im letzten Schritt werden die zwei Teil-Arrays [1, 3, 7, 8] und [2, 4, 5, 6, 9] zum Endergebnis zusammengeführt:
Am Ende erhalten wir das sortierte Array [1, 2, 3, 4, 5, 6, 7, 8, 9]. Das folgende Diagramm zeigt alle Merge-Schritte zusammengefasst in einer Übersicht:
Mergesort Java Quellcode
Im folgenden findest du die einfachste Implementierung von Mergesort.
Zunächst ruft die Methode sort() die Methode mergeSort() auf und übergibt dieser das Array sowie dessen Start- und Endpositionen.
mergeSort() prüft, ob es für ein Teil-Array der Länge 1 aufgerufen wurde und, wenn ja, gibt eine Kopie dieses Teil-Arrays zurück.
Anderfalls wird das Array geteilt, und mergeSort() wird rekursiv für beide Teile aufgerufen. Die beiden Aufrufe liefern jeweils ein sortiertes Array zurück. Diese werden anschließend durch Aufruf der merge()-Methode zusammengeführt, und mergeSort() gibt dieses zusammengeführte, sortierte Array zurück.
Abschließend kopiert die sort()-Methode das sortierte Array zurück in das Eingabe-Array. Man könnte das sortierte Array auch direkt zurückgeben – das wäre allerdings inkompatibel zum Test-Framework.
publicclassMergeSort{
publicvoidsort(int[] elements){
int length = elements.length;
int[] sorted = mergeSort(elements, 0, length - 1);
System.arraycopy(sorted, 0, elements, 0, length);
}
privateint[] mergeSort(int[] elements, int left, int right) {
// End of recursion reached?if (left == right) returnnewint[]{elements[left]};
int middle = left + (right - left) / 2;
int[] leftArray = mergeSort(elements, left, middle);
int[] rightArray = mergeSort(elements, middle + 1, right);
return merge(leftArray, rightArray);
}
int[] merge(int[] leftArray, int[] rightArray) {
int leftLen = leftArray.length;
int rightLen = rightArray.length;
int[] target = newint[leftLen + rightLen];
int targetPos = 0;
int leftPos = 0;
int rightPos = 0;
// As long as both arrays contain elements...while (leftPos < leftLen && rightPos < rightLen) {
// Which one is smaller?int leftValue = leftArray[leftPos];
int rightValue = rightArray[rightPos];
if (leftValue <= rightValue) {
target[targetPos++] = leftValue;
leftPos++;
} else {
target[targetPos++] = rightValue;
rightPos++;
}
}
// Copy the restwhile (leftPos < leftLen) {
target[targetPos++] = leftArray[leftPos++];
}
while (rightPos < rightLen) {
target[targetPos++] = rightArray[rightPos++];
}
return target;
}
}Code-Sprache:Java(java)
(Die Begriffe „Zeitkomplexität“ und „O-Notation“ werden in diesem Artikel anhand von Beispielen und Diagrammen erklärt.)
Wir bezeichnen die Anzahl der Elemente mit n.
Da wir die (Sub-)Arrays immer wieder in zwei gleich große Teile aufteilen, benötigen wir bei einer Verdopplung der Anzahl der Elemente n nur eine einzige zusätzliche Stufe von Teilungen d. Folgendes Diagramm demonstriert, dass bei vier Elementen zwei Teilungsstufen benötigt werden und bei acht Elementen nur eine mehr:
Somit beträgt die Anzahl der Teilungsstufen log2 n.
Auf jeder Merge-Stufe müssen wir insgesamt n Elemente zusammenführen (auf der ersten n × 1, auf der zweiten Stufe n/2 × 2, auf der dritten Stufe n/4 × 4, usw.):
Der Merge-Vorgang enthält keine verschachtelten Schleifen, erfolgt also mit linearem Aufwand: Bei Verdoppelung der Array-Größe verdoppelt sich auch der Merge-Aufwand. Der Gesamtaufwand ist daher auf allen Merge-Stufen gleich.
Wir haben also n Elemente mal log2 n Teilungs- und Merge-Stufen. Damit gilt:
Die Zeitkomplexität von Mergesort beträgt: O(n log n)
Und zwar unabhängig davon, ob die Eingabeelemente vorsortiert sind oder nicht. Mergesort ist also für sortierte Eingabeelemente nicht schneller als für zufällig angeordnete.
Laufzeit des Java Mergesort-Beispiels
Genug der Theorie! Das Testprogramm UltimateTest misst die Laufzeit von Mergesort (und aller anderen Sortieralgorithmen dieser Artikelserie). Es geht dazu wie folgt vor:
Sortiert werden Arrays der Länge 1.024, 2.048, 4.096, usw… bis maximal 536.870.912 (= 229) oder so lange, bis ein Sortiervorgang länger als 20 Sekunden dauert.
Sortiert werden mit Zufallszahlen gefüllte Arrays, sowie aufsteigend und absteigend vorsortierte Zahlenfolgen.
In zwei WarmUp-Runden wird dem HotSpot-Compiler ausreichend Zeit gegeben, den Code zu optimieren.
Die Tests werden solange wiederholt, bis der Prozess abgebrochen wird. Hier ist das Ergebnis für Mergesort nach 50 Wiederholungen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
n
unsortiert
aufsteigend
absteigend
1.024
0,069 ms
0,032 ms
0,033 ms
2.048
0,141 ms
0,053 ms
0,056 ms
4.096
0,297 ms
0,109 ms
0,116 ms
8.192
0,604 ms
0,213 ms
0,228 ms
…
…
…
…
33.554.432
4.860,2 ms
1.954,7 ms
2.040,2 ms
67.108.864
9.623,2 ms
3.622,8 ms
3.815,7 ms
134.217.728
19.700,3 ms
6.542,1 ms
6.973,0 ms
268.435.456
40.852,4 ms
13.773,5 ms
14.708,2 ms
Hier die Messwerte als Diagramm:
Es lässt sich sehr gut sehen:
Die Laufzeit wächst in allen Fällen etwa linear mit der Anzahl der Elemente, entspricht also dem erwarteten quasi-linearen Aufwand – O(n log n).
Für vorsortierte Elemente ist Mergesort etwa dreimal schneller als für unsortierte Elemente.
Für absteigend vorsortierte Elemente benötigt Mergesort etwas mehr Zeit als für aufsteigend sortierte Elemente.
Wie lassen sich diese Unterschiede erklären?
Mit dem Programm CountOperations können wir die Anzahl der Operationen für die verschiedenen Fälle messen lassen. Die Anzahl der Schreiboperationen ist für alle Fälle gleich, da der Merge-Prozess – unabhängig von der Vorsortierung – alle Elemente der Teil-Arrays in ein neues Array kopiert.
Die Anzahl der Vergleiche unterscheidet sich jedoch; du findest sie in der folgenden Tabelle gegenübergestellt (das vollständige Ergebnis findest Du in der Datei CountOperations_Mergesort.log):
n
Vergleiche unsortiert
Vergleiche aufsteigend
Vergleiche absteigend
…
…
…
…
1.024
31.719
23.549
24.572
2.048
69.520
51.197
53.244
4.096
151.515
110.589
114.684
8.192
327.517
237.565
245.756
16.384
703.896
507.901
524.284
Laufzeitunterschied aufsteigend / absteigend sortierte Elemente
Der Unterschied zwischen aufsteigend und absteigend sortierten Elementen entspricht in etwa dem gemessenen Zeitunterschied. Der Grund für den Unterschied liegt in dieser Code-Zeile:
while (leftPos < leftLen && rightPos < rightLen)Code-Sprache:Java(java)
Bei aufsteigend sortierten Elementen werden zuerst alle Elemente des linken Teil-Arrays in das Ziel-Array kopiert, so dass leftPos < leftLen als erstes false ergibt und danach der rechte Term nicht mehr ausgewertet werden muss.
Bei absteigend sortierten Elementen werden zuerst alle Elemente des rechten Teil-Arrays kopiert, so dass rightPos < rightLen zuerst false ergibt. Da dieser Vergleich nachleftPos < leftLen ausgeführt wird, wird bei absteigend sortierten Elementen in jeder Merge-Runde einmal mehr der linke Vergleich leftPos < leftLen durchgeführt.
Würden wir die Zeile ändern in
while (rightPos < rightLen && leftPos < leftLen)Code-Sprache:Java(java)
… dann würde sich das Laufzeitverhältnis das Sortierens von aufsteigend zu absteigend vorsortierten Elementen entsprechend umkehren.
Laufzeitunterschied sortierte / unsortierte Elemente
Mergesort ist für vorsortierte Elemente etwa drei mal schneller als für unsortierte Elemente. Die Anzahl der Vergleichsoperationen unterscheidet sich allerdings nur um etwa ein Drittel.
Warum führt ein Drittel weniger Operationen zu dreimal schnellerer Abarbeitung?
Die Ursache liegt in der Sprungvorhersage (englisch „branch prediction“): Wenn die Elemente sortiert sind, dann sind die Resultate der Vergleiche in den Loop- und Branch-Statements
while (leftPos < leftLen && rightPos < rightLen)
und
if (leftValue <= rightValue)
bis zum Ende eines Merge-Vorgangs immer gleich. Somit kann die Befehls-Pipeline der CPU während des Mergens voll ausgenutzt werden.
Bei unsortierten Eingabedaten hingegen können die Resultate der Vergleiche nicht verlässlich vorhergesagt werden. Die Pipeline muss also ständig gelöscht und neu gefüllt werden.
Weitere Eigenschaften von Mergesort
Dieses Kapitel behandelt die Platzkomplexität von Mergesort, die Stabilität sowie die Parallelisierbarkeit.
Platzkomplexität von Mergesort
In der Merge-Phase werden Elemente aus zwei Teil-Arrays in ein neu erstelltes Ziel-Array kopiert. Im allerletzten Merge-Schritt ist das Ziel-Array genau so groß wie das zu sortierende Array. Wir haben also einen linearem Platzbedarf: Bei einem doppelt so großen Eingabe-Array verdoppelt sich auch der zusätzlich benötigte Speicherplatz. Es gilt also:
Die Platzkomplexität von Mergesort beträgt: O(n)
(Zur Erinnerung: Bei linearem Aufwand kann konstanter Platzbedarf für Hilfs- und Schleifenvariablen vernachlässigt werden.)
Dieser zusätzliche Speicherbedarf kann durch sogenannte In-Place-Verfahren umgangen werden; diese werden im Abschnitt „In-Place Mergesort“ behandelt.
Stabilität von Mergesort
In der Merge-Phase entscheiden wir mittels if (leftValue <= rightValue), ob das nächste Element aus dem linken oder rechten Teil-Array in das Ziel-Array kopiert wird. Wenn linker und rechter Wert gleich sind, wird also zuerst der linke kopiert und dann der rechte. Somit bleibt die Reihenfolge gleicher Elemente zueinander immer unverändert.
Mergesort ist demzufolge ein stabiles Sortierverfahren.
Parallelisierbarkeit von Mergesort
Es gibt grundsätzlich zwei Ansätze, um Mergesort zu parallelisieren:
Rekursive Aufrufe von mergeSort() können parallel ausgeführt werden; hierbei können allerdings heutige Mehrkern-CPUs in den letzten Merge-Stufen nicht voll ausgenutzt werden.
Die merge()-Methode selbst kann parallelisiert werden.
Im Abschnitt „Platzkomplexität“ haben wir festgestellt, dass Mergesort einen zusätzlichen Platzbedarf in der Größenordnung O(n) hat.
Es gibt verschiedene Ansätze, um den Merge-Vorgang ohne zusätzlichen Speicher (also „in place“) auskommen zu lassen.
Ein Ansatz ist folgender:
Wenn das Element über dem linken Merge-Zeiger kleiner oder gleich dem Element über dem rechten Merge-Zeiger ist, wird der linke Merge-Zeiger um ein Feld nach rechts verschoben.
Andernfalls werden alle Element vom ersten Zeiger bis zu, aber ausschließlich dem zweiten Zeiger um ein Feld nach rechts geschoben und das rechte Element auf den freigewordenen Platz gesetzt. Danach werden beide Zeiger um ein Feld nach rechts verschoben, ebenso die Endposition des linken Teil-Arrays.
In-Place Mergesort – Beispiel
Das folgende Beispiel zeigt diesen In-Place-Merge-Algorithmus am Beispiel von oben – gemerged werden sollen die Teil-Arrays [2, 3, 5] und [1, 4, 6].
Das linke Teil-Array ist gelb eingefärbt, das rechte orange und die fertig gemergten Elemente blau.
Im ersten Schritt tritt gleich der zweite Fall ein: Das rechte Element (die 1) ist kleiner als das linke. Es werden alle Elemente des linken Teil-Arrays um ein Feld nach rechts geschoben und das rechte Element wird an den Anfang gesetzt:
Im zweiten Schritt ist das linke Element (die 2) kleiner, daher wird lediglich der linke Suchzeiger ein Feld nach rechts verschoben:
Im dritten Schritt ist wieder das linke Element (die 3) kleiner, es wird also wieder der linke Suchzeiger verschoben:
Im vierten Schritt ist das rechte Element (die 4) kleiner als das linke. Der verbleibende Teil des linken Bereichs (nur noch die 5) wird also um ein Feld nach rechts geschoben und das rechte Element auf den freien Platz gesetzt:
Im fünften Schritt ist das linke Element (die 5) kleiner. Der linke Suchzeiger wird um eine Position nach rechts geschoben und hat damit das Ende des linken Bereichs erreicht:
Der In-Place-Merge-Vorgang ist damit abgeschlossen.
In-Place Mergesort – Zeitkomplexität
Wir haben die Merge-Phase jetzt zwar ohne zusätzlichen Speicherbedarf ausgeführt – allerdings haben wir uns dies teuer erkauft: Durch die zwei verschachtelten Schleifen hat die Merge-Phase nun eine Zeitkomplexität im average und worst case von O(n²) – statt vorher O(n).
Die Gesamt-Komplexität des Sortierverfahrens ist damit O(n² log n) – statt O(n log n). Der Algorithmus ist somit nicht mehr effizient.
Lediglich im best case, wenn die Zahlen vorab aufsteigend sortiert sind, bleibt die Zeitkomplexität innerhalb der Merge-Phase O(n) und die des Gesamt-Algorithmus O(n log n). Der Grund dafür ist, dass in diesem Fall die innere Schleife, die die Elemente des linken Teilarrays nach rechts verschiebt, nie ausgeführt wird.
In-Place Mergesort – Quellcode
Hier ist der Quellcode der merge()-Methode von In-Place Mergesort:
voidmerge(int[] elements, int leftPos, int rightPos, int rightEnd){
int leftEnd = rightPos - 1;
while (leftPos <= leftEnd && rightPos <= rightEnd) {
// Which one is smaller?int leftValue = elements[leftPos];
int rightValue = elements[rightPos];
if (leftValue <= rightValue) {
leftPos++;
} else {
// Move all the elements from leftPos to excluding rightPos one field// to the rightint movePos = rightPos;
while (movePos > leftPos) {
elements[movePos] = elements[movePos - 1];
movePos--;
}
elements[leftPos] = rightValue;
leftPos++;
leftEnd++;
rightPos++;
}
}
}Code-Sprache:Java(java)
Den vollständigen Quellcode findest du in der Klasse InPlaceMergeSort im GitHub-Repository.
Effiziente In-Place-Merge-Verfahren
Es gibt auch effizientere In-Place-Mergeverfahren, die eine Zeitkomplexität von O(n log n) erreichen und damit eine Gesamt-Zeitkomplexität von O(n (log n)²), diese sind jedoch sehr komplex, so dass ich sie hier nicht weiter behandeln werde.
Natural Mergesort
Natural Mergesort ist eine Optimierung von Mergesort: Es identifiziert vorsortierte Bereiche („runs“) in den Eingabedaten und merged diese jeweils miteinander. So wird das unnötige weitere Teilen und Mergen vorsortierter Teilfolgen vermieden. Komplett aufsteigend sortierte Eingabeelemente werden dementsprechend in der Größenordnung O(n) sortiert.
Je nach Implementierung werden auch absteigend sortierte Teilfolgen („descending runs“) erkannt und in umgekehrter Richtung gemerged. Diese Varianten erreichen auch für komplett absteigend sortierte Eingabedaten O(n).
Natural Mergesort – Beispiel
Die folgende Grafik zeigt Natural Mergesort am Beispiel unserer Zahlenfolge [3, 7, 1, 8, 2, 5, 9, 4, 6]. Im ersten Schritt werden die „runs“ identifiziert. In den folgenden Schritten werden diese gemerged:
Natural Mergesort – Quellcode
Der folgende Quellcode zeigt eine einfache Implementierung, bei der nur aufsteigend sortierte Bereiche identifiziert und gemerged werden:
publicvoidsort(int[] elements){
int numElements = elements.length;
int[] tmp = newint[numElements];
int[] starts = newint[numElements + 1];
// Step 1: identify runsint runCount = 0;
starts[0] = 0;
for (int i = 1; i <= numElements; i++) {
if (i == numElements || elements[i] < elements[i - 1]) {
starts[++runCount] = i;
}
}
// Step 2: merge runs, until only 1 run is leftint[] from = elements;
int[] to = tmp;
while (runCount > 1) {
int newRunCount = 0;
// Merge two runs eachfor (int i = 0; i < runCount - 1; i += 2) {
merge(from, to, starts[i], starts[i + 1], starts[i + 2]);
starts[newRunCount++] = starts[i];
}
// Odd number of runs? Copy the last oneif (runCount % 2 == 1) {
int lastStart = starts[runCount - 1];
System.arraycopy(from, lastStart, to, lastStart,
numElements - lastStart);
starts[newRunCount++] = lastStart;
}
// Prepare for next round...
starts[newRunCount] = numElements;
runCount = newRunCount;
// Swap "from" and "to" arraysint[] help = from;
from = to;
to = help;
}
// If final run is not in "elements", copy it thereif (from != elements) {
System.arraycopy(from, 0, elements, 0, numElements);
}
}Code-Sprache:Java(java)
Die Signatur der merge()-Methode unterscheidet sich hier wie folgt vom Beispiel oben:
Anstatt von Teil-Arrays wird hier das gesamte Ursprungs-Arrays sowie Positionsangaben der zu mergenden Bereiche übergeben.
Anstatt ein neues Array zurückzugeben, wird auch das Ziel-Array zum Befüllen an die Methode übergeben.
Der eigentliche Merge-Algorithmus bleibt der gleiche.
Das von Tim Peters entwickelte Timsort ist eine hoch optimierte Weiterentwicklung von Natural Mergesort, bei der unter anderem (Teil-)Arrays bis zu einer bestimmten Größe mit Insertion Sort sortiert werden.
Timsort ist der Standard-Sortieralgorithmus in Python. Im JDK wird es für alle nicht-primitiven Objekte verwendet, also in den folgenden Methoden:
Collections.sort(List<T> list)
Collections.sort(List<T> list, Comparator<? super T> c)
List.sort(Comparator<? super E> c)
Arrays.sort(T[] a, Comparator<? super T> c)
Arrays.sort(T[] a, int fromIndex, int toIndex, Comparator<? super T> c)
Mergesort vs. Quicksort
Wie schlägt sich Mergesort im Vergleich zu den im vorangegangenen Artikel behandelten Quicksort?
Das folgende Diagramm zeigt die Laufzeiten für unsortierte und aufsteigend sortierte Eingabedaten. Absteigend vorsortierte Elemente werden von beiden Algorithmen minimal langsamer verarbeitet als aufsteigend vorsortierte, ich habe sie deshalb der Übersichtlichkeit halber nicht in das Diagramm eingetragen.
Quicksort ist für eine Viertelmilliarde unsortierte Elemente etwa 50 % schneller als Mergesort. Für vorsortierte Elemente ist es sogar vier mal so schnell.
Der Grund liegt ganz einfach darin, dass beim Mergen immer alle Elemente kopiert werden. Bei Quicksort hingegen werden nur diejenigen Elemente verschoben, die sich in der falschen Partition befinden.
Mergesort hat gegenüber Quicksort den Vorteil, dass auch im worst case die Zeitkomplexität O(n log n) nicht überschritten wird und dass es stabil ist. Diese Vorteile erkauft man sich durch schlechtere Performance und einen zusätzlichen Platzbedarf in der Größenordnung O(n).
Zusamenfassung
Mergesort ist ein effizienter, stabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n log n) im best, average und worst case.
Mergesort hat in seiner Standardimplementierung eine zusätzliche Platzkomplexität von O(n) – diese kann durch eine In-Place-Sortierung umgangen werden, welche allerdings entweder sehr komplex ist oder die Zeitkomplexität des Algorithmus gravierend verschlechtert.
Die JDK-Methoden Collections.sort(), List.sort() und Arrays.sort() (letzteres für alle nicht-primitiven Objekte) verwenden Timsort: ein optimiertes Natural Mergesort, wobei vorsortierte Bereiche in den Eingabedaten erkannt und nicht weiter geteilt werden.
Wir beginnen mit Quicksort („Sort“ ist hier kein separates Wort, also nicht „Quick Sort“). Dieser Artikel:
beschreibt den Quicksort-Algorithmus,
zeigt dessen Quellcode in Java,
erklärt, wie man die Zeitkomplexität von Quicksort herleitet,
testet, ob die Performance der Java-Implementierung mit dem erwarteten Laufzeitverhalten übereinstimmt,
stellt mehrere Algorithmus-Optimierungen vor (Kombination mit Insertion Sort und Dual-Pivot Quicksort)
und misst und vergleicht auch deren Geschwindigkeit.
Die Quellcodes der Artikelserie findest du in meinem GitHub-Repository.
Quicksort Algorithmus
Quicksort funktioniert nach dem „Teile-und-herrsche“-Prinzip („divide and conquer“):
Als erstes teilen wir die zu sortierenden Elemente auf zwei Bereiche auf – einen mit kleinen Elementen (im folgenen Beispiel „A“) und einen mit großen Elementen (im Beispiel „B“).
Welche Elemente klein sind und welche groß, entscheidet dabei das sogenannte Pivot-Element. Das Pivot-Element kann ein beliebiges Element aus dem Eingabe-Array sein. (Welches man wählt, bestimmt die Pivot-Strategie, dazu später mehr.)
Das Array wird nun so umsortiert, dass
die Elemente, die kleiner als das Pivot-Element sind, im linken Bereich landen,
die Elemente, die größer als das Pivot-Element sind, im rechten Bereich landen,
und dass das Pivot-Element zwischen den zwei Bereichen positioniert wird – und damit automatisch an seiner endgültigen Position.
In folgendem Beispiel werden die Elemente [3, 7, 1, 8, 2, 5, 9, 4, 6] auf diese Art umsortiert. Als Pivot-Element habe ich das letzte Element des unsortierten Eingabe-Arrays gewählt (die orange gefärbte 6):
Dieses Aufteilen auf zwei Teil-Arrays nennt man Partitionieren. Wie die Partitionierung genau funktioniert, erfährst du im nächsten Abschnitt. Vorher zeige ich dir, wie der übergeordnete Algorithmus weitergeht.
Die Teil-Arrays links und rechts des Pivot-Elements sind nach der Partitionierung weiterhin unsortiert. Die Teil-Arrays werden nun ebenfalls partitioniert. Das Pivot-Element aus dem vorherigen Schritt, die 6, habe ich halbtransparent dargestellt, um die zwei Teil-Arrays besser erkennen zu können:
Nach der erneuten Partitionierung haben wir vier Bereiche: Aus A sind A1 und A2 entstanden; aus B sind B1 und B2 hervorgegangen. Die Bereiche A1, B1 und B2 bestehen aus nur noch einem Element und gelten damit als sortiert („beherrscht“ im Sinne von „Teile und herrsche“). Jetzt müssen wir nur noch das Teil-Array A2 partitionieren:
Die zwei in diesem Schritt aus A2 entstandenen Partitionen A2a und A2b haben wieder die Länge 1 und gelten damit als sortiert. Somit sind alle Teil-Arrays sortiert – und damit auch das gesamte Array:
Der Algorithmus ist damit beendet.
Wie die Aufteilung eines Arrays in zwei Bereiche funktioniert – die Partitionierung – erkläre ich im nächsten Abschnitt.
Quicksort Partitionierung
Die Aufteilung des Arrays in zwei Partitionen erfolgt, in dem wir von links beginnend nach Elementen suchen, die größer als das Pivot-Element sind, und von rechts beginnend nach Elementen, die kleiner sind als das Pivot-Element.
Diese Elemente werden dann jeweils vertauscht. Dies wiederholen wir solange, bis die linke und rechte Suchposition aufeinander getroffen oder aneinander vorbeigelaufen sind.
Im Beispiel von oben funktioniert das wie folgt:
Das erste Element von links, das größer als das Pivot-Element 6 ist, ist die 7.
Das erste Element von rechts, das kleiner als die 6 ist, ist die 4.
Wir vertauschen die 7 und die 4.
Die 3 befand sich bereits auf der richtigen Seite (kleiner als 6, also links). Ich habe sie schwächer eingefärbt, da wir sie nicht weiter betrachten müssen.
Wir suchen weiter und finden von links aus die 8 (die 1 ist schon auf der richtigen Seite, da kleiner als 6) und von rechts aus die 5 (die 9 ist ebenfalls bereits auf der richtigen Seite, da größer als 6). Wir vertauschen die 8 und die 5:
Nun treffen sich die linke und rechte Suchposition an der 2. Das Vertauschen endet hier. Da die 2 kleiner ist als das Pivot-Element, schieben wir den Suchzeiger noch eine Position nach rechts, auf die 8, so dass alle Elemente ab dieser Position größer oder gleich dem Pivot-Element sind und alle Elemente davor kleiner:
Damit das Pivot-Element am Anfang der rechten Partition steht, vertauschen wir noch die 8 mit der 6:
Die Partitionierung ist abgeschlossen: Die 6 befindet sich an der richtigen Position, die Zahlen links von der 6 sind kleiner und die Zahlen rechts davon größer. Wir haben also den Stand erreicht, der im vorangegangenen Abschnitt nach der ersten Partitionierung gezeigt wurde:
Das Pivot-Element
„Pivot“ ist französisch und bedeutet „Dreh- und Angelpunkt“.
Im vorangegangenen Beispiel habe ich jeweils das letzte Element eines (Teil-)Arrays als Pivot-Element ausgewählt. Diese Strategie hat den Vorteil, dass sie den Algorithmus besonders einfach macht; sie kann sich aber negativ auf die Performance auswirken.
Vorteil der Pivot-Strategie „letztes Element“
Der Vorteil ist, wie oben erwähnt, ein vereinfachter Algorithmus:
Da das Pivot-Element bei dieser Strategie garantiert im rechten Bereich liegt, brauchen wir es bei den Vergleichs- und Tauschoperationen nicht zu berücksichtigen. Außerdem können wir im letzten Schritt der Partitionierung bedenkenlos das erste Element des rechten Bereichs mit dem Pivot-Element vertauschen, um dieses an seine finale Position zu setzen.
Nachteil der Pivot-Strategie „letztes Element“
In der Praxis führt die Strategie zu Problemen bei vorsortierten Eingabedaten. Bei einem aufsteigend sortierten Array wäre das Pivot-Element in jeder Iteration das größte Element.
Damit würde das Array nicht mehr in zwei möglichst gleich große Partitionen aufgeteilt werden, sondern in eine leere (da kein Element größer ist als das Pivotelement), und eine der Länge n-1 (mit allen Elementen außer dem Pivot-Element).
Bei absteigend sortierte Eingabedaten wäre das Pivot-Element immer das kleinste Element, so dass die Partitionierung ebenfalls immer eine leere Partition und eine der Größe n-1 erzeugen würde.
Alternative Pivot-Strategien
Alternative Strategien für die Auswahl des Pivot-Elements sind z. B.:
das mittlere Element,
ein zufälliges Element,
der Median aus drei, fünf oder mehr Elementen.
Wählt man auf eine dieser Arten das Pivot-Element aus, erhöht sich die Wahrscheinlichkeit, dass die aus der Partitionierung hervorgehenden Teil-Arrays möglichst gleich groß sind.
Wie sich die Wahl der Pivot-Strategie auf die Performance auswirkt, werde ich im Laufe des Artikels erklären.
Warum nicht der Median?
Im optimalen Fall teilt das Pivot-Element das Array in zwei gleich große Hälften. Warum wählt man dann nicht einfach den Median aller Elemente als Pivot-Element?
Aus folgendem Grund: Um den Median zu bestimmen, müsste man das Array erst einmal sortieren. Wir definieren aber gerade erst den Sortieralgorithmus – wir stehen also vor einem klassischen Henne-Ei-Problem.
Quicksort Java Quellcode
Der folgende Java-Quellcode (Klasse QuicksortSimple im GitHub-Repository) verwendet der Einfachheit halber als Pivot-Element immer das rechte Element eines zu sortierenden (Teil-)Arrays.
Wie oben erläutert, ist dies keine gute Wahl, wenn die Eingabedaten bereits sortiert sein könnten. Diese Variante macht den Code aber zunächst einfacher zu verstehen.
publicclassQuicksortSimple{
publicvoidsort(int[] elements){
quicksort(elements, 0, elements.length - 1);
}
privatevoidquicksort(int[] elements, int left, int right){
// End of recursion reached?if (left >= right) {
return;
}
int pivotPos = partition(elements, left, right);
quicksort(elements, left, pivotPos - 1);
quicksort(elements, pivotPos + 1, right);
}
publicintpartition(int[] elements, int left, int right){
int pivot = elements[right];
int i = left;
int j = right - 1;
while (i < j) {
// Find the first element >= pivotwhile (elements[i] < pivot) {
i++;
}
// Find the last element < pivotwhile (j > left && elements[j] >= pivot) {
j--;
}
// If the greater element is left of the lesser element, switch themif (i < j) {
ArrayUtils.swap(elements, i, j);
i++;
j--;
}
}
// i == j means we haven't checked this index yet.// Move i right if necessary so that i marks the start of the right array.if (i == j && elements[i] < pivot) {
i++;
}
// Move pivot element to its final positionif (elements[i] != pivot) {
ArrayUtils.swap(elements, i, right);
}
return i;
}
}Code-Sprache:Java(java)
Erklärung des Quellcodes:
Die Methode sort() ruft quicksort() auf und übergibt das Array sowie die Start- und Endpositionen.
Die Methode quicksort() ruft zuerst die Methode partition() auf, um das Array zu partitionieren. Daraufhin ruft sie sich selbst rekursiv auf – einmal für das Teil-Array links des Pivot-Elements und einmal für das Teil-Array rechts des Pivot-Elements. Die Rekursion endet, wenn quicksort() für ein Sub-Array der Länge 1 oder 0 aufgerufen wird.
Die Methode partition() partitioniert das Array und gibt die Position des Pivot-Elements zurück. Die Variable i stellt den linken Suchzeiger dar, die Variabe j den rechten Suchzeiger. Die einzelnen Schritte der partition()-Methode sind im Code dokumentiert – sie entsprechen den Schritten des Beispiels aus dem Abschnitt „Quicksort Partitionierung“.
Quellcode für alternative Pivot-Strategien
Wollen wir nicht das rechte, sondern ein anderes Element als Pivot-Element verwenden, muss der Algorithmus erweitert werden. Es gibt drei Varianten:
Algorithmus-Variante 1
Die einfachste Variante ist es das gewählte Pivot-Element vorab mit dem rechten Element zu tauschen. In diesem Fall kann der restliche Quellcode unverändert bleiben.
Eine entsprechende Implementierung findest du in der Klasse QuicksortVariant1 im GitHub-Repository. In dieser Variante wird vor jeder Partitionierung die Methode findPivotAndMoveRight() aufgerufen, die entsprechend der gewählten Strategie das Pivot-Element auswählt und mit dem Element ganz rechts vertauscht.
Mögliche Pivot-Strategien sind im Enum PivotStrategy definiert und lauten:
RANDOM: ein zufälliges Element wird ausgewählt.
LEFT: das linke Element wird ausgewählt.
RIGHT: das rechte Element wird ausgewählt (entspricht letztendlich der oben abgedruckten Variante „QuicksortSimple“).
MIDDLE: das mittlere Element wird ausgewählt.
MEDIAN3: der Median aus drei Elementen des Arrays wird als Pivot-Element ausgewählt.
Algorithmus-Variante 2
In dieser Variante beziehen wir das Pivot-Element in den Tauschvorgang ein und tauschen Elemente, die größer oder gleich dem Pivot-Element sind mit Elementen, die kleiner als das Pivot-Element sind.
Wenn wir das Pivot-Element selbst vertauschen, müssen wir uns diese Positionsänderung merken.
Somit befindet sich das Pivot-Element vor dem letzten Schritt der Partitionierung im rechten Bereich und kann ohne weitere Prüfung mit dem ersten Element des rechten Bereichs getauscht werden.
In dieser Variante belassen wir das Pivot-Element während der Partitionierung zunächst an seinem Platz. Dies erreichen wir, in dem wir nur Elemente, die größer als das Pivot-Element sind mit Elementen tauschen, die kleiner als das Pivot-Element sind.
Im letzten Schritt der Partitionierung müssen wir dann prüfen, ob sich das Pivot-Element im linken oder rechten Bereich befindet. Befindet es sich im linken Bereich, müssen wir es mit dem letzten Element des linken Bereichs tauschen; befindet es sich im rechten Bereich, müssen wir es mit dem ersten Element des rechten Bereichs tauschen.
Wir bezeichnen im Folgenden die Anzahl der zu sortierenden Elemente mit n.
Zeitkomplexität im best case
Quicksort erreicht optimale Performance, wenn wir die Arrays und Teil-Arrays immer wieder in zwei gleich große Partitionen aufteilen.
Denn dann brauchen wir bei einer Verdopplung der Anzahl der Elemente n nur eine einzige zusätzliche Stufe von Partitionierungen p. Folgendes Diagramm zeigt, dass bei vier Elementen zwei Partitionierungsstufen benötigt werden und bei acht Elementen nur eine mehr:
Wir haben also eine Anzahl an Partitionierungsstufen von log2 n.
Auf jeder Partitionierungsstufe müssen wir insgesamt n Elemente auf linke und rechte Partition aufteilen (auf der ersten Ebene 1 × n, auf der zweiten 2 × n/2, auf der dritten 4 × n/4, usw.):
Diese Aufteilung erfolgt – aufgrund der einzelnen Schleife innerhalb der Partitionierung – mit linearem Aufwand: Bei Verdoppelung der Array-Größe verdoppelt sich auch der Partitionierungs-Aufwand. Der Gesamtaufwand ist daher auf allen Partitionierungsstufen gleich.
Wir haben also n Elemente mal log2 n Partitionierungsstufen. Damit gilt:
Die Zeitkomplexität von Quicksort beträgt im bestcase: O(n log n)
Zeitkomplexität im average case
Die durchschnittliche Zeitkomplexität lässt sich leider nicht ohne komplizierte Mathematik herleiten. Diese würde den Rahmen dieses Artikels sprengen. Ich verwiese hier auf den englischsprachigen Wikipedia-Artikel.
Dieser kommt zu dem Schluss, dass die durchschnittlich Anzahl der Vergleichsoperationen 1,39 n × log2 n beträgt – wir befinden uns also nach wie vor im quasilinearen Aufwand; es gilt:
Die Zeitkomplexität von Quicksort beträgt auch im average case: O(n log n)
Zeitkomplexität im worst case
Wenn das Pivot-Element immer das kleinste oder größte Element des (Teil-)Arrays ist (z. B. weil unsere Eingabedaten bereits sortiert sind und wir als Pivot-Element immer das letzte wählen), würde das Array nicht in zwei etwa gleich große Partitionen aufgeteilt werden, sondern in eine der Länge 0 (da kein Element größer als das Pivot-Element ist) und eine der Länge n-1 (alle Elemente bis auf das Pivot-Element).
Damit bräuchten wir n Partitionierungsstufen mit einem Partitionierungsaufwand der Größe n, n-1, n-2, usw:
Der Partitionierungsaufwand sinkt linear von n bis 0 – im Mittel beträgt er also ½ n. Bei n Partitionierungsstufen beträgt der Gesamtaufwand also n × ½ n = ½ n². Es gilt somit:
Die Zeitkomplexität von Quicksort beträgt im worst case: O(n²)
In der Praxis würde der Versuch ein aufsteigend oder absteigend vorsortiertes Array mit der Pivot-Strategie „rechtes Element“ zu sortieren sehr schnell an einer StackOverflowException scheitern, da die Rekursion so tief gehen müsste wie das Array groß ist.
Java Quicksort Laufzeit
Nach so viel Theorie zurück zur Praxis!
Mit dem Programm UltimateTest können wir die tatsächliche Performance von Quicksort (und allen anderen Algorithmen dieser Artikelserie) messen. Das Programm geht dabei wie folgt vor:
Es sortiert Arrays der Größe 1.024, 2.048, 4.096, usw. bis maximal 536.870.912 (= 229), bricht dabei allerdings ab, wenn ein einzelner Sortiervorgang 20 Sekunden oder länger benötigt.
Es wendet den Sortieralgorithmus auf unsortierte Eingabedaten, aufsteigend sortierte und absteigend sortierte Eingabedaten an.
Es durchläuft zunächst zwei Warmup-Phasen, um dem HotSpot-Compiler ausreichend Zeit zu geben, den Code zu optimieren.
Das ganze wird so oft wiederholt, bis der Prozess beendet wird.
Laufzeit-Messung der Quicksort-Algorithmus-Varianten
Zunächst müssen wir entscheiden, welche Algorithmus-Variante wir ins Rennen schicken wollen, um den Test nicht ausufern zu lassen. Dafür kombiniert das Programm CompareQuicksorts alle Varianten mit allen Pivot-Strategien und sortiert mit jeder Kombination 50 mal etwa 5,5 Millionen Elemente.
Für alle Algorithmus-Varianten ist die Pivot-Strategie RIGHT am schnellsten, dicht gefolgt von MIDDLE, danach mit etwas größerem Abstand MEDIAN3 (der Overhead ist hier offenbar größer als der Gewinn), und am langsamsten ist RANDOM (Zufallszahlen zu generieren ist teuer).
Für alle Pivot-Strategien ist Variante 1 am schnellsten, Variante 3 am zweitschnellsten und Variante 2 am langsamsten.
Laufzeit-Messungen für verschiedene Pivot-Strategien und Array-Größen
Aufgrund dieses Ergebnisses führe ich den UltimateTest mit Algorithmus-Variante 1 aus (Pivot-Element wird vorab mit dem rechten Element vertauscht).
In den folgenden Abschnitten findest du die Ergebnisse für die verschiedenen Pivot-Strategien nach 50 Iterationen (dies sind nur Auszüge; das vollständige Testergebnis findest du in UltimateTest_Quicksort.log).
Messergebnisse für Pivot-Strategie „rechtes Element“
n
unsortiert
aufsteigend
absteigend
1.024
0,051 ms
0,155 ms
0,158 ms
2.048
0,100 ms
0,578 ms
0,597 ms
4.096
0,208 ms
2,247 ms
2,322 ms
8.192
0,436 ms
8,906 ms
9,127 ms
16.384
0,920 ms
StackOverflow
StackOverflow
32.768
1,941 ms
StackOverflow
StackOverflow
…
…
…
…
33.554.432
3.099,994 ms
StackOverflow
StackOverflow
67.108.864
6.421,172 ms
StackOverflow
StackOverflow
134.217.728
13.305,377 ms
StackOverflow
StackOverflow
268.435.456
27.493,636 ms
StackOverflow
StackOverflow
Folgendes lässt sich ablesen:
Bei zufällig verteilten Eingabedaten verlängert sich die benötigte Zeit um etwas mehr als das doppelte, wenn sich die Größe des zu sortierenden Arrays verdoppelt. Dies entspricht der erwarteten quasi-linearen Laufzeit – O(n log n).
Bei aufsteigend oder absteigend sortierten Eingabedaten vervierfacht sich die benötigte Zeit bei verdoppelter Eingabegröße, hier haben wir also quadratische Zeit – O(n²).
Absteigend sortierte Daten zu sortieren dauert nur wenig länger als aufsteigend sortierte Daten zu sortieren.
Bei nur 8.192 Elementen wird für das Sortieren vorsortierter Eingabedaten bereits 23 mal so lange benötigt wie für das Sortieren unsortierter Daten.
Bei mehr als 8.192 Elementen kommt es bei vorsortierten Eingabedaten zur gefürchteten StackOverflowException.
Messergebnisse für Pivot-Strategie „mittleres Element“
n
unsortiert
aufsteigend
absteigend
…
…
…
…
16.777.216
1.508 ms
191,3 ms
227,0 ms
33.554.432
3.127 ms
409,5 ms
464,7 ms
67.108.864
6.486 ms
806,4 ms
942,9 ms
134.217.728
13.409 ms
1.727,2 ms
1.945,8 ms
268.435.456
27.740 ms
3.405,2 ms
3.959,2 ms
Es lässt sich ablesen:
Sowohl für unsortierte als auch sortierte Eingabedaten wird bei Verdoppelung der Array-Größe etwas mehr als die doppelte Zeit benötigt. Dies entspricht der erwarteten quasi-linearen Laufzeit – O(n log n).
Für bereits sortierte Eingabedaten ist der Algorithmus deutlich schneller als für zufällig angeordnete – und zwar sowohl für aufsteigend als auch für absteigend sortierte Daten.
Die Performance-Verlust durch den Vorabtausch des mittleren mit dem rechten Element beträgt in allen Tests mit unsortierten Eingabedaten weniger als 0,9 %.
Messergebnisse für Pivot-Strategie „Median aus drei Elementen“
n
unsortiert
aufsteigend
absteigend
…
…
…
…
16.777.216
1.589 ms
222,6 ms
249,0 ms
33.554.432
3.291 ms
473,2 ms
514,4 ms
67.108.864
6.807 ms
934,6 ms
1.039,1 ms
134.217.728
14.066 ms
1.980,5 ms
2.142,8 ms
268.435.456
29.041 ms
3.907,6 ms
4.349,2 ms
Es lässt sich ablesen:
Auch hier haben wir in allen Fällen quasi-linearen Aufwand – O(n log n).
Wie schon beim Vergleich der Algorithmus-Varianten ist die Pivot-Strategie „Median aus drei Elementen“ etwas langsamer als die Strategie „mittleres Element“.
Überblick über alle Messergebnisse
Hier findest du die Messergebnisse noch einmal als Diagramm (absteigend sortierte Eingabedaten habe ich der Übersicht halber weggelassen):
Man sieht noch einmal schön, dass die Strategie „Rechtes Element“ für aufsteigend sortierte Daten zu quadratischem Aufwand führt (rote Linie) und für unsortierte Daten am schnellsten ist (blaue Linie). Am zweitschnellsten (mit minimalem Abstand) ist die Pivot-Stragie „Mittleres Element“ (gelbe Linie).
Quicksort optimiert: Kombination mit Insertion Sort
Für sehr kleine Arrays ist Insertion Sort schneller als Quicksort, daher werden in der Praxis diese Algorithmen häufig kombiniert. D. h. (Sub-)Arrays werden ab einer bestimmten Größe nicht weiter partitioniert, sondern mit Insertion Sort sortiert.
Quicksort/Insertion Sort Quellcode
Die Quellcode-Änderungen gegenüber des Standard-Quicksorts sind sehr überschaubar und beschränken sich auf die quicksort()-Methode. Hier noch einmal die Methode aus dem Standard-Algorithmus:
privatevoidquicksort(int[] elements, int left, int right){
// End of recursion reached?if (left >= right) {
return;
}
int pivotPos = partition(elements, left, right);
quicksort(elements, left, pivotPos - 1);
quicksort(elements, pivotPos + 1, right);
}Code-Sprache:Java(java)
Und hier die optimierte Variante, wobei die Variablen insertionSort und partitioningAlgorithm Instanzen des Insertion-Sort- und des Quicksort-Algorithmus sind. Hinzugekommen ist hier lediglich der mit „Threshold for insertion sort reached?“ kommentierte Code-Block in der Mitte der Methode:
privatevoidquicksort(int[] elements, int left, int right){
// End of recursion reached?if (left >= right) {
return;
}
// Threshold for insertion sort reached?if (right - left < threshold) {
insertionSort.sort(elements, left, right + 1);
return;
}
int pivotPos = partitioningAlgorithm.partition(elements, left, right);
quicksort(elements, left, pivotPos - 1);
quicksort(elements, pivotPos + 1, right);
}Code-Sprache:Java(java)
Den kompletten Quellcode findest du in der Klasse QuicksortImproved im GitHub-Repository. Als Konstruktorparameter wird der Grenzwert für das Umschalten auf Insertion Sort, threshold, übergeben, sowie eine Instanz der zu verwendenden Quicksort-Variante.
Quicksort/Insertion Sort Performance
Das Programm CompareImprovedQuickSort misst die benötigte Zeit zum Sortieren von etwa 5,5 Millionen Elementen bei verschiedenen Grenzwerten für das Umschalten auf Insertion Sort.
Da das optimierte Quicksort nur Arrays ab einer gewissen Größe partitioniert, könnte der Einfluss der Pivot-Strategie und der Algorithmus-Variante eine andere Rolle spielen als bisher. Um dies zu berücksichtigen, testet das Programm die Grenzwerte für alle drei Algorithmus-Varianten sowie die Pivot-Strategien „Mitte“ und „Median aus drei Elementen“.
Wie auch in den vorangegangenen Tests performen hier Algorithmus-Variante 1 und Pivot-Strategie „Mittleres Element“ durchgehend am besten.
Hier die Messwerte für die gewählte Kombination und verschiedene Grenzwerte für das Umschalten auf Insertion Sort:
Grenzwert
Laufzeit
0 (= reguläres Quicksort)
492,6 ms
2
492,6 ms
4
476,1 ms
8
456,1 ms
16
436,0 ms
24
427,2 ms
32
423,1 ms
48
422,3 ms
64
425,3 ms
96
438,0 ms
128
454,9 ms
196
493,4 ms
Hier die Messwerte in grafischer Darstellung:
Resultat:
Durch das Umschalten auf Insertion Sort für (Sub-)Arrays, die 48 oder weniger Elemente enthalten, können wir die Laufzeit von Quicksort bei 5,5 Millionen Elementen auf etwa 85 % des ursprünglichen Wertes reduzieren.
Quicksort lässt sich noch weiter optimieren, in dem man nicht ein Pivot-Element verwendet, sondern zwei. Bei der Partitionierung werden die Elemente dann aufgeteilt in:
Elemente kleiner als das kleinere Pivot-Element,
Elemente größer als/gleich wie das kleinere Pivot-Element und kleiner als das größere Pivot-Element,
Elemente größer als/gleich wie das größere Pivot-Element.
Auch hier gibt es unterschiedliche Pivot-Strategien, z. B.:
Linkes und rechtes Element: Dies führt – analog zum regulären Quicksort – dazu, dass bei sortierten Elementen zwei Partitionen leer bleiben und eine Partition n-2 Elemente enthält. Dies wiederum resultiert in quadratischem Aufwand und StackOverflowExceptions schon bei vergleichsweise kleinen n.
Elemente an den Position „ein Drittel“ und „zwei Drittel“: Dies ist vergleichbar mit der Strategie „Mittleres Element“ im regulären Quicksort.
Das folgende Diagramm zeigt eine beispielhafte Partitionierung mit zwei Pivot-Elementen an den „Drittel“-Positionen:
Dual-Pivot Quicksort wird (mit zusätzlichen Optimierungen) im JDK von der Methode Arrays.sort() eingesetzt.
Dual-Pivot Quicksort Quellcode
Die quicksort()-Methode ruft sich – im Vergleich zum regulären Algorithmus – nicht für zwei, sondern für drei Partitionen rekursiv auf:
privatevoidquicksort(int[] elements, int left, int right){
// End of recursion reached?if (left >= right) {
return;
}
int[] pivotPos = partition(elements, left, right);
int p0 = pivotPos[0];
int p1 = pivotPos[1];
quicksort(elements, left, p0 - 1);
quicksort(elements, p0 + 1, p1 - 1);
quicksort(elements, p1 + 1, right);
}Code-Sprache:Java(java)
Die partition()-Methode ruft zunächst findPivotsAndMoveToLeftRight() auf, welche anhand der gewählten Pivot-Strategie die Pivot-Elemente auswählt und mit den Elementen links und rechts vertauscht (analog zum Vertauschen des Pivot-Elements mit dem rechten Elemente im regulären Quicksort).
Danach laufen wieder zwei Suchzeiger von links und rechts über das Array und vergleichen und tauschen die Elemente, so dass diese am Ende auf drei Partitionen aufgeteilt sind. Wie genau sie das tun, lässt sich anhand der sprechenden Variablennamen einigermaßen gut am Quellcode ablesen.
int[] partition(int[] elements, int left, int right) {
findPivotsAndMoveToLeftRight(elements, left, right);
int leftPivot = elements[left];
int rightPivot = elements[right];
int leftPartitionEnd = left + 1;
int leftIndex = left + 1;
int rightIndex = right - 1;
while (leftIndex <= rightIndex) {
// elements < left pivot element?if (elements[leftIndex] < leftPivot) {
ArrayUtils.swap(elements, leftIndex, leftPartitionEnd);
leftPartitionEnd++;
}
// elements >= right pivot element?elseif (elements[leftIndex] >= rightPivot) {
while (elements[rightIndex] > rightPivot && leftIndex < rightIndex) {
rightIndex--;
}
ArrayUtils.swap(elements, leftIndex, rightIndex);
rightIndex--;
if (elements[leftIndex] < leftPivot) {
ArrayUtils.swap(elements, leftIndex, leftPartitionEnd);
leftPartitionEnd++;
}
}
leftIndex++;
}
leftPartitionEnd--;
rightIndex++;
// move pivots to their final positions
ArrayUtils.swap(elements, left, leftPartitionEnd);
ArrayUtils.swap(elements, right, rightIndex);
returnnewint[]{leftPartitionEnd, rightIndex};
}Code-Sprache:Java(java)
Die Methode findPivotsAndMoveToLeftRight() arbeitet wie folgt:
Bei der Pivot-Strategie LEFT_RIGHT prüft sie, ob das ganz linke Element kleiner ist als das ganz rechte. Wenn nicht, werden beide vertauscht.
Bei der Strategie THIRDS werden zunächst die Elemente an den Positionen „ein Drittel“ (Variable first) und „zwei Drittel“ (Variable second) extrahiert. Danach folgt eine Reihe von if-Abfragen, die letztendlich bloß das größere der beiden Elemente nach ganz rechts setzt und das kleinere der beiden Elemente nach ganz links.
(Der Code wird dadurch so aufgebläht, dass zwei Sonderfälle berücksichtigt werden müssen: In sehr kleinen Partitionen könnte das erste Pivotelement auf das ganz linke Element fallen und das zweite Pivotelement auf das ganz rechte Element.)
privatevoidfindPivotsAndMoveToLeftRight(int[] elements,
int left, int right){
switch (pivotStrategy) {
case LEFT_RIGHT -> {
if (elements[left] > elements[right]) {
ArrayUtils.swap(elements, left, right);
}
}
case THIRDS -> {
int len = right - left + 1;
int firstPos = left + (len - 1) / 3;
int secondPos = right - (len - 2) / 3;
int first = elements[firstPos];
int second = elements[secondPos];
if (first > second) {
if (secondPos == right) {
if (firstPos == left) {
ArrayUtils.swap(elements, left, right);
} else {
// 3-way swap
elements[right] = first;
elements[firstPos] = elements[left];
elements[left] = second;
}
} elseif (firstPos == left) {
// 3-way swap
elements[left] = second;
elements[secondPos] = elements[right];
elements[right] = first;
} else {
ArrayUtils.swap(elements, firstPos, right);
ArrayUtils.swap(elements, secondPos, left);
}
} else {
if (secondPos != right) {
ArrayUtils.swap(elements, secondPos, right);
}
if (firstPos != left) {
ArrayUtils.swap(elements, firstPos, left);
}
}
}
default -> thrownew IllegalStateException("Unexpected value: " + pivotStrategy);
}
}Code-Sprache:Java(java)
Dual-Pivot Quicksort kombiniert mit Insertion Sort
Genau wie das reguläre Quicksort kann auch Dual-Pivot Quicksort mit Insertion Sort kombiniert werden. Die Quellcode-Änderungen entsprechen denen für das reguläre Quicksort (s. Abschnitt „Quicksort/Insertion Sort Quellcode“). Ich gehe daher hier nicht noch einmal im Detail darauf ein.
Es lohnt sich also bei Dual-Pivot-Quicksort (Sub-)Arrays mit 64 Elementen oder weniger mit Insertion Sort zu sortieren.
Vergleich aller Quicksort-Optimierungen
Mit dem in Abschnitt „Java Quicksort Laufzeit“ erwähnten UltimateTest vergleiche ich abschließend noch einmal die Performance folgender Algorithmen:
Reguläres Quicksort mit Pivot-Strategie „Mittleres Element“,
Quicksort kombiniert mit Insertion Sort und einem Schwellwert von 48,
Dual-Pivot Quicksort mit Pivot-Strategie „Elemente an den Positionen ein Drittel und zwei Drittel“,
Dual-Pivot Quicksort kombiniert mit Insertion Sort und einem Schwellwert von 64,
Arrays.sort() des JDK (die JDK-Entwickler haben ihren Dual-Pivot Quicksort-Algorithmus so weit optimiert, dass es sich bei diesem schon bei 44 Elementen lohnt auf Insertion Sort umzuschalten).
Zunächst einmal ist sehr schön der quasi-lineare Aufwand aller Varianten zu erkennen.
Die Performance von Dual-Pivot-Quicksort ist sichtbar besser als die des regulären Quicksort – bei einer Viertelmilliarde Elemente etwa 5 %. Die Kombinationen mit Insertion Sort bringen jeweils mindestens 10 % Performancegewinn.
An die Sortiermethode des JDK kommen die Eigenimplementierungen nicht ganz heran – es fehlen noch etwa 6 %. Die JDK-Methode wurde im Laufe der Jahre hoch optimiert. Wenn dich interessiert, wie genau, dann kannst du dir den Quellcode auf GitHub anschauen.
Außerdem ist gut zu erkennen, dass alle Varianten vorsortierte Daten deutlich schneller sortieren als unsortierte – und aufsteigend sortierte Daten etwas schneller als absteigend sortierte. Arrays.sort() ist auch für vorsortierte Daten optimiert, so dass die entsprechende Linie nur minimal über der Null-Linie liegt (172,7 ms bei einer Viertelmilliarde Elemente).
Weitere Eigenschaften von Quicksort
Als weitere Eigenschaften werden in diesem Kapitel die Platzkomplexität von Quicksort betrachtet, die Stabilität sowie die Parallelisierbarkeit.
Platzkomplexität von Quicksort
Für jede Rekursionsstufe brauchen wir zusätzlichen Speicher auf dem Stack. Im average und best case ist die maximale Rekursionstiefe durch O(log n) begrenzt (s. Abschnitt „Zeitkomplexität“).
Im worst case ist die maximale Rekursionstiefe n.
Der Algorithmus kann allerdings durch Endrekursion insoweit optimiert werden, dass immer nur die kleinere Partition durch Rekursion weiterverarbeitet wird und die größere durch Iteration.
Da die kleinere Teilpartition maximal halb so groß ist wie die Ausgangspartition (andernfalls wäre sie nicht die kleinere, sondern die größere Teilpartition), kommt es mit Endrekursion auch im worst case maximal zu einer Rekursionstiefe von log2 n.
Der zusätzliche Speicherbedarf pro Rekursionsstufe ist konstant. Somit gilt:
Die Platzkomplexität von Quicksort ist im best und average case und – bei Einsatz von Endrekursion auch im worst case – O(log n)
Stabilität von Quicksort
Durch die Art und Weise, wie Elemente innerhalb der Partitionierung auf die Teilbereiche aufgeteilt werden, können Elemente mit gleichem Key ihre ursprüngliche Reihenfolge ändern.
Hier ein simples Beispiel: Partitioniert werden soll das Array [7, 8, 7, 2, 6] mit der Pivot-Strategie „Rechtes Element“. (Die zweite 7 habe ich als 7′ gekennzeichnet, um sie von der ersten unterscheiden zu können.)
Das erste Element von links, das größer als die 6 ist, ist die erste 7. Das erste Element von rechts, das kleiner als die 6 ist, ist die 2. Es müssen also die erste 7 und die 2 vertauscht werden:
Die erste 7 befindet sich danach nicht mehr vor, sondern hinter der zweiten 7 (7′). Dies bleibt auch so, nachdem das erste Element der rechten Partition (die 8) mit dem Pivot-Element (der 6) vertauscht wurde:
Quicksort ist demzufolge nicht stabil.
Parallelisierbarkeit von Quicksort
Es gibt verschiedene Varianten Quicksort zu parallelisieren.
Zum einen lassen sich mehrere Partitionen parallel weiter partitionieren. Bei dieser Variante kann jedoch die erste Partitionierungsstufe gar nicht parallelisiert werden, in der zweiten Stufe können nur zwei Cores ausgelastet werden, in der dritten nur vier, usw.
Einen Vergleich der Laufzeiten von Quicksort und Mergesort findest du im Artikel über Mergesort.
Zusamenfassung
Quicksort ist ein effizienter, instabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n log n) im best und average case und O(n²) im worst case.
Für sehr kleine n ist Quicksort langsamer als Insertion Sort und wird daher in der Praxis in der Regel mit Insertion Sort kombiniert.
Die Methode Arrays.sort() im JDK verwendet eine Dual-Pivot Quicksort-Implementierung, die (Teil-)Arrays mit weniger als 44 Elementen mit Insertion Sort sortiert.
erklärt, wie man die Zeitkomplexität von Bubble Sort herleitet
und prüft, ob die Performance der eigenen Implementierung dem entsprechend der Zeitkomplexität erwarteten Laufzeitverhalten entspricht.
Die Quellcodes aller Artikel dieser Serie findest du in meinem GitHub-Repository.
Bubble Sort Algorithmus
Bei Bubble Sort (auch: „Bubblesort“) werden jeweils zwei aufeinanderfolgende Elemente miteinander verglichen und – wenn das linke Element größer ist als das rechte – werden diese vertauscht.
Diese Vergleichs- und Tauschoperationen führt man von links nach rechts über alle Elemente durch, so dass nach dem ersten Durchlauf das größte Element ganz rechts positioniert ist (besser gesagt: spätestens nach dem ersten Durchlauf – es kann auch schon vorher dort angekommen sein).
Diesen Prozess wiederholt man solange, bis es in einem Durchlauf zu keinem weiteren Vertauschen mehr kommt.
Bubble Sort Beispiel
Im folgenden zeige ich, wie man das Array [6, 2, 4, 9, 3, 7] mit Bubble Sort sortiert:
Vorbereitung
Wir teilen das Array gedanklich in einen linken, nicht sortierten, und einen rechten, sortierten Teil. Der rechte Teil ist zu Beginn leer:
Iteration 1
Wir vergleichen die ersten beiden Elemente, die 6 und die 2. Da die 6 kleiner ist, vertauschen wir die Elemente:
Nun vergleichen wir das zweite mit dem dritten Element, also die 6 mit der 4. Auch diese liegen in verkehrter Reihenfolge vor und werden vertauscht:
Wir vergleichen das dritte mit dem vierten Element, also die 6 mit der 9. Die 6 ist kleiner als die 9, also brauchen wir diese zwei Elemente nicht zu vertauschen.
Das vierte und fünfte Element, die 9 und die 3, müssen wiederum vertauscht werden:
Und zuletzt müssen das fünfte und sechste Elemente, die 9 und die 7, miteinander vertauscht werden. Danach ist die erste Iteration abgeschlossen.
Die 9 hat ihre finale Position erreicht und wir verschieben die Grenze zwischen den Bereichen um eine Position nach links:
Diese Bereichsgrenze zeigt uns in der nächsten Iteration, bis zu welcher Position die Elemente vergleichen werden müssen. Die Bereichsgrenze gibt es übrigens nur in der optimierten Variante von Bubble Sort. In der ursprünglichen Variante fehlt sie, so dass in jeder Iteration unnötigerweise bis zum Ende des Arrays verglichen wird.
Iteration 2
Wir starten erneut am Anfang des Arrays und vergleichen die 2 mit der 4. Diese liegen in korrekter Reihenfolge vor und müssen nicht vertauscht werden.
Das gleiche gilt für die 4 und die 6.
Die 6 und die 3 hingegen müssen vertauscht werden, um in richtiger Reihenfolge vorzuliegen:
Die 6 und die 7 liegen in korrekter Reihenfolge vor und müssen nicht vertauscht werden. Weiter brauchen wir nicht zu vergleichen, denn die 9 liegt bereits im sortierten Bereich.
Zuletzt schieben wir die Bereichsgrenze wieder um eine Position nach links, damit wir die letzten zwei Elemente, die 7 und die 9, nicht weiter betrachten müssen.
Iteration 3
Wieder starten wir am Anfang des Arrays. Die 2 und die 4 stehen korrekt zueinander. Die 4 und die 3 müssen vertauscht werden:
Die 4 und die 6 müssen nicht vertauscht werden. Die 7 und die 9 sind bereits sortiert. Damit ist diese Iteration auch schon beendet und wir schieben die Bereichsgrenze nach links:
Iteration 4
Wir beginnen wieder am Anfang des Arrays. Im unsortierten Bereich müssen weder die 2 und 3 noch die 3 und 4 vertauscht werden. Damit sind alle Elemente sortiert und wir können den Algorithmus beenden.
Herkunft des Namens
Wenn wir die Vertauschoperationen des vorherigen Beispiels animieren, steigen die Elemente nach und nach bis zu ihren Zielpositionen auf – ähnlich wie Luftblasen (english: „bubbles“), daher der Name „Bubble Sort“:
Bubble Sort Java Quellcode
Im folgenden findest Du die oben beschriebene, optimierte Implementierung von Bubble Sort.
Da in der ersten Iteration das größte Element bis ganz nach rechts wandert, in der zweiten Iteration das zweitgößte bis zur zweitletzten Position, usw., müssen wir in jeder Iteration ein Element weniger vergleichen als in der vorherigen.
(Im Beispiel im vorangegangenen Abschnitt hatte ich das durch die Bereichsgrenze dargestellt, die nach jeder Iteration um eine Position nach links wandert.)
Dazu dekrementieren wir in der äußeren Schleife den Wert max, beginnend bei elements.length - 1, in jeder Iteration um eins.
Die innere Schleife vergleicht dann jeweils zwei Elemente bis zur Position max miteinander und vertauscht diese, wenn das linke Element größer ist als das rechte.
Wurden in einer Iteration keine Elemente vertauscht (d. h. swapped ist false), endet der Algorithmus vorzeitig.
publicclassBubbleSortOpt1{
publicstaticvoidsort(int[] elements){
for (int max = elements.length - 1; max > 0; max--) {
boolean swapped = false;
for (int i = 0; i < max; i++) {
int left = elements[i];
int right = elements[i + 1];
if (left > right) {
elements[i + 1] = left;
elements[i] = right;
swapped = true;
}
}
if (!swapped) break;
}
}
}Code-Sprache:Java(java)
Die nicht-optimierte Variante – in der der Algorithmus in jeder Iteration alle Elemente bis zum Ende vergleicht – findest du in der Klasse BubbleSort.
In der Klasse BubbleSortOpt2 findest du einen theoretisch noch stärker optimierten Algorithmus. Es kann nämlich auch sein, dass nach der n-ten Iteration, nicht nur die letzten n Elemente sortiert sind, sondern mehr – je nachdem, wie die Elemente ursprünglich angeordnet waren.
Diese Variante zählt daher max nicht um jeweils 1 herunter, sondern setzt max nach jeder Iteration auf die Position desjenigen Elements, das zuletzt vertauscht wurde. Der Test CompareBubbleSorts zeigt allerdings, dass diese Variante in der Praxis langsamer ist:
----- Results after 50 iterations-----
BubbleSort -> fastest: 772.6 ms, median: 790.3 ms
BubbleSortOpt1 -> fastest: 443.2 ms, median: 452.7 ms
BubbleSortOpt2 -> fastest: 497.0 ms, median: 510.0 ms Code-Sprache:Klartext(plaintext)
Warum ist die zweite optimierte Variante langsamer? Meine Vermutung ist, dass das Speichern und das (innerhalb einer Iteration) mehrfache Aktualisieren der Position des zuletzt vertauschten Elements deutlich teurer ist als das (pro Iteration) maximal einmalige Ändern des swapped-Werts.
Bubble Sort Zeitkomplexität
Wir bezeichnen die Anzahl der zu sortierenden Elemente mit n, im Beispiel oben wäre n = 6.
Die zwei ineinander verschachtelten Schleifen lassen vermuten, dass wir es bei Bubble Sort mit quadratischem Aufwand zu tun haben, also einer Zeitkomplexität* von O(n²). Dies wäre dann der Fall, wenn beide Schleifen bis zu einem Wert iteratieren, der linear mit n steigt.
Bei Bubble Sort müssen wir best, worse und average case separat betrachten. Dies geschieht in den folgenden Unterabschnitten.
* Die Begriffe „Zeitkomplexität“ und „O-Notation“ (ausgesprochen „Groß O-Notation“) erkläre ich in diesem Artikel anhand von Beispielen und Diagrammen.
Zeitkomplexität im best case
Fangen wir mit dem einfachsten Fall an: Falls die Zahlen bereits aufsteigend sortiert sind, wird der Algorithmus in der ersten Iteration feststellen, dass keine Zahlenpaare vertauscht werden müssen und daraufhin umgehend terminieren.
Dabei muss der Algorithmus n-1 Vergleiche durchführen; also gilt:
Die Zeitkomplexität von Bubble Sort beträgt im best case: O(n)
Zeitkomplexität im worst case
Den worst case demonstriere ich an einem Beispiel. Nehmen wir an, wir wollen das absteigend sortierte Array [6, 5, 4, 3, 2, 1] mit Bubble Sort sortieren.
In der ersten Iteration wandert das größte Element, die 6, von ganz links nach ganz rechts. Die fünf Einzelschritte (Vertauschen der Paare 6/5, 6/4, 6/3, 6/2, 6/1) habe ich in der Abbildung weggelassen:
In der zweiten Iteration wird das zweitgrößte Element, die 5, von ganz links – über vier Zwischenschritte – an die vorletzte Position verschoben:
In der dritten Iteration wird die 4 – über drei Zwischenschritte – an die drittletzte Stelle geschoben:
In der vierten Iteration wird die 3 – über zwei Einzelschritte – an ihre finale Position verschoben:
Und zuletzt werden die 2 und die 1 vertauscht:
In Summe haben wir also 5 + 4 + 3 + 2 + 1 = 15 Vergleichs- und Tauschoperationen.
Das können wir auch wie folgt ausrechnen:
Sechs Elemente mal fünf Vergleichs- und Tauschoperationen; geteilt durch zwei, da im Mittel über alle Iterationen die Hälfte der Elemente verglichen und verschoben wird:
6 × 5 × ½ = 30 × ½ = 15
Ersetzen wir 6 durch n, erhalten wir:
n × (n – 1) × ½
Ausmultipliziert ergibt das:
½ (n² – n)
Die höchste Potenz von n in diesem Term ist n²; es gilt also:
Die Zeitkomplexität von Bubble Sort beträgt im worst case: O(n²)
Zeitkomplexität im average case
Die durchschnittliche Zeitkomplexität lässt sich bei Bubble Sort – im Gegensatz zu den meisten anderen Sortieralgorithmen – leider nicht auf anschauliche Art und Weise erklären.
Ohne dies mathematisch zu beweisen (das würde den Rahmen dieses Artikels sprengen) kann man grob sagen, dass man im average case etwa halb so viele Tauschoperationen hat wie im worst case, da sich etwa die Hälfte der Elemente im Vergleich zum Nachbarelement an der richtigen Position befindet. Die Anzahl der Tauschoperationen ist also:
¼ (n² – n)
Bei der Anzahl der Vergleichsoperationen wird es noch komplizierter, diese beträgt (Quelle: Wikipedia):
½ (n² – n × ln(n) – (? + ln(2) – 1) × n) + O(√n)
In beiden Termen ist die höchste Potenz von n wieder n², so dass gilt:
Die Zeitkomplexität von Bubble Sort beträgt im average case: O(n²)
Laufzeit des Java Bubble Sort-Beispiels
Überprüfen wir die Theorie mit einem Test! Im GitHub-Repository findest du das Programm UltimateTest, das Bubble Sort (und alle anderen in dieser Artikelserie vorgestellten Sortieralgorithmen) nach folgenden Kriterien testet:
für Array-Größen beginnend ab 1.024 Elementen, mit einer Verdoppelung nach jeder Iteration, bis entweder eine Array-Größe von 536.870.912 erreicht ist (= 229) oder ein Sortiervorgang länger als 20 Sekunden dauert;
für unsortierte, aufsteigend und absteigend vorsortierte Elemente;
mit zwei Warm-Up-Runden, um dem HotSpot-Compiler ausreichend Zeit zu geben, um den Code zu optimieren.
Das ganze wird so oft wiederholt, bis der Prozess abgebrochen wird. Nach jeder Wiederholung gibt das Program den Median aller bisherigen Messergebnisse aus.
Hier das Ergebnis für Bubble Sort nach 50 Iterationen:
n
unsortiert
absteigend
aufsteigend
…
…
…
…
8.192
61,73 ms
35,18 ms
0,004 ms
16.384
294,64 ms
141,16 ms
0,008 ms
32.768
1.272,07 ms
566,39 ms
0,015 ms
65.536
5.196,82 ms
2.267,85 ms
0,030 ms
131.072
20.903,54 ms
9.068,25 ms
0,060 ms
262.144
–
–
0,129 ms
…
…
…
…
536.870.912
–
–
192,509 ms
Dies ist nur ein Auszug, das vollständige Ergebnis findest Du hier.
Hier die Ergebnisse noch einmal als Diagramm:
Bei aufsteigend vorsortierten Elementen ist Bubble Sort so schnell, dass die Kurve keinen Ausschlag nach oben zeigt. Deshalb ist hier die Kurve noch einmal einzeln:
Es lässt sich sehr gut erkennen, …
dass sich die Laufzeit bei Verdopplung der Eingabemenge bei unsortierten und absteigend sortierten Elementen in etwa vervierfacht;
dass die Laufzeit bei aufsteigend sortierten Elementen linear wächst und um Größenordnungen kleiner ist als bei unsortierten Elementen;
dass die Laufzeit im average case etwas mehr als doppelt so hoch ist wie im worst case.
Die ersten zwei Beobachtungen entsprechen den Erwartungen.
Doch warum ist die Laufzeit im average case so viel höher als im worst case? Müssten wir dort nicht nur etwa halb so viele Tauschoperationen haben und zumindest minimal weniger Vergleiche – und dementsprechend eher die halbe Zeit als die doppelte?
Tausch- und Vergleichsoperationen im average und worst case
Um das zu prüfen, nutze ich das Programm CountOperations, um die Anzahl der verschiedenen Operationen anzeigen zu lassen. Hier sind die Ergebnisse für unsortierte und absteigend sortierte Elemente in einer Tabelle zusammengefasst:
n
Tauschen unsortiert
Tauschen absteigend
Vergleiche unsortiert
Vergleiche absteigend
…
…
…
…
…
128
8.050
16.256
8.136
8.255
256
31.854
65.280
32.893
32.895
512
128.340
261.632
130.767
131.327
1.024
528.004
1.047.552
524.475
524.799
2.048
2.111.760
4.192.256
2.097.546
2.098.175
…
…
…
…
…
Die Ergebnisse bestätigen die Annahme: Bei unsortierten Elementen haben wir etwa halb so viele Tauschoperationen und minimal weniger Vergleiche als bei absteigend sortierten Elementen.
Warum ist Bubble Sort für absteigend sortierte Elemente schneller als für zufällig verteilte Elemente?
Wie kann es sein, dass Bubble Sort bei absteigend sortierten Element trotz doppelt so vieler Tauschoperationen so viel schneller ist als bei zufällig angeordneten Elementen?
Die Ursache für diese Diskrepanz ist in der Sprungvorhersage (englisch „branch prediction“) zu finden:
Wenn die Elemente absteigend sortiert sind, dann ist das Resultat der Vergleichsoperation if (left > right) im unsortierten Bereich immer true und im sortierten Bereich immer false.
Wenn die Sprungvorhersage davon ausgeht, dass das Ergebnis eines Vergleichs immer dasselbe ist wie das des vorangegangenen Vergleichs, dann hat sie mit dieser Annahme – mit einer einzigen Ausnahme: an der Bereichsgrenze – immer Recht. Somit kann die Befehls-Pipeline der CPU die meiste Zeit voll ausgenutzt werden.
Bei unsortierten Daten hingegen können keine verlässlichen Vorhersagen über das Ergebnis des Vergleichs getroffen werden, so dass die Pipeline häufig gelöscht und neu gefüllt werden muss.
Weitere Eigenschaften von Bubble Sort
In diesem Abschnitt geht es um die Platzkomplexität, Stabilität und Parallelisierbarkeit von Bubble Sort.
Platzkomplexität von Bubble Sort
Bubble Sort benötigt neben der Schleifenvariablen max und den Hilfsvariablen swapped, left und right keinen zusätzlichen Speicherplatz.
Die Platzkomplexität von Bubble Sort ist somit O(1).
Stabilität von Bubble Sort
Dadurch, dass immer zwei nebeneinander liegende Elemente miteinander verglichen werden – und diese nur dann vertauscht werden, wenn das linke Element größer ist als das rechte, können Elemente mit gleichem Key niemals die Position relativ zueinander tauschen.
Dazu müssten, wie beispielsweise bei Selection Sort, zwei Elemente über mehr als eine Position hinweg ihre Plätze tauschen. Das kann hier nicht passieren.
Bubble Sort ist somit ein stabiler Sortieralgorithmus.
Parallelisierbarkeit von Bubble Sort
Es gibt zwei Ansätze, um Bubble Sort zu parallelisieren:
Ansatz 1 „Odd-even sort“
Man vergleicht parallel das erste mit dem zweiten Element, das dritte mit dem vierten, das fünfte mit dem sechsten, usw. und vertauscht die jeweiligen Elemente, wenn das linke größer ist als das rechte.
Danach vergleicht man das zweite Element mit dem dritten, das vierte mit dem fünften, das sechste mit dem siebten usw.
Diese zwei Schritte führt man abwechselnd durch, solange bis in beiden Schritten keine Elemente mehr vertauscht werden:
Die Synchronisation zwischen den Schritten (die Threads dürfen mit einem Schritt erst dann beginnen, wenn alle Threads den vorherigen Schritt beendet haben), erfolgt dabei mit einem Phaser.
Ansatz 2 „Divide and Conquer“
Man teilt das zu sortierende Array in so viele Bereiche („Partitionen“), wie man Cores zur Verfügung hat.
Nun führt man eine Bubble-Sort-Iteration in allen Partitionen parallel durch. Man wartet, bis alle Threads fertig sind, und vergleicht dann jeweils das letzte Element einer Partition mit dem ersten der nächsten Partition. Wenn auch damit alle Threads fertig sind, beginnt der Vorgang von vorne.
Diese Schritte wiederholt man solange, bis in allen Threads keine Elemente mehr vertauscht werden:
Auch hier wird zur Synchronisation der Threads ein Phaser verwendet. Tatsächlich ist ein Großteil des Codes beider Algorithmen gleich, da auch für den Odd-Even-Ansatz das Array in Partitionen aufgeteilt wird. Den gemeinsamen Code habe ich in die abstrakte Basisklasse BubbleSortParallelSort verschoben.
Bubble Sort parallel: Performance
Die Performance der parallelen Varianten vergleiche ich mit dem oben bereits genannten Test CompareBubbleSorts. Hier das Ergebnis für die parallelen Algorithmen, verglichen mit der schnellsten sequentiellen Variante:
----- Results after 50 iterations-----
BubbleSortOpt1 -> fastest: 443.2 ms, median: 452.7 ms
BubbleSortParallelOddEven -> fastest: 62.6 ms, median: 68.6 ms
BubbleSortParallelDivideAndConquer -> fastest: 126.8 ms, median: 145.7 ms Code-Sprache:Klartext(plaintext)
Die „odd-even“-Variante ist auf meiner 6-Core-CPU (12 virtuelle Kerne mit Hyper-Threading) und bei 20.000 unsortierten Elementen also 6,6 mal schneller als die sequentielle Variante.
Der „divide-and-conquer“-Ansatz ist nur 3,1 mal schneller. Dies dürfte daran liegen, dass jeder Thread im zweiten Teilschritt der Iteration jeweils nur einen Vergleich durchführt. Demgegenüber steht ein relativ hoher Synchronisationsaufwand durch den Phaser.
Zusammenfassung
Bubble Sort ist ein einfach zu implementierender, stabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n²) im average und worst case – und O(n) im best case.
Bubble Sort war das letzte einfache Sortierverfahren dieser Artikelserie; im nächsten Teil steigen wir mit Quicksort in die effizienten Sortierverfahren ein.
Selection Sort kann man im Grunde genommen auch mit Spielkarten darstellen. Ich kenne zwar niemanden, der seine Karten so aufnimmt, aber als Beispiel eignet es sich ganz gut ;-)
Hier legst du zunächst alle deine Karten offen vor dich auf den Tisch. Dann suchst du die kleinste Karte und nimmst sie nach links auf die Hand, danach die nächst größere und setzt sie rechts daneben, usw. bis du zuletzt die größte Karte aufnimmst und ganz rechts einsortierst.
Unterschied zu Insertion Sort
Bei Insertion Sort hatten wir die jeweils nächste unsortierte Karte genommen und dann in den sortierten Karten an der richtigen Stelle eingefügt („inserted“).
Selection Sort funktioniert gewissermaßen anders herum: Wir wählen („select“) die jeweils kleinste Karte aus den unsortierten Karten, um diese dann – eine nach der anderen – an die bereits sortierten Karten anzuhängen.
Selection Sort Algorithmus
Der Algorithmus lässt sich am einfachsten an einem Beispiel erklären. Im folgenden zeige ich, wie man das Array [6, 2, 4, 9, 3, 7] mit Selection Sort sortiert:
Schritt 1
Wir teilen das Array gedanklich in einen linken, sortierten Teil und einen rechten, unsortierten Teil. Der sortierte Bereich ist zu Beginn leer:
Schritt 2
Wir suchen im rechten, unsortierten Teil nach dem kleinsten Element. Dazu merken wir uns zunächst das erste Element, die 6. Wir gehen zum nächsten Feld, dort finden wir mit der 2 ein noch kleineres Element. Wir wandern über den Rest des Arrays auf der Suche nach einem noch kleineren Element. Da wir keines finden, bleibt es bei der 2. Diese setzen wir an die korrekte Position, indem wir sie mit dem Element auf dem ersten Platz tauschen. Im Anschluss schieben wir die Grenze zwischen den Array-Bereichen um eine Position nach rechts:
Schritt 3
Wir suchen erneut im rechten, unsortierten Teil nach dem kleinsten Element. Dieses mal ist es die 3; wir tauschen sie mit dem Element an der zweiten Position:
Schritt 4
Erneut suchen wir nach dem kleinsten Element im rechten Bereich. Es ist die 4. Diese befindet sich bereits an der richtigen Position, so dass hier keine Tauschoperation stattfinden muss und wir lediglich die Bereichsgrenze verschieben:
Schritt 5
Als kleinstes Element finden wir die 6 und tauschen sie mit dem Element am Anfang des rechten Teils, der 9:
Schritt 6
Von den verbleibenden zwei Elementen ist die 7 am kleinsten, wir vertauschen sie mit der 9:
Algorithmus beendet
Das letzte Element ist automatisch das größte und damit an der richtigen Position. Der Algorithmus ist beendet, und die Elemente sind fertig sortiert:
Selection Sort Java Quellcode
In diesem Abschnitt findest du eine einfache Java-Implementierung von Selection Sort.
Die äußere Schleife iteriert über die einzusortierenden Elemente und endet nach dem vorletzten Element. Wenn dieses sortiert ist, ist automatisch auch das letzte Element sortiert. Die Schleifenvariable i zeigt immer auf das erste Element des rechten, unsortierten Teils.
Als kleinstes Element min wird in jedem Schleifendurchlauf zunächst das erste Element des rechten Teils angenommen; dessen Position wird in minPos gespeichert.
Die innere Schleife iteriert dann vom zweiten Element des rechten Teils bis zu dessen Ende und weist min und minPos immer dann neu zu, wenn ein noch kleineres Element gefunden wird.
Nach dem Durchlauf der inneren Schleife werden die Elemente der Positionen i (Anfang des rechten Teils) und minPos ausgetauscht (es sei denn, es handelt sich um dasselbe Element).
publicclassSelectionSort{
publicstaticvoidsort(int[] elements){
int length = elements.length;
for (int i = 0; i < length - 1; i++) {
// Search the smallest element in the remaining arrayint minPos = i;
int min = elements[minPos];
for (int j = i + 1; j < length; j++) {
if (elements[j] < min) {
minPos = j;
min = elements[minPos];
}
}
// Swap min with element at pos iif (minPos != i) {
elements[minPos] = elements[i];
elements[i] = min;
}
}
}
}Code-Sprache:Java(java)
Wir bezeichnen die Anzahl der Elemente mit n, in unserem Beispiel ist n = 6.
Die zwei ineinander verschachtelten Schleifen sind ein Indiz dafür, dass wir es mit einer Zeitkomplexität* von O(n²) zu tun haben. Das wäre dann der Fall, wenn beide Schleifen bis zu einem Wert iterieren, der linear mit n steigt.
Bei der äußeren Schleife ist das offensichtlich der Fall: diese zählt bis n-1.
Wie sieht es mit der inneren Schleife aus?
Dies soll die folgende Grafik zeigen:
In jedem Schritt wird jeweils ein Vergleich weniger ausgeführt als es unsortierte Elemente gibt. In Summe sind es 15 Vergleiche – und zwar unabhängig davon, ob das Array vorab sortiert ist oder nicht.
Das lässt sich auch wie folgt berechnen:
Sechs Elemente mal fünf Schritte; geteilt durch zwei, da im Durchschnitt über alle Schritte die Hälfte der Elemente noch unsortiert ist:
6 × 5 × ½ = 30 × ½ = 15
Ersetzen wir 6 durch n, erhalten wir:
n × (n – 1) × ½
Ausmultipliziert ergibt das:
½ n² – ½ n
Die höchste Potenz von n in diesem Term ist n². Die Zeitkomplexität für das Suchen des kleinsten Elements beträgt somit O(n²) – auch „quadratischer Aufwand“ genannt.
Betrachten wir nun das Vertauschen der Elemente: In jedem Schritt (bis auf den letzten) wird entweder ein Element vertauscht oder keines, je nachdem, ob sich das jeweils kleinste Element bereits an der richtigen Position befindet oder nicht. Damit haben wir in Summe maximal n-1 Tauschopertionen, also eine Zeitkomplexität von O(n) – auch „linearer Aufwand“ genannt.
Für die Gesamtkomplexität zählt nur die höchste Komplexitätsklasse, daher gilt:
Die Zeitkomplexität von Selection Sort beträgt im average, best und worst case: O(n²)
* Die Begriffe „Zeitkomplexität“ und „O-Notation“ werden in diesem Artikel anhand von Beispielen und Diagrammen erklärt.
Laufzeit des Java Selection Sort-Beispiels
Genug der Theorie! Ich habe ein Testprogramm geschrieben, das die Laufzeit von Selection Sort (und aller anderen in dieser Serie behandelten Sortieralgorithmen) wie folgt misst:
Die Anzahl der zu sortierenden Elemente verdoppelt sich nach jeder Iteration von anfänglich 1.024 Elementen auf 536.870.912 (= 229) Elemente. Ein doppelt so großes Array lässt sich in Java nicht erstellen.
Wenn ein Test länger als 20 Sekunden dauert, wird das Array nicht weiter vergrößert.
Alle Tests werden mit unsortierten, sowie aufsteigend und absteigend vorsortierten Elementen durchgeführt.
Dem HotSpot-Compiler wird zwei WarmUp-Runden Zeit gelassen den Code zu optimieren, danach werden die Tests so lange wiederholt, bis der Prozess abgebrochen wird.
Nach jeder Wiederholung gibt das Programm den Median aller bisherigen Messergebnisse aus.
Hier ist das Ergebnis für Selection Sort nach 50 Wiederholungen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
n
unsortiert
aufsteigend
absteigend
…
…
…
…
16.384
27,9 ms
26,8 ms
65,6 ms
32.768
108,0 ms
105,4 ms
265,4 ms
65.536
434,0 ms
424,3 ms
1.052,2 ms
131.072
1.729,8 ms
1.714,1 ms
4.209,9 ms
262.144
6.913,4 ms
6.880,2 ms
16.863,7 ms
524.288
27.649,8 ms
27.568,7 ms
67.537,8 ms
Hier die Messwerte noch einmal als Diagramm (wobei ich „unsortiert“ und „aufsteigend“ aufgrund der fast identischen Werte als eine Kurve dargestellt habe):
Es lässt sich sehr gut erkennen,
dass sich die Laufzeit bei Verdoppelung der Anzahl der Elemente in etwa vervierfacht – und zwar unabhängig davon, ob die Elemente vorsortiert sind oder nicht. Dies entspricht der erwarteten Zeitkomplexität O(n²).
dass die Laufzeit bei aufsteigend sortierten Elementen minimal besser ist als bei unsortierten Elementen. Dies liegt daran, dass hier die Tauschoperationen wegfallen, welche – wie zuvor analysiert – kaum ins Gewicht fallen.
dass die Laufzeit bei absteigend sortierten Elementen deutlich schlechter ist als bei unsortierten Elementen.
Wieso ist das so?
Analyse der worst case-Laufzeit
Das Suchen des jeweils kleinsten Elements sollte doch theoretisch – unabhängig von der Ausgangslage – immer gleich lang dauern; und die Tauschoperationen sollten bei absteigend sortierten Elementen nur minimal mehr sein (bei absteigend sortierten Elementen müsste jedes getauscht werden; bei unsortierten geschätzt fast jedes).
Mit dem Programm CountOperations aus meinem GitHub-Repository können wir uns die Anzahl der verschiedenen Operationen anzeigen lassen. Hier die Ergebnisse für unsortierte und absteigend sortierte Elemente in einer Tabelle zusammengefasst:
n
Vergleiche
Tauschen unsortiert
Tauschen absteigend
minPos/min unsortiert
minPos/min absteigend
…
…
…
…
…
…
512
130.816
504
256
2.866
66.047
1.024
523.776
1.017
512
6.439
263.167
2.048
2.096.128
2.042
1.024
14.727
1.050.623
4.096
8.386.560
4.084
2.048
30.758
4.198.399
8.192
33.550.336
8.181
4.096
69.378
16.785.407
Aus den Messwerten lässt sich erkennen:
Bei absteigend sortierten Elementen haben wir – wie erwartet – genauso viele Vergleichsoperationen wie bei unsortierten Elementen – nämlich n × (n-1) / 2.
Bei unsortierten Elementen haben wir – wie vermutet – beinahe so viele Tauschoperationen wie Elemente: bei 4.096 unsortierten Elementen sind es beispielsweise 4.084 Tauschoperationen. Diese Zahlen ändern sich zufallsbedingt leicht von Test zu Test.
Bei absteigend sortierten Elementen haben wir allerdings nur halb so viele Tauschoperationen wie Elemente! Dies liegt daran, dass wir beim Vertauschen nicht nur jeweils das kleinste Element an die richtige Stelle setzen, sondern auch den jeweiligen Tauschpartner.
Bei acht Elementen haben wir beispielsweise vier Tauschoperationen. In den ersten vier Iterationen jeweils eine und in den Iterationen fünf bis acht keine mehr (dennoch läuft der Algorithmus bis zum Ende weiter):
Des weiteren lässt sich an den Messwerten ablesen:
Den Grund, warum Selection Sort bei absteigend sortierten Elementen so deutlich langsamer ist, finden wir in der Anzahl der lokalen Variablenzuweisungen (minPos und min) bei der Suche nach dem kleinsten Element: Während wir bei 8.192 unsortierten Elementen 69.378 dieser Zuweisungen haben, sind es bei absteigend sortierten Elementen 16.785.407 Zuweisungen – das sind 242 mal so viele!
Warum dieser massive Unterschied?
Analyse der Laufzeit der Suche nach dem kleinsten Element
Für absteigend sortierte Elemente lässt sich die Größenordnung an der Grafik von soeben herleiten: Die Suche nach dem kleinsten Element beschränkt sich auf das Dreieck aus den orangenen und orange-blauen Kästchen. Im oberen, orangenen Teil werden die Zahlen in jedem Feld kleiner, im rechten orange-blauen Teil steigen die Zahlen wieder an.
Zuweisungsoperationen finden in jedem orangenen Kästchen statt sowie im jeweils ersten der orange-blauen. Die Anzahl der Zuweisungsoperationen für minPos und min ist also bildlich gesprochen in etwa „ein Viertel des Quadrats“ – mathematisch und ganz exakt sind es: ¼ n² + n – 1.
Für unsortierte Elemente müssten wir deutlich tiefer in die Materie eindringen. Dies würde nicht nur den Rahmen dieses Artikels, sondern des gesamten Blogs, sprengen.
Ich beschränke meine Analyse daher auf ein kleines Demo-Programm, welches misst, wie viele minPos/min-Zuweisungen es bei der Suche nach dem kleinsten Element in einem unsortierten Array gibt. Hier die durchschnittlichen Werte nach 100 Iterationen (ein kleiner Auszug; die kompletten Ergebnisse findest Du hier):
n
durchschnittliche Anzahl minPos/min-Zuweisungen
1.024
7.08
4.096
8.61
16.385
8.94
65.536
11.81
262.144
12.22
1.048.576
14.26
4.194.304
14.71
16.777.216
16.44
67.108.864
17.92
268.435.456
20.27
Hier das ganze als Diagramm mit logarithmischer x-Achse:
Am Diagramm sieht man sehr schön, dass wir hier ein logarithisches Wachstum haben, d. h. mit jeder Verdoppelung der Anzahl der Elemente erhöht sich die Anzahl der Zuweisungen nur um einen konstanten Wert. Auf die mathematischen Hintergründe gehe ich, wie gesagt, hier nicht weiter ein.
Dies ist der Grund, warum diese minPos/min-Zuweisungen bei unsortierten Arrays kaum ins Gewicht fallen.
Weitere Eigenschaften von Selection Sort
Im folgenden werden die Platzkomplexität, Stabilität und Parallelisierbarkeit von Selection Sort behandelt.
Platzkomplexität von Selection Sort
Die Platzkomplexität von Selection Sort ist konstant, da wir außer den Schleifenvariablen i und j, sowie den Hilfsvariablen length, minPos und min keinen zusätzlichen Speicherplatz benötigen.
D. h. egal wie viele Elemente wir sortieren – zehn oder zehn Millionen – wir benötigen immer nur diese fünf zusätzlichen Variablen. Konstanten Aufwand notiert man als O(1).
Stabilität von Selection Sort
Selection Sort erscheint auf den ersten Blick stabil: Wenn im unsortierten Teil mehrere Elemente mit dem gleichen Key vorkommen, sollte das erste davon doch auch als erstes an den sortierten Teil angehängt werden.
Doch der Schein trügt. Denn durch das Tauschen zweier Elemente im zweiten Teilschritt des Algorithmus kann es passieren, dass bestimmte Elemente im unsortierten Teil nicht mehr die ursprüngliche Reihenfolge haben. Dies führt dann wiederum dazu, dass sie letztlich auch im sortierten Teil nicht mehr in der ursprünglichen Reihenfolge erscheinen.
Ein Beispiel kann sehr einfach konstruiert werden. Angenommen wir haben zwei unterschiedliche Elemente mit dem Key 2 und eines mit dem Key 1, die wie folgt angeordnet sind, und sortieren diese mit Selection Sort:
Im ersten Schritt werden das erste und letzte Element vertauscht. Damit landet das Element „TWO“ hinter dem Element „two“ – die Reihenfolge beider Elemente ist vertauscht.
Im zweiten Schritt vergleicht der Algorithmus die beiden hinteren Elemente. Beide haben den gleichen Key, 2. Es wird also kein Element vertauscht.
Im dritten Schritt verbleibt nur ein Element, dieses gilt automatisch als sortiert.
Die zwei Elemente mit dem Key 2 sind also gegenüber ihrer Ausgangsreihenfolge vertauscht worden – der Algorithmus ist unstabil.
Stabile Variante von Selection Sort
Selection Sort kann stabil gemacht werden, indem in Schritt zwei das kleinste Element nicht mit dem ersten vertauscht wird, sondern zwischen dem ersten und dem kleinsten Elemente alle Elemente um eine Position nach rechts geschoben werden und das kleinste Element an den Anfang gesetzt wird.
Auch wenn die Zeitkomplexität durch diese Änderung gleichbleiben wird, führen die zusätzlichen Verschiebungen zu einer deutlichen Verschlechterung der Performance, zumindest wenn wir ein Array sortieren.
Bei einer verketteten Liste könnte das Ausschneiden und Einfügen des einzusortierenden Elements ohne signifikanten Performanceverlust durchgeführt werden.
Parallelisierbarkeit von Selection Sort
Die äußere Schleife ist nicht parallelisierbar, da diese den Inhalt des Arrays in jedem Schritt ändert.
Die innere Schleife (Suche nach dem kleinsten Element) kann parallelisiert werden, in dem das Array aufgeteilt wird, in jedem Teilarray parallel das kleinste Element gesucht wird, und dann die Zwischenergebnisse zusammengeführt werden.
Selection Sort vs. Insertion Sort
Welcher Algorithmus ist schneller, Selection Sort oder Insertion Sort?
Im folgenden stelle ich die Messwerte aus meinen Java-Implementierungen gegenüber. Den best case lasse ich außen vor; dieser hat bei Insertion Sort eine Zeitkomplexität von O(n) und hat bis zu 524.288 Elementen weniger als eine Millisekunde gebraucht – ist also in jedem Fall um Größenordnungen schneller als Selection Sort.
n
Selection Sort unsortiert
Insertion Sort unsortiert
Selection Sort absteigend
Insertion Sort absteigend
…
…
…
…
…
16.384
27,9 ms
21,9 ms
65,6 ms
43,6 ms
32.768
108,0 ms
87,9 ms
265,4 ms
175,8 ms
65.536
434,0 ms
350,4 ms
1.052,2 ms
697,6 ms
131.072
1.729,8 ms
1.398,9 ms
4.209,9 ms
2.840,0 ms
262.144
6.913,4 ms
5.706,8 ms
16.863,7 ms
11.517,4 ms
524.288
27.649,8 ms
23.009,7 ms
67.537,8 ms
46.309,3 ms
Und noch einmal als Diagramm:
Insertion Sort ist also nicht nur im best case, sondern auch im average und worst case schneller als Selection Sort.
Der Grund dafür ist, dass Insertion Sort mit durchschnittlich halb so vielen Vergleichen auskommt. Zur Erinnerung: bei Insertion Sort haben wir Vergleiche und Verschiebungen bis durchschnittlich zur Hälfte der sortierten Elemente; bei Selection Sort müssen wir in jedem Schritt in allen unsortierten Elementen das kleinste Element suchen.
Bei Selection Sort haben wir deutlich weniger Schreiboperationen, so dass Selection Sort schneller sein kann, wenn Schreiboperationen teuer sind. Beim sequentiellen Schreiben in Arrays ist das nicht der Fall, da dies größtenteils im CPU-Cache erfolgt.
In der Praxis wird daher so gut wie ausschließlich Insertion Sort angewendet.
Zusamenfassung
Selection Sort ist ein einfach zu implementierender, in der Standardimplementierung nicht stabiler Sortiergorithmus mit einer Zeitkomplexität von O(n²) im average, best und worst case.
Selection Sort ist langsamer als Insertion Sort, weshalb es in der Praxis nicht angewendet wird.
und überprüft, ob die Performance der Java-Implementierung mit dem erwarteten Laufzeitverhalten übereinstimmt.
Die Quellcodes der gesamten Artikelserie findest du in meinem GitHub-Repository.
Beispiel: Sortieren von Spielkarten
Beginnen wir mit einem Spielkartenbeispiel.
Stell dir vor, du bekommst eine Karte nach der anderen gereicht. Du nimmst die erste Karte auf die Hand. Die zweite sortierst du dann links oder rechts davon ein. Die dritte je nach Größe links, dazwischen oder rechts; und auch die folgenden Karten jeweils an der richtigen Stelle:
Hast du so schon einmal Karten sortiert?
Wenn ja, dann hast du intuitiv „Insertion Sort“ angewendet (seltener: „Insertionsort“, auf deutsch „Einfüge-Sortieren“).
Insertion Sort Algorithmus
Kommen wir vom Kartenbeispiel zum Computeralgorithmus. Nehmen wir an, wir haben ein Array mit den Elementen [6, 2, 4, 9, 3, 7]. Dieses Array soll mit Insertion Sort aufsteigend sortiert werden.
Schritt 1
Zuerst teilen wir das Array gedanklich in einen linken, sortierten Teil und einen rechten, unsortierten Teil. Der sortierte Bereich enthält zu Beginn bereits das erste Element, da ein Array mit einem einzigen Element immer als sortiert angesehen werden kann.
Schritt 2
Dann betrachten wir das erste Element des unsortierten Bereichs und prüfen, an welcher Stelle im sortierten Bereich dieses eingefügt werden muss, in dem wir es mit seinem linken Nachbarn vergleichen.
Im Beispiel ist die 2 kleiner als die 6, gehört damit also links neben die 6. Um dort Platz zu machen, schieben wir die 6 um eine Position nach rechts und setzen die 2 dann auf das freigewordene Feld. Dann schieben wir die Grenze zwischen sortiertem und unsortiertem Bereich um eine Position nach rechts:
Schritt 3
Wir betrachten wieder das erste Element des unsortierten Bereichs, die 4. Diese ist kleiner als die 6, aber nicht kleiner als die 2 und gehört somit zwischen die 2 und die 6. Wir schieben also die 6 erneut um ein Feld nach rechts und setzen die 4 auf das freigewordene Feld:
Schritt 4
Das nächste zu sortierende Element ist die 9. Diese ist größer als ihr linker Nachbar 6, und damit größer als alle Elemente des sortierten Bereichs. Sie ist also bereits an der richtigen Stelle, so dass wir in diesem Schritt kein Element verschieben müssen:
Schritt 5
Das nächste Element ist die 3. Diese ist kleiner als die 9, die 6 und die 4, aber größer als die 2. Wir schieben daher die 9, 6 und 4 um je ein Feld nach rechts und setzen dann die 3 an die Stelle, an der die 4 zuvor war:
Schritt 6
Bleibt noch die 7 – sie ist kleiner als die 9, aber größer als die 6. Also schieben wir die 9 um ein Feld nach rechts und setzen die 7 auf die freigewordene Position:
Damit ist das Array fertig sortiert.
Insertion Sort Java Quellcode
Der folgende Java-Quellcode zeigt, wie einfach man Insertion Sort implementieren kann.
Die äußere Schleife iteriert – beginnend beim zweiten Element, da das erste ja bereits als sortiert gilt – über die einzusortierenden Elemente. Die Schleifenvariable i zeigt also immer auf das erste Element des rechten, unsortierten Teils.
In der inneren while-Schleife erfolgt die Suche nach der Einfügeposition und das Verschieben der Elemente kombiniert:
das Suchen in der Schleifenbedingung: bis das Element links von der Suchposition j kleiner ist als das einzusortierende Element,
und das Verschieben der sortierten Elemente im Schleifenrumpf.
publicclassInsertionSort{
publicstaticvoidsort(int[] elements){
for (int i = 1; i < elements.length; i++) {
int elementToSort = elements[i];
// Move element to the left until it's at the right positionint j = i;
while (j > 0 && elementToSort < elements[j - 1]) {
elements[j] = elements[j - 1];
j--;
}
elements[j] = elementToSort;
}
}
}Code-Sprache:Java(java)
Der abgebildete Code unterscheidet sich in zwei Punkten vom Code im GitHub-Repository: Die Klasse InsertionSort im Repository implementiert zum einen das Interface SortAlgorithm, um innerhalb meines Testframeworks einfach austauschbar zu sein.
Zum anderen erlaubt sie die Angabe von Start- und Endindex, um auch Sub-Arrays sortieren zu können. Dies wird es uns später ermöglichen Quicksort zu optimieren, indem wir Teilarrays, die eine gewisse Größe unterschreiten, mit Insertion Sort sortieren lassen, anstatt diese weiter aufzuteilen.
Insertion Sort Zeitkomplexität
Wir bezeichnen die Anzahl der zu sortierenden Elemente mit n, im Beispiel oben wäre n = 6.
Die zwei ineinander verschachtelten Schleifen sind ein Indiz dafür, dass wir es mit quadratischem Aufwand zu tun haben, also mit einer Zeitkomplexität von O(n²)*. Das wäre dann der Fall, wenn sowohl die äußere als auch die innere Schleife bis zu einem Wert zählen, der linear mit der Anzahl der Elemente steigt.
Bei der äußeren Schleife ist das offensichtlich, da diese bis n zählt.
Und die innere Schleife? Diese analysieren wir in den nächsten drei Abschnitten.
* Die Begriffe „Zeitkomplexität“ und „O-Notation“ (ausgesprochen „Groß O-Notation“) erkläre ich in diesem Artikel anhand von Beispielen und Diagrammen.
Zeitkomplexität im average case
Schauen wir uns noch einmal das Beispiel von oben an, in dem wir das Array [6, 2, 4, 9, 3, 7] sortiert haben.
Im ersten Schritt des Beispiels haben wir das erste Element als bereits sortiert definiert; im Quellcode wird dieses einfach übersprungen.
Im zweiten Schritt haben wir ein Element aus dem sortierten Array verschoben. Wäre das einzusortierende Element bereits an der richtigen Stelle gewesen, hätten wir nichts verschieben müssen. Das heißt, dass wir im Durchschnitt im zweiten Schritt 0,5 Verschiebe-Operationen haben.
Im dritten Schritt haben wir ebenfalls ein Element verschoben. Hier hätten es aber auch null oder zwei Verschiebungen sein können. Im Durchschnitt ist es in diesem Schritt eine Verschiebung.
In Schritt vier brauchten wir keine Elemente zu verschieben. Es hätten hier aber auch ein, zwei oder drei Verschiebungen nötig sein können, im Durchschnitt sind es hier 1,5.
In Schritt fünf haben wir im Durchschnitt zwei Verschiebe-Operationen:
Und im sechsten Schritt 2,5:
In Summe haben wir also durchschnittlich 0,5 + 1 + 1,5 + 2 + 2,5 = 7,5 Verschiebe-Operationen.
Das können wir auch wie folgt ausrechnen:
Sechs Elemente mal fünf Verschiebe-Schritte; geteilt durch zwei, da im Durchschnitt über alle Schritte die Hälfte der Karten bereits sortiert ist; und nochmal geteilt durch zwei, da das einzusortierende Element im Durchschnitt bis zur Mitte der bereits sortierten Elemente geschoben werden muss:
6 × 5 × ½ × ½ = 30 × ¼ = 7,5
Die folgende Grafik zeigt noch einmal alle Schritte:
Ersetzen wir 6 durch n, erhalten wir:
n × (n – 1) × ¼
Ausmultipliziert ergibt das:
¼ n² – ¼ n
Die höchste Potenz von n in diesem Term ist n²; die Zeitkomplexität für das Verschieben beträgt daher O(n²). Dies wird auch als „quadratischer Aufwand“ bezeichnet.
Wir haben bisher nur das Verschieben der sortierten Elemente betrachtet – doch was ist mit dem Vergleichen der Elemente und dem Setzen des zu sortierenden Elements auf das freigewordene Feld?
Vergleichsoperationen haben wir jeweils eine mehr als Vertauschoperationen (bzw. gleich viel, wenn bis ganz nach links geschoben wird). Die Zeitkomplexität für die Vergleichsoperationen ist damit ebenso O(n²).
Das einzusortierenden Element müssen wir genauso oft an die richtige Position setzen wie es Elemente gibt abzgl. derjenigen, die sich schon an der richtigen Stelle befinden. Also maximal n-1 mal. Da hier kein n² vorkommt, sondern nur ein n, sprechen wir von „linearerem Aufwand“, notiert als O(n).
Die Zeitkomplexität von Insertion Sort beträgt im averagecase: O(n²)
Wo es einen average case gibt, gibt es auch einen worst und einen best case.
Zeitkomplexität im worst case
Im worst case sind die Elemente zu Beginn komplett absteigend sortiert. In jedem Schritt müssen somit alle Elemente des sortierten Teil-Arrays nach rechts verschoben werden, damit das einzusortierende Element – welches in jedem Schritt kleiner ist als alle bereits sortierten Elemente – ganz an den Anfang gesetzt werden kann.
Im folgenden Diagramm wird dies dadurch demonstriert, dass die Pfeile immer nach ganz links zeigen.
Der Term aus dem average case ändert sich daher insofern, dass das zweite Teilen durch zwei wegfällt:
6 × 5 × ½
Bzw.:
n × (n – 1) × ½
Wenn wir dies ausmultiplizieren, erhalten wir:
½n² – ½n
Auch wenn wir nur halb so viele Operationen haben wie im durchschnittlichen Fall, ändert sich an der Zeitkomplexität nichts – der Term enthält immer noch ein n², und somit gilt:
Die Zeitkomplexität von Insertion Sort beträgt im worst case: O(n²)
Zeitkomplexität im best case
Der best case wird interessant!
Wenn die Elemente bereits in sortierter Reihenfolge vorliegen, gibt es in der inneren Schleife jeweils einen Vergleich und keine Vertauschoperation.
Bei n Elementen, also n-1 Schritten (da wir beim zweiten Element beginnen) kommen wir somit auf n-1 Vergleichsoperationen.
Die Zeitkomplexität von Insertion Sort beträgt somit im best case: O(n)
Insertion Sort mit binärer Suche?
Könnten wir den Algorihmus nicht beschleunigen, indem wir die Einfügeposition mit binärer Suche suchen? Diese ist doch deutlich schneller als die sequentielle Suche – sie hat eine Zeitkomplexität von O(log n).
Ja, das könnten wir. Allerdings hätten wir dadurch nichts gewonnen, da wir zum Verschieben trotzdem jedes Element ab der Einfügeposition um eine Position nach rechts verschieben müssten, was in einem Array eben nur schrittweise geht. Somit bliebe die innere Schleife trotz der binären Suche bei linearem Aufwand, der Gesamtalgorithmus also weiterhin bei quadratischem Aufwand, also O(n²).
Insertion Sort mit verketteter Liste?
Wenn die Elemente in einer verkettete Liste vorliegen, könnten wir dann nicht ein Element in konstanter Zeit, also O(1) einfügen?
Ja, das könnten wir. Allerdings erlaubt eine verkettete Liste keine binäre Suche. D. h. wir müssten in der inneren Schleife dennoch über alle sortierten Element iterieren, um die Einfügeposition zu finden. Womit wir wiederum bei linearem Aufwand für die innere Schleife wären – und damit bei quadratischem Aufwand für den Gesamtalgorithmus.
Laufzeit des Java Insertion Sort-Beispiels
Nach so viel Theorie wird es Zeit diese anhand der oben vorgestellten Java-Implementierung zu überprüfen.
Die Klasse UltimateTest aus dem GitHub-Repository führt Insertion Sort (und allen weiteren in dieser Artikelserie vorgestellten Sortieralgorithmen) wie folgt aus:
für verschiedene Array-Größen, beginnend bei 1.024, dann jeweils verdoppelt bis 536.870.912 (der Versuch ein Array mit 1.073.741.824 Elementen zu erzeugen führt bei mir zu einem „Native memory allocation“-Fehler) – oder bis ein Test mehr als 20 Sekunden dauert;
mit unsortierten, aufsteigend sortierten und absteigend sortierten Elementen;
mit zwei Warm-Up-Runden, um dem HotSpot-Compiler zu ermöglichen den Code zu optimieren;
danach so oft wiederholt, bis das Programm abgebrochen wird.
Nach jeder Wiederholung gibt das Testprogramm den Median der bisherigen Messergebnisse aus.
Hier das Ergebnis für Insertion Sort nach 50 Iterationen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
n
unsortiert
absteigend
aufsteigend
…
…
…
…
32.768
87,86 ms
175,80 ms
0,042 ms
65.536
350,43 ms
697,59 ms
0,084 ms
131.072
1.398,92 ms
2.840,00 ms
0,168 ms
262.144
5.706,82 ms
11.517,36 ms
0,351 ms
524.288
23.009,68 ms
46.309,27 ms
0,710 ms
1.048.576
–
–
1,419 ms
…
…
…
…
536.870.912
–
–
693,310 ms
Man kann gut sehen,
wie sich die Laufzeit bei Verdopplung der Eingabemenge bei unsortierten und absteigend sortierten Elementen in etwa vervierfacht,
wie die Laufzeit im worst case doppelt so groß ist wie im average case,
wie die Laufzeit bei vorab sortierten Elementen linear wächst und deutlich kleiner ist.
Die entspricht den erwarteten Zeitkomplexitäten O(n²) und O(n).
Hier die Messwerte noch einmal als Diagramm:
Bei aufsteigend vorsortierten Elementen ist Insertion Sort so schnell, dass die Kurve keinen sichtbaren Ausschlag nach oben zeigt. Hier daher die Kurve noch mal einzeln:
Weitere Eigenschaften von Insertion Sort
Die Platzkomplexität von Insertion Sort ist konstant, da wir außer den Schleifenvariablen i und j, sowie der Hilfsvariablen elementToSort keinen zusätzlichen Speicherplatz benötigen. D. h. egal ob wir 10 Elemente sortieren oder eine Million, wir benötigen immer nur diese drei zusätzlichen Variablen. Konstanten Aufwand notiert man als O(1).
Das Sortierverfahren ist stabil, da wir nur Elemente verschieben, die größer als das einzusortierende Element sind (nicht „größer oder gleich“), sich also die relative Position zweier gleicher Elemente zueinander nie ändert.
Insertion Sort ist nicht direkt parallelisierbar.* Allerdings gibt es eine parallelisierbare Variante von Insertion Sort: Shellsort (hier die Beschreibung auf Wikipedia).
* Man könnte binär suchen und dann das Verschieben der sortierte Elemente parallelisieren. Dies würde aber nur bei großen Arrays sinnvoll sein, die man genau entlang der Cache-Lines aufteilen müsste, um die durch die Parallelisierung gewonnene Performance durch Synchronisationseffekte nicht wieder zu verlieren bzw. ins Gegenteil umzudrehen. Diesen Aufwand spart man sich, da es für größere Arrays ohnehin effizientere Sortieralgorithmen gibt.
Insertion Sort vs. Selection Sort
Einen Vergleich der Laufzeiten von Insertion Sort und Selection Sort findest du im Artikel über Selection Sort.
Zusammenfassung
Insertion Sort ist ein sehr einfach zu implementierender, stabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n²) im average und worst case, und O(n) im best case.
Für sehr kleine n ist Insertion Sort schneller als effizientere Algorithmen wie Quicksort oder Merge Sort, so dass diese Algorithmen kleinere Teilprobleme mit Insertion Sort lösen (die Dual-Pivot Quicksort-Implementierung in Arrays.sort() des JDK beispielsweise bei weniger als 44 Elementen).
Dieses Tutorial erklärt – Schritt für Schritt und mit vielen Code-Beispielen – wie man in Java primitive Datentypen (ints, longs, doubles, etc.) und Objekte beliebiger Klassen sortieren kann.
Im einzelnen beantwortet der Artikel folgende Fragen:
Wie sortiert man in Java Arrays von primitiven Datentypen?
Wie sortiert man in Java Arrays und Listen von Objekten?
Wie sortiert man in Java parallel?
Welche Sortieralgorithmen verwendet das JDK intern?
Der Artikel ist Teil des Ultimate Guides über Sortieralgorithmen, der einen Überblick über die gängigsten Sortierverfahren und deren Eigenschaften, wie z. B. deren Zeit- und Platzkomplexität, gibt.
Alle Quellcodes dieses Artikels findest du in meinem GitHub-Repository.
Was kann man in Java sortieren?
Die folgenden Datentypen lassen sich mit Java-Bordmitteln sortieren:
Arrays von primitiven Datentypen (int[], long[], double[], usw.),
Arrays und Listen von Objekten, die das Comparable-Interface implementieren,
Arrays und Listen von Objekten beliebiger Klassen, mit Angabe eines Comparators, d. h. eines zusätzlichen Objekts, das das Comparator-Interface implementiert (oder eines entsprechenden Lambdas).
Den genauen Unterschied zwischen Comparable und Comparator erkläre ich in einem separaten Artikel. Dort zeige ich auch, wie man seit Java 8 mit Comparator.comparing() sehr elegant Comparatoren erstellen und aneinanderreihen kann.
Arrays.sort() – primitive Datentypen sortieren
Die Klasse java.util.Arrays stellt Sortiermethoden für alle primitiven Datentypen (außer boolean) bereit:
static void sort(byte[] a)
static void sort(char[] a)
static void sort(double[] a)
static void sort(float[] a)
static void sort(int[] a)
static void sort(long[] a)
static void sort(short[] a)
Beispiel: Sortieren eines int-Arrays
Das folgenden Beispiel zeigt, wie ein int-Array sortiert und dann auf der Konsole ausgegeben wird:
Die ersten fünf Elemente 2, 4, 5, 8, 9 wurden sortiert, die restlichen vier Elemente 3, 1, 7, 6, sind unverändert.
Java-Objekte sortieren
Primitive Datentypen werden nach ihrer natürlichen Ordnung sortiert. Dementsprechend wird unser Beispiel-Array [4, 8, 5, 9, 2, 3, 1, 7, 6] nach dem Sortieren zu [1, 2, 3, 4, 5, 6, 7, 8, 9].
Doch in welcher Reihenfolge werden Objekte sortiert?
Integer- und String-Arrays sortieren
Wie ein Integer– oder String-Array sortiert wird, versteht jeder Java-Entwickler intuitiv:
Wir versuchen diese mit Arrays.sort() zu sortieren:
Customer[] customers = {
new Customer(43423, "Elizabeth", "Mann"),
new Customer(10503, "Phil", "Gruber"),
new Customer(61157, "Patrick", "Sonnenberg"),
new Customer(28378, "Marina", "Metz"),
new Customer(57299, "Caroline", "Albers")
};
Arrays.sort(customers);
System.out.println(Arrays.toString(customers));Code-Sprache:Java(java)
Diesen Versuch quittiert Java mit folgender Fehlermeldung:
Exception in thread „main“ java.lang.ClassCastException: class eu.happycoders.sorting.Customer cannot be cast to class java.lang.Comparable
Java weiß ohne zusätzliche Informationen nicht, wie Customer-Objekte sortiert werden sollen. Wie stellen wir diese Informationen bereit? Das erfährst du im nächsten Kapitel.
Sortieren mit Comparable und Comparator
Die Sortier-Instruktionen können wir auf zwei unterschiedliche Arten bereitstellen:
indem wir die Klasse Customer das Interface java.lang.Comparable implementieren lassen (so wie von der Fehlermeldung gefordert) oder
indem wir der Arrays.sort()-Methode eine Implementierung des Interfaces java.util.Comparator mitgeben.
Das Interface java.lang.Comparable definiert eine einzige Methode:
public int compareTo(T o)
Diese wird vom Sortieralgorithmus aufgerufen, um zu prüfen, ob ein Objekt kleiner, gleich oder größer als ein anderes Objekt ist. Je nachdem muss die Methode eine negative Zahl, 0 oder eine positive Zahl zurückliefern.
(Wenn du dir die Quellcodes von Integer und String anschaust, wirst du feststellen, dass beide das Comparable-Interface und die compareTo()-Methode implementieren.)
Wir wollen unsere Kunden nach Kundennummer sortieren. Dazu müssen wir die Customer-Klasse wie folgt erweitern (den Konstruktor und die toString()-Methode lasse ich hier der Übersicht halber weg):
Unsere so erweiterte Customer-Klasse können wir nun problemlos sortieren lassen (hier noch mal, damit du nicht scrollen musst, das Customer-Sortier-Beispiel von oben):
Customer[] customers = {
new Customer(43423, "Elizabeth", "Mann"),
new Customer(10503, "Phil", "Gruber"),
new Customer(61157, "Patrick", "Sonnenberg"),
new Customer(28378, "Marina", "Metz"),
new Customer(57299, "Caroline", "Albers")
};
Arrays.sort(customers);
System.out.println(Arrays.toString(customers));Code-Sprache:Java(java)
Dieses mal läuft das Programm ohne Fehler durch und gibt folgendes aus (die Zeilenumbrüche habe ich der Übersicht halber manuell eingefügt):
Unsere Kunden sind nun, wie gewünscht, nach Kundernnummer sortiert.
Was aber, wenn wir die Kunden für einen anderen Use Case nicht nach Nummern, sondern nach Namen sortieren wollen? Wir können ja compareTo() nur einmal implementieren. Müssen wir uns für immer und ewig auf eine Reihenfolge festlegen?
Hier kommt das Interface Comparator ins Spiel, das ich im nächsten Abschnitt beschreiben werde.
Sortieren mit einem Comparator
Mit der Customer.compareTo()-Methode haben wir die sogenannte „natürliche Ordnung“ der Kunden definiert. Mit dem Interface Comparator können wir beliebig viele weitere Sortierreihenfolgen für eine Klasse definieren.
Analog zur compareTo()-Methode definiert das Comparator-Interface die folgende Methode:
int compare(T o1, T o2)
Diese wird aufgerufen, um zu prüfen, ob das Objekt o1kleiner, gleich oder größer als das Objekt o2 ist. Entsprechend muss auch diese Methode eine negative Zahl, 0 oder eine positive Zahl als Rückgabewert liefern.
Seit Java 8 können wir einen Comparator sehr elegant mit Comparator.comparing() erstellen. Mit folgendem Code können wir die Kunden zunächst nach Nachnamen und dann nach Vornamen sortieren:
Weitere Möglichkeiten, um Comparatoren zu erstellen, findest Du in diesem Artikel. Probier es einfach mal aus!
Sortieren einer Liste in Java
Bis jetzt haben wir ausschließlich die folgenden zwei Methoden der Klasse java.util.Arrays verwendet, um Objekte zu sortieren:
static void sort(Object[] a) – zum Sortieren von Objekten entsprechend ihrer natürlichen Ordnung,
static void sort(T[] a, Comparator<? super T> c) – zum Sortieren von Objekten anhand des übergebenenen Comparators.
Oft haben wir Objekte nicht in einem Array vorliegen, sondern in einer Liste. Um diese zu sortieren, gibt es (seit Java 8) zwei Möglichkeiten:
Liste sortieren mit Collections.sort()
Bis einschließlich Java 7 musste die Methode Collections.sort() zu Hilfe genommen werden, um eine Liste zu sortieren.
Im folgenden Beispiel sollen wieder unsere Kunden sortiert werden, zunächst nach Kundennummer (also entsprechend ihrer „natürlichen Ordnung“):
ArrayList<Customer> customers = new ArrayList<>(List.of(
new Customer(43423, "Elizabeth", "Mann"),
new Customer(10503, "Phil", "Gruber"),
new Customer(61157, "Patrick", "Sonnenberg"),
new Customer(28378, "Marina", "Metz"),
new Customer(57299, "Caroline", "Albers")
));
Collections.sort(customers);
System.out.println(customers);Code-Sprache:Java(java)
Das Programm gibt, wie im vorherigen Beispiel auch, die Kunden sortiert nach ihrer Kundennummer aus.
Warum werden im Beispiel zwei Listen erstellt? Eine mit List.of() und dann eine weitere mit new ArrayList<>()?
List.of() ist die eleganteste Art eine Liste zu erstellen. Die ist allerdings unveränderlich (was in den meisten Anwendungsfällen von List.of() auch sinnvoll ist) und kann dementsprechend nicht sortiert werden. Daher übergebe ich diese dann an den Konstruktor von ArrayList, der daraus eine veränderliche Liste macht. Zugegeben: nicht die performanteste Lösung, sie macht den Code aber schön kurz.
Collections.sort() prüft übrigens (im Gegensatz zu Arrays.sort()) schon zur Compile-Zeit, ob die übergebene Liste aus Objekten besteht, die Comparable implementieren.
Liste sortieren mit Collections.sort() und einem Comparator
Auch einen Comparator kann man Collections.sort() mitgeben. Folgende Code-Zeile sortiert die Kunden nach Namen:
Seit Java 8 gibt es (dank der Default-Methoden in Interfaces) die Möglichkeit eine Liste direkt mit List.sort() zu sortieren. Dabei muss immer ein Comparator angegeben werden:
Der Comparator darf allerdings auch null sein, um die Liste entsprechend ihrer natürlichen Ordnung zu sortieren:
customers.sort(null);Code-Sprache:Java(java)
Auch hier bekommen wir eine ClassCastException, wenn die übergebene Liste Objekte enthält, die nicht Comparable implementieren.
Arrays parallel sortieren
Seit Java 8 steht jede der Sortiermethoden aus der java.util.Arrays-Klasse auch in einer parallelen Variante zur Verfügung. Diese verteilt den Sortieraufwand ab einer festgelegten Array-Größe (8.192 Elemente von Java 8 bis Java 13; 4.097 Elemente seit Java 14) auf mehrere CPU Cores. Ein Beispiel:
static void parallelSort(double[] a)
Das folgende Beispiel misst die benötigte Zeit für das Sortieren von 100 Millionen double-Werten einmal mit Arrays.sort() und einmal mit Arrays.parallelSort():
publicclassDoubleArrayParallelSortDemo{
privatestaticfinalint NUMBER_OF_ELEMENTS = 100_000_000;
publicstaticvoidmain(String[] args){
for (int i = 0; i < 5; i++) {
sortTest("sort", Arrays::sort);
sortTest("parallelSort", Arrays::parallelSort);
}
}
privatestaticvoidsortTest(String methodName, Consumer<double[]> sortMethod){
double[] a = createRandomArray(NUMBER_OF_ELEMENTS);
long time = System.currentTimeMillis();
sortMethod.accept(a);
time = System.currentTimeMillis() - time;
System.out.println(methodName + "() took " + time + " ms");
}
privatestaticdouble[] createRandomArray(int n) {
ThreadLocalRandom current = ThreadLocalRandom.current();
double[] a = newdouble[n];
for (int i = 0; i < n; i++) {
a[i] = current.nextDouble();
}
return a;
}
}Code-Sprache:Java(java)
Mein System (DELL XPS 15 mit Core i7-8750H) gibt folgende Messwerte aus:
sort() took 9596 ms
parallelSort() took 2186 ms
sort() took 9232 ms
parallelSort() took 1835 ms
sort() took 8994 ms
parallelSort() took 1917 ms
sort() took 9152 ms
parallelSort() took 1746 ms
sort() took 8899 ms
parallelSort() took 1757 msCode-Sprache:Klartext(plaintext)
Die jeweils ersten Aufrufe dauern etwas länger, da der HotSpot-Compiler etwas Zeit braucht, um den Code zu optimieren.
Danach ist gut zu sehen, wie das parallele Sortieren etwa fünf mal schneller ist als das sequentielle. Für sechs Cores ist das ein sehr gutes Ergebnis, da die Parallelisierung natürlich auch einen gewissen Overhead mit sich bringt.
Sortieralgorithmen im Java Development Kit (JDK)
Im JDK werden je nach Aufgabenstellung verschiedene Sortieralgorithmen angewendet:
Counting Sort für byte[], short[] und char[], wenn mehr als 64 Bytes bzw. mehr als 1750 Shorts oder Characters sortiert werden.
Dual-Pivot Quicksort für das Sortieren primitiver Datentypen mit Arrays.sort(). Hierbei handelt es sich um eine optimierte Variante von Quicksort, kombiniert mit Insertion Sort und Counting Sort. Der Algorithmus erreicht eine Zeitkomplexität von O(n log n) bei vielen Eingabedaten, für die andere Quicksort-Implementierungen in der Regel auf O(n²) zurückfallen.
Timsort (ein optimiertes Natural Mergesort kombiniert mit Insertion Sort) für alle anderen Objekte.
Beim parallelen Sortieren werden folgende Algorithmen angewendet:
Bytes, Shorts, Characters werden niemals parallel sortiert.
Für andere primitive Datentypen wird eine Kombination aus Quicksort, Mergesort, Insertion Sort und Heapsort eingesetzt.
Für Objekte wird ebenfalls Timsort eingesetzt – die parallele Variante allerdings erst bei einer Listengröße von mehr als 8.192 Elementen; darunter wird die Single-Threaded Variante verwendet, da ansonsten der Overhead größer ist als der Gewinn.
Zusamenfassung
Du hast in diesem Artikel gelernt (oder aufgefrischt), wie du in Java primitive Datentypen und Objekte sortieren kannst und welche Sortierverfahren das JDK intern anwendet.
Sortieralgorithmen sind Thema jeder Informatiker-Ausbildung. Viele von uns haben irgendwann einmal die genaue Funktionsweise von Insertion Sort bis Merge- und Quicksort auswendig lernen müssen, einschließlich deren Zeitkomplexitäten im best, average und worst case in Big-O-Notation … um nach der Prüfung das meiste davon wieder zu vergessen ;-)
Wenn du eine Auffrischung brauchst, wie die gebräuchlichsten Sortieralgorithmen funktionieren und wie sie sich unterscheiden, ist diese Artikelserie genau das Richtige für dich.
Dieser erste Artikel behandelt folgende Fragen:
Welches sind die gebräuchlichsten Sortierverfahren?
In welchen Eigenschaften unterscheiden sie sich?
Wie ist das Laufzeitverhalten der einzelnen Sortiermethoden (Platz- und Zeitkomplexität)?
Möchtest du wissen, wie ein bestimmter Sortieralgorithmus genau funktioniert? Jedes aufgelistete Sortierverfahren linkt zu einem vertiefenden Artikel, welcher…
die Funktionsweise des jeweiligen Verfahrens anhand eines Beispiels erklärt,
die Zeitkomplexität herleitet (auf anschauliche Weise, ohne komplizierte mathematische Beweise),
zeigt, wie man den jeweiligen Sortieralgorithmus in Java implementiert, und
die Performance der Java-Implementierung misst und mit dem theoretischen Laufzeitverhalten abgleicht.
Die Quellcodes der gesamten Artikelserie findest du in meinem GitHub-Repository.
Eigenschaften von Sortieralgorithmen
Sortierverfahren unterscheiden sich hauptsächlich in den folgenden Eigenschaften (Erklärungen findest du in den folgenden Abschnitten):
Geschwindigkeit (oder besser: Zeitkomplexität)
Platzkomplexität
Stabilität
Vergleichsbasiert / nicht-vergleichsbasiert
Parallelisierbarkeit
Rekursiv / nicht rekursiv
Adaptionsfähigkeit
Du kannst die Erklärungen auch erstmal überspringen und später hierher zurückkehren. Hier geht es direkt zu den wichtigsten Sortieralgorithmen.
Zeitkomplexität von Sortieralgorithmen
Das wichtigste Kriterium bei der Auswahl eines Sortierverfahrens ist in den meisten Fällen dessen Geschwindigkeit. Interessant ist hierbei in erster Linie, wie sich die Geschwindigkeit in Abhängigkeit von der Anzahl der zu sortierenden Elemente ändert.
Denn ein Algorithmus kann bei hundert Elementen doppelt so schnell sein wie ein anderer, bei tausend Elementen aber durchaus fünf mal langsamer (oder noch viel viel langsamer; aber das ließ sich nicht mehr gut in dem Diagramm abbilden):
Deshalb gibt man die Laufzeit eines Algorithmus im allgemeinen als Zeitkomplexität in der sogenannten „O-Notation“ (englisch: „Big O notation“) an.
Die folgenden Klassen von Zeitkomplexitäten sind für Sortieralgorithmen relevant (detailliertere Beschreibungen dieser Komplexitätsklassen findest Du in dem jeweils verlinkten Artikel):
Hier noch einmal das Diagramm von oben mit der Angabe der Zeitkomplexitäten und einer zusätzlichen Kurve für quasilinearen Aufwand. Da die Zeitkomplexität keine Aussage über die absolut benötigten Zeiten macht, sind die Achsen hier nicht mehr mit Werten beschriftet.
Bei quadratischer Komplexität stößt man relativ schnell an die Leistungsgrenzen heutiger Hardware:
Während Quicksort auf meinem Laptop eine Milliarde Elemente in 90 Sekunden sortiert, breche ich den Versuch mit Insertion Sort nach einer Viertelstunde ab. Ausgehend von etwa 100 Sekunden für eine Million Elemente, würde Insertion Sort für eine Milliarde Elemente beeindruckende drei Jahre und zwei Monate brauchen.
Quadratische Komplexität sollte also, wenn möglich, vermieden werden.
Platzkomplexität von Sortieralgorithmen
Nicht nur Zeitkomplexität ist für Sortierverfahren relevant, sondern auch die Platzkomplexität. Diese gibt an, wie viel zusätzlichen Speicherplatz der Algorithmus in Abhängigkeit von der Anzahl der zu sortierenden Elemente benötigt. Damit ist nicht der Speicherplatz gemeint, der für die zu sortierenden Elemente selbst benötigt wird, sondern darüberhinaus benötigter Platz für z. B. Hilfsvariablen, Schleifenzähler und temporäre Arrays.
Platzkomplexität wird mit den gleichen Klassen angegeben wie Zeitkomplexität. Hier treffen wir noch auf eine weitere Klasse:
Bei stabilen Sortierverfahren wird die relative Reihenfolge von Elementen, die den gleichen Sortierschlüssel haben, beibehalten. Bei nicht-stabilen Sortierverfahren wird dies nicht garantiert: Die relative Reihenfolge kann beibehalten werden, muss es aber nicht.
Was bedeutet das?
In folgendem Beispiel haben wir eine zufällig erzeugte Namensliste. Die Liste ist zunächst nach Vornamen sortiert:
Annika Weigert
Fabio Müller
Gertrud Selig
Jonathan Heydrich
Mathias Müller
Waltraud Birke
Diese Liste soll nun – ohne die Vornamen zu betrachten – nach Nachnamen sortiert werden. Wenn wir dafür ein stabiles Sortierverfahren anwenden, ist das Ergebnis immer:
Waltraud Birke
Jonathan Heydrich
Fabio Müller
Mathias Müller
Annika Weigert
Gertrud Selig
D. h. die Reihenfolge von Fabio und Mathias bleibt bei einem stabilen Sortierverfahren immer unverändert. Bei einem unstabilen Sortierverfahren kann auch folgendes Sortierergebnis herauskommen:
Waltraud Birke
Jonathan Heydrich
Mathias Müller
FabioMüller
Annika Weigert
Gertrud Selig
Mathias und Fabio sind hierbei gegenüber der Ausgangsreihenfolge vertauscht.
Vergleichsbasierte und nicht-vergleichsbasierte Sortierverfahren
Die meisten der bekannten Sortierverfahren basieren auf dem Vergleich zweier Elemente auf kleiner, größer oder gleich. Es existieren jedoch auch nicht-vergleichsbasierte Sortieralgorithmen.
Diese Eigenschaft beschreibt, ob und in wie weit sich ein Sortieralgorithmus für die parallele Abarbeitung auf mehreren CPU Cores eignet.
Rekursive / nicht-rekusive Sortiermethoden
Ein rekursiver Sortieralgorithmus benötigt zusätzlichen Speicherplatz auf dem Stack. Bei zu tiefer Rekursion droht die gefürchtete StackOverflowExecption.
Adaptionsfähigkeit (adaptability)
Ein adaptiver Sortieralgorithmus kann sein Verhalten während der Laufzeit an bestimmte Eingabedaten (z. B. vorsortierte Elemente) anpassen und diese deutlich schneller sortieren als zufällig verteilte Elemente.
Vergleich der wichtigsten Sortieralgorithmen
Die folgende Tabelle gibt einen Überblick über alle in dieser Artikelserie vorgestellten Sortieralgorithmen. Es handelt sich um eine Auswahl der am meisten verbreitetsten Sortierverfahren. Dies sind auch die, die man in der Regel in der Informatik-Ausbildung lernt.
Jeder Eintrag ist verlinkt zu einem vertiefenden Artikel, der den jeweiligen Algorithmus und dessen Eigenschaften im Detail beschreibt und auch dessen Quellcode enthält.
Wenn dir zunächst ein Überblick genügt, findest du im Anschluss an die Tabelle die Sortieralgorithmen in jeweils einem Satz erklärt.
Die Variable k steht bei Counting Sort steht für keys (die Anzahl der möglichen Schlüsselwerte) und bei Radix Sort für key length (die maximale Länge eines Schlüssels). Die Variable b bei Radix Sort steht für Basis.
Einfache Sortierverfahren
Einfache Sortierverfahren sind gut geeignet, um kleine Listen zu sortieren. Für große Listen sind sie aufgrund des quadratischen Aufwands ungeeignet. Insbesondere Insertion Sort (was aufgrund von weniger Vergleichen ungefähr doppelt so schnell ist wie Selection Sort) wird gerne verwendet, um effiziente Sortieralgorithmen wie Quicksort und Mergesort weiter zu optimieren. Dazu lässt man diese Verfahren kleine Teillisten im Größenbereich bis ca. 50 Elemente mit Insertion Sort sortieren.
Insertion Sort
Insertion Sort verwendet man zum Beispiel beim Sortieren von Spielkarten: man nimmt eine Karte nach der anderen auf und fügt sie an der richtigen Stelle in die bereits sortieren Karten ein (auf deutsch: Einfüge-Sortieren).
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n)
O(n²)
O(n²)
O(1)
Ja
Selection Sort
Selection Sort kannst du dir anhand des Spielkartenbeispiels so vorstellen, dass alle einzusortierenden Karten offen vor dir liegen. Du suchst die kleinste Karte und nimmst sie auf, dann suchst du die nächstgrößere Karte und nimmst sie rechts neben die zuerst aufgenommene Karte, usw. bis du als letztes die größte Karte aufnimmst und nach ganz rechts auf die Hand nimmst.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n²)
O(n²)
O(n²)
O(1)
Nein
Bubble Sort
Bei Bubble Sort werden von links nach rechts jeweils nebeneinanderliegende Elemente verglichen und – falls diese in der falschen Reihenfolge vorliegen – miteinander vertauscht. Dieser Vorgang wird so oft wiederholt bis alle Elemente sortiert sind.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n)
O(n²)
O(n²)
O(1)
Ja
Effiziente Sortierverfahren
Effiziente Sortieralgorithmen erreichen eine deutlich bessere Zeitkomplexität von O(n log n). Sie eignen sich daher auch für große Datensätze mit Milliarden von Elementen.
Quicksort
Quicksort funktioniert nach dem „Teile und Herrsche“-Prinzip. Durch eine sogenannte Partitionierung wird der Datensatz zunächst grob in kleine und große Elemente aufgeteilt: kleine kommen nach links, große nach rechts. Jede dieser Partitionen wird danach rekursiv wieder partitioniert, solange bis eine Partition nur noch ein Element enthält und damit als sortiert gilt.
Sobald für alle Partionen und Teil-Partitionen die tiefste Rekursionsstufe erreicht ist, ist die gesamte Liste sortiert.
Quicksort hat zwei Nachteile:
Im worst case (bei absteigend sortierten Elementen) ist die Zeitkomplexität O(n²).
Quicksort ist nicht stabil.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n log n)
O(n log n)
O(n²)
O(log n)
Nein
Mergesort
Mergesort funktioniert ebenfalls nach dem „Teile und Herrsche“-Prinzip. Wobei hier sozusagen in umgekehrter Reihenfolge vorgegangen wird wie bei Quicksort: Anstatt zuerst zu sortieren und dann in die Rekursion abzusteigen, geht Mergesort zuerst in die Rekursion, bis Teillisten mit nur noch einem Element erreicht sind und fügt dann jeweils zwei Teillisten so zusammen („merged“ sie), dass eine sortierte Teilliste entsteht.
Beim letzten Schritt aus der Rekursion heraus werden zwei verbleibende Teillisten gemerged und ergeben das sortierte Gesamtergebnis.
Mergesort hat gegenüber Quicksort den Vorteil, dass auch im worst case die Zeitkomplexität O(n log n) nicht überschreitet und dass es stabil ist. Allerdings erkauft man sich diese Vorteile durch einen zusätzlichen Platzbedarf in der Größenordnung O(n).
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n log n)
O(n log n)
O(n log n)
O(n)
Ja
Heapsort
Der Begriff Heapsort ist für Java-Entwickler oft verwirrend, da man ihn zunächst mit dem Java Heap in Verbindung bringt. Die Heaps von Heapsort und Java sind allerdings zwei völlig unterschiedliche Dinge.
Dieses Wurzelelement wird entnommen, dann wird das letzte Element auf die Wurzelposition gesetzt und danach der Baum per „Heapify“-Operation repariert, woraufhin wiederum das größte der verbleibenden Element auf der Wurzelposition liegt. Der Prozess wird solange wiederholt, bis der Baum leer ist. Die dem Baum entnommenen Elemente ergeben das sortierte Ergebnis.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n log n)
O(n log n)
O(n log n)
O(1)
Nein
Nicht vergleichsbasierte Sortierverfahren
Nicht vergleichsbasierte Sortierverfahren basieren nicht auf dem Vergleich zweier Element auf kleiner, größer oder gleich.
Wie können sie dann funktionieren?
Am besten lässt sich das an einem Beispiel erklären – im folgenden anhand von Counting Sort.
Counting Sort
Bei Counting Sort werden Elemente – wie der Name schon sagt – gezählt. Um beispielsweise ein Array mit Zahlen aus dem Bereich 1 bis 10 zu sortieren, zählen wir (in einem einzigen Durchgang), wie oft die 1 vorkommt, wie oft die 2, usw. bis zur 10.
Im zweiten Durchgang schreiben wir dann die 1 so oft von links beginnend in das Array, wie sie vorkommt, dann die 2 so oft, wie diese vorkommt, usw. wiederum bis zur 10.
Dieses Verfahren wird in der Regel nur für kleine Zahlentypen wie byte, char oder short eingesetzt, oder wenn der Bereich der zu sortierenden Zahlen bekannt ist (z. B. ints zwischen 0 und 150). Der Grund dafür ist, dass wir für das Zählen der Elemente ein zusätzliches Array entsprechend der Größe des Zahlenbereichs benötigen.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(n + k)
O(n + k)
O(n + k)
O(k)
Ja
Die Variable k steht für die Anzahl der möglichen Werte (keys).
Radix Sort
Bei Radix Sort werden die Elemente Ziffer für Ziffer sortiert. Dreistellige Zahlen z. B. zuerst nach den Einerstellen, dann nach den Zehnerstellen und zuletzt nach den Hunderterstellen.
Dieses Verfahren eignet sich im Gegensatz zu Counting Sort auch für große Zahlenräume wie int und long, ist stabil und kann sogar schneller sein als Quicksort, hat jedoch mit O(n) eine höhere Platzkomplexität und wird daher seltener eingesetzt.
Zeit best case
Zeit avg. case
Zeit worst case
Platz
Stabil
O(k · (b + n))
O(k · (b + n))
O(k · (b + n))
O(n)
Ja
Sonstige Sortieralgorithmen
Es gibt zahlreiche weitere Sortieralgorithmen (Shell Sort, Comb Sort, Bucket Sort, um nur ein paar zu nennen). Die in diesem Artikel vorgestellten Methoden zu kennen stellt meiner Meinung nach jedoch ein sehr gutes Grundlagenwissen dar.
Falls du dir die Javadocs von List.sort() und Arrays.sort() durchgelesen hast, fragst du dich vielleicht, warum ich hier Timsort und Dual-Pivot Quicksort nicht aufführe.
Timsort ist kein komlett eigenständiges Sortierverfahren. Vielmehr ist es eine Kombination aus Mergesort, Insertion Sort und etwas zusätzlicher Logik. Ich werde Timsort im Artikel über Mergesort beschreiben.
Ebenso ist Dual-Pivot Quicksort eine Variante des regulären Quicksort und wird im entsprechenden Artikel beschrieben werden.
Zusamenfassung
Dieser Artikel hat einen Überblick über die gängigsten Sortieralgorithmen gegeben und die Eigenschaften beschrieben, in denen sich diese hauptsächlich unterscheiden.
In den folgenden Teilen dieser Serie beschreibe ich je einen Sortieralgorithmus im Detail – anhand von Beispielen und mit Quellcodes.
Die O-Notation (ausgesprochen: „Groß O Notation“)¹ wird eingesetzt, um die Komplexität von Algorithmen zu beschreiben.
Auf Google und YouTube findet man zahlreiche Artikel und Videos, die die O-Notation erklären. Doch für das Verständnis der meisten davon (wie z. B. dieses Wikipedia-Artikels), sollte man als Vorbereitung ein Mathematik-Studium absolviert haben. ;-)
In diesem Artikel werde ich daher die O-Notation und die damit beschriebene Zeit- und Platzkomplexität ausschließlich anhand von Beispielen und Diagrammen erklären – und ganz ohne mathematische Formeln, Beweisführungen und Symbole wie θ, Ω, ω, ∈, ∀, ∃ und ε.
Alle Quellcodes aus diesem Artikel findest du in diesem GitHub-Repository.
¹ alternative Bezeichnungen: „Landau-Notation“ oder „Asymptotische Notation“; englisch: „Big O notation“.
Arten von Komplexität
Zeitkomplexität
Zeitkomplexität (englisch: „computational time complexity“) beschreibt die Änderung der Ausführungszeit eines Algorithmus in Abhängigkeit von der Änderung der Größe der Eingabedaten.
Oder anders gesagt: „Um wie viel verlangsamt sich ein Algorithmus, wenn die Menge der Eingabedaten größer wird?“
Beispiele:
Wie viel länger dauert es ein Element innerhalb eines unsortierten Arrays zu suchen, wenn sich die Größe des Arrays verdoppelt? (Antwort: doppelt so lange)
Wie viel länger dauert es ein Element innerhalb eines sortierten Arrays zu suchen, wenn sich die Größe des Arrays verdoppelt? (Antwort: einen Schritt mehr)
Platzkomplexität
Platzkomplexität (englisch: „space complexity“) beschreibt, wie viel zusätzlichen Speicherplatz ein Algorithmus in Abhängigkeit von der Größe der Eingabedaten benötigt.
Damit ist nicht der Speicherbedarf für die Eingabedaten selbst gemeint (d. h. dass man für ein doppelt so großes Eingabe-Array selbstverständlich doppelt so viel Platz benötigt), sondern derjenige Speicher, den der Algorithmus für Schleifen- und Hilfsvariablen, temporäre Datenstrukturen und Call Stack (z. B. durch Rekursion) zusätzlich benötigt.
Komplexitätsklassen
Algorithmen werden in sogenannte Komplexitätsklassen eingeteilt. Eine Komplexitätsklasse wird mit dem Landau-Symbol O („Groß O“) gekennzeichnet.
Im folgenden stelle ich die wichtigsten Komplexitätsklassen vor, wobei ich mit den leicht verständlichen Klassen beginne und dann zu den etwas komplizierteren komme. Dementsprechend sind die Klassen nicht nach Aufwand sortiert.
O(1) – konstanter Aufwand
Ausgesprochen: „O von 1“
Die Ausführungszeit ist konstant, also unabhängig von der Anzahl der Eingabeelemente n.
Im folgenden Graph stellt die horizontale Achse die Anzahl der Eingabeelemente n (oder allgemeiner: die Größe des Eingabeproblems) dar und die vertikale Achse die benötigte Zeit.
Da Komplexitätsklassen nur verwendet werden können, um Algorithmen einzuordnen, nicht aber, um deren genaue Laufzeit zu berechnen, sind die Achsen nicht beschriftet.
Komplexitätsklasse O(1) – konstanter Aufwand
O(1) Beispiele
Die folgenden zwei Problemstellungen sind Beispiele für konstanten Aufwand:
Zugriff auf ein bestimmtes Element eines Arrays der Größe n: Egal wie groß ein Array ist, der Zugriff über array[index] benötigt immer die gleiche Zeit².
Einfügen eines Elements am Anfang einer verketteten Liste: Dies erfordert immer das Setzen von einem bzw. zwei (bei einer doppelt verketteten Liste) Zeigern (oder Referenzen), unabhängig davon, wie groß die verkettete Liste ist. (Bei einem Array hingegen müssten dazu alle Werte um ein Feld nach rechts verschoben werden, was bei einem größeren Array länger dauert als bei einem kleineren.)
² Hundertprozentig korrekt ist diese Aussage nicht, denn hier kommen auch noch Effekte durch die CPU-Caches ins Spiel: Wenn der Datenblock, der das auszulesende Element enthält, bereits (oder noch) im CPU-Cache liegt (wofür die Wahrscheinlichkeit größer ist, je kleiner das Array ist), dann ist der Zugriff schneller, als wenn dieser erst aus dem RAM gelesen werden muss.
O(1) Beispiel-Quellcode
Der folgende Quellcode (Klasse ConstantTimeSimpleDemo im GitHub-Repository) zeigt ein einfaches Beispiel zur Messung des Aufwandes für das Einfügen eines Elements am Anfang einer verketteten Liste:
publicstaticvoidmain(String[] args){
for (int n = 32; n <= 8_388_608; n *= 2) {
LinkedList<Integer> list = createLinkedListOfSize(n);
long time = System.nanoTime();
list.add(0, 1);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
privatestatic LinkedList<Integer> createLinkedListOfSize(int n){
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < n; i++) {
list.add(i);
}
return list;
}Code-Sprache:Java(java)
Bei mir liegen die benötigten Zeiten – ungleichmäßig über die verschiedenen Messungen verteilt – zwischen 1.200 ns und 19.000 ns. Für einen schnellen Test reicht das aus. Allerdings bekommen wir hier keine besonders guten Messergebnisse, da sowohl HotSpot-Compiler als auch Garbage Collector jederzeit anspringen können.
Bessere Messergebnisse liefert das Testprogramm TimeComplexityDemo mit der Klasse ConstantTime. Hier werden zunächst mehrere Warmup-Runden ausgeführt, um dem HotSpot-Compiler die Gelegenheit zu geben den Code zu optimieren. Erst danach werden wiederholt Messungen vorgenommen und der Median der Messwerte ausgegeben.
Hier ein Auszug der Ergebnisse:
--- ConstantTime (results 5 of 5) ---
ConstantTime, n = 32 -> fastest: 31,700 ns, median: 44,900 ns
ConstantTime, n = 16,384 -> fastest: 14,400 ns, median: 40,200 ns
ConstantTime, n = 8,388,608 -> fastest: 34,000 ns, median: 51,100 nsCode-Sprache:Klartext(plaintext)
Der Aufwand bleibt also in etwa gleich, unabhängig von der Größe der Liste. Die vollständigen Testergebnisse findest du in der Datei test-results.txt.
O(n) – linearer Aufwand
Ausgesprochen: „O von n“
Der Aufwand wächst linear mit der Anzahl der Eingabeelemente n: Verdoppelt sich n, dann verdoppelt sich auch ungefähr der Aufwand.
„Ungefähr“ deshalb, weil der Aufwand auch Komponenten mit niedrigeren Komplexitätsklassen enthalten kann. Diese fallen bei hinreichend großem n nicht ins Gewicht, so dass sie bei der Notation vernachlässigt werden.
In folgendem Diagramm habe ich das dadurch demonstriert, dass der Graph etwas oberhalb des Nullpunkts beginnt (der Aufwand enthält also auch eine konstante Komponente):
O(n) Beispiele
Die folgenden Problemstellungen sind Beispiele für linearen Aufwand:
Finden eines bestimmten Elements in einem Array: Es müssen dazu alle Elemente des Arrays betrachtet werden – bei doppelt so vielen Elementen dauert es doppelt so lang.
Summieren aller Elemente eines Arrays: Auch dafür müssen alle Elemente einmal betrachtet werden – ist das Array doppelt so groß, dauert es doppelt so lang.
Es ist wichtig zu verstehen, dass die Komplexitätsklasse keine Aussage über die absolut benötigte Zeit macht, sondern lediglich über die Änderung der benötigten Zeit in Abhängigkeit von der Änderung der Eingabegröße. Beispielsweise würde die beiden o. g. Beispiele mit einer verketteten Liste deutlich länger benötigen als mit einem Array – an der Komplexitätsklasse ändert das jedoch nichts.
O(n) Beispiel-Quellcode
Der folgende Quellcode (Klasse LinearTimeSimpleDemo) misst den Aufwand für das Summieren aller Elemente eines Arrays:
publicstaticvoidmain(String[] args){
for (int n = 32; n <= 536_870_912; n *= 2) {
int[] array = createArrayOfSize(n);
long sum = 0;
long time = System.nanoTime();
for (int i = 0; i < n; i++) {
sum += array[i];
}
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
privatestaticint[] createArrayOfSize(int n) {
int[] array = newint[n];
for (int i = 0; i < n; i++) {
array[i] = i;
}
return array;
}Code-Sprache:Java(java)
Auf meinem System steigt die benötigte Zeit von 1.100 ns auf 155.911.900 ns ungefähr linear an. Bessere Messergebnisse liefert auch hier das Testprogramm TimeComplexityDemo mit der Algorithmus-Klasse LinearTime – hier ein Auszug der Ergebnisse:
--- LinearTime (results 5 of 5) ---
LinearTime, n = 512 -> fastest: 300 ns, median: 300 ns
LinearTime, n = 524,288 -> fastest: 159,300 ns, median: 189,400 ns
LinearTime, n = 536,870,912 -> fastest: 164,322,600 ns, median: 168,681,700 nsCode-Sprache:Klartext(plaintext)
Die vollständigen Testergebnisse findest du auch hier wieder in test-results.txt.
Was ist der Unterschied zwischen „linear“ und „proportional“?
Eine Funktion ist linear, wenn sie durch eine gerade Linie dargestellt weden kann, z. B. f(x) = 5x + 3.
Proportional ist ein Sonderfall von linear, bei dem die Linie durch den Punkt (0,0) des Koordinatensystems geht, z. B. f(x) = 3x.
Da es in der Klasse O(n) einen konstanten Anteil geben kann, handelt es sich um linearen Aufwand.
O(n²) – quadratischer Aufwand
Ausgesprochen: „O von n Quadrat“
Der Aufwand wächst quadratisch mit der Anzahl der Eingabeelemente: Verdoppelt sich die Anzahl der Eingabeelemente n, dann vervierfacht sich in etwa der Aufwand. (Und verzehnfacht sich die Anzahl der Elemente, wächst die benötigte Zeit um den Faktor Hundert!)
Das folgende Beispiel (QuadraticTimeSimpleDemo) zeigt, wie sich der Aufwand für das Sortieren eines Arrays mittels Insertion Sort in Abhängigkeit von der Größe des Arrays ändert:
publicstaticvoidmain(String[] args){
for (int n = 32; n <= 262_144; n *= 2) {
int[] array = createRandomArrayOfSize(n);
long time = System.nanoTime();
insertionSort(array);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
privatestaticint[] createRandomArrayOfSize(int n) {
ThreadLocalRandom random = ThreadLocalRandom.current();
int[] array = newint[n];
for (int i = 0; i < n; i++) {
array[i] = random.nextInt();
}
return array;
}
privatestaticvoidinsertionSort(int[] elements){
for (int i = 1; i < elements.length; i++) {
int elementToSort = elements[i];
int j = i;
while (j > 0 && elementToSort < elements[j - 1]) {
elements[j] = elements[j - 1];
j--;
}
elements[j] = elementToSort;
}
}Code-Sprache:Java(java)
Bessere Messergebnisse bekommt man wiederum mit dem Testprogramm TimeComplexityDemo und der Klasse QuadraticTime. Hier der Auszug der Ergebnisse, bei dem man schön die jeweilige ungefähre Vervierfachung der Zeit bei Verdoppelung der Problemgröße erkennen kann:
Die vollständigen Testergebnisse findest du in test-results.txt.
O(n) vs. O(n²)
An dieser Stelle möchte ich noch einmal darauf hinweisen, dass der Aufwand Komponenten niedrigerer Komplexitätsklassen und konstante Faktoren enthalten kann. Beides ist für die O-Notation irrelevant, da diese bei hinreichend großem n nicht mehr ins Gewicht fallen.
Es kann somit auch sein, dass beispielsweise O(n²) schneller ist als O(n) – zumindest bis zu einer gewissen Größe von n.
Im folgenden Beispiel-Diagramm werden drei fiktive Algorithmen gegenübergestellt: einer mit der Komplexitätsklasse O(n²) und zwei mit O(n), wobei einer davon schneller ist als der andere. Es ist gut zu sehen, wie bis zu n = 4 der orangene O(n²)-Algorithmus weniger Zeit benötigt als der gelbe O(n)-Algorithmus. Und sogar bis n = 8 weniger Zeit als der türkise O(n)-Algorithmus.
Ab hinreichend großem n – also ab n = 9 – ist und bleibt O(n²) der langsamste Algorithmus.
Als nächstes kommen wir zu zwei nicht ganz so intuitiv verständlichen Komplexitätsklassen.
O(log n) – logarithmischer Aufwand
Ausgesprochen: „O von log n“
Der Aufwand wächst ungefähr um einen konstanten Betrag, wenn sich die Anzahl der Eingabeelemente verdoppelt.
Wenn sich beispielsweise der Aufwand um eine Sekunde erhöht, wenn die Anzahl der Eingabeelemente von 1.000 auf 2.000 steigt, dann erhöht er sich lediglich um eine weitere Sekunde, wenn der Aufwand auf 4.000 steigt und wiederum um eine weitere Sekunde, wenn der Aufwand auf 8.000 steigt.
O(log n) Beispiel
Ein Beispiel für logarithmischen Aufwand ist die binäre Suche nach einem bestimmten Element in einem sortierten Array der Größe n.
Da wir mit jedem Suchschritt den zu durchsuchenden Bereich halbieren, können wir im Umkehrschluss mit nur einem Suchschritt mehr ein doppelt so großes Array durchsuchen.
(Die älteren unter uns kennen das vielleicht noch von der Suche im Telefonbuch oder in einem Lexikon.)
O(log n) Beispiel-Quellcode
Das folgende Beispiel (LogarithmicTimeSimpleDemo) misst, wie sich der Aufwand für die binäre Suche innerhalb eines sortierten Arrays im Verhältnis zur Größe des Arrays verändert:
publicstaticvoidmain(String[] args){
for (int n = 32; n <= 536_870_912; n *= 2) {
int[] array = createArrayOfSize(n);
long time = System.nanoTime();
Arrays.binarySearch(array, 0);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
privatestaticint[] createArrayOfSize(int n) {
int[] array = newint[n];
for (int i = 0; i < n; i++) {
array[i] = i;
}
return array;
}Code-Sprache:Java(java)
Bessere Messergebnisse bekommen wir, wie zuvor, mit dem Testprogramm TimeComplexityDemo und der Klasse LogarithmicTime. Hier die Ergebnisse:
Die Problemgröße n wächst hier jeweils um den Faktor 64. Der Aufwand wächst nicht immer exakt um den gleichen Wert, aber doch ausreichend genau, um zu demonstrieren, dass logarithmischer Aufwand deutlich günstiger ist als linearer Aufwand (bei welchem die benötigte Zeit auch jeweils um den Faktor 64 wachsen würde).
Die vollständigen Testergebnisse findest Du, wie auch zuvor, in der Datei test-results.txt.
O(n log n) – quasi-linearer Aufwand
Ausgesprochen: „O von n log n“
Der Aufwand wächst etwas stärker als linear, da die lineare Komponente mit einer logarithmischen multipliziert wird; man kann zum besseren Verständnis auch ein Multiplikationszeichen einfügen: O(n × log n).
Am besten lässt sich das am Graphen veranschaulichen. Wir haben hier eine Kurve, deren Steigung zu Beginn noch sichtbar wächst, mit wachsendem n sich aber einer Geraden annähert:
O(n log n) Beispiel
Als Beispiele für quasi-linearen Aufwand können effiziente Sortieralgorithmen wie Quicksort, Mergesort und Heapsort genannt werden.
Die Problemgröße steigt hier jeweils um den Faktor 16 und die benötigte Zeit um Faktor 18,5 bis 20,3. Das vollständige Testergebnis findest du, wie immer, in test-results.txt.
³ Genauer gesagt: Dual-Pivot Quicksort, welches bei Arrays mit weniger als 44 Elementen auf Insertion Sort wechselt. Aus diesem Grund startet dieser Test bei 64 Elementen, nicht bei 32 wie die anderen.
O-Notation Reihenfolge
Hier noch einmal die vorgestellten Komplexitätsklassen, aufsteigend sortiert nach Komplexität:
O(1) – konstanter Aufwand
O(log n) – logarithmischer Aufwand
O(n) – linearer Aufwand
O(n log n) – quasi-linearer Aufwand
O(n²) – quadratischer Aufwand
Und hier der Vergleich in graphischer Darstellung:
Ich habe die Kurven absichtlich so entlang der Aufwandsachse verschoben, dass die schlechteste Komplexitätsklasse O(n²) bei niedrigem n am schnellsten ist und die beste Komplexitätsklasse O(1) am langsamsten. Um dann zu zeigen, wie sich für hinreichend hohe Werte von n die Aufwände entsprechend den Erwartungen verschieben.
Weitere Komplexitätsklassen
Weitere Komplexitätsklassen sind z. B.
O(nm) – polynomieller Aufwand
O(2n) – exponentieller Aufwand
O(n!) – faktorieller Aufwand
Diese sind jedoch so schlecht, dass wir Algorithmen mit diesen Komplexitäten möglichst vermeiden sollten.
Im folgenden Diagram habe ich diese Klassen noch einmal mit aufgenommen (für O(nm) mit m=3):
Die y-Achse musste ich hier im Vergleich zum vorherigen Diagramm um Faktor 10 stauchen, damit ich die drei zusätzlichen Kurven sinnvoll abbilden konnte.
Fazit
Zeitkomplexität beschreibt, wie sich die Laufzeit eines Algorithmus in Abhängigkeit von der Menge der Eingabedaten verändert. Die gebräuchlichsten Komplexitätsklassen sind (aufsteigend sortiert nach Aufwand): O(1), O(log n), O(n), O(n log n), O(n²).
Algorithmen mit konstantem, logarithmischem, linearem und quasi-linearem Aufwand führen in der Regel bei Eingabegrößen bis zu mehreren Milliarden Elementen in überschaubarer Zeit zu einem Ende, während Algorithmen mit quadratischem Aufwand für dieselben Eingabemengen schnell theoretische Ausführungszeiten von mehreren Jahren erreichen können⁴. Sie sollten also, soweit wie möglich, vermieden werden.
⁴ Quicksort beispielsweise sortiert auf meinem Laptop eine Milliarde Elemente in 90 Sekunden; Insertion Sort hingegen braucht für eine Million Elemente 85 Sekunden; das wären auf eine Milliarde Elemente hochgerechnet 85 Millionen Sekunden – oder anders ausgedrückt: etwas über zwei Jahre und acht Monate!
Früher oder später müssen sich Java-Entwickler mit den Datenstrukturen Queue, Deque und Stack auseinandersetzen. In den Stack-, Queue- und Deque-Tutorials findest du Antworten auf die folgenden Fragen:
Wie funktionieren die Datenstrukturen Stack, Queue und Deque?
Wie unterscheiden sie sich?
Wie unterscheiden sich die Java-Interfaces bzw. Klassen Stack, Queue und Deque?
Welche Queue-, Deque- und Stack-Implementierungen gibt es im JDK?
Und welche der zahlreichen Implementierungen sind für welche Einsatzzwecke geeignet?
Wie kann man Queues, Deques und Stacks selbst implementieren?
Datenstrukturen: Was sind Stacks, Queues und Deques?
Ein Stack (auf deutsch: „Stapelspeicher“, „Kellerspeicher“ oder kurz „Stapel“, „Keller“) ist eine Liste von Elementen, bei der die Elemente auf derselben Seite (in Darstellungen klassischerweise oben) eingefügt („gestapelt“) und wieder entnommen werden:
Eine Queue (auf deutsch: „Warteschlange“) ist eine Liste von Elementen, bei der die Elemente auf einer Seite eingefügt und in derselben Reihenfolge auf der anderen Seite wieder entnommen werden:
Ein Deque (Double-ended queue, ausgesprochen „Deck“ – eine deutsche Übersetzung gibt es nicht) ist eine Liste von Elementen, bei der die Elemente sowohl auf der einen als auch auf der anderen Seite eingefügt und entnommen werden können:
Welche Java-Implementierungen gibt es, und welche sollte man einsetzen?
Die Einsatzempfehlungen basieren auf den Charakteristika der JDK-Queue- und Deque-Implementierungen, die in den verlinkten Artikeln näher beschrieben sind.
Folgendes sind meine Empfehlungen für allgemeine Einsatzzwecke:
Verwende ArrayDeque für single-threaded Anwendungen.
ArrayBlockingQueue als threadsichere, blockierende, bounded Queue, sofern du wenig Contention zwischen Producer- und Consumer-Threads erwartest.
LinkedBlockingQueue als threadsichere, blockierende, bounded Queues, wenn du eher hohe Contention zwischen Producer- und Consumer-Threads erwartest (am besten testen, welche Implementierung für deinen Use Case performanter ist).
DelayQueue, um Elemente nach einer vorgegebenen Wartezeit zu entnehmen.
SynchronousQueue, um Elemente synchron von einem Producer an einen Consumer zu übergeben.
LinkedTransferQueue, um einen Producer-Threads solange zu blockieren, bis das Element an einen Consumer-Thread transferiert wurde.
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion. Möchtest du über neue Tutorials und Artikel informiert werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.
Tag 1 ist schnell gelöst: Ein Counter wird für jede ‚(‚ hoch- und für jede ‚)‘ wieder runtergezählt – entweder bis zum Ende (Teil eins) oder bis der Zähler den Wert -1 erreicht (Teil zwei).
Tag 2 ist auch recht einfach – man muss nur jede Zeile in Länge, Breite und Höhe parsen und ein paar Grundrechenarten anwenden, um Flächen, Umfang und Volumen zu berechnen.
Die Lösung von Tag 3 habe ich mit einem Set implementiert, das alle Orte speichert, die Santa besucht hat. Die Lösung von Teil eins entspricht der Größe des Sets.
Für Teil zwei habe ich je ein Set für Santa und eines für Robo-Santa verwendet. Am Ende werden beide Sets zu einem zusammengeführt und dessen Größe zurückgegeben.
Um Tag 4 zu lösen, müssen wir über alle positiven Zahlen iterieren, bis wir einen Hash mit der geforderten Anzahl von führenden Nullen finden. Es geht etwa doppelt so schnell, wenn wir direkt im Byte-Array nach den führenden Nullen suchen und dieses nicht erst in einen Hex-String umwandeln.
Für Tag 5 habe ich zwei „Nice String“-Detektoren geschrieben, die das Interface Predicate<String> implementieren. Auf diese Weise können wir den Detektor für Teil zwei leicht austauschen.
Tag 6 habe ich mit einem zweidimensionalen Array von ints gelöst. Ich habe die beiden Regelsätze für Teil eins und zwei jeweils mit einer Map vom Kommando („turn on“, „toggle“, „turn off“) auf einen IntUnaryOperator implementiert, der die neue Helligkeit auf der Grundlage der vorherigen berechnet.
Das Domänenmodell für Tag 7 war ein bisschen schwierig zu gestalten. So sah es am Ende aus:
Wenn dieses Modell fertig verdrahtet ist, muss man nur noch die Instruction mit der destinationWireId finden und die Methode getSignal() für die WireSource dieser Instruction aufrufen.
An Tag 9 müssen wir das klassische „Problem des Handlungsreisenden“ (Travelling salesman problem) lösen. Da wir nur ein paar Städte haben, können wir eine einfache Tiefensuche durchführen, um alle möglichen Routen zu finden, und ihre minimale und maximale Länge festhalten.
Ein Blick in den von Tag 10 verlinkten Wikipedia-Artikel lässt mich vermuten, dass die die Länge der Sequenz nach 40 Runden in der Größenordnung von einer Million liegt. Das sollte jeder moderne Computer in wenigen Millisekunden simulieren können.
Der Algorithmus ist schnell implementiert und löst Teil eins in 5 Millisekunden. Mein Ergebnis ist 492.982 – liegt also in der angepeilten Größenordnung.
Auch für Teil zwei – 50 Runden – braucht der Algorithmus nur 70 ms.
Der Algorithmus für Tag 11 schafft die Aufgabe auch ohne Optimierungen in unter 100 ms. Mit einigen Optimierungen lässt sich diese Zeit stark reduzieren:
Der String wird zu Beginn in ein Character-Array umgewandelt; alle Operationen erfolgen auf diesem; die Rückumwandung in einen String erfolgt erst am Ende.
Zu Beginn wird geprüft, ob das Passwort einen der Buchstaben i, l, o enthält. Wenn ja, dann wird die entsprechende Stelle sofort erhöht und alle Folgestellen auf ‚a‘ gesetzt.
Beim Hochzählen werden die Buchstaben i, l, o übersprungen.
Mit diesen Optimierungen findet der Algorithmus das nächste Passwort in 0,016 ms!
Teil eins von Tag 12 lässt sich mit einem simplen regulären Ausdruck lösen: „-?\d+“ (die Anführungszeichen gehören nicht dazu). Wir müssen nur noch alle Treffer aufsummieren.
Teil zwei lässt sich mit einem JSON-Parser (z. B. Gson) und Rekursion gut lösen.
Teil eins von Tag 14, also die Entfernung, die ein Rentier nach einer bestimmten Zeit zurückgelegt hat, lässt sich leicht berechnen.
Die gleiche Formel können wir für Teil zwei anwenden, mit ihr lässt sich die Aufgabe in weniger als einer Millisekunde lösen. Die Zeitkomplexität ist allerdings O(n² · m), wobei n die simulierte Zeit ist und m die Anzahl der Rentiere. Die benötigte Zeit wächst also im Quadrat mit der simulierten Zeit.
Schneller geht es, wenn wir den Fortschritt der Rentiere Sekunde für Sekunde simulieren (so habe ich Teil zwei letztlich implementiert). So erreichen wir die deutlich bessere Zeitkomplexität O(n · m).
Die Aufgabe von Tag 15 lässt sich wieder mit einer Tiefensuche lösen, über die wir für alle möglichen Kombinationen von Zutataten den jeweiligen Score berechnen. Für Teil 2 habe ich einfach die Berechnung des Scores angepasst: Sobald ein Keks keine 500 Kalorien hat, wird dessen Score als 0 festgelegt.
Die Lösung für Tag 16 kann sehr elegant mit einem Predicate<Sue> als abstrakte Basisklasse für ein Strategy Pattern implementiert werden. So können für Teil eins und Teil zwei leicht zwei unterschiedliche Strategien implementiert werden.
Da alle angeforderten Eigenschaften vorab bekannt sind, könnten sie in entsprechend benannten Variablen gespeichert werden, wobei eine nicht bekannte Eigenschaft als null oder -1 gespeichert werden könnte. Eleganter und flexibler ist eine Liste von Tupeln von Eigenschaftname und -wert. Eine nicht bekannte Eigenschaft zeichnet sich dann durch Nichtvorhandensein in der Liste aus.
Die Aufgabe von Tag 17 kann per Tiefensuche gelöst werden. Bei 20 Containern gibt es genau 220 – also etwas mehr als eine Million – verschiedene Kombinationen. Es dauert etwa 3,2 Millisekunden, diese alle durchzuprobieren.
Doch es gibt eine Menge Optimierungspotential:
Ist bei einer unvollständigen Kombination das Zielvolumen exakt erreicht, haben wir eine Kombination gefunden und brauchen den Pfad nicht weiter zu verfolgen – die restlichen Container werden nicht benötigt.
Ist bei einer unvollständigen Kombination das Zielvolumen überschritten, können wir den aktuellen Pfad abbrechen.
Wenn die aktuelle Summe plus das kleinste Element der restlichen Elemente die Zielsumme überschreitet, können wir den Pfad ebenfalls abbrechen. Das kleinste Element der letzten x Elemente können wir vorab für jede Position innerhalb der Containerfolge bestimmen.
Wenn die Summe der Volumen der restlichen Container nicht ausreicht, um die noch benötigte Restsumme zu erreichen, können wir den Pfad ebenfalls abbrechen. Die Restsummen der letzten x Elemente können wir ebenfalls vorab berechnen.
Mit diesen Optimierungen dauert es nur noch 0,15 ms, alle passenden Kombinationen zu finden. Die Optomierungen haben den Algorithmus also um mehr als Faktor 20 beschleunigt.
An Tag 18 müssen wir Conway’s Game of Life implementieren. Da unser Grid begrenzt ist und relativ viele lebende Zellen enthält, eignet sich ein zweidimensionalen boolean-Array. (Bei unbegrenzten Feldern oder wenigen lebenden Zellen kann man auch nur die lebenden Zellen in einer Collection speichern.)
Die Anpassungen für Teil zwei – die vier Ecken immer eingeschaltet zu lassen – sind schnell erledigt.
Teil eins der Aufgabe von Tag 19 ist schnell gelöst, indem wir das Molekül Atom für Atom durchgehen, die Atome jeweils durch all ihre Ersetzungen ersetzen und die entstandenen Moleküle in einem Set speichern. Dessen Größe ist am Ende die Lösung.
Teil zwei ist deutlich komplexer. Ich habe mehrere Brute-Force-Lösungen durchprobiert: Breitensuche vorwärts, Tiefensuche vorwärts, Breitensuche rückwärts, Tiefensuche rückwärts. Der einzige Weg, der in akzeptabler Zeit überhaupt zu einer Lösung führte, war eine Tiefensuche rückwärts (d. h. der Versuch, vom Zielmolekül durch umgekehrtes Anwenden der Ersetzungsregeln zum Elektron zu gelangen) – mit Priorisierung der Ersetzungsregeln absteigend nach Länge des Zielmoleküls. Auf diese Weise wurde nach wenigen Sekunden zumindest ein Ergebnis gefunden. Doch es hätte mehrere Tage gedauert, die Tiefensuche bis zum Ende laufen zu lassen.
Auf eine bessere Lösung brachte mich erst ein Blick in das entsprechende Reddit-Topic:
Wenn wir uns die Ersetzungsregeln genauer anschauen, fällt auf, dass diese einem der folgenden Muster zuzuordnen sind, wobei X für ein beliebiges Atom steht:
e => XX
X => XX
X => XRnXAr
X => XRnXYXAr
X => XRnXYXYXAr
Rn, Y und Ar stehen nur auf der rechten Seite der Regeln. Wenn wir sie durch ‚(‚, ‚,‘ und ‚)‘ ersetzen, sehen die Regeln wie folgt aus:
e => XX
X => XX
X => X(X)
X => X(X,X)
X => X(X,X,X)
Auf der linken Seite steht immer genau ein Atom. Und jedes Zielmuster hat eine spezifische Länge. Die Anwendung eines bestimmten Musters verlängert also das Molekul um eine bestimmte Anzahl Atome:
e => XX – von 1 auf 2, also +1
X => XX – von 1 auf 2, also +1
X => X(X) – von 1 auf 4, also +3
X => X(X,X) – von 1 auf 6, also +5
X => X(X,X,X) – von 1 auf 8, also +7
Wenn wir keine Klammern und Kommas hätten, wäre die Anzahl der Schritte, um von einem Atom („e“) zu n Atomen zu gelangen genau n-1, da wir das Molekül in jedem Schritt um ein Atom verlängern.
Beispiel: Um von „e“ zu „XXXX“ (n = 4) zu gelangen, bräuchten wir 4-1 = 3 Schritte:
e → XX
XX → XXX
XXX → XXXX
Wenn wir zusätzlich die Regel X => X(X) beachten, verlängert sich das Molekül zusätzlich um die „Klammer-Atome“. Um aus dem Zielmolekül die Anzahl der Schritte zu berechnen, können wir diese „Klammer-Atome“ einfach wieder abziehen. Wir bräuchten also n-1-(Anzahl der Klammern) Schritte.
Beispiel: Um von „e“ zu „X(X)X(X)“ (n = 8) zu gelangen, bräuchten wir 8-1-4 = 3 Schritte:
e → XX
XX → X(X)X (erstes X ersetzt)
X(X)X → X(X)X(X) (letztes X ersetzt)
Wenn wir nun auch noch die Regeln X => X(X,X) und X => X(X,X,X) beachten, verlängert sich das Molekül mit jedem Komma um zwei weitere Atome: das Komma-Atom selbst und das auf das Komma folgende Atom. Für jedes Komma müssen wir also zwei Atome abziehen. Als Gesamtformel ergibt sich:
Für Tag 21 habe ich einen Simulator geschrieben, der das Spiel mit gegebenen Parametern („hit points“, „damage“, „armor“ pro Spieler) durchspielt und den Sieger zurückgibt. Mit dem Simulator können alle erlaubten Kombinationen von Waffe, Verteidigung und Ringen (es gibt nur 1.080 solcher Kombinationen) durchgespielt werden.
Wenn wir vorab die möglichen Kombinationen nach Gesamtkosten sortieren (aufsteigend für Teilaufgabe eins und absteigend für Teilaufgabe zwei), dann können wir die Simulationen abbrechen, sobald die erste Kombination gefunden wurde, bei der der Spieler (bei Teilaufgabe eins) bzw. der Boss (bei Teilaufgabe zwei) gewinnt.
Die Aufgabe von Tag 22 kann gut mit einer Breitensuche gelöst werden, da es pro Spielrunde nicht allzu viele Möglichkeiten gibt (die bezahlbaren und aktuell nicht aktiven Zaubersprüche).
Ich habe die Breitensuche mit einer PriorityQueue implementiert, die die erreichten Spielstände nach Gesamtkosten aufsteigend sortiert.
Wenn eine Lösung gefunden wurde und wir einen Zauberspruch überspringen mussten (weil dieser nicht bezahlbar war oder bereits aktiv ist), könnten wir noch eine bessere Lösung finden – von einem weiter hinten in der Queue liegenden Spielstand aus mit gleich viel oder höheren Kosten kombiniert mit einem günstigeren Zauberspruch.
Wir brauchen die Suche jedoch nur solange fortzusetzen, bis die Kosten des Spielstands in der Queue plus die Kosten des günstigsten Zauberspruchs gleich oder höher als die Kosten der bisher besten Lösung sind. Alle weiteren Spielstände in der Queue würden zu einer teureren Lösung führen.
An Tag 23 müssen wir eine CPU mit zwei Registern und sechs Instruktionen emulieren. Dies ist recht einfach, und auch die Änderungen für Teil zwei sind schnell gemacht.
Für die Aufgabe von Tag 24 eignet sich wieder eine Tiefensuche über die möglichen Paket-Kombinationen. Dabei müssen wir nur für das erste Abteil eine optimale Lösung finden. Wannimmer wir für das erste Abteil eine Lösung gefunden haben und diese besser ist als die bisher beste Lösung, müssen wir nur prüfen, ob es für die restlichen Abteile wenigstens eine Lösung gibt.
Sobald die Tiefensuche für das erste Abteil zu mehr Paketen führt als die bisher beste Lösung, kann der entsprechende Pfad abgebrochen werden.
Meine Implementierung findet eine Lösung für Teil eins in 1,5 s und für Teil zwei in 40 ms.
An Tag 25 von Advent of Code 2015 müssen wir einen Code-Generator implementieren. Die Beschreibung der Aufgabe ist lang, die Lösung erfordert aber nur wenige Zeilen Code:
staticintsolve(int row, int col){
int elementIndex = calculateElementIndex(row - 1, col - 1);
return getCode(elementIndex);
}
staticintcalculateElementIndex(int row, int col){
int diagonalNumber = row + col;
int diagonalStart = diagonalNumber * (diagonalNumber + 1) / 2;
return diagonalStart + col;
}
staticintgetCode(int iterations){
int code = 20_151_125;
for (int i = 0; i < iterations; i++) {
code = (int) (code * 252_533L % 33_554_393);
}
return code;
}
Code-Sprache:Java(java)
Wenn dir der Artikel gefallen hat, teile ihn gerne über einen der Share-Buttons am Ende. Möchtest du per E-Mail informiert werden, wenn ich einen neuen Artikel veröffentliche? Dann klicke hier, um dich in den HappyCoders-E-Mail-Verteiler einzutragen


















































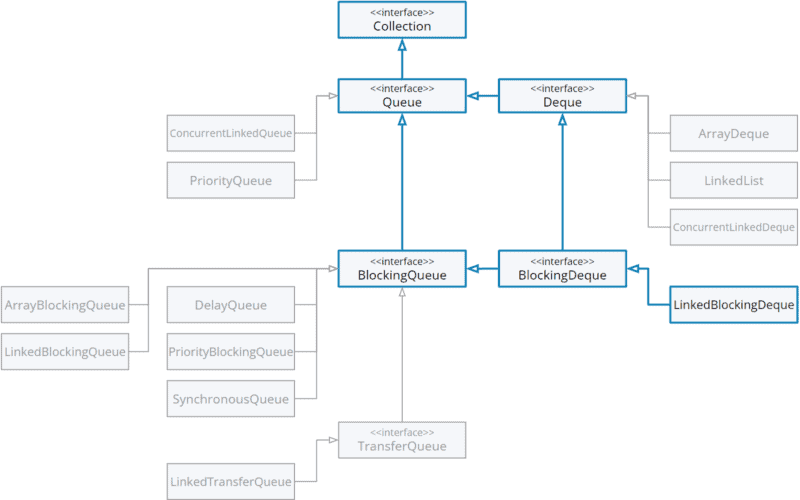























































































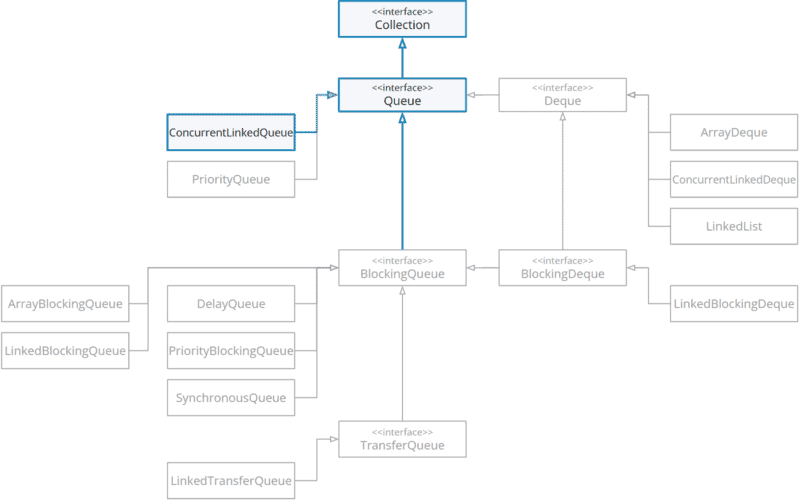




































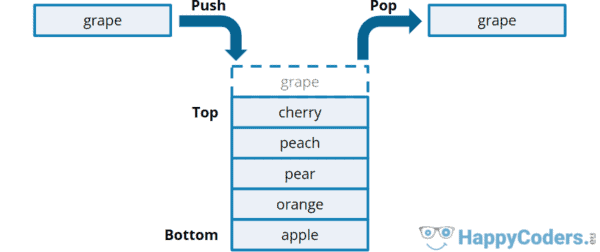



































































































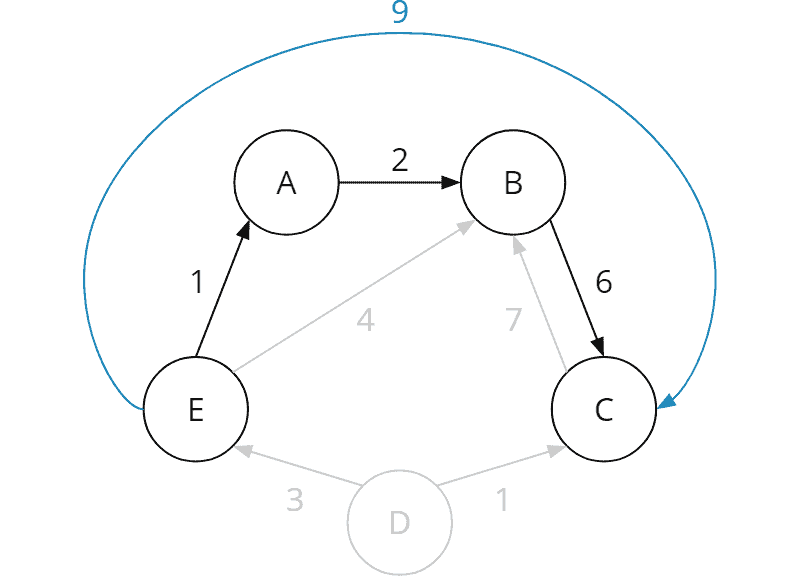
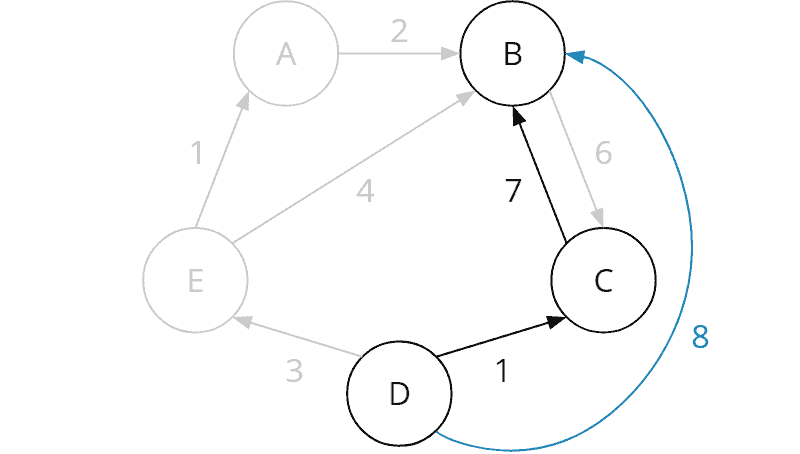

































































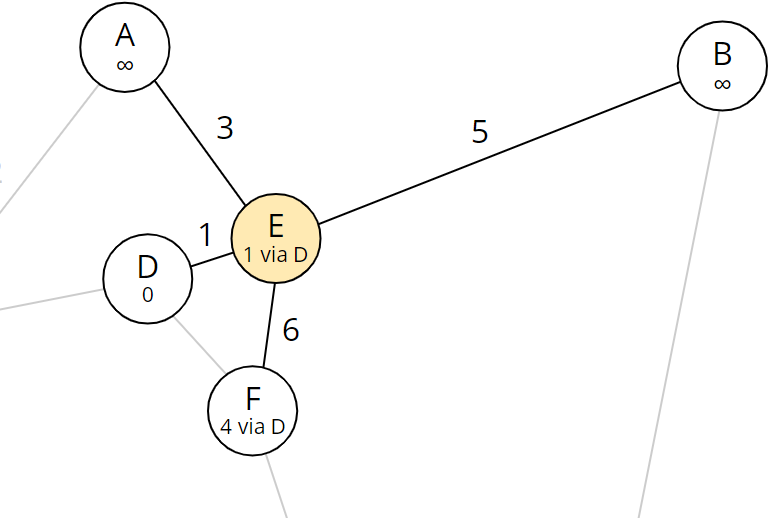



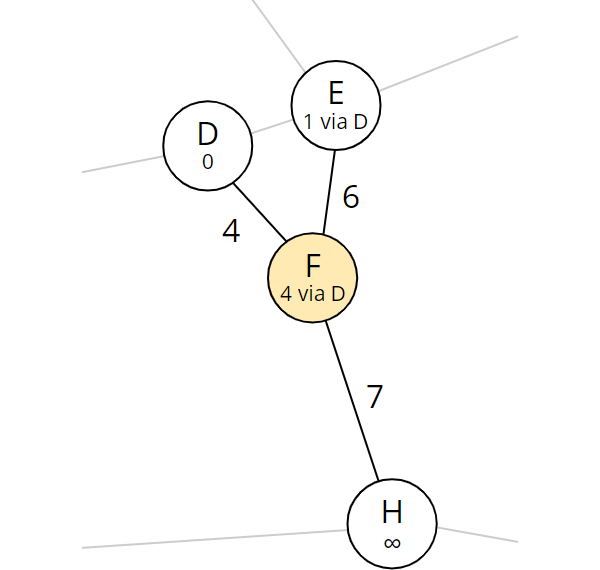


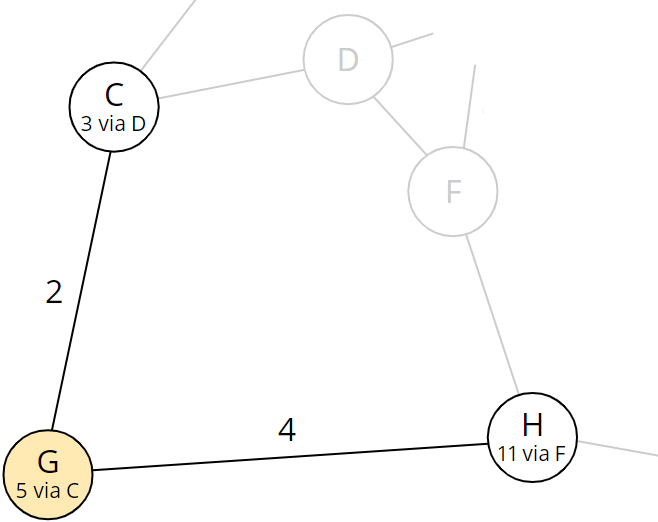















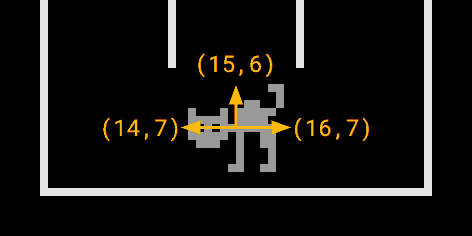



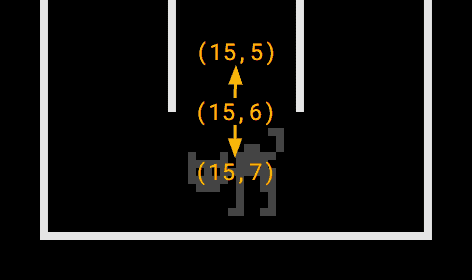











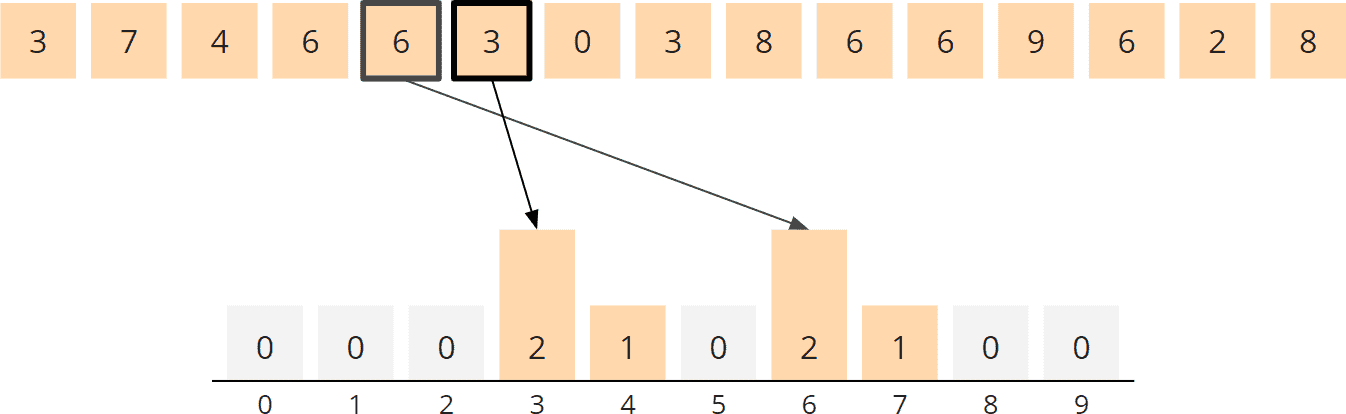





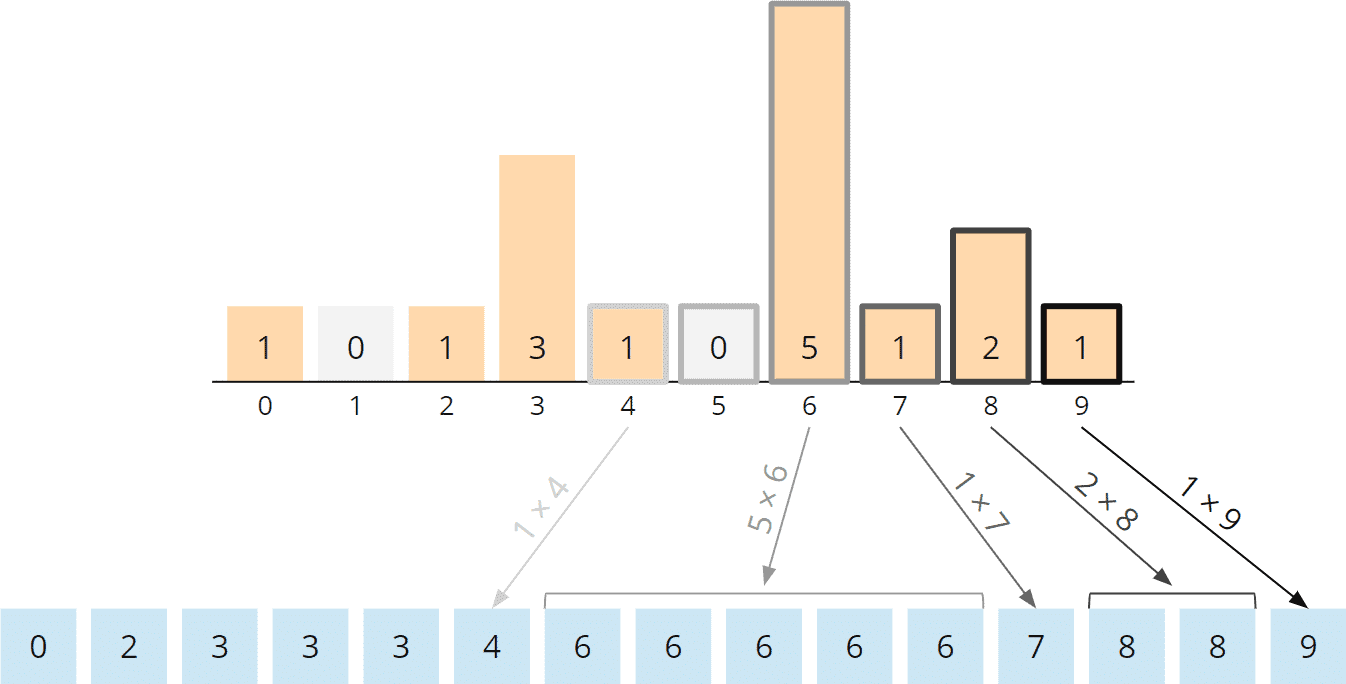











































































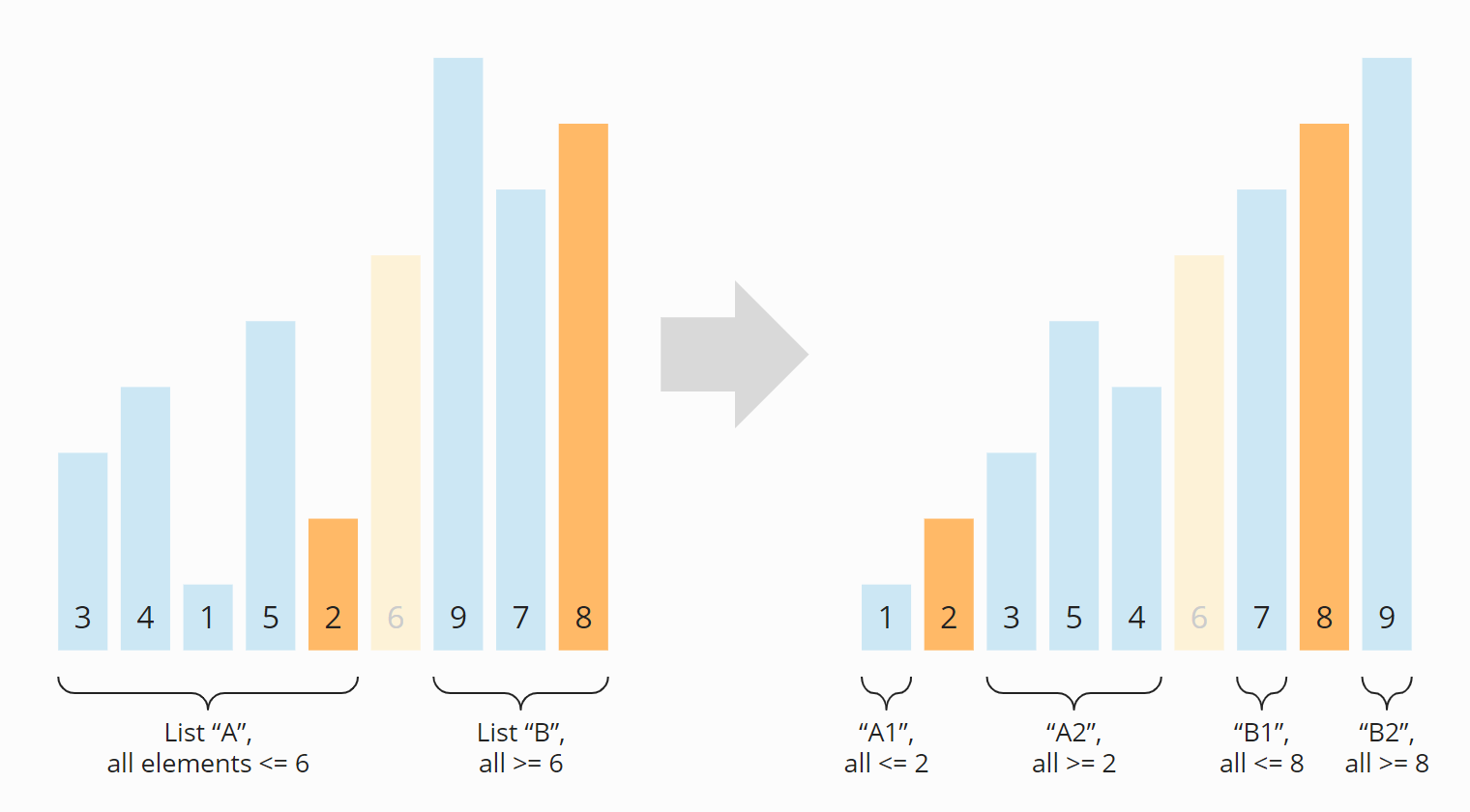














































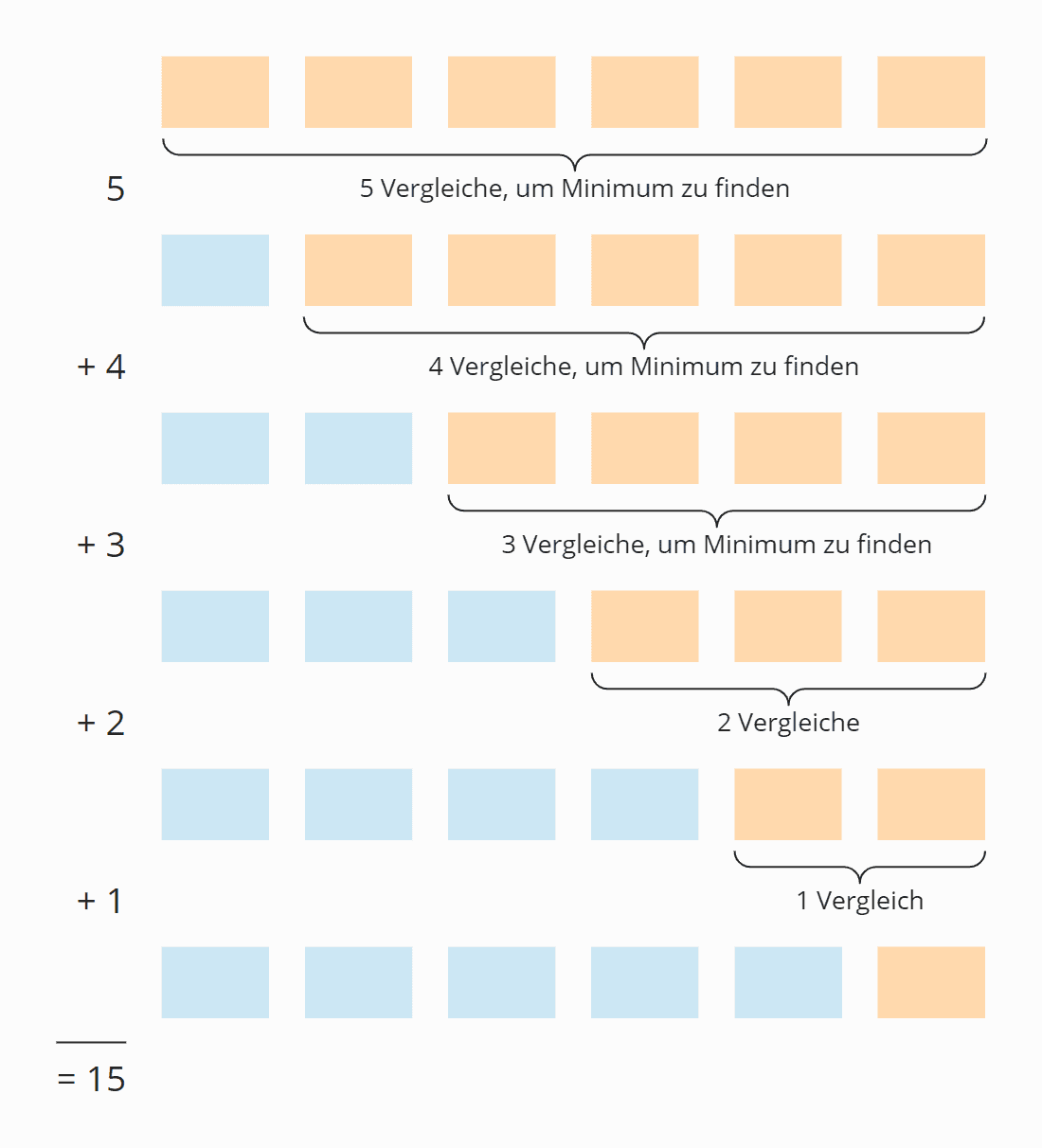




















![Sortieren in Java [Tutorial]](https://janice.happycoders.eu/wp-content/uploads/2020/06/sorting-in-java-feature-image.jpg)
![Sortieralgorithmen [Ultimate Guide]](https://janice.happycoders.eu/wp-content/uploads/2020/06/sorting-algorithms-java-feature-image.jpg)