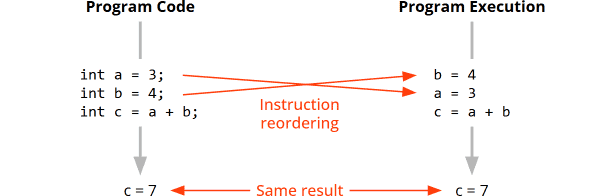
Das Initialization-on-Demand Holder Idiom ist ein sicherer und effizienter Weg, um in Multithreading-Anwendungen statische Felder erst bei Bedarf zu initialisieren. Es verhindert dabei subtile Race Conditions, ohne die Performance durch vollständige Synchronisierung aller Zugriffe zu beeinträchtigen.
In diesem Artikel erfährst du:
- Was ist die Motivation für das Initialization-on-Demand Holder Idiom?
- Warum ist die vollständige Synchronisierung mit
synchronizednicht optimal? - Wie wird das Initialization-on-Demand Holder Idiom in Java implementiert?
- Welche Alternativen gibt es?
Motivation
Bei zeitaufwändigen Initialisierungsprozessen ist es oft ratsam, diese erst bei tatsächlichem Bedarf durchzuführen. Beispielsweise könnten es Sinn machen, einen Logger, der eine Verbindung zu einer Datenbank aufbaut, erst dann zu initialisieren, wenn das erste Mal etwas geloggt wird. Diese „Lazy Initialization“ verhindert unnötige Verzögerungen beim Programmstart.
In einer Single-Thread-Umgebung ist die Implementierung unkompliziert:
public class UserService {
private static Logger logger;
private static Logger getLogger() {
if (logger == null) {
logger = initializeLogger();
}
return logger;
}
public void createUser(User user) {
// . . .
getLogger().info("User created");
}
// . . .
}Code-Sprache: Java (java)Der erste Aufruf von getLogger() initializiert den Logger und speichert ihn im statischen Feld logger. Nachfolgende Aufrufe liefern direkt das gespeicherte Objekt.
Diese Implementierung ist allerdings nicht threadsicher.
In einer Multithreading-Anwendung können hier verschiedene subtile Effekte auftreten, die zu kaum zu reproduzierenden und damit nur schwer zu behebenden Race Conditions führen können:
- Bei nahezu gleichzeitigem ersten Aufruf der
getLogger()-Methode aus zwei Threads könnten beide Threads daslogger-Feld alsnullsehen, so dass der Logger mehrfach initialisiert wird. - Durch Thread-Caching-Effekte könnte ein Thread selbst dann, wenn ein anderer Thread das
logger-Feld bereits zugewiesen hat, dieses noch alsnullsehen. - Durch Instruction Reordering könnte ein Thread das
logger-Feld als nichtnullsehen, dieses könnte aber auf ein noch nicht vollständig initialisiertesLogger-Objekt zeigen.
Die drei Effekte habe ich im Artikel über das Double-Checked Locking Idiom ausführlich beschrieben.
In Multithreading-Anwendungen müssen wir daher den Zugriff auf das logger-Feld durch geeignete Maßnahmen synchronisieren.
Lösung 1: Vollständige Synchronisation
Der einfachste Ansatz ist eine vollständige Synchronisation der getLogger()-Methode durch synchronized (oder alternativ ein explizites Lock):
// ↓
private synchronized static Logger getLogger() {
if (logger == null) {
logger = initializeLogger();
}
return logger;
}Code-Sprache: Java (java)Diese Implementierung führt jedoch zu erheblichen Performance-Einbußen, da:
- jeder Aufruf den Verwaltungsoverhead einer kompletten Synchronisation erfordert,
- Threads bei parallelen Zugriffen warten müssen,
- Ein- und Austritt aus dem
synchronized-Block vollständige Cache-Hauptspeicher-Synchronisationen auslösen.
Aufgrund dieses signifikanten Mehraufwands ist diese Lösung insbesondere für oft aufgerufene Methoden nicht optimal.
Lösung 2: Double-Checked-Locking
Eine weitere Lösungsmöglichkeit ist das oben bereits erwähnte Double-Checked-Locking. Dieses habe ich ausführlich in dem verlinkten Artikel erläutert.
Ein korrekt implementiertes Double-Checked Locking löst die oben genannten Performance-Probleme, ist aber recht kompliziert und damit fehleranfällig in der Implementierung.
Lösung 3: Initialization-on-Demand Holder
Die dritte Lösung ist das Initialization-on-Demand Holder Idiom. Auch dieses löst die oben genannten Performance-Probleme. Es ist einfacher umzusetzen als Double-Checked Locking und damit weniger fehleranfällig – es funktionert aber nur mit statischen Feldern, nicht mit Instanzfeldern.
Und so wird es implementiert:
public class UserService {
private static class LoggerHolder {
private static final Logger LOGGER = initializeLogger();
}
public void registerUser(User user) {
// . . .
LoggerHolder.LOGGER.info("User created");
}
// . . .
}Code-Sprache: Java (java)Hier wird das Logger-Objekt im statischen LOGGER-Feld der inneren Klasse LoggerHolder gespeichert.
Aber wird damit der Logger nicht schon beim Programmstart initialisiert? Wollten wir nicht genau das vermeiden?
Nein, denn die JVM lädt und initialisiert eine Klasse erst dann, wenn sie benötigt wird.
Wie stellt das Initialization-on-Demand Holder Idiom die Lazy Initialization sicher?
Wenn die JVM (die Java Virtual Machine) die UserService-Klasse lädt, lädt sie nicht automatisch die LoggerHolder-Klasse mit. Sie lädt die Klasse erst dann, wenn zur Laufzeit zum ersten Mal auf LoggerHolder.LOGGER zugegriffen wird.
Hier ist ein kleines Demo-Programm, mit dem du das ausprobieren kannst:
public class InitializationOnDemandHolderIdiomDemo {
private static class LoggerHolder {
private static final Logger LOGGER = initializeLogger();
private static Logger initializeLogger() {
System.out.println(">>>>>>>>>> Initializing logger <<<<<<<<<<");
return Logger.getLogger(InitializationOnDemandHolderIdiomDemo.class.getName());
}
}
public static void main(String[] args) {
InitializationOnDemandHolderIdiomDemo demo =
new InitializationOnDemandHolderIdiomDemo();
demo.doSomethingWithoutLogging();
demo.doSomethingWithoutLogging();
demo.doSomethingWithoutLogging();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
}
private void doSomethingWithoutLogging() {
System.out.println("Not logging");
}
private void doSomethingWithLogging() {
System.out.println("\nI'm going to log something...");
LoggerHolder.LOGGER.info("Some log message");
System.out.println("Logged something");
}
}Code-Sprache: Java (java)Du wirst folgende Ausgabe sehen:
Not logging
Not logging
Not logging
I'm going to log something...
>>>>>>>>>> Initializing logger <<<<<<<<<<
Logged something
I'm going to log something...
Logged something
I'm going to log something...
Logged somethingCode-Sprache: Klartext (plaintext)Du siehst: Der Logger wird erst dann – und nur dann – initialisiert, wenn er das erste Mal benötigt wird. Damit können wir an die Anforderung „Lazy Initialization“ einen Haken setzen.
Und was ist mit der Threadsicherheit?
Wie garantiert das Initialization-on-Demand Holder Idiom die Threadsicherheit?
Die Threadsicherheit wird beim Laden und Initialisieren von Klassen automatisch durch die JVM (die Java Virtual Machine) garantiert.
D. h. wenn der erste Zugriff auf LoggerHolder.LOGGER gleichzeitig durch zwei Threads erfolgen sollte, dann stellt die JVM zum einen sicher, dass das LoggerHolder.LOGGER nur einmal initialisiert wird – und zum anderen, dass beide Threads das vollständig initialisierte Logger-Objekt sehen.
Das klingt ja fast zu schön um wahr zu sein…
Nachteil des Initialization-on-Demand Holder Idioms
Wie fast immer gibt es auch bei dieser Lösung einen Nachteil:
Wenn beim ersten Zugriff auf LoggerHolder.LOGGER der Aufruf der initializeLogger()-Methode fehlschlagen sollte, dann wird bei folgenden Zugriffen nicht etwa erneut versucht, initializeLogger() aufzurufen. Nein – wenn das Initialisieren einer Klasse einmal fehlgeschlagen ist, wird die JVM nicht erneut versuchen, die Klasse zu initialisieren. Stattdessen wird jeder weitere Zugriff auf LoggerHolder.LOGGER unverzüglich zu einem NoClassDefFoundError führen.
Hier ist ein kleines Programm, das das Verhalten demonstriert:
public class InitializationOnDemandHolderIdiomErrorDemo {
private static class LoggerHolder {
private static final Logger LOGGER = initializeLogger();
private static Logger initializeLogger() {
System.out.println(">>>>>>>>>> Initializing logger <<<<<<<<<<");
throw new RuntimeException("Initialization failed");
}
}
public static void main(String[] args) {
InitializationOnDemandHolderIdiomErrorDemo demo =
new InitializationOnDemandHolderIdiomErrorDemo();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
}
private void doSomethingWithLogging() {
try {
System.out.println("\nI'm going to log something...");
LoggerHolder.LOGGER.info("I did something smart");
System.out.println("Logged something");
} catch (Throwable t) {
System.out.println(">>>>>>>>>> " + t.getClass().getName() + " <<<<<<<<<<");
}
}
}Code-Sprache: Java (java)Das Programm gibt folgendes aus:
I'm going to log something...
>>>>>>>>>> Initializing logger <<<<<<<<<<
>>>>>>>>>> java.lang.ExceptionInInitializerError <<<<<<<<<<
I'm going to log something...
>>>>>>>>>> java.lang.NoClassDefFoundError <<<<<<<<<<
I'm going to log something...
>>>>>>>>>> java.lang.NoClassDefFoundError <<<<<<<<<<Code-Sprache: Klartext (plaintext)Du siehst: Nur beim ersten Zugriff auf LoggerHolder.LOGGER wird initializeLogger() aufgerufen. Alle folgenden Zugriffe führen direkt zu einem NoClassDefFoundError.
Bei den anderen Lösungen – vollständiger Synchronisation und Double-Checked Locking – würde hingegen bei jedem weiteren Aufruf der getLogger()-Methode erneut versucht werden, das Logger-Objekt zu initialisieren.
Hier ein entsprechendes Demo für die Variante mit vollständiger Synchronisation:
public class LazyInitializationErrorDemo {
private static Logger logger;
private static Logger getLogger() {
if (logger == null) {
logger = initializeLogger();
}
return logger;
}
private static Logger initializeLogger() {
System.out.println(">>>>>>>>>> Initializing logger <<<<<<<<<<");
throw new RuntimeException("Initialization failed");
}
public static void main(String[] args) {
LazyInitializationErrorDemo demo = new LazyInitializationErrorDemo();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
demo.doSomethingWithLogging();
}
private void doSomethingWithLogging() {
try {
System.out.println("\nI'm going to log something...");
getLogger().info("I did something smart");
System.out.println("Logged something");
} catch (Throwable t) {
System.out.println(">>>>>>>>>> " + t.getClass().getName() + " <<<<<<<<<<");
}
}
}
Code-Sprache: Java (java)Und hier die Ausgabe des Programms:
I'm going to log something...
>>>>>>>>>> Initializing logger <<<<<<<<<<
>>>>>>>>>> java.lang.RuntimeException <<<<<<<<<<
I'm going to log something...
>>>>>>>>>> Initializing logger <<<<<<<<<<
>>>>>>>>>> java.lang.RuntimeException <<<<<<<<<<
I'm going to log something...
>>>>>>>>>> Initializing logger <<<<<<<<<<
>>>>>>>>>> java.lang.RuntimeException <<<<<<<<<<Code-Sprache: Klartext (plaintext)Hier wird nun bei jedem Aufruf von getLogger() erneut versucht, den Logger zu initialisieren.
Ob das gewünscht ist oder nicht, hängt selbstverständlich von den Anforderungen ab.
Kommende Alternative: Lazy Constants
Auch den JDK-Entwickler:innen ist bewusst, dass die existierenden Lösungen allesamt nicht optimal sind. Daher wird aktuell an einem neuen Feature gearbeitet: Lazy Constants.
Lazy Constants wurden in Java 25 unter dem Namen Stable Values als Preview-Version eingeführt und in Java 26 in Lazy Constants umbenannt und grundlegend überarbeitet. Eine Lazy Constant ist ein Container, der die threadsichere Initialisierung von Konstanten beim erstem Zugriff darauf hinter einer einfachen API kapselt.
Fazit
Um Felder in Multithreading-Anwendungen erst bei Bedarf zu initialisieren, können wir das Double-Checked Locking Idiom oder – für statische Felder – das in diesem Artikel beschriebene Initialization-on-Demand Holder Idiom einsetzen.
Beide Varianten sind performanter als eine vollständige Synchronisation der Zugriffsmethode mit synchronized oder einem expliziten Lock.
Beide Varianten sind allerding auch kompliziert in der Implementierung – und das kann leicht zu Fehlern führen – vor allem, da sich eine fehlerhafte Implementierung nur durch Race Conditions offenbart, und damit in der Regel nicht sofort, sondern unter Umständen erst nach Wochen oder Monaten.
An einer performanten und gleichzeitig leicht zu implementierenden Variante wird derzeit gearbeitet: Lazy Constants (zum Stand von Java 26 im Preview-Stadium).