
In diesem Artikel lernst du den Sortieralgorithmus „Radix Sort“ kennen. Du erfährst:
- Wie funktioniert Radix Sort? (Schritt für Schritt)
- Wie implementiert man Radix Sort in Java?
- Welche Zeit- und Platzkomplexität hat Radix Sort?
- Welche Varianten gibt es von Radix Sort?
- … und was bedeutet überhaupt der Begriff „Radix“?
Fangen wir mit der letzten Frage an:
Was ist Radix Sort?
„Radix“ ist zwar das lateinische Wort für „Wurzel“ – dennoch hat Radix Sort nichts mit Wurzelziehen zu tun.
Die „Radix“ eines Zahlensystems (auch „Basis“ genannt) bezeichnet vielmehr die Anzahl der Ziffern, die zur Darstellung von Zahlen in diesem Zahlensystem benötigt werden. Die Radix im Dezimalsystem ist 10, die Radix des Binärsystems ist 2, und die Radix des Hexadezimalsystems ist 16.
Bei Radix Sort sortieren wir die Zahlen Ziffer für Ziffer – und nicht, wie bei den meisten anderen Sortierverfahren, indem wir zwei Zahlen miteinander vergleichen. Wie genau das funktioniert, liest du im folgenden Kapitel.
Radix Sort Algorithmus
Den Algorithmus für Radix Sort erkläre ich am besten Schritt für Schritt an einem Beispiel. Folgende Zahlen sollen sortiert werden:

Wir betrachten zu Beginn ausschließlich die letzte Ziffer (es gibt auch Radix-Sort-Varianten, bei denen man bei der ersten Ziffer beginnt, aber dazu kommen wir später):

Wir sortieren die Zahlen in zwei Phasen: einer Partitionierungsphase und einer Sammelphase.
Partitionierungsphase
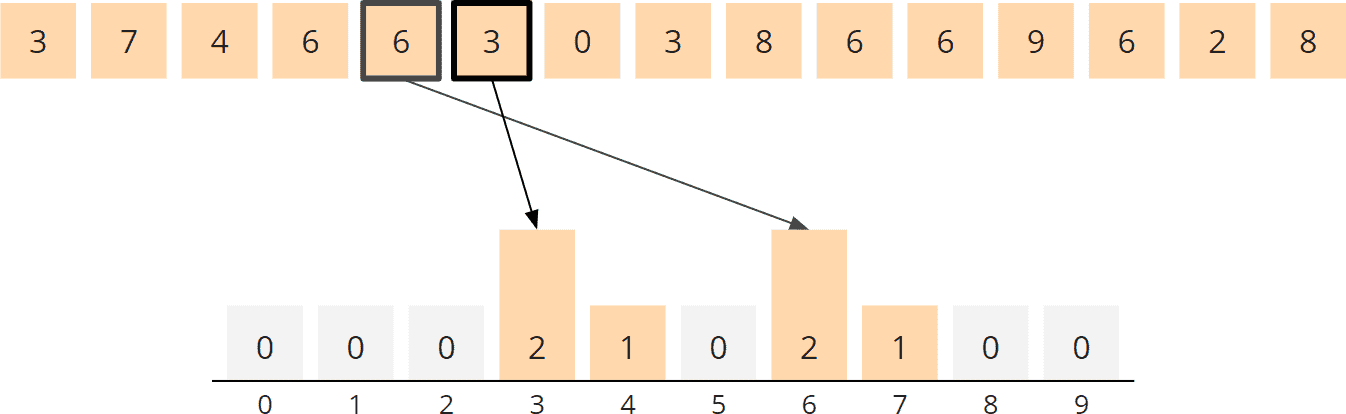
Für die Partitionierung legen wir zehn sogenannte „Buckets“ an, bezeichnet mit „0“ bis „9“. Auf diese verteilen wir die Zahlen entsprechend ihrer jeweils letzten Ziffer. Die folgende Grafik demonstriert, wie wir die erste Zahl, die 41, in den Bucket „1“ legen:

Die zweite Zahl, die 573, legen wir, entsprechend ihrer letzten Ziffer, in den Bucket „3“:

Die dritte Zahl, die 3, legen wir ebenfalls in den Bucket „3“:

Auf die gleiche Art verteilen wir auch die restlichen Zahlen auf die Buckets:

Die Partitionierungsphase für die letzte Ziffer ist damit abgeschlossen.
Sammelphase
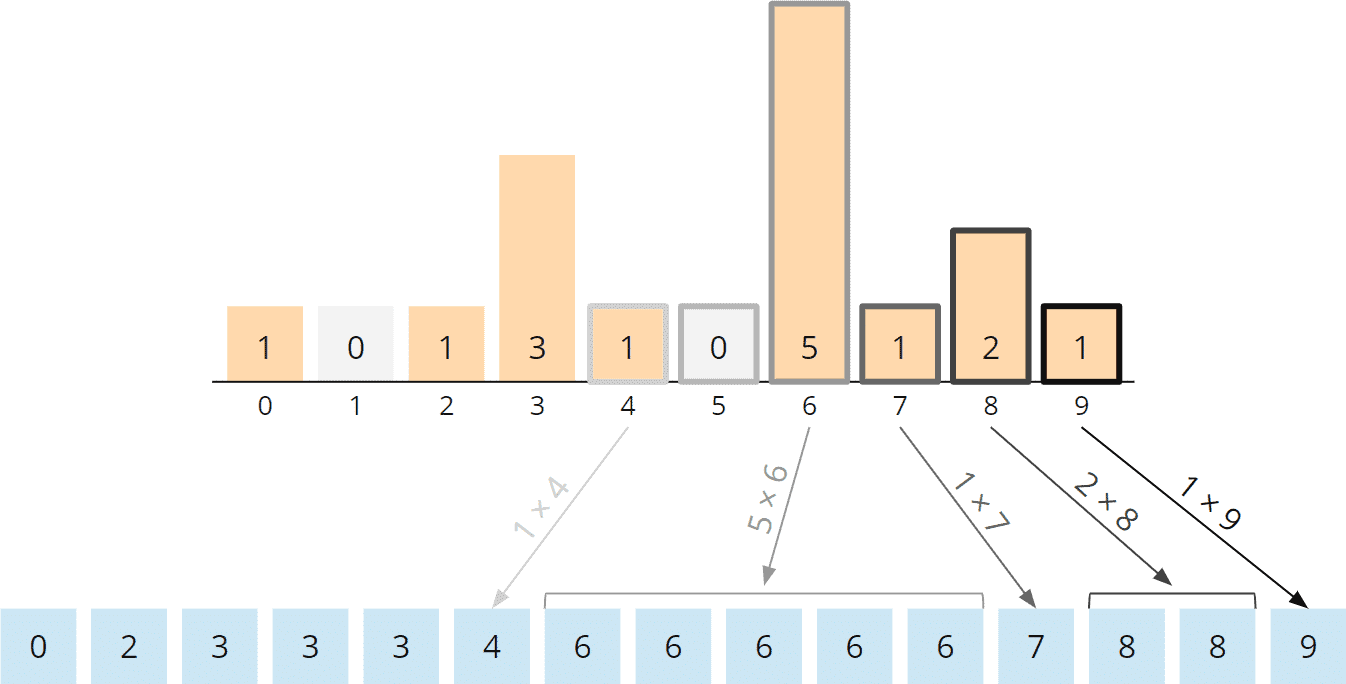
An die Partitionierungsphase schließt sich die Sammelphase an. Wir sammeln die Zahlen, Bucket für Bucket, in aufsteigender Reihenfolge – und innerhalb der Buckets von links nach rechts (also in der gleichen Reihenfolge wie die Zahlen in den jeweiligen Bucket eingetragen wurden) – in eine neue Liste.
Wir beginnen mit dem Buckets mit der kleinsten Ziffer, also Bucket 1:

Danach sammeln wir die Zahlen des nächsthöheren Buckets, also Bucket 3:

Und schließlich die Zahlen aus Bucket 6 und dann Bucket 8:

Alle Buckets sind nun geleert:

In dieser neuen Liste sind die Zahlen nach ihrer letzten Ziffer aufsteigend sortiert: 1, 1, 3, 3, 3, 6, 8
Nach Zehnerstelle sortieren
Wir wiederholen die Partitionierungs- und Sammelphase für die Zehnerstelle. Die zwei Phasen stelle ich dieses Mal mit nur jeweils einer Grafik dar.
In der Partitionierungsphase verteilen wir die Zahlen nach ihrer Zehnerstelle auf die Buckets:

Die Zehnerstelle von einstelligen Zahlen ist die Null. Dementsprechend habe ich die Drei als „03“ dargestellt.
In der Sammelphase entnehmen wir die Zahlen wieder Bucket für Bucket:

Die Zahlen sind nun nach ihren jeweils zwei letzten Ziffern sortiert: 3, 8, 36, 41, 71, 73, 93
Nach Hunderterstelle sortieren
Die gleiche Prozedur wiederholen wir für die Hunderterstelle. Zunächst die Partitionierungsphase:

Und im Anschluss die Sammelphase:

Nach der dritten und letzten Sammelphase sind die Zahlen nun vollständig sortiert.
Hier noch einmal das Endergebnis ohne führende Nullen:

Im nächsten Kapitel kommen wir zur Implementierung von Radix Sort.
Radix Sort in Java
Radix Sort kann auf verschiedene Weisen implementiert werden. Wir beginnen mit einer einfachen Variante, die sich sehr nah am beschriebenen Algorithmus orientiert. Danach zeige ich dir zwei alternative Implementierungen.
Variante 1: Radix Sort mit dynamischen Listen
Wir fangen mit einer leeren sort()-Methode an und füllen diese Schritt für Schritt.
(Das Endergebnis findest du am Ende dieses Abschnitts und in der Klasse RadixSortWithDynamicLists im GitHub-Repository dieser Sortier-Tutorial-Serie.)
public class RadixSortWithDynamicLists
public void sort(int[] elements) {
// We will implement this method step by step...
}
}Code-Sprache: Java (java)Da wir die zwei Phasen (Partitionierungsphase und Sammelphase) für jede Ziffer wiederholen müssen, müssen wir zunächst einmal feststellen, wie viele Ziffern unsere Zahlen überhaupt haben.
Das tun wir, indem wir die größte Zahl aus dem zu sortierenden Array ermitteln und danach zählen, wie oft sich diese Zahl durch 10 teilen lässt:
public class RadixSortWithDynamicLists
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
// TODO: Implement the partitioning and collection phases
}
private static int getMaximum(int[] elements) {
int max = 0;
for (int element : elements) {
if (element > max) {
max = element;
}
}
return max;
}
private int getNumberOfDigits(int number) {
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
}Code-Sprache: Java (java)Danach sortieren wir Ziffer für Ziffer. Dazu schreiben wir eine for-Schleife mit der Schleifenvariable digitIndex, wobei 0 für die Einerstelle steht, 1 für die Zehnerstelle, 2 für die Hunderterstelle, usw.
(In den folgenden Listings drucke ich die Klasse selbst nicht mehr mit ab, nur noch die Methoden innerhalb der Klasse.)
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
// TODO: Sort elements by digit at 'digitIndex'
}
}Code-Sprache: Java (java)Für den nächsten Schritt benötigen wir die Buckets, auf die wir die Zahlen verteilen können. Wir könnten hierfür zehn ArrayLists verwenden.
Eleganter ist es jedoch diese in eine Bucket-Klasse zu wrappen. Das macht zum einen den Code lesbarer; zum anderen ermöglicht es uns später die Implementierung der Buckets zu ändern, ohne den restlichen Code anpassen zu müssen.
Die Bucket-Klasse können wir als innere Klasse innerhalb der Klasse RadixSortWithDynamicLists anlegen:
private static class Bucket {
private final List<Integer> elements = new ArrayList<>();
private void add(int element) {
elements.add(element);
}
private List<Integer> getElements() {
return elements;
}
}Code-Sprache: Java (java)Das war die Vorbereitung.
Kommen wir zur Partitionierungsphase. Wir benötigen zehn Buckets, auf die wir die Zahlen verteilen können; diese generieren wir mit einer createBuckets()-Methode:
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}Code-Sprache: Java (java)Danach verteilen wir unsere Zahlen anhand der aktuell betrachteten Stelle digitIndex auf die Buckets:
private void distributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets) {
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
private int calculateDivisor(int digitIndex) {
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}Code-Sprache: Java (java)Der divisor ist dabei diejenige Zahl, durch die wir ein Element teilen müssen, so dass an der hintersten Stelle die aktuell zu betrachtende Ziffer steht – also 1 für die Einerstelle, 10 für die Zehnerstelle, 100 für die Hunderterstelle, usw.
Die Methoden der Partitionierungsphase fassen wir in einer partition()-Methode zusammen:
private Bucket[] partition(int[] elements, int digitIndex) {
Bucket[] buckets = createBuckets();
distributeToBuckets(elements, digitIndex, buckets);
return buckets;
}Code-Sprache: Java (java)In der Sammelphase müssen wir nun lediglich die Zahlen der einzelnen Buckets aneinanderreihen:
private void collect(Bucket[] buckets, int[] elements) {
int targetIndex = 0;
for (Bucket bucket : buckets) {
for (int element : bucket.getElements()) {
elements[targetIndex] = element;
targetIndex++;
}
}
}Code-Sprache: Java (java)Die partition()– und collect()-Methoden fassen wir in einer sortByDigit()-Methode zusammen:
private void sortByDigit(int[] elements, int digitIndex) {
Bucket[] buckets = partition(elements, digitIndex);
collect(buckets, elements);
}Code-Sprache: Java (java)Und jetzt schließen wir den Kreis, indem wir die sortByDigit()-Methode aus der digitIndex-Schleife der zu Beginn gezeigten sort()-Methode heraus aufrufen:
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}Code-Sprache: Java (java)Damit ist unserer Radix-Sort-Implementierung abgeschlossen.
Hier siehst du noch einmal den vollständigen Quellcode:
public class RadixSortWithDynamicLists {
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}
private static int getMaximum(int[] elements) {
int max = 0;
for (int element : elements) {
if (element > max) {
max = element;
}
}
return max;
}
private int getNumberOfDigits(int number) {
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
private void sortByDigit(int[] elements, int digitIndex) {
Bucket[] buckets = partition(elements, digitIndex);
collect(buckets, elements);
}
private Bucket[] partition(int[] elements, int digitIndex) {
Bucket[] buckets = createBuckets();
distributeToBuckets(elements, digitIndex, buckets);
return buckets;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
private void distributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets) {
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
private int calculateDivisor(int digitIndex) {
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}
private void collect(Bucket[] buckets, int[] elements) {
int targetIndex = 0;
for (Bucket bucket : buckets) {
for (int element : bucket.getElements()) {
elements[targetIndex] = element;
targetIndex++;
}
}
}
private static class Bucket {
private final List<Integer> elements = new ArrayList<>();
private void add(int element) {
elements.add(element);
}
private List<Integer> getElements() {
return elements;
}
}
}Code-Sprache: Java (java)Die RadixSortWithDynamicLists-Klasse im GitHub-Repository unterscheidet sich übrigens leicht von dem hier abgedruckten Quellcode:
- Sie implementiert das Interface SortAlgorithm, das es ermöglicht verschiedene Radix-Sort-Implementierungen miteinander und mit den anderen Algorithmen der Sortieralgorithmen-Serie zu vergleichen.
- Die
getMaximum()-Methode ist in die Klasse ArrayUtils ausgelagert. - Die Methoden
getNumberOfDigits()undcalculateDivisor()liegen in der Klasse RadixSortHelper und können so auch in anderen Radix-Sort-Implementierungen verwendet werden.
Die gezeigte Implementierung hat ein Manko:
Dynamische Listen (also Listen, deren Größe sich zur Laufzeit ändern kann) sind für leistungskritische Einsatzzwecke wie Sortieralgorithmen nicht optimal, da das Hinzufügen von Elementen mit einem gewissen Performance-Overhead verbunden ist (bei einer verketteten Liste beispielsweise müssen neue Knoten angelegt werden; bei einer ArrayList muss das Array in bestimmten Abständen in ein größeres umkopiert werden).
Im nächsten Abschnitt zeige ich dir daher eine alternativen Variante.
Variante 2: Radix Sort mit Arrays
Wir können die Implementierung deutlich beschleunigen (wir werden die Performance der Implementierungen im Anschluss vergleichen), indem wir für die Buckets statt einer ArrayList ein Array verwenden.
Da Arrays eine feste Größe haben, müssen wir vor der Erstellung eines Buckets wissen, wie viele Elemente der Bucket enthalten soll. Wir ändern unsere Bucket-Klasse wie folgt ab und übergeben die Größe an dessen Konstruktor:
private static class Bucket {
private final int[] elements;
private int addIndex;
private Bucket(int size) {
elements = new int[size];
}
private void add(int element) {
elements[addIndex] = element;
addIndex++;
}
private int[] getElements() {
return elements;
}
}Code-Sprache: Java (java)Um zu bestimmen, wie viele Elemente ein Bucket enthalten soll, zählen wir vorab die Ziffern an der aktuell betrachteten Stelle digitIndex. Die partition()-Methode sieht dann so aus:
private Bucket[] partition(int[] elements, int digitIndex) {
int[] counts = countDigits(elements, digitIndex);
Bucket[] buckets = createBuckets(counts);
distributeToBuckets(elements, digitIndex, buckets);
return buckets;
}
private int[] countDigits(int[] elements, int digitIndex) {
int[] counts = new int[10];
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
counts[digit]++;
}
return counts;
}
private Bucket[] createBuckets(int[] counts) {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket(counts[i]);
}
return buckets;
}Code-Sprache: Java (java)Die distributeToBuckets()-Methode brauchen wir nicht zu ändern, ebensowenig alle anderen in Variante 1 gezeigten Methoden. Gut, dass wir in Variante 1 eine Bucket-Klasse verwendet haben und nicht direkt eine ArrayList :-)
Den vollständigen Code von Variante 2 findest du im GitHub-Repository in der Klasse RadixSortWithArrays.
Kommen wir zu einer dritten Variante.
Variante 3: Radix Sort mit Counting Sort
In Variante 2 haben wir vorab gezählt, wie viele Elemente in jeden Bucket sortiert werden müssen. Mit dieser Information können wir die Buckets auch überspringen und die Elemente direkt an ihre Zielpositionen verschieben. Und zwar indem wir die allgemein Form von Counting Sort anwenden.
Wie Counting Sort funktioniert, werde ich an dieser Stelle nicht noch einmal wiederholen. Ich zeige dir direkt die Implementierung:
public class RadixSortWithCountingSort {
@Override
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
// Remember input array
int[] inputArray = elements;
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
elements = sortByDigit(elements, digitIndex);
}
// Copy sorted elements back to input array
System.arraycopy(elements, 0, inputArray, 0, elements.length);
}
// Same as in the other variants:
// getMaximum(), getNumberOfDigits(), calculateDivisor()
private int[] sortByDigit(int[] elements, int digitIndex) {
int[] counts = countDigits(elements, digitIndex);
int[] prefixSums = calculatePrefixSums(counts);
return collectElements(elements, digitIndex, prefixSums);
}
private int[] countDigits(int[] elements, int digitIndex) {
int[] counts = new int[10];
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
counts[digit]++;
}
return counts;
}
private int[] calculatePrefixSums(int[] counts) {
int[] prefixSums = new int[10];
prefixSums[0] = counts[0];
for (int i = 1; i < 10; i++) {
prefixSums[i] = prefixSums[i - 1] + counts[i];
}
return prefixSums;
}
private int[] collectElements(int[] elements, int digitIndex, int[] prefixSums) {
int divisor = calculateDivisor(digitIndex);
int[] target = new int[elements.length];
for (int i = elements.length - 1; i >= 0; i--) {
int element = elements[i];
int digit = element / divisor % 10;
target[--prefixSums[digit]] = element;
}
return target;
}
}Code-Sprache: Java (java)Diesen Code findest du ebenfalls im GitHub-Repository, in der Klasse RadixSortWithCountingSort.
Radix Sort Varianten
Es gibt zwei grundlegende Varianten von Radix Sort, die sich durch die Reihenfolge unterscheiden, in der wir die Ziffern der Elemente betrachten.
LSD Radix Sort
Der im ersten Kapitel gezeigte Radix-Sort-Algorithmus nennt sich „LSD Radix Sort“. LSD steht dabei für „least significant digit“, also „niedrigstwertige Stelle“. Wir haben mit dem Sortieren bei der niedrigstwertigen Stelle (den Einern) begonnen und uns Ziffer für Ziffer bis zur höchstwertigen Stelle vorgearbeitet.
MSD Radix Sort
Alternativ können wir auch bei der höchstwertigen Stelle, „most significant digit“ beginnen. Entsprechend heißt die zweite Variante „MSD Radix Sort“.
Dabei müssen wir allerdings anders vorgehen als bei der LSD-Variante. Denn wenn wir in unserem Ausgangsbeispiel die gesamte Eingabeliste zunächst nach Hundertern, dann nach Zehnern und zuletzt nach der Einerstelle sortieren würden, würde folgendes passieren (die Buckets habe ich in der Grafik weggelassen, da es nur um die Ergebnisse nach den drei Collect-Phasen geht):

Die Sortierung nach der Zehner- und Einerstelle hat die jeweiligen vorherigen Sortierungen wieder durcheinander gebracht.
Das Problem ist schnell gelöst:
Nach der Hunderterstelle dürfen wir die Eingabeliste nicht erneut als Ganzes sortieren, sondern die Hunderterstellen-Buckets in sich. Die daraus wiederum resultierenden Zehnerstellen-Buckets sortieren wir dann jeweils nach der Einerstelle. Wir sortieren die Buckets also rekursiv.
MSD Radix Sort – Schritt für Schritt
Die folgenden Grafiken zeigen das rekursive MSD-Radix-Sort-Verfahren Schritt für Schritt am Eingangsbeispiel. Buckets werden durch schwarze Klammern unter den Elementen dargestellt. Leere Buckets werden nicht angezeigt.
Wir beginnen mit der Partitionierung nach Hunderterstellen:

Anstatt nun von der Partitionierungs- in die Sammelphase überzugehen, führen wir auf jedem Bucket eine weitere Partitionierungsphase aus – und zwar auf der nächst niedrigeren Stelle, also den Zehnern.
Leere Buckets und solche, die nur ein Element enthalten (wie die 271 und die 836), brauchen brauchen wir nicht weiter zu partitionieren.

Eigentlich müssten wir die Buckets nun noch nach Einerstellen partitionieren. Da aber keiner der Zehnerstellen-Buckets mehr als ein Element enthält, ist das nicht notwendig.
Wir steigen daher aus der Rekursion wieder aus. Zunächst führen wir eine Sammelphase auf den Zehnerstellen-Buckets aus:

Und zuletzt führen wir die Sammelphase auf den Hunderterstellen-Buckets aus:

Die Sortierung ist damit abgeschlossen.
MSD Radix Sort – Implementierung
Genau wie die LSD-Variante kann auch MSD Radix Sort mit Dynamischen Listen, Arrays und mit Counting Sort implementiert werden.
Ich zeige dir, wie du die oben gezeigte LSD-Array-Implementierung mit wenigen Änderungen in eine MSD-Implementierung ändern kannst.
Hier sind noch einmal die Methoden sort() und sortByDigit() der Klasse RadixSortWithArrays:
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
for (int digitIndex = 0; digitIndex < numberOfDigits; digitIndex++) {
sortByDigit(elements, digitIndex);
}
}
private void sortByDigit(int[] elements, int digitIndex) {
Bucket[] buckets = partition(elements, digitIndex);
collect(buckets, elements);
}
Code-Sprache: Java (java)Alles was wir nun tun müssen, ist die sortByDigit()-Methode für die höchstwertige Stelle aufzurufen und zwischen Partitionierungs- und Sammelphase den rekursiven Aufruf für die nächstniedrigere Stelle einzufügen:
public void sort(int[] elements) {
int max = getMaximum(elements);
int numberOfDigits = getNumberOfDigits(max);
sortByDigit(elements, numberOfDigits - 1);
}
private void sortByDigit(int[] elements, int digitIndex) {
Bucket[] buckets = partition(elements, digitIndex);
// If we haven't reached the last digit,
// sort the buckets by the next digit, recursively
if (digitIndex > 0) {
for (Bucket bucket : buckets) {
if (bucket.needsToBeSorted()) {
sortByDigit(bucket.getElements(), digitIndex - 1);
}
}
}
collect(buckets, elements);
}Code-Sprache: Java (java)Die Methode Bucket.needsToBeSorted() gibt true zurück, wenn der Bucket wenigstens ein Element enthält.
Den vollständigen Code findest du im GitHub-Repository in der Klasse RecursiveMsdRadixSortWithArrays.
Ich überlasse es dir als Übungsaufgabe auch für die zwei anderen LSD-Implementierungen (dynamische Listen und Counting Sort) je eine MSD-Variante zu schreiben.
Verwendung anderer Basen
Bisher haben wir die Partitionierung nach dem Dezimalsystem, also mit 10 Buckets, durchgeführt. Wir können aber auch mit jeder anderen Basis arbeiten, also beispielsweise mit dem Binärsystem (2 Buckets), dem Hexadezimalsystem (16 Buckets) oder auch mit hundert, tausend oder mehr Buckets.
Je höher die Basis, desto mehr Buckets, desto aufwändiger die Partitionierungsphase. Andererseits haben die zu sortierenden Zahlen dann weniger Stellen (1.000.000 dezimal = F4240 hexadezimal), so dass insgesamt weniger Partitionierungs- und Sammelphasen stattfinden müssen. Was das für die Performance bedeutet, werden wir im Kapitel „Radix Sort Laufzeit“ ermitteln.
Wie implementiert man Radix Sort mit einer anderen Basis?
Im Grunde genommen müssen wir jedes Vorkommen der Zahl 10 im Quellcode durch die neue Basis ersetzen. In der Klasse RadixSortWithDynamicLists kommt die 10 in den folgenden Methoden vor:
private int getNumberOfDigits(int number) {
int numberOfDigits = 1;
while (number >= 10) {
number /= 10;
numberOfDigits++;
}
return numberOfDigits;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
private void distributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets) {
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % 10;
buckets[digit].add(element);
}
}
private int calculateDivisor(int digitIndex) {
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= 10;
}
return divisor;
}Code-Sprache: Java (java)Wir können die 10 an all diesen Stellen durch eine andere Basis ersetzen. Besser noch: Wir ersetzen sie durch eine Variable, so dass wir den Sortieralgorithmus mit jeder beliebigen Basis aufrufen können.
In der Klasse RadixSortWithDynamicListsAndCustomBase findest du die entsprechende Anpassung:
public class RadixSortWithDynamicListsAndCustomBase implements SortAlgorithm {
private final int base;
public RadixSortWithDynamicListsAndCustomBase(int base) {
this.base = base;
}
// All methods not printed here are the same as in RadixSortWithDynamicLists
private int getNumberOfDigits(int number) {
int numberOfDigits = 1;
while (number >= base) {
number /= base;
numberOfDigits++;
}
return numberOfDigits;
}
private Bucket[] createBuckets() {
Bucket[] buckets = new Bucket[base];
for (int i = 0; i < base; i++) {
buckets[i] = new Bucket();
}
return buckets;
}
private void distributeToBuckets(int[] elements, int digitIndex, Bucket[] buckets) {
int divisor = calculateDivisor(digitIndex);
for (int element : elements) {
int digit = element / divisor % base;
buckets[digit].add(element);
}
}
private int calculateDivisor(int digitIndex) {
int divisor = 1;
for (int i = 0; i < digitIndex; i++) {
divisor *= base;
}
return divisor;
}
}Code-Sprache: Java (java)Beachte bitte, dass im GitHub-Repository die Methoden getNumberOfDigits() und calculateDivisor() in die Klasse RadixSortHelper ausgelagert sind, da sie auch von anderen Radix-Sort-Implementierungen benötigt werden.
Im GitHub-Repository findest du außerdem die angepassten Algorithmen für Arrays, Counting Sort und rekursives MSD Radix Sort:
- Dynamische Listen + variable Basis: RadixSortWithDynamicListsAndCustomBase
- Arrays + variable Basis: RadixSortWithArraysAndCustomBase
- Counting Sort + variable Basis: RadixSortWithCountingSortAndCustomBase
- Rekursives MSD Radix Sort + variable Basis: RecursiveMsdRadixSortWithArraysAndCustomBase
Radix Sort Zeitkomplexität
In diesem Kapitel zeige ich dir, wie du die Zeitkomplexität von Radix Sort bestimmst. Eine Einführung in das Thema Zeitkomplexität findest du im Artikel „Zeitkomplexität“ und „O-Notation„.
Wir verwenden im Folgenden die folgenden Variablen:
- n = die Anzahl der zu sortierenden Elemente
- k = die maximale Schlüssellänge („key length“, Anzahl der Stellen) der zu sortierenden Elemente
- b = die Basis (= die Anzahl der Buckets)
Der Algorithmus iteriert über k Stellen; für jede Stelle betreibt er den folgenden Aufwand:
- Er legt b Buckets an. Der Aufwand dafür ist jeweils konstant.
- Er iteriert über alle n Elemente, um diese in die Buckets einzusortieren. Der Aufwand für die Berechnung der Bucket-Nummer und für das Einfügen in den Bucket ist konstant.
- Er iteriert über b Buckets und entnimmt diesen wieder insgesamt n Elemente. Der Aufwand für jeden dieser Schritte ist wiederum konstant.
Konstante Aufwände vernachlässigen wir bei der Bestimmung der Zeitkomplexität. Somit ergibt sich:
Die Zeitkomplexität für Radix Sort ist: O(k · (b + n))
Der Aufwand ist unabhängig davon, wie die Eingabezahlen angeordnet sind. Ob diese zufällig verteilt oder bereits vorsortiert sind, macht keinen Unterschied für den Algorithmus. Best case, average case und worst case sind also identisch.
Die Formel sieht erstmal kompliziert aus. Doch zwei der drei Variablen sind in den meisten Fällen gar nicht variabel. Wenn wir z. B. Longs mit der Basis 10 sortieren, können wir k durch 19 ersetzen (der maximal mögliche Wert für ein Long ist 9.223.372.036.854.775.807) und b durch 10.
Die Formel wird dann zu O(19 · (10 + n)). Konstanten können wir weglassen, somit ergibt sich:
Die Zeitkomplexität für Radix Sort
bei bekannter maximaler Länge der zu sortierenden Elemente
und mit festgelegter Basis ist: O(n)
Radix Sort hat also für primitive Datentypen wie Integer und Long (bei diesen kennen wir die maximale Länge) eine bessere Zeitkomplexität als Quicksort!
Ob Radix Sort tatsächlich schneller ist, erfährst du im nächsten Kapitel. Dort werden wir die Laufzeit der verschiedenen Radix-Sort-Implementierungen messen und untereinander (und auch mit Quicksort) vergleichen.
Radix Sort Laufzeit
In diesem Kapitel zeige ich dir die Ergebnisse einiger Performance-Tests, die ich mit den Tools UltimateTest und CompareRadixSorts durchgeführt habe, um die Performance der verschiedenen Algorithmen, Implementierungen und Basen zu vergleichen.
Laufzeit verschiedener Radix-Sort-Implementierungen
Das erste Diagramm zeigt den Vergleich der verschiedenen Implementierungen:

Die Implementierung mit dynamischen Listen schneidet, wie vermutet, am schlechtesten ab. Die restlichen drei Varianten liefern sich ein Kopf-an-Kopf-Rennen, das die Implementierung mit Counting Sort knapp gewinnt, dicht gefolgt von der Implementierung mit Arrays.
Sehr schön zu sehen ist auch die jeweils lineare Laufzeit O(n), die wir im vorangegangenen Kapitel vorhergesagt hatten.
Auswirkung der Basis auf die Laufzeit
Das zweite Diagramm zeigt, wie sich die Wahl der Basis auf die Laufzeit der Array-Implementierung auswirkt:

Wir können sehen, dass die Laufzeit bei einer Basis von 100 und 1.000 deutlich besser ist als bei kleineren als auch größeren Basen.
Untersuchen wir das etwas detaillierter… Das dritte Diagramm zeigt feinere Abstufungen der Basen bei gleicher Anzahl Elemente (n = 5,555,555):

Sowohl eine zu kleine als auch eine zu große Basis sind schlecht für die Performance.
Eine sehr kleine Basis führt dazu, dass viele Iterationen durchgeführt werden müssen. Eine zu große Basis führt zwar zu weniger Iterationen, aber deutlich mehr Buckets innerhalb der Iterationen.
Ein Sweetspot zeigt sich bei einer Basis von 256.
Radix Sort vs. Quicksort
In folgendem Diagramm siehst du die Laufzeiten…
- der Radix-Sort-Array-Implementierung mit einer Basis von 256,
- von Dual-Pivot Quicksort kombiniert mit Insertion Sort (die schnellste Variante, die wir im Quicksort-Tutorial ermittelt haben)
- und der JDK-Sortiermethode
Arrays.sort(), welche ebenfalls ein optimiertes Dual-Pivot Quicksort implementiert.

Und tatsächlich ist Radix Sort nicht nur in der Theorie schneller – O(n) vs. O(n log n) – sondern auch in der Praxis – und zwar sowohl im Vergleich mit dem selbst implementierten Quicksort als auch mit der noch schnelleren JDK-Quicksort-Implementierung Arrays.sort().
Wenn du also int-Primitive sortieren musst und die Performance kritisch ist, solltest du erwägen statt des Java-Hausmittels Arrays.sort() besser Radix-Sort einzusetzen. Du kannst gerne die Implementierung aus diesem Artikel verwenden.
Für long-Primitive gilt das nicht, hier ist Arrays.sort() etwa 50% schneller als meine Radix-Sort-Implementierung.
Weitere Eigenschaften von Radix Sort
In diesem abschließenden Kapitel betrachten wir die Platzkomplexität, Stabilität und Parallelisierbarkeit von Radix Sort, sowie die Unterschiede zu Counting Sort und Bucket Sort.
Radix Sort Platzkomplexität
Alle hier gezeigten Varianten benötigen zusätzlichen Speicherplatz:
- O(b) für das Zählen der Ziffern (nicht benötigt in der Variante mit dynamischen Listen)
- O(b) für die Referenzen auf die Buckets (nicht benötigt bei der Counting-Sort-Variante)
- O(n) für die Buckets (nicht benötigt bei der Counting-Sort-Variante)
- O(n) für ein zusätzliches Ziel-Array (nur bei der Counting-Sort-Variante)
Jede Variante enthält also mindestens einen O(b)-Anteil und mindestens einen O(n)-Anteil.
Somit gilt:
Die Platzkomplexität von Radix Sort ist: O(b + n)
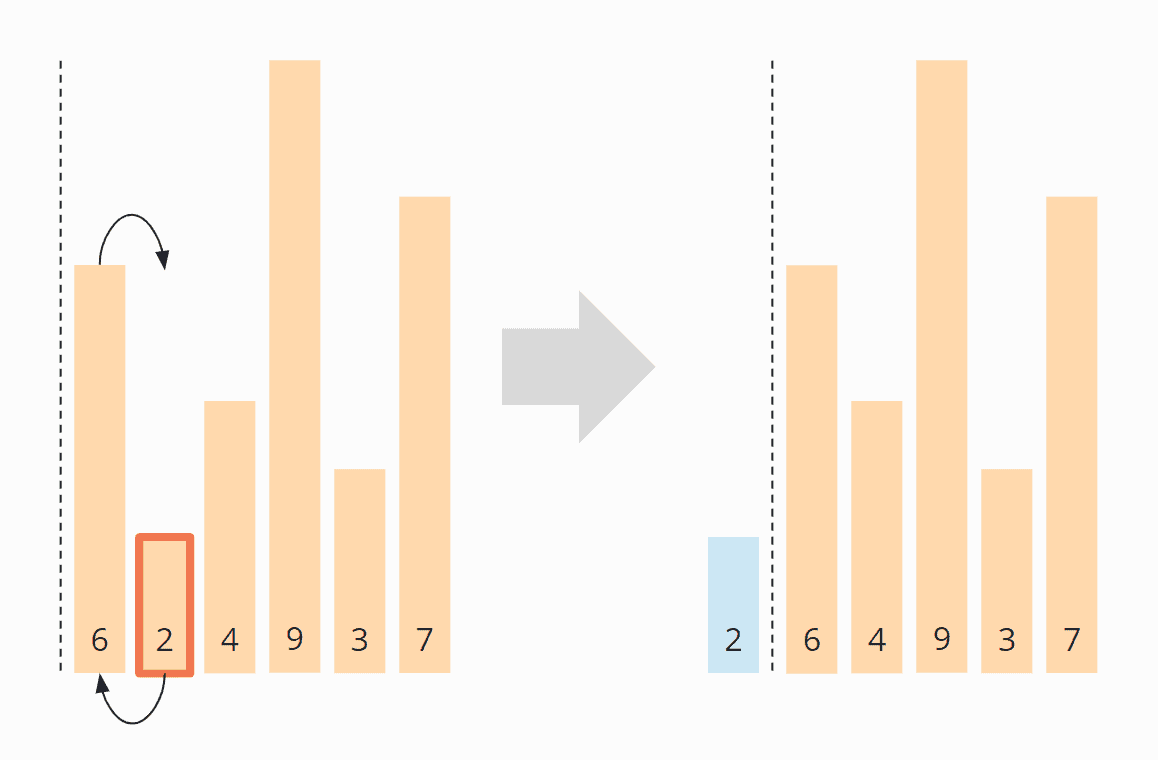
Es gibt eine Ausnahme: Rekursives MSD Radix Sort mit der Basis 2 kann ohne zusätzlichen Speicher für die Elemente auskommen, indem diese derart partitioniert werden, dass durch jeweiligen Austausch zweier Elemente alle Elemente, deren Bit an der gerade betrachteten Stelle auf 1 steht, an den rechten Rand geschoben werden und alle Elemente, deren Bit auf 0 steht, an den linken Rand (ähnlich wie bei Quicksort).
Ist Radix Sort stabil?
Die Bedeutung von Stabilität bei Sortierverfahren kannst du im verlinkten Einführungsartikel nachlesen. Kurz gesagt: Elemente mit dem gleichen Schlüssel behalten bei der Sortierung ihre ursprüngliche Reihenfolge zueinander bei.
Alle in diesem Artikel gezeigten Implementierungen von Radix Sort sind stabil.
Die im vorherigen Abschnitt angesprochene In-Place-MSD-Radix-Sort-Variante ist hingegen nicht stabil (analog zu Quicksort).
Paralleles Radix Sort
Beide Radix-Sort-Varianten (LSD und MSD) lassen sich parallelisieren.
MSD Radix Sort parallel
Bei MSD Radix Sort können wir nach der ersten Partitionierungsphase alle entstandenen Buckets unabhängig voneinander parallel sortieren. Dank paralleler Streams lässt sich das in Java sehr einfach implementieren:
Hier noch einmal der entsprechende sequentielle Code aus der Klasse RecursiveMsdRadixSortWithArrays:
for (Bucket bucket : buckets) {
if (bucket.needsToBeSorted()) {
sortByDigit(bucket.getElements(), digitIndex - 1);
}
}Code-Sprache: Java (java)Und hier die parallelisierte Variante (Klasse ParallelRecursiveMsdRadixSortWithArrays im GitHub-Repository):
Arrays.stream(buckets)
.parallel()
.forEach(
bucket -> {
if (bucket.needsToBeSorted()) {
sortByDigit(bucket.getElements(), digitIndex - 1);
}
});Code-Sprache: Java (java)LSD Radix Sort parallel
Um LSD Radix Sort zu parallelisieren, müssen wir etwas mehr Aufwand betreiben:
- Wir teilen das Eingabe-Array in parallel zu bearbeitende Segmente auf (z. B. entsprechend der Anzahl der CPU-Kerne).
- Wir berechnen parallel pro Segment, wie viele Elemente in welche Buckets sortiert werden müssen.
- Wenn Schritt 2 für alle Segmente abgeschlossen ist, berechnen wir a) pro Bucket die Gesamtanzahl der Elemente und b) pro Segment die Start-Schreibpositionen für jeden Bucket.
- Wir verteilen die Elemente der Segmente parallel auf die Buckets. Durch die in Schritt 3 berechneten Start-Schreibpositionen wissen wir, an welchen Positionen innerhalb der Buckets wir aus welchen Segmenten schreiben dürfen.
- Wenn Schritt 4 für alle Segmente abgeschlossen ist, berechnen wir pro Bucket den Offset im Zielarray (als Präfixsummen über die Anzahl der Elemente der Buckets).
- Wir sammeln die Elemente der Buckets parallel ein. Durch die in Schritt 5 berechneten Offsets wissen wir, an welcher Position im Zielarray die Elemente eines Buckets starten müssen.
Den Quellcode findest du in der Klasse ParallelRadixSortWithArrays im GitHub-Repo. Die sechs oben aufgezählten Schritte sind im Code mit entsprechend nummerierten Kommentaren markiert.
Radix Sort parallel vs. sequentiell
Das folgende Diagramm zeigt die Laufzeit der parallelen Varianten verglichen mit den sequentiellen Varianten auf einer 6-Kern-i7-CPU:

Die parallelen Varianten sind bei 67 Millionen Elementen nur etwa 2,3 mal schneller. Dass Faktor 6 nicht einmal annähernd erreicht wird, liegt zum einen daran, dass Teile des Codes nicht parallel ausgeführt werden können und zum anderen daran, dass die CPU-Kerne sehr viele Daten mit dem Arbeitsspeicher austauschen müssen (das Eingabearray belegt 1 GB).
Wenn wir uns einen kleineren Ausschnitt des Diagramms anschauen, sieht die Sache anders aus:

Bei einer halben Million Elemente ist das parallele Radix Sort mit Arrays 5,75 mal schneller als die sequentielle Variante. Die CPU-Kerne werden also nahezu komplett ausgenutzt. Das liegt daran, dass das Eingabearray nur noch 2 MB groß ist, und die Sortierung somit komplett im L3-Cache der CPU stattfinden kann.
Radix Sort vs. Counting Sort
Beide Sortierverfahren verwenden Buckets zum Sortieren. Bei Counting Sort benötigen wir einen Bucket für jeden Wert. Wollten wir beispielsweise Integers sortieren, bräuchten wir etwa vier Milliarden Buckets. Bei Radix Sort hingegen entspricht die Anzahl der Buckets der gewählten Basis.
Bei Radix Sort sortieren wir iterativ Ziffer für Ziffer; bei Counting Sort sortieren wir die Elemente in einer einzigen Iteration.
Counting Sort eignet sich daher in erster Linie für kleine Zahlenräume.
Radix Sort vs. Bucket Sort
Bei Bucket Sort werden die Elemente zunächst so auf eine vorgegebene Anzahl Buckets verteilt, dass alle Elemente eines Buckets größer sind als alle Elemente des vorherigen Buckets (z. B. 0-99, 100-199, 200-299, usw.).
Danach wird jeder Bucket in sich sortiert – entweder rekursiv mit Bucket Sort oder mit einem anderen Sortierverfahren – mit welchem genau ist nicht spezifiziert. Abschließend werden die Elemente aus den sortierten Buckets aneinandergereiht.
Falls dir das bekannt vorkommt – eine Form von Bucket Sort hast du in diesem Artikel kennengelernt: das rekursive MSD Radix Sort.
Zusammenfassung
Radix Sort ist ein stabiler Sortieralgorithmus mit einer allgemeinen Zeitkomplexität von O(k · (b + n)), wobei k für die maximale Schlüssellänge („key length“) der zu sortierenden Elemente steht und b für die Basis.
Ist die maximale Länge der zu sortierenden Elemente bekannt und die Basis festgelegt, dann beträgt die Zeitkomplexität O(n).
Für Integers ist Radix Sort schneller als Quicksort (zumindest auf meiner Testumgebung). Solltest du zeitkritische Sortiervorgänge in Java implementieren müssen, empfehle ich dir Arrays.sort() mit einer Implementierung von Radix Sort zu vergleichen.
Weitere Sortieralgorithmen findest du in der Übersicht aller Sortieralgorithmen und ihrer Eigenschaften im ersten Teil der Artikelserie.
























































































































































![Sortieren in Java [Tutorial]](https://janice.happycoders.eu/wp-content/uploads/2020/06/sorting-in-java-feature-image.jpg)
![Sortieralgorithmen [Ultimate Guide]](https://janice.happycoders.eu/wp-content/uploads/2020/06/sorting-algorithms-java-feature-image.jpg)

