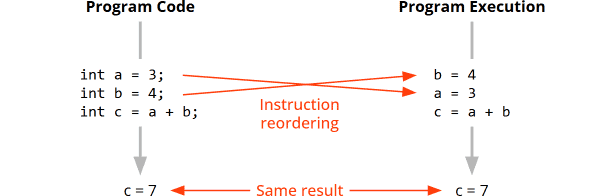
Java 26 has been in the so-called “Rampdown Phase One” since December 4, 2025, meaning no further JDK Enhancement Proposals (JEPs) will be included in the release. The feature set has therefore been finalized. Only bugs will be fixed and minor improvements made where necessary.
The target release date is March 17, 2026. You can download the current Early Access version here.
With 10 delivered JDK Enhancement Proposals (JEPs), Java 26 is one of the more manageable releases of recent years. Half of the JEPs are minor to medium-sized changes – such as warnings for mutating final fields and HTTP/3 support.
The other half are re-proposed previews – i.e., updates to features that have already been introduced but not yet finalized. Except for Lazy Constants (previously known as Stable Values), there were only minimal changes here.
For all JEPs and changes from the release notes, I use the original English terms as always.
Prepare to Make Final Mean Final – JEP 500
Most developers assume that a field we mark as final is immutable. In fact, we cannot simply assign a new value to a final field using an equals sign. However, so-called Deep Reflection allows us to bypass this restriction.
Here is a small example class to which we pass a value in the constructor, which is then stored in the final field value:
public class Box {
private final Object value;
public Box(Object value) {
this.value = value;
}
@Override
public String toString() {
return "Box{value=" + value + "}";
}
}Code language: Java (java)The following code shows how easily the content of the final field can be changed – even from outside the object:
Box box = new Box("Rubic's Cube");
IO.println("box = " + box);
Field valueField = Box.class.getDeclaredField("value");
valueField.setAccessible(true);
valueField.set(box, "Magic Wand");
IO.println("box = " + box);Code language: Java (java)Here we bypass both the encapsulation of the field via private and immutability via final. And this code can be executed from anywhere, for example, by third-party libraries that we don’t even know are on the classpath.
This problem was recognized years ago, and therefore, with Hidden Classes in Java 15 and Records in Java 16, Deep Reflection was not allowed from the outset.
In Java 16, “Strong Encapsulation” for JDK internals was also introduced. Since then, we have had to explicitly allow Deep Reflection across module boundaries with --add-opens. However, this only works for custom applications if they also use the module system.
To make Java more secure, the modification of final fields via Deep Reflection will be fundamentally prohibited in the future – even within a module.
Warnings in Java 26
In Java 26, JDK Enhancement Proposal 500 introduces warnings as a first step. The code shown above runs without issues in Java 25; in Java 26, it now displays the following warning:
WARNING: Final field value in class eu.happycoders.java26.jep500.Box has been mutated reflectively by class eu.happycoders.java26.jep500.FinalTest in unnamed module @3f99bd52
WARNING: Use --enable-final-field-mutation=ALL-UNNAMED to avoid a warning
WARNING: Mutating final fields will be blocked in a future release unless final field mutation is enabledCode language: plaintext (plaintext)The use of Deep Reflection can be explicitly allowed for specific modules via --enable-final-field-mutation=<Modulname> – thus preventing the warning.
In a future Java version, Deep Reflection will be forbidden by default – instead of a warning, an exception will be thrown, unless Deep Reflection is explicitly allowed via --enable-final-field-mutation.
The future behavior can already be enabled using the VM option --illegal-final-field-mutation. The option offers the following possibilities:
--illegal-final-field-mutation=allow | Final fields can be modified without warning (default behavior before Java 26). |
--illegal-final-field-mutation=warn | A warning appears when a final field is first modified (default behavior from Java 26). |
--illegal-final-field-mutation=debug | A warning appears every time a final field is modified. |
--illegal-final-field-mutation=deny | Final fields must not be changed – attempting to do so leads to an IllegalAccessException. |
In a future Java version, deny will become the default setting, and allow will no longer be allowed. Then, Deep Reflection must be activated at the module level via --enable-final-field-mutation.
The guarantee that final fields are truly final not only protects against unexpected behavior but also improves application performance: If the JVM knows that a field cannot be changed, it can optimize access to it via Constant Folding – a type of inlining for constants.
Ahead-of-Time Object Caching with Any GC – JEP 516
In Java 24, Ahead-of-Time Class Loading & Linking was introduced – the ability to store the classes required by an application in an architecture-specific binary format in a so-called Ahead-of-Time cache – and to load them from there to significantly accelerate application startup (by up to 42% in tests).
Previously, classes were stored in the cache exactly as the Garbage Collector places them on the heap, including headers and references to other objects (e.g., from Class objects to strings). This has the advantage that the Ahead-of-Time cache file can be mapped directly from the file system to the heap – and this happens with virtually no time loss if the Ahead-of-Time cache file is in the file system cache.
However, the binary representation of both object headers and references can differ from Garbage Collector to Garbage Collector or depending on VM options:
- With Compressed OOPs (default for heaps up to 32 GB), references are 32 bits long.
- Without Compressed OOPs (with a heap larger than 32 GB or with the VM option
-XX:-UseCompressedOOPs), they are 64 bits long. - ZGC uses some bits of the references for metadata.
- By activating Compact Object Headers (
-XX:+UseCompactObjectHeaders) or deactivating Compressed Class Pointers (deprecated since Java 25), the binary format of the header changes.
Therefore, an Ahead-of-Time cache created with G1, Serial GC, or Parallel GC could not previously be read by applications using ZGC – and vice versa. Similarly, a cache created with Compressed OOPs or Compact Object Headers enabled could not be read by an application where Compressed OOPs or Compact Object Headers were disabled – and vice versa.
GC-Independent Ahead-of-Time Cache
To use the Ahead-of-Time cache more flexibly, starting with Java 26, we can create a GC-independent Ahead-of-Time cache. In this approach, objects in the cache file are referenced by their index within the cache. The cache file can no longer be directly mapped to the heap. Instead, objects are gradually read from the file and then stored on the heap in the GC-specific format and correctly linked there – or, in other words: they are streamed from the cache file to the heap.
The GC-independent format (also called “Streamable Objects”) is used if, during the training run…
- ZGC was used – or
- Compressed OOPs were deactivated with
-XX:-CompressedOops– or - the heap was larger than 32 GB – or
- the VM option
-XX:+AOTStreamableObjectswas specified.
If, on the other hand, an application was started with G1, Serial GC, or Parallel GC and a heap of a maximum of 32 GB, the previous, GC-specific format is used.
HTTP/3 for the HTTP Client API – JEP 517
The next feature is already fully explained by the heading: The HttpClient API supports version 3 of the HTTP protocol (introduced in 2022) starting with Java 26.
With the HttpClient API, you could, for example, load the content of my homepage and store it in a string as follows:
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.janice.happycoders.eu/"))
.build();
HttpResponse<String> response =
client.send(request, BodyHandlers.ofString());
String responseBody = response.body();Code language: Java (java)By default, HTTP/2 was used here – and that doesn’t change with Java 26, as only about one-third of all websites currently support HTTP/3.
However, you can now explicitly enable HTTP/3 as follows:
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.janice.happycoders.eu/"))
.version(HttpClient.Version.HTTP_3) // ← Try to use HTTP/3
.build();Code language: Java (java)Thus, an attempt is made to communicate with the server via HTTP/3. If the server does not support HTTP/3, it will transparently switch to HTTP/2.
G1 GC: Improve Throughput by Reducing Synchronization – JEP 522
G1 is the default Garbage Collector of the JVM – it offers a balanced ratio of high throughput and low latencies (in contrast, Serial GC and Parallel GC are designed for the highest possible throughput, and ZGC and Shenandoah for the lowest possible latencies).
When the Garbage Collector moves an object, it must also adjust all references to that object. Scanning the entire heap for this would be very inefficient. Therefore, G1 only scans objects
How does G1 know that the application code has set a reference from one object to another, which also needs to be stored in the Card Table? Through so-called Write Barriers: short pieces of machine code that G1 weaves into the code when an application starts.
To ensure that scanning the Card Table after moving an object is as fast as possible, G1 continuously optimizes the Card Table in the background. Since G1 runs in parallel with the application, access to the Card Table by application threads via Write Barriers and access by the optimization thread must be synchronized. This, in turn, represents a significant overhead.
Reducing Synchronization Overhead in Java 26
Therefore, G1 is optimized in Java 26 as follows:
A second Card Table is introduced. While the application threads access one of these two Card Tables, the optimization thread optimizes the other. As soon as a Card Table has been modified so heavily by the application threads that the time required to scan it exceeds a certain limit, the Card Tables are swapped. The application thread then accesses the previously optimized Card Table, while the optimization thread re-optimizes the Card Table that has become cumbersome.
The optimization thread therefore does not need to be synchronized with the concurrently running application. The reduced synchronization overhead can lead to an increase in overall throughput of 5 to 15%. The costs for this are minimal: a Card Table occupies 0.2% of the heap – accordingly, with a constant heap size, only 0.2% more native memory is required.
This optimization takes effect after an upgrade to Java 26 without any code changes or VM parameter adjustments.
Re-proposed Preview and Incubator Features
None of the five features that were in preview or incubator status in Java 25 were finalized in Java 26. All five features were re-proposed with minor or major changes. The following sections describe the features with a focus on the changes compared to Java 25.
PEM Encodings of Cryptographic Objects (Second Preview) – JEP 524
PEM stands for Privacy-Enhanced Mail and represents an encoding scheme for cryptographic objects. You have certainly seen PEM-encoded objects before – such as the following PEM-encoded cryptographic certificate:
-----BEGIN CERTIFICATE-----
MIIDtzCCAz2gAwIBAgISBUCeYELtjMmr4FAIqHapebbFMAoGCCqGSM49BAMDMDIx
CzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQDEwJF
. . .
DBeMde1YpWNXpF9+B/OMKgn7RgXRj5b2QpBCnFsP92T4cK/Nn+xFIjYCMCCx4E79
toSQBlYnNHv0eXnWkI8TmXsU/A6rU4Gxdr9GbGixgRJvkw0C6zjL/lH2Vg==
-----END CERTIFICATE-----Code language: plaintext (plaintext)Writing or reading PEM-encoded objects in Java was previously extremely complicated and required over a dozen lines of code. The following example shows what you had to write to read a PEM-encoded private key in Java:
String encryptedPrivateKeyPemEncoded = . . .
String passphrase = . . .
String encryptedPrivateKeyBase64Encoded = encryptedPrivateKeyPemEncoded
.replace("-----BEGIN ENCRYPTED PRIVATE KEY-----", "")
.replace("-----END ENCRYPTED PRIVATE KEY-----", "")
.replaceAll("[\\r\\n]", "");
Base64.Decoder decoder = Base64.getDecoder();
byte[] encryptedPrivateKeyBytes = decoder.decode(encryptedPrivateKeyBase64Encoded);
EncryptedPrivateKeyInfo encryptedPrivateKeyInfo =
new EncryptedPrivateKeyInfo(encryptedPrivateKeyBytes);
String algorithmName = encryptedPrivateKeyInfo.getAlgName();
SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithmName);
PBEKeySpec pbeKeySpec = new PBEKeySpec(passphrase.toCharArray());
Key pbeKey = secretKeyFactory.generateSecret(pbeKeySpec);
Cipher cipher = Cipher.getInstance(algorithmName);
AlgorithmParameters algParams = encryptedPrivateKeyInfo.getAlgParameters();
cipher.init(Cipher.DECRYPT_MODE, pbeKey, algParams);
KeyFactory rsaKeyFactory = KeyFactory.getInstance("RSA");
KeySpec keySpec = encryptedPrivateKeyInfo.getKeySpec(cipher);
PrivateKey privateKey = rsaKeyFactory.generatePrivate(keySpec);Code language: Java (java)In Java 25, a dedicated PEM API was introduced as a preview feature, intended to significantly simplify handling PEM-encoded objects. Reading the encrypted private key is thus possible with just a few lines of code (or just one, if you write everything on a single line):
PrivateKey privateKey = PEMDecoder.of()
.withDecryption(passphrase.toCharArray())
.decode(encryptedPrivateKeyPemEncoded, PrivateKey.class);Code language: Java (java)In addition to the PEMDecoder shown above, there is a corresponding PEMEncoder with a encode() method.
In Java 26, the basic functionality of this API remains the same – only a few details have been changed and the scope of functions has been slightly increased:
- Some classes and methods have been renamed, and some methods have been added (the simple example above was not affected by these changes).
- Some exceptions have been adjusted.
- In addition to the existing cryptographic objects, key pairs and PKCS#8-encoded keys can now also be encoded and decoded.
More details on the new API and these changes can be found in JDK Enhancement Proposal 524.
Structured Concurrency (Sixth Preview) – JEP 525
Structured Concurrency is already in its sixth preview round. If you are already familiar with the API and just want to know what has changed in Java 26, you can jump to the section Structured Concurrency – Changes in Java 26.
What is Structured Concurrency?
Structured Concurrency means – in contrast to Unstructured Concurrency and based on Structured Programming – that the execution paths created when starting concurrent threads converge at a single point in the code – and that it is guaranteed that no orphaned threads are still running at that point.
The following graphic illustrates this. It also shows that “scopes” (= the areas in which concurrent tasks are executed) created by Structured Concurrency can be nested:

This was previously possible – to a limited extent – with a ExecutorService and the invocation of close() or shutdown() and awaitTermination(). However, the Java API for Structured Concurrency, ExecutorService, this was only possible with extremely complex and thus error-prone orchestration.
StructuredTaskScope API
The following example shows how multiple subtasks can be started in parallel with the StructuredTaskScope API, and then the result of all subtasks is awaited. Should one of the subtasks fail, the still-running subtasks are canceled, and scope.join() throws the exception that occurred in the failed subtask.
Invoice createInvoice(int orderId, int customerId, String language)
throws InterruptedException {
try (var scope = StructuredTaskScope.open()) {
var orderTask = scope.fork(() -> orderService.getOrder(orderId));
var customerTask = scope.fork(() -> customerService.getCustomer(customerId));
var templateTask = scope.fork(() -> templateService.getTemplate(language));
scope.join();
var order = orderTask.get();
var customer = customerTask.get();
var template = templateTask.get();
return Invoice.generate(order, customer, template);
}
}Code language: Java (java)The following example shows another strategy (enabled by Joiner.anySuccessfulOrThrow()): Here, only the result of one of the subtasks is needed – and as soon as it is available, the other subtasks are canceled:
AddressVerificationResponse verifyAddress(Address address) throws InterruptedException {
try (var scope = StructuredTaskScope.open(
Joiner.<AddressVerificationResponse>anySuccessfulOrThrow())) {
scope.fork(() -> verificationService.verifyViaServiceA(address));
scope.fork(() -> verificationService.verifyViaServiceB(address));
scope.fork(() -> verificationService.verifyViaServiceC(address));
return scope.join();
}
}Code language: Java (java)The Joiner interface used here provides further strategies. You can find out what these are and how you can implement your own strategies in the main article on Structured Concurrency in Java.
Structured Concurrency – Changes in Java 26
Structured Concurrency was first introduced in Java 21. In Java 25, the API was fundamentally revised (keyword: “Composition over Inheritance”). In Java 26, the following extensions and adjustments were made through JDK Enhancement Proposal 525:
- The
Joinerinterface has received an additional methodonTimeout(), in addition toonFork()andonComplete(). This method is called byStructuredTaskScope.join()in case of a timeout and throws aTimeoutExceptionby default. However, it can be overridden in a custom Joiner to handle timeouts alternatively – e.g., to return a specific value. - The Joiner created by
Joiner.allSuccessfulOrThrow()no longer returns a stream of subtasks (which are all successful anyway), but a list of the results of the subtasks. - The Joiner created by
Joiner.allUntil(...)returns a list of subtasks instead of a stream of subtasks. - The method
Joiner.anySuccessfulResultOrThrow()was renamed toanySuccessfulOrThrow()(the wordResultwas removed, as it is not used in the otherJoinerfactory methods either). - There is an overloaded
StructuredTaskScope.open(...)method that allows customizing the configuration of a joiner. In this method, the type for the configuration parameter was changed fromFunction<Configuration, Configuration>toUnaryOperator<Configuration>(which is ultimately aFunction<Configuration, Configuration>again).
Code written with Java 25 therefore requires only minor (or no) adjustments to run on Java 26.
Lazy Constants (Second Preview) – JEP 526
Lazy Constants were introduced in Java 25 as Stable Values. If you are already familiar with Stable Values and are only interested in the changes in Java 26, you can jump to the section Lazy Constants – Changes in Java 26.
What problem do we want to solve?
Constants – i.e., immutable values – have many advantages: They make the code simpler and safer, as they can only be in one state and can be safely accessed from multiple threads. In addition, they enable performance optimizations by the JVM, e.g., through Constant Folding (already mentioned above for final fields).
Until now, constants could only be defined by final fields:
- final static fields, which are initialized when a class is loaded – or
- final instance fields, which are initialized when an object is created.
If you want to initialize an immutable value only when needed, e.g., because the initialization is expensive, you have to use the concept of “Lazy Initialization”. To make lazy initialization thread-safe in Java, we previously had to resort to either the Double-Checked-Locking-Idiom or the Initialization-on-Demand-Holder-Idiom. Anyone who has done this before knows that errors can easily creep in.
Lazy Constants API
In Java 25, the Stable Values API was introduced to simplify Lazy Initialization. After extensive feedback, the API in Java 26 was greatly simplified by JDK Enhancement Proposal 526 and renamed to Lazy Constants.
The following example shows how we define a LazyConstant that initializes a Settings object by loading it from a database only upon its first access:
private final LazyConstant<Settings> settings =
LazyConstant.of(this::loadSettingsFromDatabase);
public Locale getLocale() {
return settings.get().getLocale(); // ⟵ Here we access the lazy constant
}Code language: Java (java)Only on the first call to settings.get() will the loadSettingsFromDatabase() method be invoked. The value is then stored in the LazyConstant object, and subsequent calls to settings.get() will return this stored value. Thread safety is also guaranteed: Should settings.get() be called simultaneously from multiple threads, loadSettingsFromDatabase() will still be called at most once.
Once the LazyConstant is initialized, it is interpreted as immutable by the JVM, and access to it is optimized through Constant Folding.
Lazy Lists
In addition to individual Lazy Constants, we can also define Lazy Lists – lists where each element is a Lazy Constant. The following example shows a simple Lazy List in which each field is lazily initialized with the square root of the field index:
private final List<Double> squareRoots = List.ofLazy(100, Math::sqrt);Code language: Java (java)Here too, initialization only occurs on first access – and separately for each element of the list, e.g., during direct access with get(int index) – or when iterating over the list. And here too, initialization is thread-safe, and after initialization, the values are treated and optimized by the JVM like constants.
Lazy Maps
Maps can also be lazily initialized in the future. The following example shows a Lazy Map where Locales are mapped to ResourceBundles:
Set<Locale> supportedLocales = getSupportedLocales();
Map<Locale, ResourceBundle> resourceBundles =
Map.ofLazy(supportedLocales, this::loadResourceBundle);Code language: Java (java)On the first access to a map element for a specific Locale, the corresponding ResourceBundle is loaded via loadResourceBundle() and then stored in the map as a constant. Just like Lazy Constants and Lazy Lists, Lazy Maps are also thread-safe.
Lazy Constants – Changes in Java 26
In addition to the obvious change – the renaming to Lazy Constants – the following simplifications were made in Java 26:
- Low-level methods such as
orElseSet(),setOrThrow(), andtrySet()were removed, as they made the API unnecessarily complicated. - Lazy Lists and Lazy Maps were previously created via
StableValue.list(...)andStableValue.map(...). These factory methods were moved to theListandMapinterfaces, respectively. - The
FunctionandIntFunctionimplementations created viaStableValue.function(...)andStableValue.intFunction(...), respectively, were removed without replacement, as they offered no added value compared to Lazy Lists and Lazy Maps. - For performance reasons, Lazy Constants, Lazy Lists, and Lazy Maps may no longer contain
nullvalues. If the computation function returnsnull, anNullPointerExceptionis thrown.
So, if you have already relied on Stable Values in Java 25, extensive refactoring will be required.
Vector API (Eleventh Incubator) – JEP 529
And now, for the eleventh time, we come to the Vector API.
With the Vector API, mathematical vector operations can be calculated particularly efficiently using the vector instruction sets of modern CPUs (such as SSE and AVX) – e.g., a vector addition like the following:

As Java code, this operation would be implemented as follows, where a and b are the input vectors and c is the output vector:
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void addVectors(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.add(vb);
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}Code language: Java (java)Currently, quite a lot of boilerplate is still necessary for such a simple operation:
- Via
SPECIES.length(), it is queried how many vector elements can be processed simultaneously in one CPU cycle. SPECIES.loopBound(...)calculates into how many complete sub-vectors of this length the output vector can be split.- All sub-vectors are added via the first loop.
- If the length of the output vector is not a multiple of the sub-vector length, a remainder remains. Its elements are individually added via the second loop.
I am curious if the API will be further simplified after it reaches the preview stage.
However, we still have to be patient until the first JEP from Project Valhalla – JEP 401: Value Classes and Objects – reaches the preview stage. This is because the Vector class is intended to be a Value Class from the start – i.e., a class whose objects will manage without identity.
When will it be ready? Brian Goetz, Language Architect at Oracle, has consistently answered the question about Project Valhalla’s release date for years with: “It’s ready when it’s ready” – he has not yet been persuaded to give a more concrete statement. On October 10, 2025, the Java community was finally provided with a first Early-Access Build of Project Valhalla.
The eleventh incubator version of the Vector API is described in JDK Enhancement Proposal 529: There are no substantial changes compared to the previous version.
You can find more examples and details in the main article about lazy constants.
Primitive Types in Patterns, instanceof, and switch (Fourth Preview) – JEP 530
Pattern Matching with primitive types was first introduced in Java 23 as a preview feature. Since then, there have been no fundamental changes. If you are already familiar with the feature and are interested in the minor refinements in Java 26, feel free to jump to the section Primitive Types in Patterns – Changes in Java 26.
Pattern Matching and switch with Primitive Types – Current Status
Pattern Matching has so far been limited to reference types, for example, as follows:
Object obj = . . .
switch (obj) {
case String s when s.length() >= 5 -> IO.println(s.toUpperCase());
case Integer i -> IO.println(i * i);
case null, default -> IO.println(obj);
}Code language: Java (java)A switch over primitive types is possible – but only with byte, short, char and int – and in the case-labels, only constants are allowed:
int code = . . .
switch (code) {
case 200 -> IO.println("OK");
case 404 -> IO.println("Not Found");
}Code language: Java (java)Pattern Matching and switch with Primitive Types – What will change?
In the future, all primitive types should be allowed in switch, including long, double, float, and even boolean. And patterns should also be allowed in the case labels. This would allow us to check, for example, a int value against specific number ranges:
int code = . . .
switch (code) {
case int i when i >= 100 && i < 200 -> IO.println("information");
case int i when i >= 200 && i < 300 -> IO.println("success");
case int i when i >= 300 && i < 400 -> IO.println("redirection");
case int i when i >= 400 && i < 500 -> IO.println("client error");
case int i when i >= 500 && i < 600 -> IO.println("server error");
default -> throw new IllegalArgumentException();
}Code language: Java (java)Patterns with reference types also match derived types, e.g., a case Number n would also match an object of type Integer. With primitive types, there is no inheritance – therefore, the JDK developers have come up with something different here:
In the future, we can check with switch (and similarly with instanceof) whether the value of a primitive variable can be represented by another primitive type without loss of precision:
double value = . . .
switch (value) {
case byte b -> IO.println(value + " instanceof byte: " + b);
case short s -> IO.println(value + " instanceof short: " + s);
case char c -> IO.println(value + " instanceof char: " + c);
case int i -> IO.println(value + " instanceof int: " + i);
case long l -> IO.println(value + " instanceof long: " + l);
case float f -> IO.println(value + " instanceof float: " + f);
case double d -> IO.println(value + " instanceof double: " + d);
}Code language: Java (java)If value here were, for example, 42, then the pattern byte b would match, since 42 can also be stored in a byte. If value were, for example, 50,000, then the pattern char c would match. For 65,000, int i would match, for 0.5 float f, and for 0.7, only double d.
The dominance principle also applies to primitive types: The order of the case labels in the previous example must not be changed, as individual case labels would then no longer be reachable. For example, the pattern int i should not appear before byte b, as every possible byte would already match int i.
Primitive Types in Patterns – Changes in Java 26
Through JDK Enhancement Proposal 530, the dominance check was mainly improved in Java 26. The following code, for example, can still be compiled without errors with Java 25:
int i1 = . . .
switch (i1) {
case float f -> {}
case 16_777_216 -> {}
default -> {}
}
int i2 = . . .
switch (i2) {
case int _ -> {}
case float _ -> {}
}
byte b = . . .
switch (b) {
case short s -> {}
case 42 -> {}
}Code language: Java (java)In Java 26, however, all three switch statements are met with compiler errors:
- In the first
switch, the constant 16,777,216 can never match, since this number can also be precisely represented by afloat, and thus the constant is dominated by the patternfloat f. - In the second
switch, the patternfloat fcan never match, since every value thati2can take is already matched by the patternint _. - In the third
switch, the constant 42 can never match, since 42 can also be stored in ashort, and thus the constant is dominated by the patternshort s.
Apart from the improved dominance check, there are no other changes in Java 26.
Deprecations and Deletions
In Java 26, the Applet API and the Thread.stop() method were removed. You can find details in the following two sections.
Remove the Applet API – JEP 504
The Applet API and the Security Manager, which was responsible for securing applets, were marked as deprecated in Java 9 in 2017, as applets were no longer supported by any modern web browser at that time. In Java 17, the Applet API and Security Manager were marked as deprecated for removal.
The Security Manager was disabled in Java 24.
In Java 26, the Applet API – i.e., all classes in the java.applet package as well as some others, such as java.beans.AppletInitializer and javax.swing.JApplet – has now been completely removed via JDK Enhancement Proposal 504.
Thread.stop is removed
Thread.stop() It was already marked as deprecated in Java 1.2 – in December 1998 – because it could lead to inconsistent states and unpredictable behavior. In Java 18, it was marked as deprecated for removal, and since Java 20, it throws an UnsupportedOperationException.
In Java 26 – more than 27 years after being marked as deprecated – the method is now completely removed.
(There is no JEP for this change; it is registered in the bug tracker under JDK-8368226.)
Other Changes in Java 26
In this section, you will find a selection of minor changes from the release notes for which no JDK Enhancement Proposals were written.
Add Dark Theme to API Documentation
This feature is quickly explained: in Java 26, the Javadoc documentation offers a dark mode. You can already try it out in the Early-Access documentation of 26 by clicking on the sun or moon icon in the menu bar.
Here’s an impression of the new mode:

(There is no JEP for this change; it is registered in the bug tracker under JDK-8342705.)
New ofFileChannel Method in java.net.http.HttpRequest.BodyPublishers
To send a file with the HttpClient API (available since Java 11), it previously had to be completely loaded into RAM and passed as a byte array to the HttpRequest:
byte[] fileContent = Files.readAllBytes(Path.of("test.bin"));
try (HttpClient client = HttpClient.newHttpClient()) {
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create("https://www.example.com/upload"))
.POST(BodyPublishers.ofByteArray(fileContent))
.build();
HttpResponse<Void> response =
client.send(request, HttpResponse.BodyHandlers.discarding());
}Code language: Java (java)Starting with Java 26, a file (or part of it) can also be streamed via FileChannel to the HttpRequest and thus no longer needs to be fully available in memory beforehand. This is particularly helpful for very large files:
try (FileChannel fileChannel =
FileChannel.open(Path.of("test.bin"), StandardOpenOption.READ);
HttpClient client = HttpClient.newHttpClient()) {
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create("https://www.example.com/upload"))
.POST(BodyPublishers.ofFileChannel(fileChannel, 0, fileChannel.size()))
.build();
HttpResponse<Void> response =
client.send(request, HttpResponse.BodyHandlers.discarding());
}Code language: Java (java)(There is no JEP for this change; it is registered in the bug tracker under JDK-8329829.)
Default initial heap size is trimmed down
If neither -Xms nor -XX:InitialRAMPercentage is used to specify a minimum heap size when starting a Java application, the heap is set by default to 1/64 (= 1.5625%) of the physical RAM. Today, computers have significantly more RAM than twenty years ago, so many applications are equipped with an unnecessarily large heap. On my 64 GB laptop, for example, even a Hello World application is started with a 1 GB heap.
Besides the unnecessarily occupied RAM, this can also noticeably delay the start of an application, because the Garbage Collector has to create initial data structures for the heap, which scale with the heap size.
In Java 26, the initial heap size is changed by default to 0.2%, i.e., 1/500 of the physical RAM. On my 64 GB laptop, this is still a sufficient 128 MB for many small applications.
(There is no JEP for this change; it is registered in the bug tracker under JDK-8348278.)
Virtual threads now unmount when waiting for another thread to execute a class initializer
Under certain circumstances, virtual threads are “pinned” to their carrier thread, meaning that if the virtual thread blocks, it cannot be unmounted from its carrier thread (the operating system thread on which the virtual thread is executed). Thus, the carrier thread is also blocked and cannot execute another virtual thread.
Already in Java 24, the serious pinning issue within synchronized blocks was resolved.
Before Java 26, a virtual thread was also pinned if it tried to initialize a class that was currently being initialized by another thread. This no longer happens either.
(There is no JEP for this change; it is registered in the bug tracker under JDK-8369238.)
Support for Unicode 17.0
Java 26 increases Unicode support to version 17.0.
Why is this relevant? All character-processing classes such as String and Character must be able to process the characters and code blocks introduced in the new Unicode version.
(For this change, there is no JEP; it is registered in the bug tracker under JDK-8346944.)
Complete List of All Changes in Java 26
In this article, I have presented all JDK Enhancement Proposals that were delivered with Java 26, as well as a selection of changes from the release notes. You can find the complete list of all changes in the Java 26 Release Notes.
Conclusion
Compared to the last two Java versions, the changes in Java 26 are quite manageable:
- Mutating final fields with deep reflection now issues a warning – in the future, an exception will be thrown.
- The Ahead-of-Time Class Loading & Linking introduced in Java 24 now works with any garbage collector – no longer just with G1.
- HttpClient now supports HTTP/3.
- The G1 Garbage Collector has been optimized, leading to an increase in throughput.
- The Applet API and
Thread.stop()have been removed. - Stable Values have been renamed to Lazy Constants – and the API has been radically simplified.
- For the remaining features currently in preview, minor improvements have been made.
As always, various other changes round off the release. You can download the current Java 26 Early-Access Release here.
Which of the changes do you find most exciting? Share your opinion in the comments!